Esercitazione: Acquisire i dati di Hub eventi in formato Parquet e analizzare con Azure Synapse Analytics
Questa esercitazione illustra come usare Analisi di flusso senza editor di codice per creare un processo che acquisisce i dati di Hub eventi in Azure Data Lake Storage Gen2 nel formato parquet.
In questa esercitazione apprenderai a:
- Distribuire un generatore di eventi che invia eventi di esempio a un hub eventi
- Creare un processo di Analisi di flusso usando l'editor di codice senza editor di codice
- Esaminare i dati di input e lo schema
- Configurare Azure Data Lake Storage Gen2 in cui verranno acquisiti i dati dell'hub eventi
- Eseguire il processo di Analisi di flusso
- Usare Azure Synapse Analytics per eseguire query sui file parquet
Prerequisiti
Prima di iniziare, assicurarsi di aver completato i passaggi seguenti:
- Se non hai una sottoscrizione di Azure, crea un account gratuito.
- Distribuire l'app generatore di eventi TollApp in Azure. Impostare il parametro 'interval' su 1 e usare un nuovo gruppo di risorse per questo passaggio.
- Creare un'area di lavoro di Azure Synapse Analytics con un account Data Lake Storage Gen2.
Usare nessun editor di codice per creare un processo di Analisi di flusso
Individuare il gruppo di risorse in cui è stato distribuito il generatore di eventi TollApp.
Selezionare lo spazio dei nomi Hub eventi di Azure. Potrebbe essere necessario aprirlo in una scheda separata o in una finestra.
Nella pagina Spazio dei nomi di Hub eventi selezionare Hub eventi in Entità nel menu a sinistra.
Selezionare l'istanza
entrystream.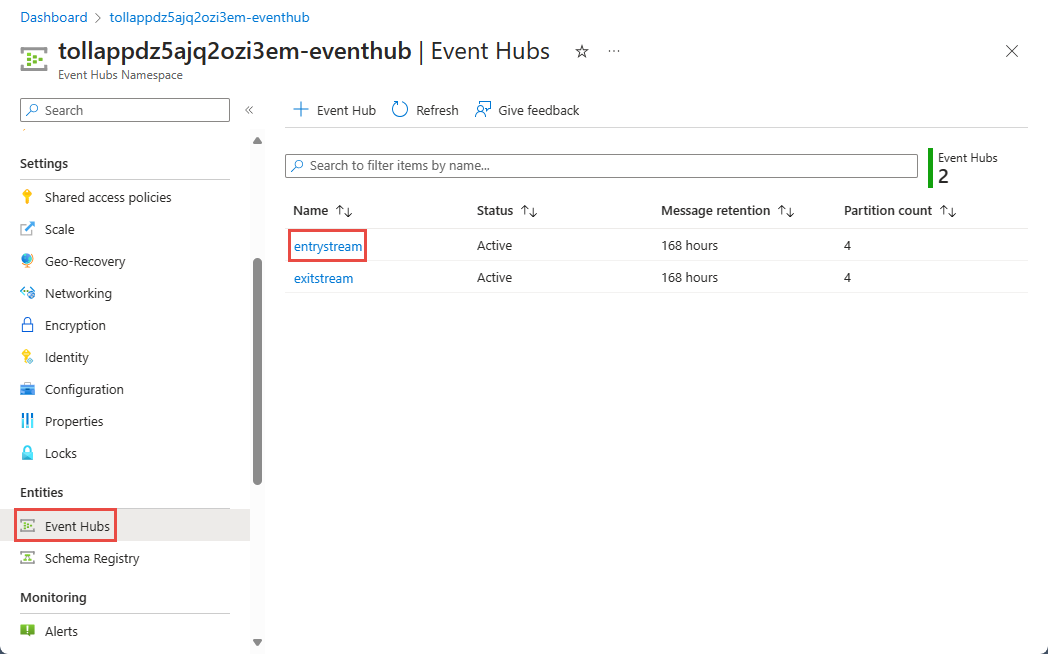
Nella pagina dell'istanza di Hub eventi selezionare Elabora dati nella sezione Funzionalità del menu a sinistra.
Selezionare Avvia nel riquadro Acquisisci dati in ADLS Gen2 nel riquadro Formato Parquet.
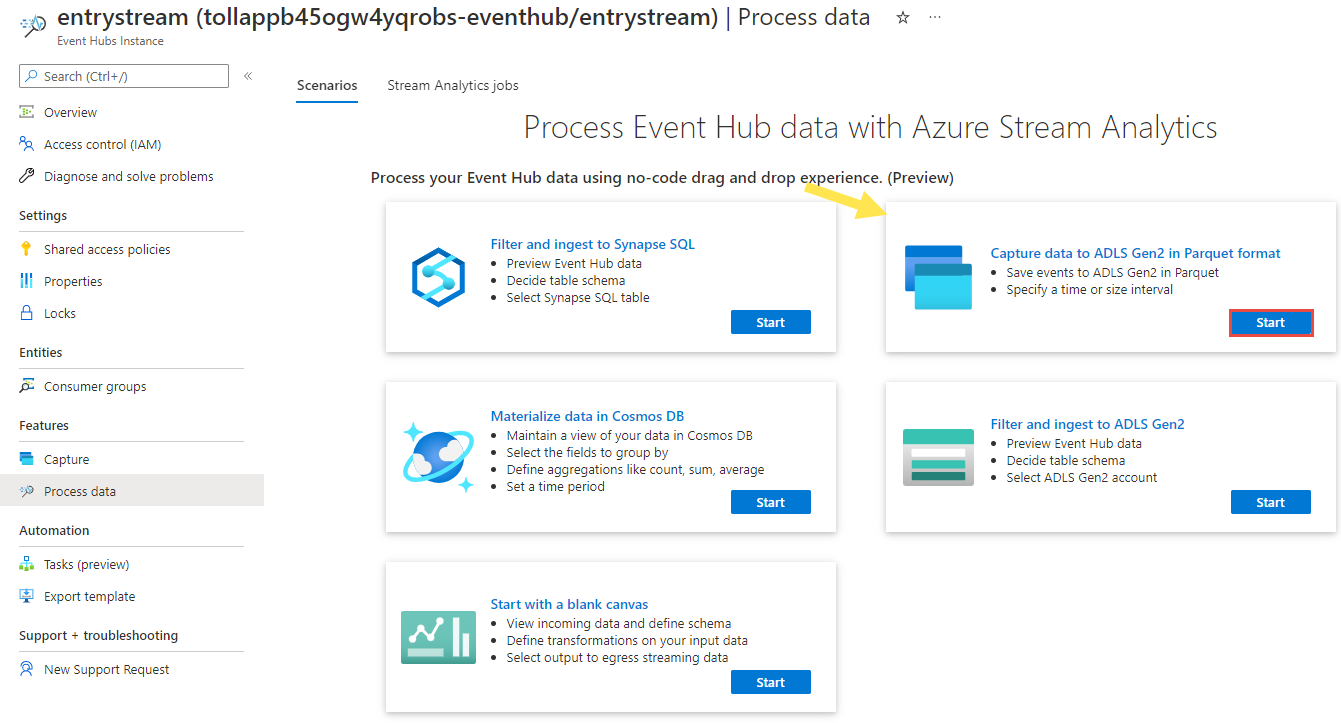
Assegnare un nome al processo
parquetcapturee selezionare Crea.
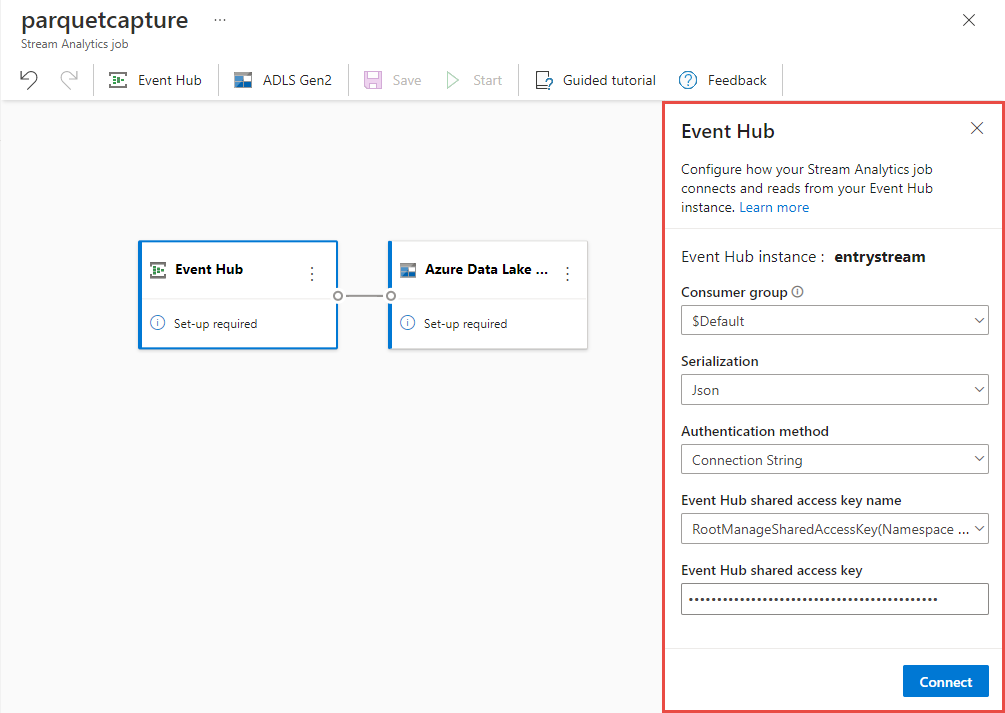
Nella pagina di configurazione dell'hub eventi seguire questa procedura:
In Gruppo consumer selezionare Usa esistente.
Verificare che
$Defaultsia selezionato il gruppo di consumer.Verificare che serializzazione sia impostata su JSON.
Verificare che il metodo di autenticazione sia impostato su Stringa di connessione.
Verificare che il nome della chiave di accesso condiviso dell'hub eventi sia impostato su RootManageSharedAccessKey.
Selezionare Connetti nella parte inferiore della finestra.
Entro pochi secondi verranno visualizzati i dati di input di esempio e lo schema. È possibile scegliere di eliminare campi, rinominare i campi o modificare il tipo di dati.
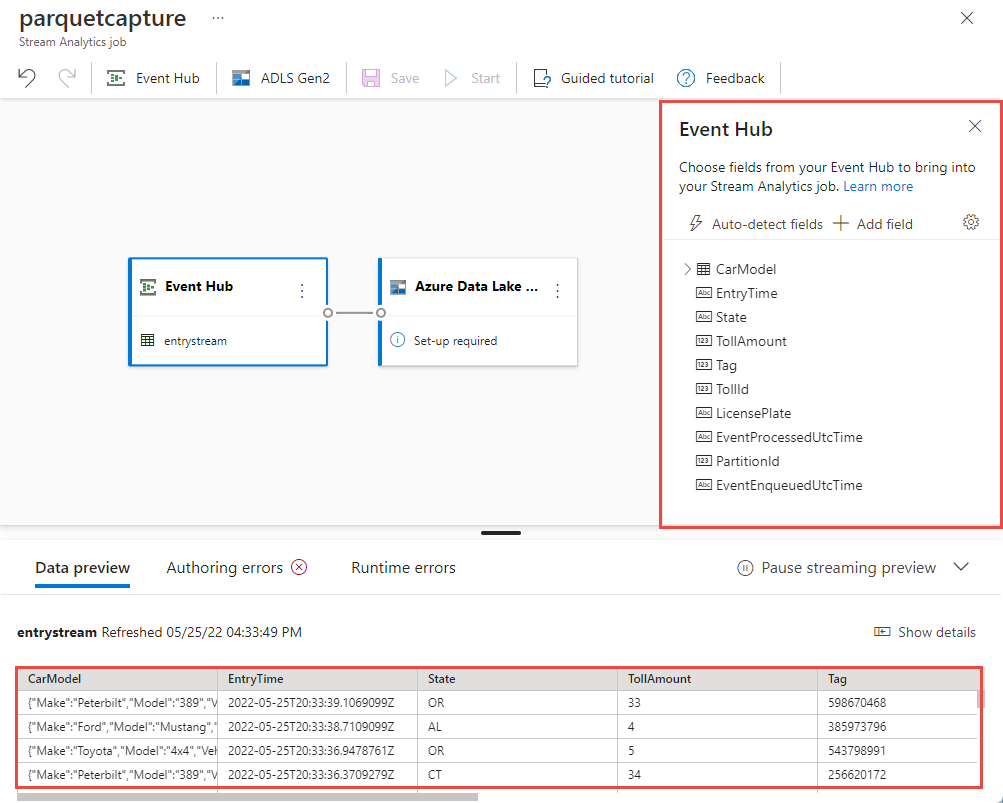
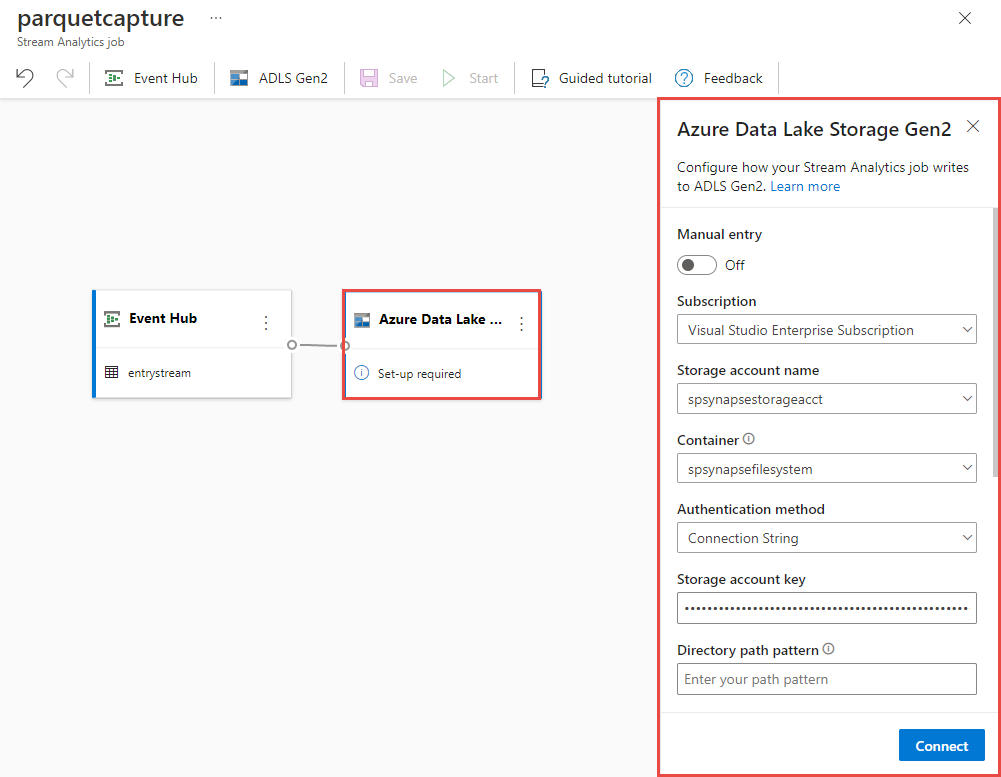
Selezionare il riquadro azure Data Lake Storage Gen2 nell'area di disegno e configurarlo specificando
Sottoscrizione in cui si trova l'account Azure Data Lake Gen2
Nome dell'account di archiviazione, che deve essere lo stesso account ADLS Gen2 usato con l'area di lavoro di Azure Synapse Analytics eseguita nella sezione Prerequisiti.
Contenitore in cui verranno creati i file Parquet.
Per Percorso tabella Delta specificare un nome per la tabella.
Modello di data e ora come valore predefinito aaaa-mm-gg e HH.
Seleziona Connetti
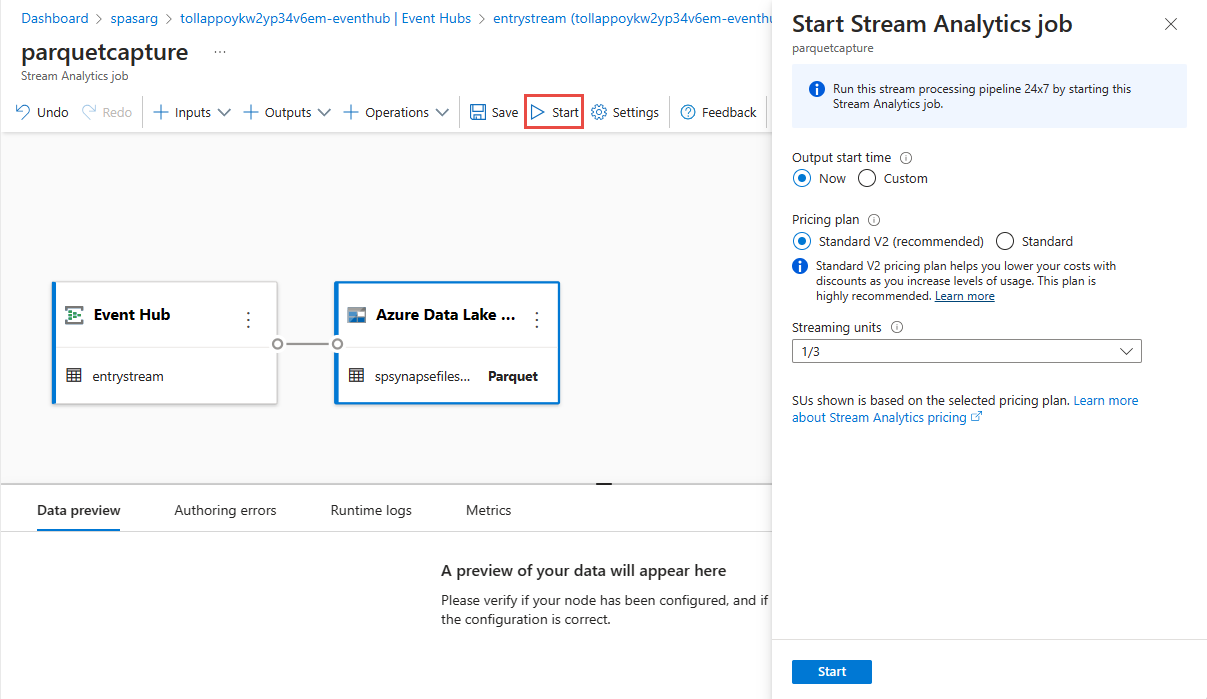
Selezionare Salva nella barra multifunzione superiore per salvare il processo e quindi selezionare Avvia per eseguire il processo. Dopo aver avviato il processo, selezionare X nell'angolo destro per chiudere la pagina del processo di Analisi di flusso.
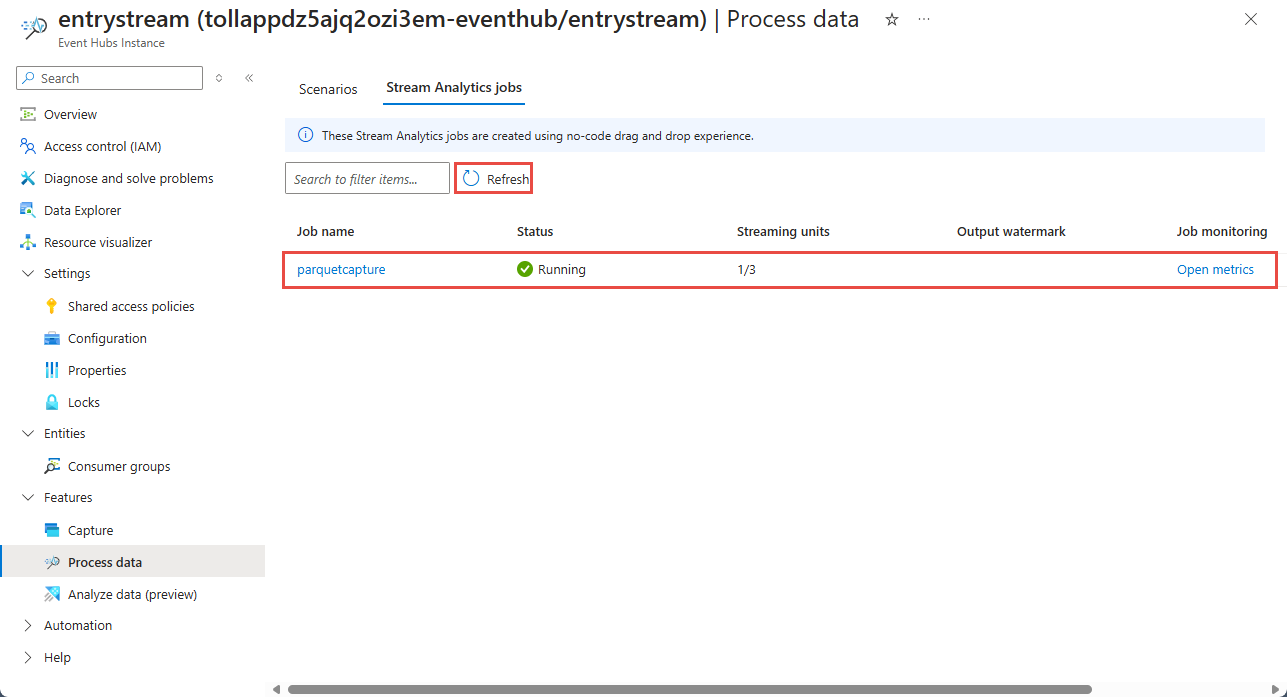
Verrà quindi visualizzato un elenco di tutti i processi di Analisi di flusso creati usando l'editor di codice no. E entro due minuti, il processo passerà a uno stato In esecuzione . Selezionare il pulsante Aggiorna nella pagina per visualizzare lo stato che cambia da Creato -> Avvio -> In esecuzione.








Visualizzare l'output nell'account Azure Data Lake Storage Gen2
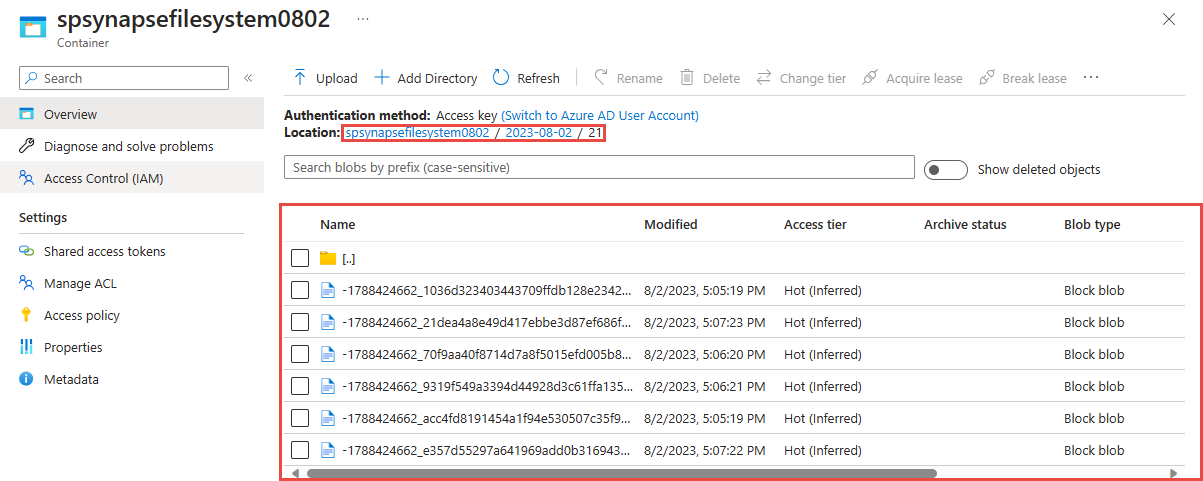
Individuare l'account Azure Data Lake Storage Gen2 usato nel passaggio precedente.
Selezionare il contenitore usato nel passaggio precedente. Nella cartella specificata in precedenza verranno visualizzati i file parquet creati.

Eseguire query sui dati acquisiti in formato Parquet con Azure Synapse Analytics
Eseguire query con Azure Synapse Spark
Individuare l'area di lavoro di Azure Synapse Analytics e aprire Synapse Studio.
Creare un pool di Apache Spark serverless nell'area di lavoro, se non ne esiste già uno.
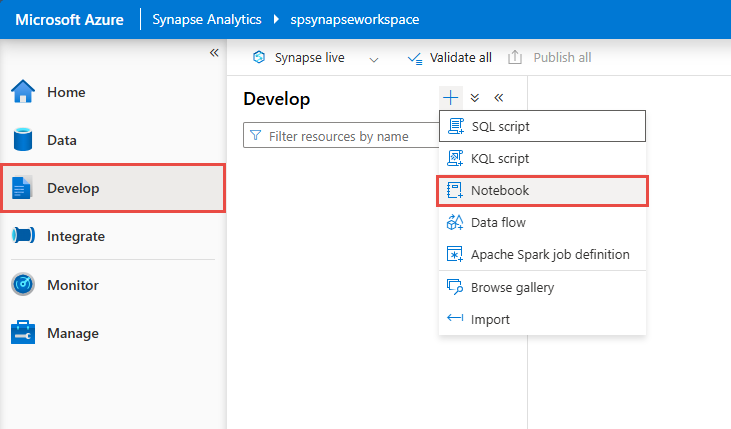
In Synapse Studio passare all'hub Sviluppo e creare un nuovo notebook.
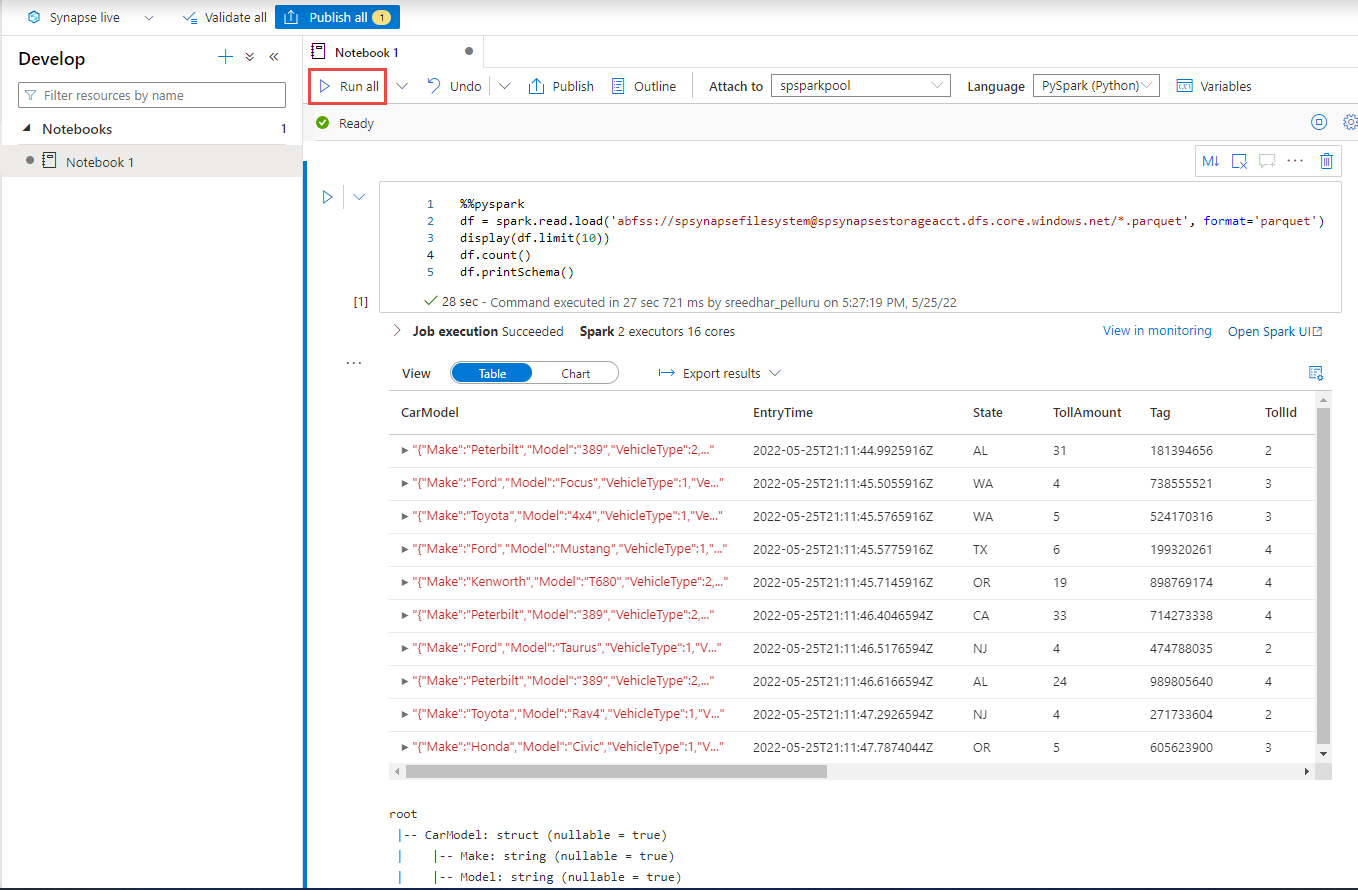
Creare una nuova cella di codice e incollare il codice seguente in tale cella. Sostituire contenitore e adlsname con il nome del contenitore e dell'account ADLS Gen2 usato nel passaggio precedente.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Per Collega a sulla barra degli strumenti, selezionare il pool di Spark dall'elenco a discesa.
Selezionare Esegui tutto per visualizzare i risultati

Eseguire query con Sql serverless di Azure Synapse
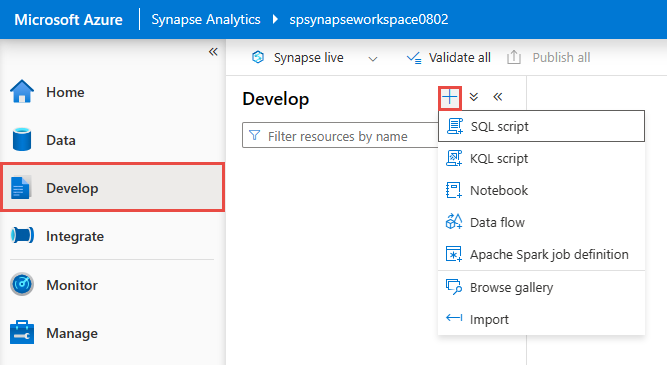
Nell'hub Sviluppo creare un nuovo script SQL.
Incollare lo script seguente ed eseguirlo usando l'endpoint SQL serverless predefinito . Sostituire contenitore e adlsname con il nome del contenitore e dell'account ADLS Gen2 usato nel passaggio precedente.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]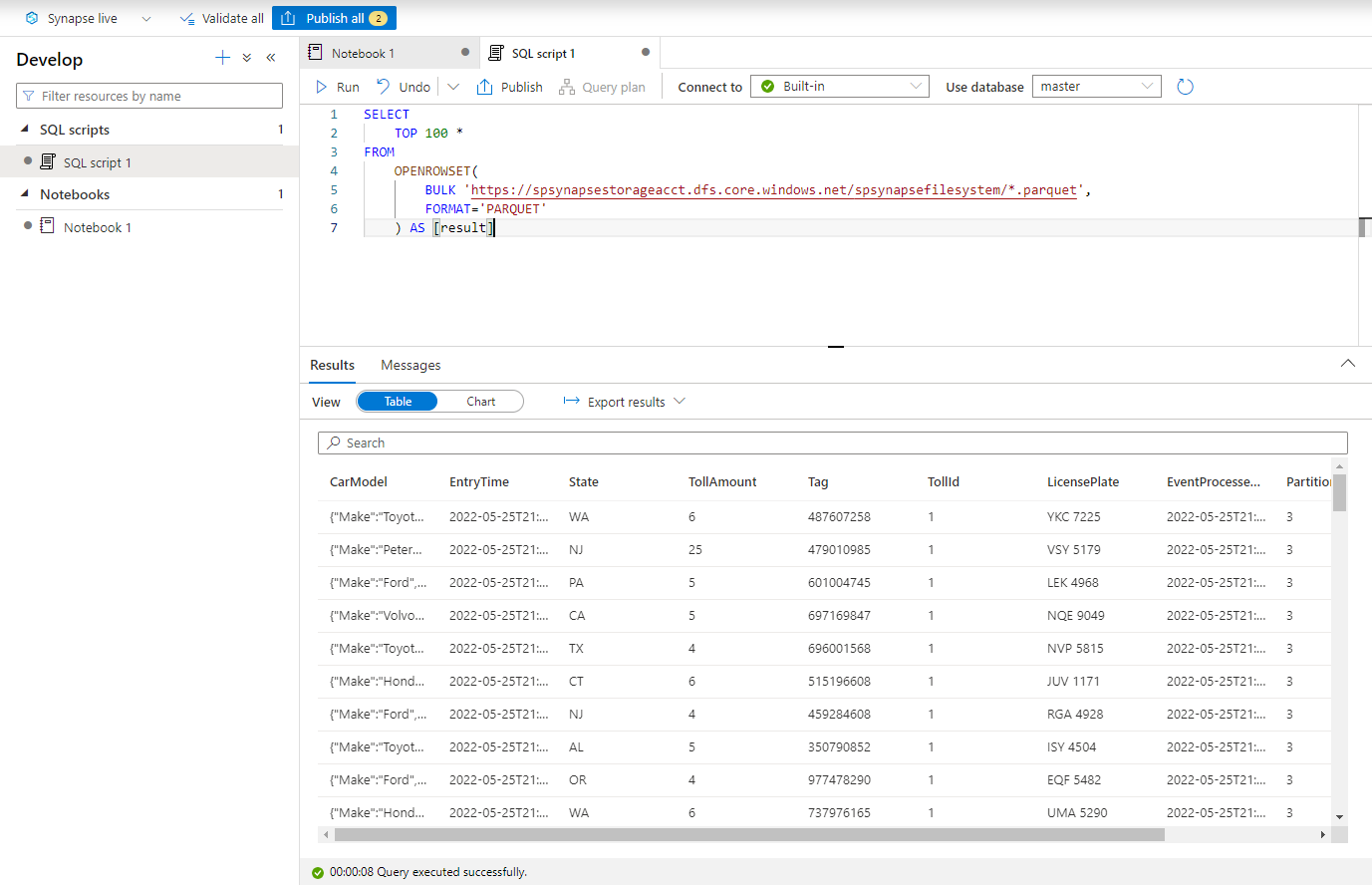

Pulire le risorse
- Individuare l'istanza di Hub eventi e visualizzare l'elenco dei processi di Analisi di flusso nella sezione Elabora dati . Arrestare tutti i processi in esecuzione.
- Passare al gruppo di risorse usato durante la distribuzione del generatore di eventi TollApp.
- Selezionare Elimina gruppo di risorse. Digitare il nome del gruppo di attività per confermare l'eliminazione.
Passaggi successivi
In questa esercitazione si è appreso come creare un processo di Analisi di flusso usando l'editor di codice per acquisire flussi di dati di Hub eventi in formato Parquet. È stato quindi usato Azure Synapse Analytics per eseguire query sui file parquet usando Sia Synapse Spark che Synapse SQL.