Ottimizzare le prestazioni della condivisione file quando si accede a directory di grandi dimensioni dai client Linux
Questo articolo fornisce consigli per l'uso di directory che contengono un numero elevato di file. In genere è consigliabile ridurre il numero di file in una singola directory distribuendo i file su più directory. Tuttavia, esistono situazioni in cui non è possibile evitare directory di grandi dimensioni. Quando si utilizzano directory di grandi dimensioni nelle condivisioni file di Azure montate nei client Linux, prendere in considerazione i suggerimenti seguenti.
Si applica a
| Tipo di condivisione file | SMB | NFS |
|---|---|---|
| Condivisioni file Standard (GPv2), archiviazione con ridondanza locale/archiviazione con ridondanza della zona | ||
| Condivisioni file Standard (GPv2), archiviazione con ridondanza geografica/archiviazione con ridondanza geografica della zona | ||
| Condivisioni file Premium (FileStorage), archiviazione con ridondanza locale/archiviazione con ridondanza della zona |
Opzioni di montaggio consigliate
Le opzioni di montaggio seguenti sono specifiche dell'enumerazione e possono ridurre la latenza quando si utilizzano directory di grandi dimensioni.
actimeo
Specificando actimeo imposta tutti gli acregminoggetti , acregmax, acdirmine acdirmax sullo stesso valore. Se actimeo non viene specificato, il client usa le impostazioni predefinite per ognuna di queste opzioni.
È consigliabile impostare actimeo tra 30 e 60 secondi quando si utilizzano directory di grandi dimensioni. L'impostazione di un valore in questo intervallo rende gli attributi validi per un periodo di tempo più lungo nella cache degli attributi del client, consentendo alle operazioni di ottenere gli attributi di file dalla cache anziché recuperarli in rete. Ciò può ridurre la latenza nelle situazioni in cui gli attributi memorizzati nella cache scadono mentre l'operazione è ancora in esecuzione.
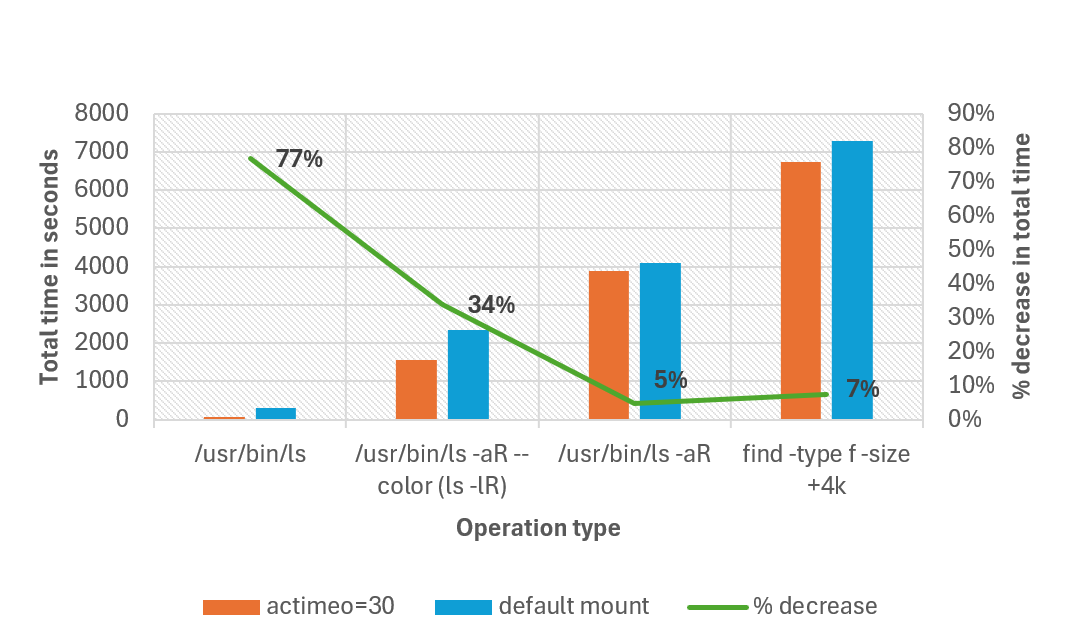
Il grafico seguente confronta il tempo totale necessario per completare operazioni diverse con montaggio predefinito e impostando un actimeo valore pari a 30 per un carico di lavoro con 1 milione di file in una singola directory. Nel test, il tempo totale di completamento è stato ridotto del 77% per alcune operazioni. Tutte le operazioni sono state eseguite con ls non allineati.
nconnect
Nconnect è un'opzione di montaggio lato client che consente di usare più connessioni TCP tra il client e il servizio File Premium di Azure per NFSv4.1. È consigliabile impostare l'impostazione ottimale di nconnect=4 per ridurre la latenza e migliorare le prestazioni. Nconnect può essere particolarmente utile per i carichi di lavoro che usano operazioni di I/O asincrone o sincrone da più thread. Altre informazioni.
Comandi e operazioni
Il modo in cui vengono specificati i comandi e le operazioni può influire anche sulle prestazioni. Elencare tutti i file in una directory di grandi dimensioni usando il ls comando è un buon esempio.
Nota
Alcune operazioni come ls, finde du richiedono sia nomi di file che attributi di file, quindi combinano enumerazioni di directory (per ottenere le voci) con uno stato per ogni voce (per ottenere gli attributi). È consigliabile usare un valore più alto per actimeo nei punti di montaggio in cui è probabile che si eseguano questi comandi.
Usare ls nonliased
In alcune distribuzioni linux, la shell imposta automaticamente le opzioni predefinite per il ls comando, ls --color=autoad esempio . Questo cambia il funzionamento ls in rete e aggiunge altre operazioni all'esecuzione ls . Per evitare una riduzione delle prestazioni, è consigliabile usare ls nonliased. È possibile eseguire questa operazione in tre modi:
Rimuovere l'alias usando il comando
unalias ls. Si tratta solo di una soluzione temporanea per la sessione corrente.Per una modifica permanente, è possibile modificare l'alias
lsnel file dell'utentebashrc/bash_aliases. In Ubuntu modificare~/.bashrcper rimuovere l'alias perls.Anziché chiamare
ls, è possibile chiamare direttamente illsfile binario, ad esempio/usr/bin/ls. In questo modo è possibile usarelssenza opzioni che potrebbero trovarsi nell'alias. È possibile trovare il percorso del file binario eseguendo il comandowhich ls.
Impedire ls di ordinare l'output
Quando si usa ls con altri comandi, è possibile migliorare le prestazioni impedendo ls l'ordinamento dell'output in situazioni in cui non ci si preoccupa dell'ordine che ls restituisce i file. L'ordinamento dell'output comporta un sovraccarico significativo.
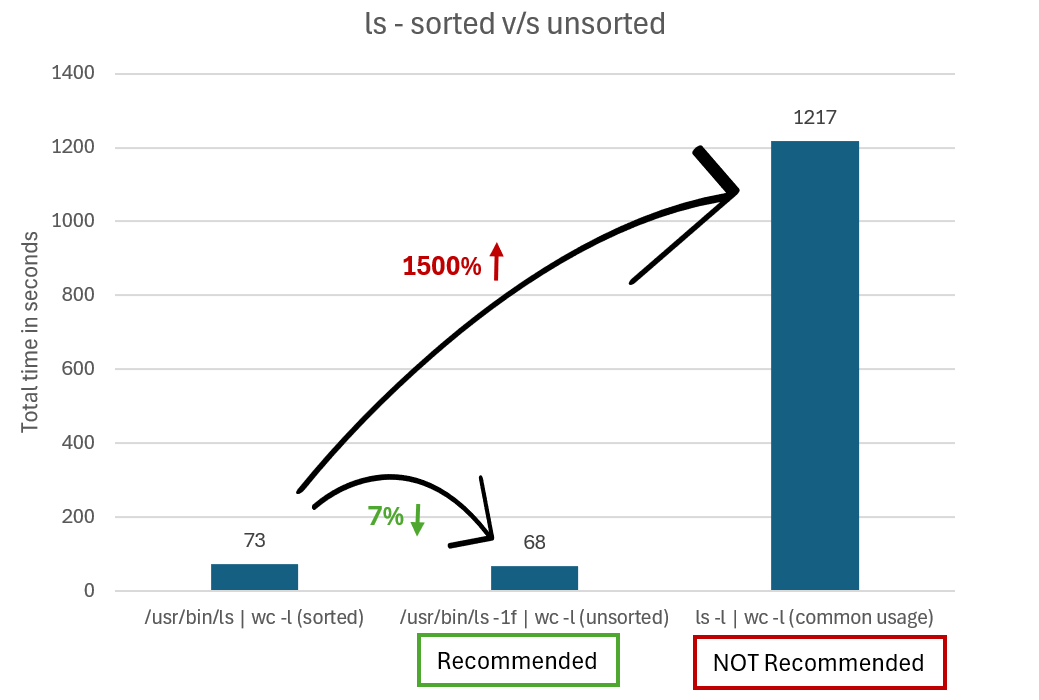
Anziché eseguire ls -l | wc -l per ottenere il numero totale di file, è possibile usare le -f opzioni o -U per ls impedire l'ordinamento dell'output. La differenza è che -f mostrerà anche i file nascosti e -U non lo farà.
Ad esempio, se si chiama direttamente il ls file binario in Ubuntu, si eseguirà /usr/bin/ls -1f | wc -l o /usr/bin/ls -1U | wc -l.
Il grafico seguente confronta il tempo necessario per restituire i risultati usando dati non ordinati e non ls ordinati ls.
Aumentare il numero di bucket hash
La quantità totale di RAM presente nel sistema che esegue l'enumerazione influisce sul funzionamento interno dei protocolli del file system come NFS e SMB. Anche se gli utenti non riscontrano un utilizzo elevato della memoria, la quantità di memoria disponibile influisce sulla quantità di bucket hash del sistema, che influisce/migliora le prestazioni di enumerazione per le directory di grandi dimensioni. È possibile modificare la quantità di bucket hash che il sistema deve ridurre i conflitti hash che possono verificarsi durante carichi di lavoro di enumerazione di grandi dimensioni.
A tale scopo, è necessario modificare le impostazioni di configurazione di avvio fornendo un comando kernel aggiuntivo che diventa effettivo durante l'avvio per aumentare il numero di bucket hash. Effettuare i passaggi seguenti.
Usando un editor di testo, modificare il
/etc/default/grubfile.sudo vim /etc/default/grubAggiungere il testo seguente al file
/etc/default/grub. Questo comando imposta 128 MB come dimensione della tabella hash, aumentando il consumo di memoria di sistema di un massimo di 128 MB.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Se
GRUB_CMDLINE_LINUXesiste già, aggiungereihash_entries=16777216separati da uno spazio, come illustrato di seguito:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Per applicare le modifiche, eseguire:
sudo update-grub2Riavviare il sistema:
sudo rebootPer verificare che le modifiche siano state applicate, dopo il riavvio del sistema, controllare i comandi del kernel cmdline:
cat /proc/cmdlineSe
ihash_entriesè visibile, il sistema ha applicato l'impostazione e le prestazioni dell'enumerazione dovrebbero migliorare in modo esponenziale.È anche possibile controllare l'output dmesg per verificare se è stata applicata la cmdline del kernel:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Operazioni di copia e backup dei file
Quando si copiano dati da una condivisione file o si esegue il backup da condivisioni file a un'altra posizione, per ottenere prestazioni ottimali, è consigliabile usare uno snapshot di condivisione come origine anziché la condivisione file live con I/O attivo. Le applicazioni di backup devono eseguire direttamente i comandi sullo snapshot. Per altre informazioni, vedere Usare snapshot di condivisione con File di Azure.
Raccomandazioni a livello di applicazione
Quando si sviluppano applicazioni che usano directory di grandi dimensioni, seguire queste raccomandazioni.
Ignorare gli attributi del file. Se l'applicazione richiede solo il nome del file e non gli attributi di file, ad esempio il tipo di file o l'ora dell'ultima modifica, è possibile usare più chiamate alle chiamate di sistema, ad
getdents64esempio con una buona dimensione del buffer. In questo modo si otterranno le voci nella directory specificata senza il tipo di file, rendendo l'operazione più veloce evitando operazioni aggiuntive non necessarie.Chiamate di stato interleave. Se l'applicazione necessita di attributi e il nome del file, è consigliabile interleaving le chiamate di stat insieme
getdents64a invece di ottenere tutte le voci fino alla fine del file congetdents64e quindi eseguire una statx su tutte le voci restituite. L'interfoliazione delle chiamate stat indica al client di richiedere sia il file che i relativi attributi contemporaneamente, riducendo il numero di chiamate al server. Se combinato con un valore elevatoactimeo, questo può migliorare significativamente le prestazioni. Ad esempio, invece di[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ], posizionare le chiamate statx dopo ognunagetdents64di queste operazioni:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Aumentare la profondità di I/O. Se possibile, è consigliabile configurare
nconnectun valore diverso da zero (maggiore di 1) e distribuire l'operazione tra più thread o usare operazioni di I/O asincrone. In questo modo, le operazioni che possono essere asincrone possono trarre vantaggio da più connessioni simultanee alla condivisione file.Utilizzo forzato della cache. Se l'applicazione esegue una query sugli attributi del file in una condivisione file montata da un solo client, usare la chiamata di sistema statx con il
AT_STATX_DONT_SYNCflag . Questo flag garantisce che gli attributi memorizzati nella cache vengano recuperati dalla cache senza sincronizzare con il server, evitando round trip di rete aggiuntivi per ottenere i dati più recenti.