Ottenere la ridondanza geografica per i processi di Analisi di flusso di Azure
Analisi di flusso di Azure non fornisce il failover geografico automatico, ma è possibile ottenere la ridondanza geografica tramite la distribuzione di processi di Analisi di flusso identici in più aree di Azure. Ogni processo si connette a un input locale e a origini di output locali. È responsabilità dell'applicazione inviare entrambi i dati di input nei due input regionali e riconciliare tra i due output regionali. I processi di Analisi di flusso sono due entità separate.
Il diagramma seguente illustra una distribuzione del processo di Analisi di flusso con ridondanza geografica di esempio con input dell'hub eventi e output del database di Azure.
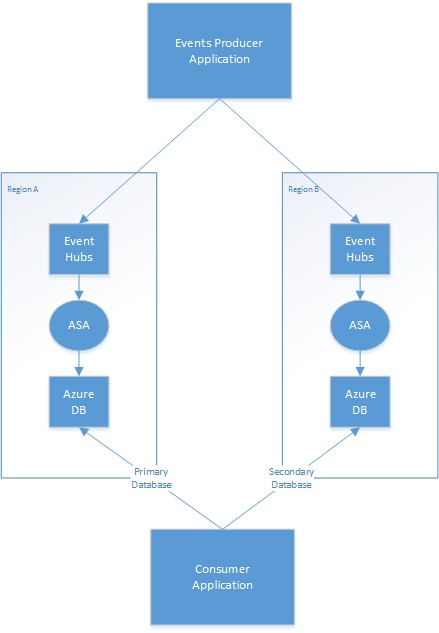
Strategia primaria/secondaria
L'applicazione deve gestire il database di output dell'area considerato primario e considerato secondario. In un errore di area primaria, l'applicazione passa al database secondario e avvia la lettura degli aggiornamenti da tale database. Il meccanismo effettivo che consente di ridurre al minimo le letture duplicate dipende dall'applicazione. È possibile semplificare questo processo scrivendo informazioni aggiuntive all'output. Ad esempio, è possibile aggiungere un timestamp o un ID sequenza a ogni output per rendere ignorate le righe duplicate un'operazione semplice. Una volta ripristinata l'area primaria, viene recuperata con il database secondario usando meccanismi simili.
Anche se diversi tipi di input e output consentono diverse opzioni di replica geografica, è consigliabile usare il modello descritto in questo articolo per ottenere la ridondanza geografica perché offre flessibilità e controllo per i produttori di eventi e i consumer di eventi.