Modellazione di relazioni
Questo articolo illustra il processo di modellazione per semplificare la progettazione di soluzioni di archiviazione tabelle di Azure.
La compilazione di modelli di dominio è un passaggio chiave della progettazione di sistemi complessi. Il processo di modellazione in genere viene usato per identificare le entità e le relazioni tra di esse, per poter comprendere il dominio aziendale e informare la progettazione del sistema. Questa sezione illustra come sia possibile convertire alcuni tipi comuni di relazione presenti nei modelli di dominio in progettazioni per il servizio tabelle. Il processo di mapping da un modello di dati logico a un modello di dati fisico basato su NoSQL è diverso da quello usato quando si progetta un database relazionale. La progettazione di database relazionali presuppone in genere un processo di normalizzazione dei dati ottimizzato per ridurre al minimo la ridondanza, oltre a una funzionalità di query dichiarativa che astrae l'implementazione per il funzionamento del database.
Relazioni uno-a-molti
Le relazioni uno a molti tra gli oggetti del dominio aziendale sono frequenti: ad esempio, un reparto ha più dipendenti. Esistono modi diversi per implementare le relazioni uno a molti nel servizio tabelle, ciascuno dei quali presenta pro e contro che potrebbero essere pertinenti a un particolare scenario.
Si consideri l'esempio di una grande società multi-nazionale/regionale con decine di migliaia di reparti ed entità dipendenti in cui ogni reparto ha molti dipendenti e ogni dipendente come associato a un reparto specifico. Un approccio prevede l'archiviazione di entità reparto e dipendente separate, come queste:

Questo esempio illustra una relazione uno a molti implicita tra i tipi basata sui valori PartitionKey . Ogni reparto può avere più dipendenti.
Questo esempio mostra anche un'entità reparto e le relative entità dipendente nella stessa partizione. È possibile scegliere di usare partizioni, tabelle o anche account di archiviazione diversi per ogni tipo di entità.
Un approccio alternativo prevede la denormalizzazione dei dati e l'archiviazione delle sole entità dipendente con i dati reparto denormalizzati, come illustrato nell'esempio seguente. In questo particolare scenario, l'approccio denormalizzato non sarà quello migliore se si deve essere in grado di cambiare i dettagli di un responsabile di reparto perché, per questa operazione, sarà necessario aggiornare ogni dipendente del reparto.
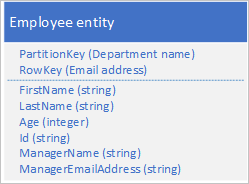
Per ulteriori informazioni, vedere il Modello di denormalizzazione più avanti in questa guida.
La tabella seguente riepiloga i vantaggi e gli svantaggi di ogni approccio descritto sopra per l'archiviazione delle entità dipendente e reparto con una relazione uno a molti. Si consiglia inoltre di considerare la frequenza con cui si prevede di eseguire le diverse operazioni: una progettazione che include un'operazione dal costo elevato può essere accettabile se l'operazione non viene eseguita spesso.
| Approccio | Vantaggi | Svantaggi |
|---|---|---|
| Tipi di entità distinti, stessa partizione, stessa tabella |
|
|
| Tipi di entità distinti, partizioni o tabelle o account di archiviazione diversi |
|
|
| Denormalizzazione in un solo tipo di entità |
|
|
*Per altre informazioni, vedere Transazioni del gruppo di entità
Per scegliere tra queste opzioni e stabilire quali siano i vantaggi e gli svantaggi più importanti, è necessario considerare gli scenari specifici dell'applicazione. Ad esempio, ogni quanto si modificano le entità reparto, se tutte le query dei dipendenti richiedono informazioni aggiuntive sul reparto, quanto si è vicini ai limiti di scalabilità nelle partizioni o nell'account di archiviazione.
Relazioni uno a uno
I modelli di dominio possono includere relazioni uno a uno tra le entità. Se è necessario implementare una relazione uno a uno nel servizio tabelle, è necessario scegliere anche come collegare le due entità correlate quando è necessario recuperarle entrambe. Questo collegamento può essere implicito, ovvero basato su una convenzione nei valori chiave, o esplicito, ovvero basato sull'archiviazione di un collegamento all'entità correlata, sotto forma di valori PartitionKey e RowKey in ogni entità. Per informazioni utili a stabilire se archiviare le entità correlate nella stessa partizione, vedere la sezione Relazioni uno a molti.
Esistono anche alcune considerazioni sull'implementazione che potrebbero far decidere di implementare le relazioni uno a uno nel servizio tabelle:
- Gestione di entità di grandi dimensioni (per altre informazioni, vedere Modello di entità di grandi dimensioni).
- Implementazione di controlli di accesso. Per altre informazioni, vedere Controllo dell'accesso con le firme di accesso condiviso.
Join nel client
Anche se esistono alcuni modi per modellare le relazioni nel servizio tabelle, è bene non dimenticare che i due principali motivi per usare il servizio tabelle sono la scalabilità e le prestazioni. Se ci si accorge che si stanno modellando troppe relazioni che compromettono le prestazioni e la scalabilità della soluzione, è consigliabile chiedersi se sia necessario compilare tutte le relazioni tra i dati nella progettazione tabelle. È possibile semplificare la progettazione e migliorare la scalabilità e le prestazioni della soluzione permettendo all'applicazione client di eseguire i join necessari.
Ad esempio, se si dispone di tabelle di piccole dimensioni che contengono dati che non cambiano spesso, è possibile recuperare i dati una sola volta e memorizzarli nella cache del client. Questo consente di evitare round trip ripetuti per il recupero degli stessi dati. Negli esempi esaminati in questa guida, il set di reparti di una piccola organizzazione sarà probabilmente di dimensioni ridotte e cambierà raramente. Si tratta di un caso ideale di dati che l'applicazione client può scaricare una sola volta e memorizzare nella cache come dati di ricerca.
Relazioni di ereditarietà
Se l'applicazione client usa un set di classi che fanno parte di una relazione di ereditarietà per rappresentare entità aziendali, è possibile rendere facilmente le entità persistenti nel servizio tabelle. Ad esempio, nell'applicazione client potrebbe essere definito il set di classi seguente, dove Person è una classe astratta.
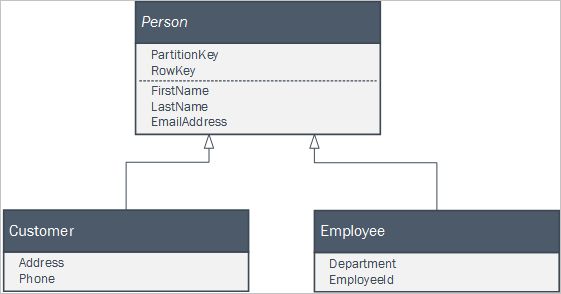
È possibile rendere persistenti le istanze delle due classi concrete nel servizio tabelle usando una singola tabella Persone con entità simili alle seguenti:

Per altre informazioni sull'uso di più tipi di entità nella stessa tabella nel codice del client, vedere la sezione Uso di tipi di entità eterogenei più avanti in questa guida. In questa sezione sono disponibili esempi su come riconoscere il tipo di entità nel codice del client.