Sicurezza, accesso e operazioni per le migrazioni di Netezza
Questo articolo è la terza parte di una serie in sette parti che fornisce indicazioni su come eseguire la migrazione da Netezza ad Azure Synapse Analytics. Questo articolo si incentra sulle procedure consigliate per le operazioni di accesso alla sicurezza.
Considerazioni sulla sicurezza
Questo articolo illustra i metodi di connessione per gli ambienti di Netezza legacy esistenti e il modo in cui è possibile eseguirne la migrazione ad Azure Synapse Analytics con un rischio e un impatto sull'utente minimi.
Questo articolo presuppone che sia necessario eseguire la migrazione dei metodi di connessione esistenti e della struttura di utente/ruolo/autorizzazione così come sono. Altrimenti, usare il portale di Azure per creare e gestire un nuovo regime di sicurezza.
Per altre informazioni sulle opzioni di sicurezza di Azure Synapse, vedere il white paper sulla sicurezza.
Connessione e autenticazione
Suggerimento
L'autenticazione sia in Netezza che in Azure Synapse può essere eseguita "nel database" o tramite metodi esterni.
Opzioni di autorizzazione di Netezza
Il sistema IBM Netezza offre diversi metodi di autenticazione per gli utenti del database di Netezza:
Autenticazione locale: gli amministratori di Netezza definiscono gli utenti del database e le relative password usando il comando
CREATE USERo tramite le interfacce amministrative di Netezza. Nell'autenticazione locale usare il sistema Netezza per gestire gli account e le password del database e per aggiungere e rimuovere utenti del database dal sistema. Questo metodo è il metodo di autenticazione predefinito.Autenticazione LDAP: usare un server dei nomi LDAP per eseguire l'autenticazione degli utenti del database e gestire password, attivazioni e disattivazioni dell'account del database. Il sistema Netezza usa un modulo PAM (Pluggable Authentication Module) per eseguire l'autenticazione degli utenti nel server dei nomi LDAP. Microsoft Active Directory è conforme al protocollo LDAP, pertanto può essere considerato come un server LDAP ai fini dell'autenticazione LDAP.
Autenticazione Kerberos: usare un server di distribuzione Kerberos per eseguire l'autenticazione degli utenti del database e gestire password, attivazioni e disattivazioni dell'account del database.
L'autenticazione è un'impostazione a livello di sistema. Gli utenti devono essere autenticati in locale o tramite il metodo LDAP o Kerberos. Se si sceglie l'autenticazione LDAP o Kerberos, creare utenti con autenticazione locale in base all'utente. LDAP e Kerberos non possono essere usati contemporaneamente per eseguire l'autenticazione degli utenti. L'host di Netezza supporta l'autenticazione LDAP o Kerberos solo per gli accessi utente del database, non per gli accessi del sistema operativo nell'host.
Opzioni di autorizzazione di Azure Synapse
Azure Synapse supporta due opzioni di base per la connessione e l'autorizzazione:
Autenticazione SQL: l'autenticazione SQL viene eseguita tramite una connessione di database che include un identificatore del database, un ID utente e una password oltre ad altri parametri facoltativi. Ciò equivale a livello funzionale alle connessioni locali di Netezza.
Autenticazione di Microsoft Entra: con l'autenticazione di Microsoft Entra è possibile gestire centralmente le identità degli utenti del database e altri servizi Microsoft in un'unica posizione centrale. La gestione centrale degli ID consente di gestire gli utenti di Azure Synapse da un unico punto e semplifica la gestione delle autorizzazioni. Microsoft Entra ID può anche supportare le connessioni ai servizi LDAP e Kerberos, ad esempio, Microsoft Entra ID può essere usato per connettersi alle directory LDAP esistenti se devono rimanere attive dopo la migrazione del database.
Utenti, ruoli e autorizzazioni
Panoramica
Suggerimento
La pianificazione generale è essenziale per un progetto di migrazione ottimale.
Sia Netezza che Azure Synapse implementano il controllo di accesso al database tramite una combinazione di utenti, ruoli (gruppi in Netezza) e autorizzazioni. Entrambi usano istruzioni SQL CREATE USER e CREATE ROLE/GROUP standard per definire utenti e ruoli e istruzioni GRANT e REVOKE per assegnare o rimuovere autorizzazioni a tali utenti e/o ruoli.
Suggerimento
È consigliabile eseguire l'automazione dei processi di migrazione per ridurre il tempo trascorso e l'ambito degli errori.
Concettualmente i due database sono simili e potrebbe essere possibile automatizzare la migrazione di ID utente, gruppi e autorizzazioni esistenti in qualche modo. Eseguire la migrazione di tali dati estraendo le informazioni esistenti sull'utente e sul gruppo legacy dalle tabelle del catalogo del sistema Netezza e generando istruzioni CREATE USER e CREATE ROLE equivalenti e corrispondenti da eseguire in Azure Synapse per ricreare la stessa gerarchia utente/ruolo.
Dopo l'estrazione dei dati, usare le tabelle del catalogo di sistema Netezza per generare istruzioni GRANT equivalenti per assegnare le autorizzazioni (dove esiste un'istruzione equivalente). Il diagramma seguente illustra come usare i metadati esistenti per generare il codice SQL necessario.
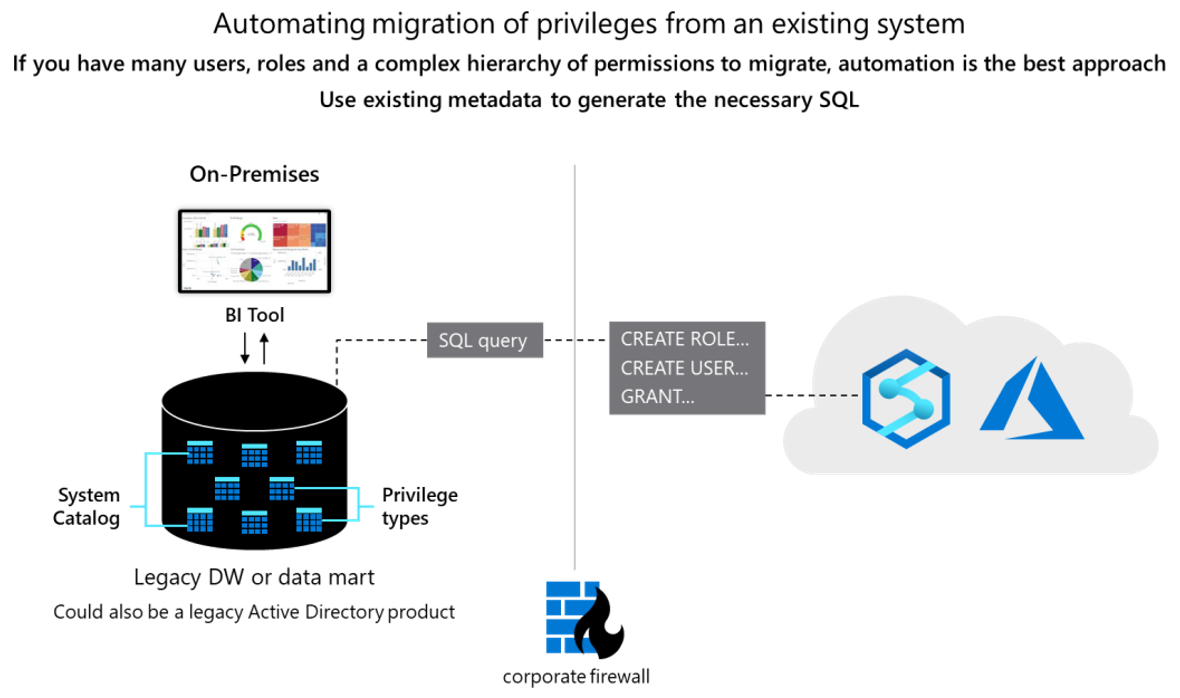
Per altre informazioni, vedere le sezioni seguenti.
Utenti e ruoli
Suggerimento
La migrazione di un data warehouse richiede molto più di semplici tabelle, viste e istruzioni SQL.
Le informazioni sugli utenti e sui gruppi correnti in un sistema Netezza sono contenute nelle viste del catalogo di sistema _v_users e _v_groupusers. Usare l'utilità nzsql o strumenti come gli script Netezza Performance, NzAdmin o Netezza Utility per elencare i privilegi dell'utente. Ad esempio, usare i comandi dpu e dpgu in nzsql per visualizzare utenti o gruppi con le relative autorizzazioni.
Usare o modificare gli script di utilità nz_get_users e nz_get_user_groups per recuperare le stesse informazioni nel formato richiesto.
Eseguire query sulle viste del catalogo di sistema direttamente (se l'utente ha accesso SELECT a tali viste) per ottenere gli elenchi correnti di utenti e ruoli definiti all'interno del sistema. Vedere gli esempi per elencare utenti, gruppi o utenti e i relativi gruppi associati:
-- List of users
SELECT USERNAME FROM _V_USER;
--List of groups
SELECT DISTINCT(GROUPNAME) FROM _V_USERGROUPS;
--List of users and their associated groups
SELECT USERNAME, GROUPNAME FROM _V_GROUPUSERS;
Modificare l'istruzione SELECT di esempio per produrre un set di risultati costituito da una serie di istruzioni CREATE USER e CREATE GROUP includendo il testo appropriato come valore letterale all'interno dell'istruzione SELECT.
Non è possibile recuperare le password esistenti, quindi è necessario implementare uno schema per allocare nuove password iniziali in Azure Synapse.
Autorizzazioni
Suggerimento
Esistono autorizzazioni equivalenti di Azure Synapse per operazioni di database di base, ad esempio DML e DDL.
In un sistema Netezza, la tabella di sistema _t_usrobj_priv contiene i diritti di accesso per utenti e ruoli. Eseguire una query su queste tabelle (se l'utente ha accesso SELECT a tali tabelle) per ottenere gli elenchi correnti dei diritti di accesso definiti all'interno del sistema.
In Netezza le singole autorizzazioni vengono rappresentate come singoli bit all'interno di privilegi di campo o g_privileges. Vedere l'istruzione SQL di esempio nell'articolo sulle autorizzazioni del gruppo di utenti.
Il modo più semplice per ottenere uno script DDL che contiene i comandi GRANT per replicare i privilegi correnti per utenti e gruppi consiste nell'usare gli script dell'utilità Netezza appropriati:
--List of group privileges
nz_ddl_grant_group -usrobj dbname > output_file_dbname;
--List of user privileges
nz_ddl_grant_user -usrobj dbname > output_file_dbname;
Il file di output può essere modificato per produrre uno script che è una serie di istruzioni GRANT per Azure Synapse.
Netezza supporta due classi di diritti di accesso, Amministratore e Oggetto. Per un elenco dei diritti di accesso di Netezza e dei loro equivalenti in Azure Synapse, vedere le tabelle seguenti.
| Privilegio di amministratore | Descrizione | Equivalente di Azure Synapse |
|---|---|---|
| Backup | Consente all'utente di creare backup. L'utente può eseguire i backup. L'utente può eseguire il comando nzbackup. |
1 |
| [Create] Aggregate | Consente all'utente di creare aggregazioni definite dall'utente. L'autorizzazione per operare sulle aggregazioni definite dall'utente esistenti è controllata dai privilegi di tipo oggetto. | CREATE FUNCTION 3 |
| [Create] Database | Consente all'utente di creare database. L'autorizzazione per operare sui database esistenti è controllata dai privilegi di tipo oggetto. | CREATE DATABASE |
| [Create] External Table | Consente all'utente di creare tabelle esterne. L'autorizzazione per operare sulle tabelle esistenti è controllata dai privilegi di tipo oggetto. | CREATE TABLE |
| [Create] Function | Consente all'utente di creare funzioni definite dall'utente. L'autorizzazione per operare sulle funzioni definite dall'utente esistenti è controllata dai privilegi di tipo oggetto. | CREATE FUNCTION |
| [Create] Group | Consente all'utente di creare gruppi. L'autorizzazione per operare sui gruppi esistenti è controllata dai privilegi di tipo oggetto. | CREATE ROLE |
| [Create] Index | Riservato per l'utilizzo nel sistema. Gli utenti non possono creare indici. | CREATE INDEX |
| [Create] Library | Consente all'utente di creare librerie condivise. L'autorizzazione per operare sulle librerie esistenti è controllata dai privilegi di tipo oggetto. | 1 |
| [Create] Materialized View | Consente all'utente di creare viste materializzate. | CREATE VIEW |
| [Create] Procedure | Consente all'utente di creare stored procedure. L'autorizzazione per operare sulle stored procedure esistenti è controllata dai privilegi di tipo oggetto. | CREATE PROCEDURE |
| [Create] Schema | Consente all'utente di creare schemi. L'autorizzazione per operare sugli schemi esistenti è controllata dai privilegi di tipo oggetto. | CREATE SCHEMA |
| [Create] Sequence | Consente all'utente di creare sequenze di database. | 1 |
| [Create] Synonym | Consente all'utente di creare sinonimi. | CREATE SYNONYM |
| [Create] Table | Consente all'utente di creare tabelle. L'autorizzazione per operare sulle tabelle esistenti è controllata dai privilegi di tipo oggetto. | CREATE TABLE |
| [Create] Temp Table | Consente all'utente di creare tabelle temporanee. L'autorizzazione per operare sulle tabelle esistenti è controllata dai privilegi di tipo oggetto. | CREATE TABLE |
| [Create] User | Consente all'utente di creare utenti. L'autorizzazione per operare sugli utenti esistenti è controllata dai privilegi di tipo oggetto. | CREATE USER |
| [Create] View | Consente all'utente di creare viste. L'autorizzazione per operare sulle viste esistenti è controllata dai privilegi di tipo oggetto. | CREATE VIEW |
| [Manage Hardware | Consente all'utente di eseguire le operazioni correlate all'hardware seguenti: visualizzare lo stato dell'hardware, gestire le SPU, gestire la topologia e il mirroring ed eseguire test di diagnostica. L'utente può eseguire questi comandi: nzhw e nzds. | 4 |
| [Manage Security | Consente all'utente di eseguire comandi e operazioni correlate alle opzioni di sicurezza avanzata seguenti, ad esempio: gestione e configurazione di database della cronologia, gestione di oggetti di sicurezza a più livelli e definizione della sicurezza per utenti e gruppi, gestione di archivi chiavi e chiavi del database e archivi chiavi per la firma digitale dei dati di controllo. | 4 |
| [Manage System | Consente all'utente di eseguire le operazioni di gestione seguenti: avvio/arresto/sospensione/ripresa del sistema, interruzione sessioni, visualizzazione della mappa di distribuzione, statistiche di sistema e log. L'utente può usare questi comandi: nzsystem, nzstate, nzstats e nzsession. | 4 |
| Ripristino | Consente all'utente di ripristinare il sistema. L'utente può eseguire il comando nzrestore. | 2 |
| Unfence | Consente all'utente di creare o modificare una funzione definita dall'utente o un'aggregazione da eseguire senza limiti. | 1 |
| Interruzione dei privilegi di tipo oggetto | Descrizione | Equivalente di Azure Synapse |
|---|---|---|
| Interrompi | Consente all'utente di interrompere le sessioni. Si applica a gruppi e utenti. | KILL DATABASE CONNECTION |
| Alter | Consente all'utente di modificare gli attributi dell'oggetto. Si applica a tutti gli oggetti. | ALTER |
| Elimina | Consente all'utente di eliminare righe di tabella. Si applica solo a alle tabelle. | DELETE |
| Goccia | Consente all'utente di rimuovere oggetti. Si applica a tutti i tipi di oggetto. | DROP |
| Execute | Consente all'utente di eseguire funzioni definite dall'utente, aggregazioni definite dall'utente o stored procedure. | EXECUTE |
| GenStats | Consente all'utente di generare statistiche su tabelle o database. L'utente può eseguire il comando GENERATE STATISTICS. | 2 |
| Groom | Consente all'utente di recuperare spazio su disco per le righe eliminate oppure obsolete e di riorganizzare una tabella in base alle chiavi organizzative o di eseguire la migrazione dei dati per le tabelle con più versioni archiviate. | 2 |
| Inserisci | Consente all'utente di inserire righe in una tabella. Si applica solo a alle tabelle. | INSERT |
| List | Consente all'utente di visualizzare un nome di oggetto, in un elenco o in un altro modo. Si applica a tutti gli oggetti. | INSERZIONE |
| Seleziona | Consente all'utente di selezionare righe (o eseguire query su di esse) all'interno di una tabella. Si applica a tabelle e viste. | SELECT |
| Truncate | Consente all'utente di eliminare tutte le righe da una tabella. Si applica solo a alle tabelle. | TRUNCATE |
| Aggiornamento | Consente all'utente di modificare le righe della tabella. Si applica solo alle tabelle. | UPDATE |
Note della tabella:
Non esiste un equivalente diretto per questa funzione in Azure Synapse.
Queste funzioni di Netezza vengono gestite automaticamente in Azure Synapse.
La funzione
CREATE FUNCTIONdi Azure Synapse incorpora la funzionalità di aggregazione di Netezza.Queste funzioni vengono gestite automaticamente dal sistema o tramite il portale di Azure in Azure Synapse. Vedere la sezione successiva sulle considerazioni operative.
Fare riferimento alle autorizzazioni di sicurezza di Azure Synapse Analytics.
Considerazioni operative
Suggerimento
Le attività operative sono necessarie per mantenere efficiente il funzionamento di qualsiasi data warehouse.
Questa sezione illustra come implementare attività operative di Netezza tipiche in Azure Synapse con un rischio e un impatto sugli utenti minimi.
Come per tutti i prodotti del data warehouse, una volta in produzione sono necessarie attività di gestione che vengono svolte per mantenere il sistema in esecuzione in modo efficiente e fornire dati per il monitoraggio e il controllo. Anche l'utilizzo delle risorse e la pianificazione della capacità per una crescita futura rientrano in questa categoria, come il backup/ripristino dei dati.
Le attività di amministrazione di Netezza in genere rientrano in due categorie:
Amministrazione del sistema, che consiste nella gestione di hardware, impostazioni di configurazione, stato del sistema, accesso, spazio su disco, utilizzo, aggiornamenti e altre attività.
Amministrazione del database, che consiste nella gestione di database utente e del relativo contenuto, caricamento dei dati, esecuzione del backup dei dati, ripristino dei dati e controllo dell'accesso ai dati e alle autorizzazioni.
IBM Netezza offre diversi modi o interfacce che è possibile usare per eseguire le varie attività di gestione del sistema e del database:
I comandi di Netezza (comandi
nz*) vengono installati nella directory/nz/kit/binnell'host di Netezza. Per molti comandinz*, è necessario essere in grado di accedere al sistema Netezza per accedere ed eseguire tali comandi. Nella maggior parte dei casi, gli utenti accedono come account utentenzpredefinito, ma è possibile creare altri account utente Linux nel sistema. Alcuni comandi richiedono di specificare un account utente del database, una password e un database per assicurarsi di disporre delle autorizzazioni necessarie per eseguire l'attività.Il kit client dell'interfaccia della riga di comando di Netezza crea un subset dei comandi
nz*che possono essere eseguiti dai sistemi client Windows e UNIX. I comandi client possono anche richiedere di specificare un account utente del database, una password e un database per assicurarsi di disporre delle autorizzazioni di tipo amministrativo e oggetto del database per eseguire l'attività.I comandi SQL supportano attività di amministrazione e query all'interno di una sessione del database SQL. È possibile eseguire i comandi SQL dall'interprete dei comandi nzsql di Netezza o tramite le API SQL, ad esempio ODBC, JDBC e il provider OLE DB. È necessario disporre di un account utente del database per eseguire i comandi SQL con le autorizzazioni appropriate per le query e le attività eseguite.
Lo strumento NzAdmin è un'interfaccia Netezza che viene eseguita nelle workstation client Windows per gestire i sistemi Netezza.
Anche se concettualmente le attività di gestione e operative per data warehouse diversi sono simili, le singole implementazioni possono differire. In generale, i moderni prodotti basati sul cloud, ad esempio Azure Synapse, tendono a incorporare un approccio più automatizzato e "gestito dal sistema" (anziché un approccio più "manuale" nei data warehouse legacy, come Netezza).
Le sezioni seguenti confrontano le opzioni di Netezza e Azure Synapse per varie attività operative.
Attività di manutenzione
Suggerimento
Le attività di manutenzione mantengono efficiente l'operatività di un warehouse di produzione e ottimizzano l'uso di risorse come l'archiviazione.
Nella maggior parte degli ambienti di data warehouse legacy, le normali attività di "manutenzione" richiedono molto tempo. Recuperare spazio di archiviazione su disco rimuovendo le versioni precedenti di righe aggiornate o eliminate o riorganizzando dati, file di log o blocchi di indice per ottenere efficienza (GROOM e VACUUM in Netezza). Anche la raccolta di statistiche è un'attività potenzialmente dispendiosa in termini di tempo, necessaria dopo un inserimento di dati in blocco per fornire a Query Optimizer dati aggiornati su cui basare i piani di esecuzione delle query.
Netezza consiglia di raccogliere le statistiche nel modo seguente:
Raccogliere statistiche sulle tabelle non popolate per configurare l'istogramma di intervalli usato nell'elaborazione interna. Questa raccolta iniziale rende più veloci le raccolte di statistiche successive. Assicurarsi di raccogliere nuovamente le statistiche dopo l'aggiunta dei dati.
Raccogliere le statistiche sulle fasi del prototipo per le tabelle appena popolate.
Raccogliere statistiche sulle fasi di produzione dopo aver apportato una percentuale significativa di modifica alla tabella o alla partizione (~10% delle righe). Per volumi elevati di valori non univoci, ad esempio date o timestamp, può essere vantaggioso raccogliere nuovamente il 7%.
Raccogliere le statistiche sulle fasi di produzione dopo aver creato gli utenti e applicato caricamenti di query reali al database (fino a circa tre mesi di query).
Raccogliere statistiche nelle prime settimane dopo un aggiornamento o una migrazione durante i periodi di basso utilizzo della CPU.
Il database di Netezza contiene molte tabelle di log nel dizionario dei dati che accumulano dati, automaticamente o dopo l'abilitazione di determinate funzionalità. Poiché i dati di log aumentano nel tempo, eliminare le informazioni meno recenti per evitare di usare spazio permanente. Sono disponibili opzioni per automatizzare la manutenzione di questi log.
Suggerimento
Automatizzare e monitorare le attività di manutenzione in Azure.
Azure Synapse offre un'opzione per creare automaticamente le statistiche in modo che possano essere usate in base alle esigenze. Eseguire manualmente la deframmentazione di indici e blocchi di dati, in base a una pianificazione o in modo automatico. L'uso delle funzionalità predefinite native di Azure può ridurre il lavoro richiesto in un esercizio di migrazione.
Monitoraggio e controllo
Suggerimento
Il portale delle prestazioni di Netezza è il metodo consigliato per il monitoraggio e la registrazione per i sistemi Netezza.
Netezza fornisce il portale delle prestazioni per monitorare vari aspetti di uno o più sistemi Netezza, tra cui attività, prestazioni, accodamento e utilizzo delle risorse. Il portale delle prestazioni di Netezza è un'interfaccia utente grafica interattiva che consente agli utenti di eseguire il drill-down in dettagli di basso livello per qualsiasi grafico.
Suggerimento
Il portale di Azure offre un'interfaccia utente per gestire le attività di monitoraggio e controllo per tutti i dati e i processi di Azure.
Analogamente, Azure Synapse offre una ricca esperienza di monitoraggio nel portale di Azure per fornire informazioni dettagliate sul carico di lavoro del data warehouse. Il portale di Azure è lo strumento consigliato per il monitoraggio del data warehouse, in quanto fornisce periodi di conservazione, avvisi, raccomandazioni, grafici personalizzabili, nonché dashboard di metriche e log configurabili.
Il portale consente inoltre l'integrazione con altri servizi di monitoraggio di Azure come Operations Management Suite (OMS) e Monitoraggio di Azure (log) per fornire un'esperienza di monitoraggio olistica non solo per il data warehouse, ma anche per l'intera piattaforma analitica di Azure per un'esperienza di monitoraggio integrata.
Suggerimento
Le metriche di basso livello e a livello di sistema vengono registrate automaticamente in Azure Synapse.
Le statistiche di utilizzo delle risorse per Azure Synapse vengono registrate automaticamente all'interno del sistema. Le metriche per ogni query includono statistiche di utilizzo per CPU, memoria, cache, I/O e un'area di lavoro temporanea, nonché informazioni di connettività come tentativi di connessione non riusciti.
Azure Synapse offre un set di Dynamic Management Views (DMV). Queste viste sono utili durante la risoluzione dei problemi e l'identificazione dei colli di bottiglia nelle prestazioni con il carico di lavoro.
Per altre informazioni, consultare le opzioni di gestione e per le operazioni di Azure Synapse.
Disponibilità elevata e ripristino di emergenza
Le appliance Netezza sono sistemi ridondanti, a tolleranza di errore e sono disponibili diverse opzioni in un sistema Netezza per abilitare la disponibilità elevata e il ripristino di emergenza.
L'aggiunta di IBM Netezza Replication Services per il ripristino di emergenza migliora la tolleranza di errore estendendo la ridondanza tra reti locali e WAN.
IBM Netezza Replication Services protegge dalla perdita di dati sincronizzando i dati in un sistema primario (il nodo primario) con i dati in uno o più nodi di destinazione (subordinati). Questi nodi costituiscono un set di replica.
High-Availability Linux (detto anche Linux-HA) fornisce funzionalità di failover da un host Netezza primario o attivo a un host Netezza secondario o in standby. Il daemon di gestione del cluster principale nella soluzione Linux-HA viene chiamato Heartbeat. Heartbeat controlla gli host e gestisce i controlli di comunicazione e stato dei servizi.
Ogni servizio è una risorsa.
Netezza raggruppa i servizi specifici di Netezza nel gruppo di risorse nps. Quando Heartbeat rileva problemi che implicano una condizione di errore dell'host o una perdita di servizio per gli utenti di Netezza, Heartbeat può avviare un failover nell'host di standby.
Distributed Replicated Block Device (DRBD) è un driver dei dispositivi in blocchi che esegue il mirroring del contenuto dei dispositivi in blocchi (dischi rigidi, partizioni e volumi logici) tra gli host. Netezza usa la replica DRBD solo nelle partizioni /nz e /export/home. Man mano che i nuovi dati vengono scritti nella partizione /nz e nella partizione /export/home nell'host primario, il software DRBD apporta automaticamente le stesse modifiche alla partizione /nz e /export/home dell'host di standby.
Suggerimento
Azure Synapse crea automaticamente snapshot per garantire tempi di ripristino rapidi.
Azure Synapse usa gli snapshot del database per offrire disponibilità elevata del warehouse. Uno snapshot del data warehouse crea un punto di ripristino che è possibile usare per copiare il data warehouse o ripristinarlo a uno stato precedente. Poiché Azure Synapse è un sistema distribuito, uno snapshot del data warehouse è costituito da molti file che si trovano in Archiviazione di Azure. Gli snapshot acquisiscono le modifiche incrementali dai dati archiviati nel data warehouse.
Suggerimento
Usare snapshot definiti dall'utente per definire un punto di ripristino prima degli aggiornamenti delle chiavi.
Suggerimento
Microsoft Azure offre backup automatici in una posizione geografica separata per abilitare il ripristino di emergenza.
Azure Synapse acquisisce automaticamente gli snapshot nell'arco della giornata per creare punti di ripristino che sono disponibili per sette giorni. Non è possibile modificare questo periodo di conservazione. Azure Synapse supporta un obiettivo del punto di ripristino (RPO) di otto ore. È possibile ripristinare un data warehouse nell'area primaria da uno qualsiasi degli snapshot acquisiti negli ultimi sette giorni.
Sono supportati anche i punti di ripristino definiti dall'utente, consentendo l'attivazione manuale degli snapshot per creare punti di ripristino di un data warehouse prima e dopo modifiche di grandi dimensioni. Questa funzionalità garantisce la coerenza logica dei punti di ripristino, offrendo così una protezione dei dati aggiuntiva in caso di eventuali interruzioni del carico di lavoro o di errori dell'utente per ottenere un RPO inferiore a 8 ore.
Oltre agli snapshot descritti in precedenza, Azure Synapse esegue anche come operazione standard un backup geografico una volta al giorno in un data center associato. L'obiettivo del punto di ripristino per un ripristino geografico è di 24 ore. È possibile ripristinare il backup geografico in un server in qualsiasi altra area in cui sia supportato Azure Synapse. Un backup geografico garantisce che un data warehouse possa essere ripristinato nel caso in cui i punti di ripristino nell'area primaria non siano disponibili.
Gestione dei carichi di lavoro
Suggerimento
In un data warehouse di produzione sono in genere presenti carichi di lavoro misti con diverse caratteristiche di utilizzo delle risorse in esecuzione simultaneamente.
Netezza incorpora varie funzionalità per la gestione dei carichi di lavoro:
| Tecnica | Descrizione |
|---|---|
| Regole dell'Utilità di pianificazione | Le regole dell'Utilità di pianificazione influiscono sulla pianificazione dei piani. Ogni regola dell'utilità di pianificazione specifica una condizione o un set di condizioni. Ogni volta che l'utilità di pianificazione riceve un piano, valuta tutte le regole dell'utilità di pianificazione che apportano modifiche ed esegue le azioni appropriate. Ogni volta che l'utilità di pianificazione seleziona un piano per l'esecuzione, valuta tutte le regole dell'utilità di pianificazione di limitazione. Il piano viene eseguito solo se ciò non supera un limite imposto da una regola dell'utilità di pianificazione di limitazione. In caso contrario, il piano resta in attesa. In questo modo è possibile classificare e modificare i piani in modo da influenzare le altre tecniche WLM (SQB, GRA e PQE). |
| Allocazione delle risorse garantita | È possibile assegnare una condivisione minima e una percentuale massima di risorse di sistema totali alle entità denominate gruppi di risorse. L'utilità di pianificazione garantisce che ogni gruppo di risorse riceva le risorse di sistema in proporzione alla condivisione minima. Un gruppo di risorse riceve una quota maggiore di risorse quando altri gruppi di risorse sono inattivi, ma non riceve mai più della percentuale massima configurata. Ogni piano è associato a un gruppo di risorse e le impostazioni di tale gruppo di risorse determinano quale frazione delle risorse di sistema disponibili devono essere rese disponibili per elaborare il piano. |
| Deviazione da query brevi | Le risorse (ovvero gli slot di pianificazione, la memoria e l'accodamento preferenziale) sono riservate a query brevi. Una query breve è una query per cui la stima dei costi è inferiore a un valore massimo specificato (il valore predefinito è due secondi). Con la deviazione da query brevi, le query brevi possono essere eseguite anche quando il sistema sta elaborando altre query più lunghe. |
| Esecuzione di query con priorità | In base alle impostazioni configurate, il sistema assegna una priorità (critica, alta, normale o bassa) a ogni query. La priorità dipende da fattori quali l'utente, il gruppo o la sessione associati alla query. Il sistema può quindi usare la priorità come base per l'allocazione delle risorse. |
Azure Synapse registra automaticamente le statistiche di utilizzo delle risorse. Le metriche includono statistiche di utilizzo per CPU, memoria, cache, I/O e area di lavoro temporanea per ogni query. Azure Synapse registra anche le informazioni di connettività, ad esempio i tentativi di connessione non riusciti.
Suggerimento
Le metriche di basso livello e a livello di sistema vengono registrate automaticamente in Azure.
In Azure Synapse, le classi di risorse sono limiti delle risorse predeterminati che regolano le risorse di calcolo e la concorrenza per l'esecuzione delle query. Le classi di risorse possono agevolare la gestione del carico di lavoro, consentendo di impostare limiti per il numero di query eseguite contemporaneamente e per le risorse di calcolo assegnate a ogni query. È necessario trovare il giusto compromesso tra memoria e concorrenza.
Azure Synapse supporta questi concetti di base relativi alla gestione dei carichi di lavoro:
Classificazione del carico di lavoro: è possibile assegnare una richiesta a un gruppo di carico di lavoro per impostare i livelli di importanza.
Importanza del carico di lavoro: è possibile influire sull'ordine in cui una richiesta ottiene l'accesso alle risorse. Per impostazione predefinita, le query vengono rilasciate dalla coda in base alla modalità first-in, first-out man mano che le risorse diventano disponibili. L'importanza del carico di lavoro consente alle query con priorità maggiore di ricevere immediatamente le risorse indipendentemente dalla coda.
Isolamento del carico di lavoro: è possibile riservare le risorse per un gruppo di carico di lavoro, assegnare un utilizzo massimo e minimo per risorse variabili, limitare le risorse che un gruppo di richieste può utilizzare e impostare un valore di timeout per terminare automaticamente le query con eccessivo tempo di esecuzione.
L'esecuzione di carichi di lavoro misti può causare problemi di risorse nei sistemi sovraccarichi. Uno schema corretto di gestione del carico di lavoro comporta una gestione efficace delle risorse, ne assicura l'utilizzo altamente efficiente e massimizza il ritorno sugli investimenti (ROI). La classificazione del carico di lavoro, l'importanza del carico di lavoro e l'isolamento del carico di lavoro offrono un maggiore controllo sul modo in cui il carico di lavoro usa le risorse di sistema.
La guida alla gestione dei carichi di lavoro descrive le tecniche per analizzare il carico di lavoro, gestire e monitorare l'importanza del carico di lavoro](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) e i passaggi per convertire una classe di risorse in un gruppo di carico di lavoro. Usare il portale di Azure e le query T-SQL in DMV per monitorare il carico di lavoro e garantire che le risorse applicabili vengano usate in modo efficiente. Azure Synapse offre un set di DMV (Dynamic Management Views) per il monitoraggio di tutti gli aspetti della gestione dei carichi di lavoro. Queste viste sono utili durante l'attiva risoluzione dei problemi e l'identificazione dei colli di bottiglia delle prestazioni nel carico di lavoro.
Queste informazioni possono essere usate anche per la pianificazione della capacità, determinando le risorse necessarie per altri utenti o carichi di lavoro dell'applicazione. Questo vale anche per la pianificazione di aumento/riduzione delle prestazioni per le risorse di calcolo per il supporto conveniente dei carichi di lavoro "di picco", ad esempio carichi di lavoro con picchi temporanei e intensi di attività seguiti da periodi di attività poco frequenti.
Per altre informazioni sulla gestione dei carichi di lavoro in Azure Synapse, vedere Gestione del carico di lavoro con le classi di risorse.
Ridimensionare le prestazioni
Suggerimento
Un vantaggio importante di Azure è la possibilità di aumentare e ridurre in modo indipendente le prestazioni delle risorse di calcolo su richiesta per gestire carichi di lavoro di picco in modo economicamente conveniente.
L'architettura di Azure Synapse separa le risorse di archiviazione e calcolo consentendo di eseguire il dimensionamento per ognuna in modo indipendente. Pertanto, è possibile dimensionare le risorse di calcolo per soddisfare le richieste di prestazioni, a prescindere dalla quantità di dati. È anche possibile sospendere e riprendere le risorse di calcolo. Un vantaggio naturale di questa architettura è che la fatturazione per calcolo e archiviazione è separata. Se un data warehouse non è in uso, è possibile risparmiare sui costi di calcolo sospendo il calcolo.
Le risorse di calcolo possono essere dimensionate aumentandone o riducendone le prestazioni modificando l'impostazione delle unità del data warehouse per il data warehouse. Le prestazioni di caricamento e relative alle query aumentano in modo lineare man mano che si aggiungono più unità di data warehouse.
L'aggiunta di più nodi di calcolo aggiunge maggiore potenza di calcolo e possibilità di sfruttare un maggior numero di elaborazioni parallele. Con l'aumento del numero dei nodi di calcolo si riduce il numero di distribuzioni per ogni nodo di calcolo, con un conseguente incremento della potenza di calcolo e dell'elaborazione parallela per le query. In modo analogo, la diminuzione delle unità di data warehouse riduce il numero di nodi di calcolo e di conseguenza le risorse di calcolo per le query.
Passaggi successivi
Per altre informazioni sulla visualizzazione e la creazione di report, vedere l'articolo successivo di questa serie: Visualizzazione e creazione di report per le migrazioni di Netezza.