Ridurre al minimo i problemi di SQL per le migrazioni di Oracle
Questo articolo è la quinta parte di una serie in sette parti che fornisce indicazioni su come eseguire la migrazione da Oracle ad Azure Synapse Analytics. L'obiettivo di questo articolo è illustrare le procedure consigliate per ridurre al minimo i problemi di SQL.
Panoramica
Caratteristiche degli ambienti Oracle
Il prodotto di database iniziale di Oracle, rilasciato nel 1979, era un database relazionale SQL commerciale per le applicazioni di elaborazione delle transazioni online (OLTP) con tassi di transazione molto inferiori rispetto a oggi. Da quel rilascio iniziale, l'ambiente Oracle si è evoluto per diventare molto più complesso e comprende numerose funzionalità. Le funzionalità includono architetture client-server, database distribuiti, elaborazione parallela, analisi dei dati, disponibilità elevata, data warehousing, tecniche di dati in memoria e supporto per le istanze basate sul cloud.
Suggerimento
Oracle ha introdotto il concetto di "appliance data warehouse" nei primi anni 2000.
A causa dei costi e della complessità della gestione e dell'aggiornamento di ambienti Oracle locali legacy, molti utenti Oracle esistenti vogliono sfruttare le innovazioni offerte dagli ambienti cloud. Gli ambienti cloud moderni, ad esempio cloud, IaaS e PaaS, consentono di delegare attività come la manutenzione dell'infrastruttura e lo sviluppo della piattaforma al provider di servizi cloud.
Molti data warehouse che supportano query SQL analitiche complesse su volumi di dati di grandi dimensioni usano tecnologie Oracle. Questi data warehouse in genere hanno un modello di dati dimensionale, ad esempio schemi star o snowflake, e usano data mart per singoli reparti.
Suggerimento
Molte installazioni Oracle esistenti sono data warehouse che usano un modello di dati dimensionale.
La combinazione di modelli di dati SQL e dimensionali in Oracle semplifica la migrazione ad Azure Synapse perché i concetti del modello di dati SQL e di base sono trasferibili. Microsoft consiglia di spostare il modello di dati esistente così com'è in Azure per ridurre i rischi, il lavoro e il tempo di migrazione. Anche se il piano di migrazione può includere una modifica nel modello di dati sottostante, ad esempio uno spostamento da un modello Inmon a un insieme di credenziali dei dati, è opportuno eseguire inizialmente una migrazione così com'è. Dopo la migrazione iniziale, è quindi possibile apportare modifiche all'interno dell'ambiente cloud di Azure per sfruttare le prestazioni, la scalabilità elastica, le funzionalità predefinite e i vantaggi economici.
Anche se il linguaggio SQL è standardizzato, i singoli fornitori talvolta implementano estensioni proprietarie. Di conseguenza, è possibile trovare differenze SQL durante la migrazione che richiedono soluzioni alternative in Azure Synapse.
Usare le strutture Azure per implementare una migrazione basata sui metadati
È possibile automatizzare e orchestrare il processo di migrazione usando le funzionalità dell'ambiente Azure. Questo approccio riduce al minimo l'impatto sulle prestazioni nell'ambiente Oracle esistente, che potrebbe essere già aver quasi raggiunto il limite di capacità.
Azure Data Factory è un servizio di integrazione di dati basato sul cloud che consente di creare flussi di lavoro basati sui dati nel cloud per orchestrare e automatizzare lo spostamento e la trasformazione dei dati stessi. È possibile usare Data Factory per creare e pianificare flussi di lavoro basati sui dati (pipeline) che inseriscono dati da archivi dati diversi. Data Factory può elaborare e trasformare i dati usando servizi di calcolo, ad esempio Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics e Azure Machine Learning.
Azure include anche Servizi Migrazione del database di Azure che consente di pianificare ed eseguire una migrazione da ambienti come Oracle. SQL Server Migration Assistant (SSMA) per Oracle può automatizzare la migrazione di database Oracle, tra cui in alcuni casi funzioni e codice procedurale.
Suggerimento
Automatizzare il processo di migrazione usando le funzionalità di Azure Data Factory.
Quando si prevede di usare le funzionalità di Azure, come Data Factory, per gestire il processo di migrazione, creare innanzitutto metadati che elenchino tutte le tabelle di dati di cui è necessario eseguire la migrazione e la relativa posizione.
Differenze di DDL SQL tra Oracle e Azure Synapse
Lo standard SQL ANSI definisce la sintassi di base per i comandi DDL (Data Definition Language). Alcuni comandi DDL, come CREATE TABLE e CREATE VIEW, sono comuni sia a Oracle che ad Azure Synapse, ma sono stati estesi per offrire anche funzionalità specifiche dell'implementazione, ad esempio l'indicizzazione, la distribuzione delle tabelle e le opzioni di partizionamento.
Suggerimento
I comandi SQL DDL CREATE TABLE e CREATE VIEW dispongono di elementi di base standard, ma vengono usati anche per definire opzioni specifiche dell'implementazione.
Le sezioni seguenti illustrano le opzioni specifiche di Oracle che devono essere considerate durante una migrazione ad Azure Synapse.
Considerazioni sulla tabella/vista
Quando si esegue la migrazione di tabelle tra ambienti diversi, in genere vengono trasferiti solo i dati non elaborati e i metadati che li descrivono fisicamente. Altri elementi di database del sistema di origine, ad esempio gli indici e i file di log, in genere non vengono trasferiti perché potrebbero non essere necessari o potrebbero essere implementati in modo diverso nel nuovo ambiente. Ad esempio, l'opzione TEMPORARY all'interno della sintassi CREATE TABLE di Oracle equivale al prefisso del nome di una tabella con un carattere # in Azure Synapse.
Le ottimizzazioni delle prestazioni nell'ambiente di origine, ad esempio gli indici, indicano dove è possibile aggiungere l'ottimizzazione delle prestazioni nel nuovo ambiente di destinazione. Ad esempio, se gli indici bitmap vengono usati spesso nelle query nell'ambiente Oracle di origine, ciò suggerisce che debba essere creato un indice non cluster all'interno di Azure Synapse. Altre tecniche di ottimizzazione delle prestazioni native, ad esempio la replica di tabelle, possono essere più applicabili rispetto alla creazione di indici simili a quelle di tipo semplice. SSMA per Oracle può fornire raccomandazioni sulla migrazione per la distribuzione e l'indicizzazione delle tabelle.
Suggerimento
Gli indici esistenti indicano candidati per l'indicizzazione nel warehouse migrato.
Le definizioni delle viste SQL contengono istruzioni DML (Data Manipulation Language) SQL che definiscono la vista, in genere con una o più istruzioni SELECT. Quando si esegue la migrazione di istruzioni CREATE VIEW, tenere conto delle differenze di DML tra Oracle e Azure Synapse.
Tipi di oggetto di database Oracle non supportati
Le funzionalità specifiche di Oracle possono spesso essere sostituite dalle funzionalità di Azure Synapse. Tuttavia, alcuni oggetti di database Oracle non sono supportati direttamente in Azure Synapse. L'elenco seguente di oggetti di database Oracle non supportati descrive come ottenere una funzionalità equivalente in Azure Synapse:
Opzioni di indicizzazione: in Oracle, diverse opzioni di indicizzazione, ad esempio indici bitmap, indici basati sulle funzioni e indici di dominio, non hanno equivalenti diretti in Azure Synapse. Anche se Azure Synapse non supporta tali tipi di indice, è possibile ottenere una riduzione simile dell'I/O del disco usando i tipi di indice definiti dall'utente e/o il partizionamento. La riduzione dell'I/O del disco migliora le prestazioni delle query.
È possibile individuare le colonne indicizzate e il relativo tipo di indice eseguendo query su tabelle e viste del catalogo di sistema, ad esempio
ALL_INDEXES,DBA_INDEXES,USER_INDEXESeDBA_IND_COL. Oppure è possibile eseguire query sulle vistedba_index_usageov$object_usagequando il monitoraggio è abilitato.Le funzionalità di Azure Synapse, ad esempio l'elaborazione parallela delle query e la memorizzazione nella cache dei dati e dei risultati, rendono probabile la necessità di un minor numero di indici per le applicazioni di data warehouse per raggiungere gli obiettivi di prestazioni eccellenti.
Tabelle cluster: le tabelle Oracle possono essere organizzate in modo che le righe della tabella a cui si accede di frequente (in base a un valore comune) vengano archiviate fisicamente insieme. Questa strategia riduce l'I/O del disco quando vengono recuperati i dati. Oracle offre anche un'opzione hash-cluster per le singole tabelle, che applica un valore hash alla chiave del cluster e archivia fisicamente le righe con lo stesso valore hash insieme.
In Azure Synapse, è possibile ottenere un risultato simile tramite il partizionamento e/o usando altri indici.
Viste materializzate: Oracle supporta le viste materializzate e consiglia di usarne una o più per le tabelle di grandi dimensioni con molte colonne in cui solo poche colonne vengono usate regolarmente nelle query. Le viste materializzate vengono aggiornate automaticamente dal sistema quando i dati nella tabella di base vengono aggiornati.
Nel 2019 Microsoft ha annunciato che Azure Synapse supporterà le viste materializzate con le stesse funzionalità di Oracle. Le viste materializzate sono ora una funzionalità di anteprima in Azure Synapse.
Trigger nel database: in Oracle un trigger può essere configurato per l'esecuzione automatica quando si verifica un evento di attivazione. Gli eventi di attivazione possono essere:
Viene eseguita un'istruzione DML, ad esempio
INSERT,UPDATEoDELETE. Se è stato definito un trigger che viene generato prima di un'istruzioneINSERTin una tabella Customer, il trigger verrà generato una volta prima che venga inserita una nuova riga nella tabella Customer.Viene eseguita un'istruzione DDL, ad esempio
CREATEoALTER. Questo evento di attivazione viene spesso usato per registrare le modifiche dello schema a scopo di controllo.Un evento di sistema, ad esempio l'avvio o l'arresto del database Oracle.
Un evento utente, ad esempio accesso o disconnessione.
Azure Synapse non supporta i trigger di database Oracle. Tuttavia, è possibile ottenere funzionalità equivalenti usando Data Factory, anche se in questo modo sarà necessario effettuare il refactoring dei processi che usano trigger.
Sinonimi: Oracle supporta la definizione di sinonimi come nomi alternativi per diversi tipi di oggetto di database. Tali tipi includono: tabelle, viste, sequenze, procedure, funzioni archiviate, pacchetti, viste materializzate, oggetti dello schema di classe Java, oggetti definiti dall'utente o altri sinonimi.
Azure Synapse attualmente non supporta la definizione di sinonimi, anche se un sinonimo in Oracle fa riferimento a una tabella o a una vista, è possibile definire una vista in Azure Synapse in modo che corrisponda al nome alternativo. Se un sinonimo in Oracle fa riferimento a una funzione o a una stored procedure, è possibile sostituire il sinonimo in Azure Synapse con un'altra funzione o stored procedure che chiama la destinazione.
Tipi definiti dall'utente: Oracle supporta oggetti definiti dall'utente che possono contenere una serie di singoli campi, ognuno con la propria definizione e valori predefiniti. È quindi possibile fare riferimento a tali oggetti all'interno di una definizione di tabella allo stesso modo dei tipi di dati predefiniti, ad esempio
NUMBERoVARCHAR.Azure Synapse attualmente non supporta i tipi definiti dall'utente. Se i dati di cui è necessario eseguire la migrazione includono tipi di dati definiti dall'utente, "appiattirli" in una definizione di tabella convenzionale o se sono matrici di dati, normalizzarli in una tabella separata.
Generazione di DDL SQL
È possibile modificare gli script CREATE TABLE e CREATE VIEW di Oracle esistenti per ottenere definizioni equivalenti in Azure Synapse. A tale scopo, potrebbe essere necessario usare tipi di dati modificati e rimuovere o modificare clausole specifiche di Oracle, ad esempio TABLESPACE.
Suggerimento
Usare i metadati Oracle esistenti per automatizzare la generazione di DDL CREATE TABLE e CREATE VIEW per Azure Synapse.
All'interno dell'ambiente Oracle, le tabelle del catalogo di sistema specificano la definizione di tabella/vista corrente. A differenza della documentazione gestita dall'utente, le informazioni sul catalogo di sistema sono sempre complete e sincronizzate con le definizioni di tabella correnti. È possibile accedere alle informazioni del catalogo di sistema usando utilità come Oracle SQL Developer. Oracle SQL Developer può generare istruzioni DDL CREATE TABLE che è possibile modificare per applicare a tabelle equivalenti in Azure Synapse, come illustrato nello screenshot successivo.

Oracle SQL Developer restituisce l'istruzione CREATE TABLE seguente, che contiene clausole specifiche di Oracle da rimuovere. Eseguire il mapping di qualsiasi tipo di dati non supportato prima di eseguire l'istruzione CREATE TABLE modificata in Azure Synapse.
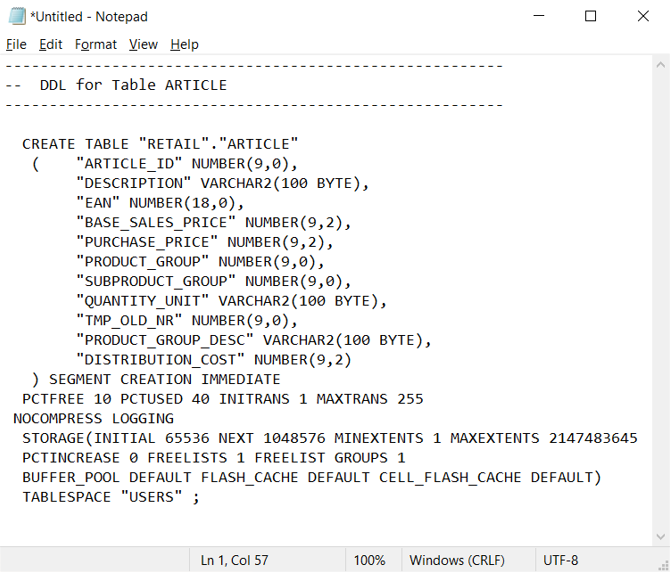
In alternativa, è possibile generare automaticamente istruzioni CREATE TABLE dalle informazioni all'interno delle tabelle del catalogo Oracle usando query SQL, SSMA o strumenti di migrazione di terze parti. Questo approccio è il modo più rapido e coerente per generare istruzioni CREATE TABLE per molte tabelle.
Suggerimento
Strumenti e servizi di terze parti possono automatizzare le attività di mapping dei dati.
I fornitori di terze parti offrono strumenti e servizi per automatizzare la migrazione, incluso il mapping dei tipi di dati. Se uno strumento ETL di terze parti è già in uso nell'ambiente Oracle, usarlo per implementare le trasformazioni dei dati necessarie.
Differenze di DML SQL tra Oracle e Azure Synapse
Lo standard SQL ANSI definisce la sintassi di base per i comandi DML, ad esempio SELECT, INSERT, UPDATE e DELETE. Anche se Oracle e Azure Synapse supportano entrambi i comandi DDL, in alcuni casi implementano lo stesso comando in modo diverso.
Suggerimento
I comandi DML SQL standard SELECT, INSERT e UPDATE possono avere opzioni di sintassi aggiuntive in ambienti di database diversi.
Le sezioni seguenti illustrano i comandi DML specifici di Oracle che devono essere considerati durante una migrazione ad Azure Synapse.
Differenze di sintassi SQL DML
Esistono alcune differenze di sintassi SQL DML tra Oracle SQL e Azure Synapse T-SQL:
Tabella
DUAL: Oracle include una tabella di sistema denominataDUALcostituita esattamente da una colonna denominatadummye un record con il valoreX. La tabella di sistemaDUALviene usata quando una query richiede un nome di tabella per motivi di sintassi, ma il contenuto della tabella non è necessario.Una query Oracle di esempio che usa la tabella
DUALèSELECT sysdate from dual;. L'equivalente di Azure Synapse èSELECT GETDATE();. Per semplificare la migrazione di DML, è possibile creare una tabellaDUALequivalente in Azure Synapse usando il DDL seguente.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GOValori
NULL: un valoreNULLin Oracle è una stringa vuota, rappresentata da un tipo di stringaCHARoVARCHARdi lunghezza0. In Azure Synapse e nella maggior parte degli altri databaseNULLsignifica qualcos'altro. Prestare attenzione quando si esegue la migrazione dei dati o durante la migrazione di processi che gestiscono o archiviano i dati, per assicurarsi che i valoriNULLvengano gestiti in modo coerente.Sintassi outer join di Oracle: anche se le versioni più recenti di Oracle supportano la sintassi outer join ANSI, i sistemi Oracle meno recenti usano una sintassi proprietaria per gli outer join che usano un segno più (
+) all'interno dell'istruzione SQL. Se si esegue la migrazione di un ambiente Oracle precedente, è possibile che si verifichi la sintassi precedente. Ad esempio:SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;La sintassi standard ANSI equivalente è:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;Dati
DATE: in Oracle, il tipo di datiDATEpuò archiviare sia data che ora. Azure Synapse archivia data e ora in tipi di datiDATE,TIMEeDATETIMEseparati. Quando si esegue la migrazione di colonneDATEdi Oracle, verificare se archiviano sia data che ora o solo una data. Se archiviano solo una data, eseguire il mapping della colonna aDATE, in caso contrario aDATETIME.Aritmetica
DATE: Oracle supporta la sottrazione di una data da un'altra, ad esempioSELECT date '2018-12-31' - date '2018-1201' from dual;. In Azure Synapse è possibile sottrarre le date usando la funzioneDATEDIFF(), ad esempioSELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle può sottrarre numeri interi dalle date, ad esempio
SELECT hire_date, (hire_date-1) FROM employees;. In Azure Synapse è possibile aggiungere o sottrarre numeri interi dalle date usando la funzioneDATEADD().Aggiornamenti tramite viste: in Oracle è possibile eseguire operazioni di inserimento, aggiornamento ed eliminazione in una vista per aggiornare la tabella sottostante. In Azure Synapse queste operazioni vengono eseguite su una tabella di base, non in una vista. Se una tabella Oracle viene aggiornata tramite una vista potrebbe essere necessario riprogettare l'elaborazione ETL.
Funzioni predefinite: la tabella seguente illustra le differenze nella sintassi e nell'utilizzo di alcune funzioni predefinite.
| Funzione di Oracle | Descrizione | Equivalente di Synapse |
|---|---|---|
| ADD_MONTHS | Aggiunge un numero di mesi specificato | DATEADD |
| CAST | Convertire un tipo di dati predefinito in un altro | CAST |
| DECODE | Valuta un elenco di condizioni | Espressione CASE |
| EMPTY_BLOB | Crea un valore BLOB vuoto | Costante 0x (stringa binaria vuota) |
| EMPTY_CLOB | Crea un valore CLOB o NCLOB vuoto | '' (stringa vuota) |
| INITCAP | Converte in maiuscolo la prima lettera di ogni parola | Funzione definita dall'utente |
| INSTR | Trova la posizione di una substring in una stringa | CHARINDEX |
| LAST_DAY | Ottiene l'ultima data del mese | EOMONTH |
| LENGTH | Ottiene la lunghezza della stringa in caratteri | LEN |
| LPAD | Stringa del riquadro sinistro alla lunghezza specificata | Espressione che usa REPLICATE, RIGHT e LEFT |
| MOD | Ottiene il resto di una divisione di un numero per un altro | Operatore % |
| MONTHS_BETWEEN | Ottiene il numero di mesi tra due date | DATEDIFF |
| NVL | Sostituisce NULL con un'espressione |
ISNULL |
| SUBSTR | Restituisce una substring da una stringa | SUBSTRING |
| TO_CHAR per datetime | Converte datetime in stringa | CONVERT |
| TO_DATE | Converte una stringa in datetime | CONVERT |
| TRANSLATE | Sostituzione di un singolo carattere uno a uno | Espressioni che usano REPLACE o una funzione definita dall'utente |
| TRIM | Taglia i caratteri iniziali o finali | LTRIM e RTRIM |
| TRUNC per datetime | Tronca datetime | Espressioni che usano CONVERT |
| UNISTR | Converte i punti di codice Unicode in caratteri | Espressioni che usano NCHAR |
Funzioni, stored procedure e sequenze
Quando si esegue la migrazione di un data warehouse da un ambiente maturo come Oracle, è probabile che sia necessario eseguire la migrazione di elementi diversi da tabelle e viste semplici. Controllare se gli strumenti all'interno dell'ambiente Azure possono sostituire le funzionalità di funzioni, stored procedure e sequenze perché in genere è più efficiente usare gli strumenti predefiniti di Azure rispetto a ricodificare le funzioni Oracle.
Come parte della fase di preparazione, creare un inventario di oggetti di cui è necessario eseguire la migrazione, definire un metodo per gestirli e allocare risorse appropriate nel piano di migrazione.
Strumenti Microsoft come SSMA per Oracle e Servizio Migrazione del database di Azure oppure prodotti e servizi di migrazione di terze parti possono automatizzare la migrazione di funzioni, stored procedure e sequenze.
Suggerimento
I prodotti e i servizi di terze parti possono automatizzare la migrazione di elementi non dati.
Le sezioni seguenti illustrano la migrazione di funzioni, stored procedure e sequenze.
Funzioni
Come per la maggior parte dei prodotti di database, Oracle supporta funzioni definite dall'utente e di sistema all'interno di un'implementazione SQL. Quando si esegue la migrazione di una piattaforma di database legacy ad Azure Synapse, è in genere possibile eseguire la migrazione di funzioni di sistema comuni senza modifiche. Alcune funzioni di sistema potrebbero avere una sintassi leggermente diversa, ma tutte le modifiche necessarie possono essere automatizzate.
Per le funzioni di sistema Oracle o le funzioni arbitrarie definite dall'utente che non hanno equivalenti in Azure Synapse, ricodificarle usando il linguaggio di ambiente di destinazione. Le funzioni definite dall'utente Oracle vengono codificate in PL/SQL, Java o C. Azure Synapse usa il linguaggio Transact-SQL per implementare funzioni definite dall'utente.
Stored procedure
La maggior parte dei prodotti di database moderni supporta l'archiviazione delle procedure all'interno del database. Oracle offre il linguaggio PL/SQL a questo scopo. Una stored procedure contiene in genere istruzioni SQL e logica procedurale e restituisce dati o uno stato.
Azure Synapse supporta stored procedure con T-SQL, quindi sarà necessario codificare tutte le stored procedure sottoposte a migrazione in T-SQL.
Sequenze
In Oracle una sequenza è un oggetto di database denominato, creato tramite CREATE SEQUENCE. Una sequenza offre valori numerici univoci tramite i metodi CURRVAL e NEXTVAL. È possibile usare i numeri univoci generati come valori di chiave surrogata per le chiavi primarie. Azure Synapse non implementa CREATE SEQUENCE, ma è possibile implementare sequenze usando colonne IDENTITY o codice SQL che genera il numero di sequenza successivo in una serie.
Usare EXPLAIN per convalidare SQL legacy
Suggerimento
Usare query reali dai log delle query di sistema esistenti per individuare potenziali problemi di migrazione.
Supponendo che in Azure Synapse sia stato eseguito un modello di dati di tipo like-for-like con gli stessi nomi di tabella e colonna, un modo per testare Oracle SQL legacy per la compatibilità con Azure Synapse è:
- Acquisire alcune istruzioni SQL rappresentative dai log della cronologia delle query di sistema legacy.
- Anteporre tali query all'istruzione
EXPLAIN. - Eseguire le istruzioni
EXPLAINin Azure Synapse.
Qualsiasi SQL incompatibile genererà un errore e le informazioni sull'errore possono essere usate per determinare la scala dell'attività di ricodifica. Questo approccio non richiede il caricamento di dati nell'ambiente Azure, ma è sufficiente creare le tabelle e le viste pertinenti.
Riepilogo
Le installazioni Oracle legacy esistenti vengono in genere implementate in modo da rendere relativamente semplice la migrazione ad Azure Synapse. Entrambi gli ambienti usano SQL per le query analitiche su volumi di dati di grandi dimensioni e in genere usano una forma di modello di dati dimensionale. Questi fattori rendono le installazioni Oracle un buon candidato per la migrazione ad Azure Synapse.
Per riepilogare, i suggerimenti per ridurre al minimo l'attività di migrazione del codice SQL da Oracle ad Azure Synapse sono:
Eseguire la migrazione del modello di dati esistente così come è per ridurre al minimo i rischi, il lavoro e il tempo di migrazione, anche se è pianificato un modello di dati diverso, ad esempio un insieme di credenziali dei dati.
Comprendere le differenze tra l'implementazione di Oracle SQL e l'implementazione di Azure Synapse.
Usare i metadati e i log di query dell'implementazione Oracle esistente per valutare l'impatto della modifica dell'ambiente. Pianificare un approccio per attenuare le differenze.
Automatizzare il processo di migrazione per ridurre al minimo i rischi, il lavoro richiesto e il tempo di migrazione. È possibile usare strumenti Microsoft come Servizi Migrazione del database di Azure e SSMA.
Prendere in considerazione l'uso di strumenti e servizi di terze parti per semplificare la migrazione.
Passaggi successivi
Per altre informazioni sugli strumenti Microsoft e di terze parti, vedere l'articolo successivo di questa serie: Strumenti per la migrazione di data warehouse Oracle ad Azure Synapse Analytics.