Funzionamento del failover pianificato gestito dal cliente (anteprima)
Il failover pianificato gestito dal cliente può essere utile in scenari come la pianificazione e il ripristino di emergenza e i test, la correzione proattiva di emergenze su larga scala previste e interruzioni non correlate all'archiviazione.
Durante il processo di failover pianificato, le aree primarie e secondarie dell'account di archiviazione vengono scambiate. L'area primaria originale viene abbassata di livello e diventa la nuova secondaria mentre l'area secondaria originale viene alzata di livello e diventa la nuova primaria. L'account di archiviazione deve essere disponibile sia nelle aree primarie che secondarie prima di poter avviare un failover pianificato.
Questo articolo descrive cosa accade durante il failover e il failback pianificati gestiti dal cliente in ogni fase del processo. Per informazioni sul funzionamento di un failover a causa di un'interruzione imprevista dell'endpoint di archiviazione, vedere Come funziona il failover gestito dal cliente (non pianificato).
Importante
Il failover pianificato gestito dal cliente è attualmente in ANTEPRIMA e limitato alle aree seguenti:
- Francia centrale
- Francia meridionale
- India centrale
- India occidentale
- Asia orientale
- Asia sud-orientale
Per acconsentire esplicitamente all'anteprima, vedere Configurare le funzionalità di anteprima nella sottoscrizione di Azure e specificare AllowSoftFailover come nome della funzionalità. Il nome del provider per questa funzionalità di anteprima è Microsoft.Storage.
Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Importante
Dopo un failover pianificato, il valore LST (Last Sync Time) di un account di archiviazione potrebbe apparire non aggiornato o essere segnalato come NULL quando sono presenti i dati di File di Azure.
Gli snapshot di sistema vengono creati periodicamente nell'area secondaria di un account di archiviazione per mantenere punti di ripristino coerenti usati durante il failover e il failback. L'avvio del failover pianificato gestito dal cliente fa sì che l'area primaria originale diventi la nuova replica secondaria. In alcuni casi, non sono disponibili snapshot di sistema nel nuovo database secondario dopo il completamento del failover pianificato, cosa che causa la visualizzazione del valore LST complessivo dell'account come Null.
Poiché le attività utente, ad esempio la creazione, la modifica o l'eliminazione di oggetti, possono attivare la creazione di snapshot, qualsiasi account su cui si verificano queste attività dopo il failover pianificato non richiederà ulteriore attenzione. Tuttavia, gli account senza snapshot o attività utente possono continuare a visualizzare un valore LST Null finché non viene attivata la creazione dello snapshot di sistema.
Se necessario, eseguire una delle attività seguenti per ogni condivisione all'interno di un account di archiviazione per attivare la creazione di snapshot. Al termine, l'account dovrebbe visualizzare un valore LST valido entro 30 minuti.
- Montare la condivisione, quindi aprire qualsiasi file per la lettura.
- Caricare un file di test o di esempio nella condivisione.
Gestione della ridondanza durante il failover e il failback pianificati
Suggerimento
Per comprendere in dettaglio i vari stati di ridondanza durante il failover e il processo di failback gestiti dal cliente, vedere ridondanza di Archiviazione di Azure per le definizioni di ognuno di essi.
Durante il processo di failover pianificato, gli endpoint del servizio di archiviazione dell'area primaria diventano di sola lettura, mentre gli aggiornamenti rimanenti terminano la replica nell'area secondaria. Successivamente, tutte le voci DNS (Domain Name Service) dell'endpoint servizio di archiviazione vengono cambiate. Gli endpoint secondari dell'account di archiviazione diventano i nuovi endpoint primari e gli endpoint primari originali diventano i nuovi endpoint secondari. La replica dei dati all'interno di ogni area rimane invariata anche se le aree primarie e secondarie sono cambiate.
Il processo di failback pianificato è essenzialmente lo stesso del processo di failover pianificato, ma con un'unica eccezione. Durante il failback pianificato, Azure archivia la configurazione di ridondanza originale dell'account di archiviazione e la ripristina allo stato originale al failback. Ad esempio, se l'account di archiviazione è stato originariamente configurato come archiviazione con ridondanza geografica della zona, l'account di archiviazione avrà quel tipo di archiviazione dopo il failback.
Nota
A differenza del failover gestito dal cliente (non pianificato), durante il failover pianificato la replica dall'area primaria a quella secondaria deve essere completata prima che le voci DNS per gli endpoint vengano modificate nel nuovo database secondario. Per questo motivo, la perdita di dati non è prevista durante il failover pianificato o il failback, purché entrambe le aree primarie e secondarie siano disponibili in tutto il processo.
Come avviare un failover
Per informazioni su come avviare un failover, vedere Avviare un failover dell'account.
Processo di failover e failback pianificati
I diagrammi seguenti illustrano cosa accade durante un failover pianificato gestito dal cliente e il failback di un account di archiviazione.
- Archiviazione con ridondanza geografica/archiviazione con ridondanza geografica e accesso in lettura
- Archiviazione con ridondanza geografica della zona/archiviazione con ridondanza geografica della zona e accesso in lettura
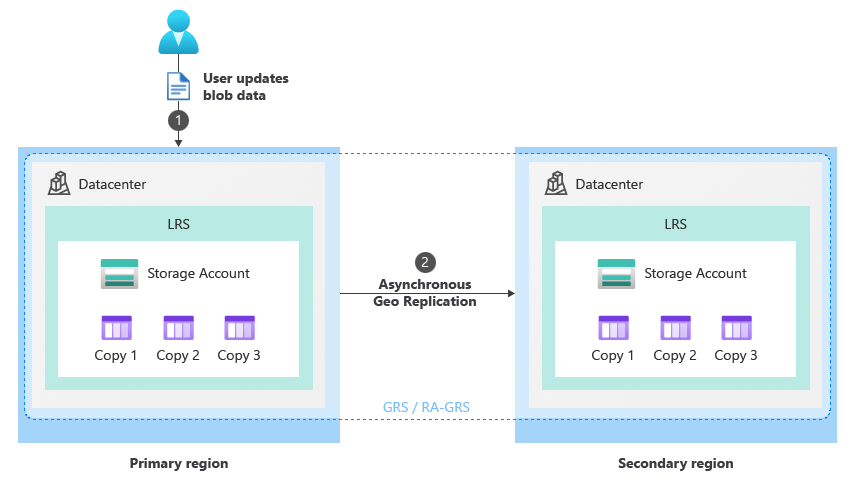
In circostanze normali, un client scrive i dati in un account di archiviazione nell'area primaria tramite gli endpoint del servizio di archiviazione (1). I dati vengono quindi copiati in modo asincrono dall'area primaria all'area secondaria (2). L'immagine seguente mostra lo stato normale di un account di archiviazione configurato come archiviazione con ridondanza geografica:

Processo di failover pianificato (GRS/RA-GRS)
Avviare il test di ripristino di emergenza avviando un failover dell'account di archiviazione nell'area secondaria. I passaggi seguenti descrivono il processo di failover e l'immagine successiva fornisce un'illustrazione:
- L'area primaria originale diventa di sola lettura.
- La replica di tutti i dati dall'area primaria all'area secondaria viene completata.
- Le voci DNS per gli endpoint del servizio di archiviazione nell'area secondaria vengono alzate di livello e diventano i nuovi endpoint primari per l'account di archiviazione.
Il failover richiede in genere circa un'ora.

Al termine del failover, l'area primaria originale diventa la nuova replica secondaria (1) e l'area secondaria originale diventa la nuova primaria (2). Gli URI per gli endpoint del servizio di archiviazione per BLOB, tabelle, code e file rimangono invariati, ma le loro voci DNS vengono modificate in modo da puntare alla nuova area primaria (3). Gli utenti possono riprendere la scrittura dei dati nell'account di archiviazione nella nuova area primaria e i dati vengono quindi copiati in modo asincrono nel nuovo database secondario (4), come illustrato nell'immagine seguente:

Durante lo stato del failover, eseguire i test di ripristino di emergenza.
Processo di failback pianificato (GRS/RA-GRS)
Al termine del test, eseguire un altro failover per eseguire il failback nell'area primaria originale. Durante il processo di failover, come illustrato nell'immagine seguente:
- L'area primaria originale diventa di sola lettura.
- Tutti i dati terminano la replica dall'area primaria corrente all'area secondaria corrente.
- Le voci DNS per gli endpoint del servizio di archiviazione vengono modificate in modo da tornare all'area primaria prima dell'esecuzione del failover iniziale.
Il failback richiede in genere circa un'ora.

Al termine del failback, l'account di archiviazione viene ripristinato nella configurazione di ridondanza originale. Gli utenti possono riprendere la scrittura dei dati nell'account di archiviazione nell'area primaria originale (1) mentre la replica nel database secondario originale (2) continua come prima del failover: