Database Lake
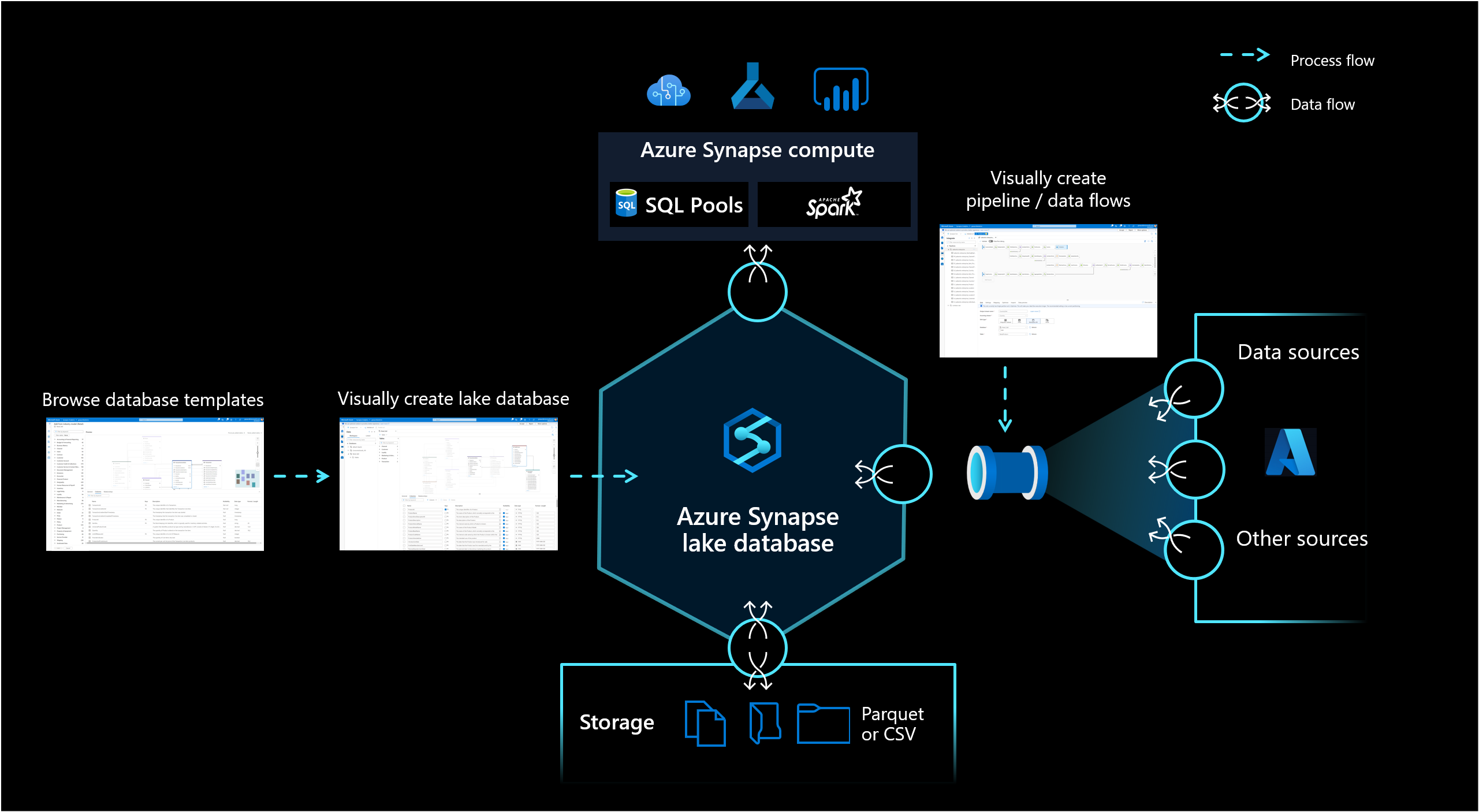
Il database Lake in Azure Synapse Analytics consente ai clienti di unire la progettazione del database, le informazioni meta sui dati archiviati e la possibilità di descrivere come e dove archiviarli. Il database Lake risolve la sfida dei data lake odierni in cui è difficile comprendere come sono strutturati i dati.
Progettazione database
La nuova finestra di progettazione di database in Synapse Studio offre la possibilità di creare un modello di dati per il database Lake e aggiungervi altre informazioni. È possibile descrivere ogni entità e attributo per fornire altre informazioni sul modello, che non solo contiene entità, ma anche relazioni. In particolare, l'impossibilità di modellare le relazioni è stata una sfida per l'interazione sul data lake. Questa sfida è ora affrontata con una finestra di progettazione integrata che offre possibilità disponibili nei database ma non nel lake. Inoltre, la possibilità di aggiungere descrizioni e possibili valori demo al modello consente alle persone che interagiscono con esso in futuro di avere informazioni ove sono necessarie così da consentire una migliore comprensione dei dati.
Nota
La dimensione massima dei metadati in un database Lake è di 10 GB. Il tentativo di pubblicare o aggiornare un modello con dimensioni superiori a 10 GB avrà esito negativo. Per risolvere questo problema, ridurre le dimensioni del modello rimuovendo tabelle e colonne. Prendere in considerazione la suddivisione di modelli di grandi dimensioni in più database Lake per evitare questo limite.
Archiviazione di dati
I database Lake usano un data lake nell'account di archiviazione di Azure per archiviare i dati del database. I dati possono essere archiviati in formato Parquet, Delta o CSV e è possibile usare impostazioni diverse per ottimizzare l'archiviazione. Ogni database Lake usa un servizio collegato per definire il percorso della cartella dati radice. Per ogni entità, cartelle separate vengono create per impostazione predefinita all'interno di questa cartella di database nel data lake. Per impostazione predefinita, tutte le tabelle all'interno di un database Lake usano lo stesso formato; tuttavia, è possibile modificare i formati e la posizione dei dati per ogni entità, se necessario.
Nota
La pubblicazione di un database Lake non crea alcuna delle strutture o degli schemi sottostanti necessari per eseguire query sui dati in Spark o SQL. Dopo la pubblicazione, caricare i dati nel database Lake usando le pipeline per iniziare a eseguire query.
Attualmente, il supporto del formato Delta per i database Lake non è supportato in Synapse Studio.
La sincronizzazione degli oggetti di database Lake tra la risorsa di archiviazione e Synapse è unidirezionale. Assicurarsi di eseguire la creazione o modifica dello schema degli oggetti di database Lake usando la finestra di progettazione di database in Synapse Studio. Se invece si apportano tali modifiche da Spark o direttamente nell'archiviazione, le definizioni dei database Lake non verranno sincronizzate. In questo caso, è possibile che nella finestra di progettazione database vengano visualizzate le definizioni di database Lake precedenti. Sarà necessario replicare e pubblicare tali modifiche nella finestra di progettazione del database per sincronizzare nuovamente i database Lake.
Calcolo del database
Il database Lake viene esposto nel pool SQL serverless di Synapse SQL e Apache Spark che offre agli utenti la possibilità di separare l'archiviazione dal calcolo. I metadati associati al database lake semplificano l'uso di motori di calcolo diversi non solo per offrire un'esperienza integrata, ma anche usare informazioni aggiuntive (ad esempio relazioni) che non erano originariamente supportate nel data lake.
Contenuto correlato
Continuare a esplorare le funzionalità della finestra di progettazione database usando i collegamenti seguenti.