accelerazione delle query Azure Data Lake Storage
L'accelerazione delle query consente alle applicazioni e ai framework di analisi di ottimizzare notevolmente l'elaborazione dei dati recuperando solo i dati necessari per eseguire una determinata operazione. In questo modo si riduce il tempo e la potenza di elaborazione necessari per ottenere informazioni dettagliate critiche sui dati archiviati.
Panoramica
L'accelerazione delle query accetta predicati di filtro e proiezioni di colonne, che consentono alle applicazioni di filtrare righe e colonne al momento in cui i dati vengono letti dal disco. Solo i dati che soddisfano le condizioni di un predicato vengono trasferiti in rete all'applicazione. Ciò riduce la latenza di rete e i costi di calcolo.
È possibile usare SQL per specificare i predicati del filtro di riga e le proiezioni di colonna in una richiesta di accelerazione della query. Una richiesta elabora un solo file. Di conseguenza, le funzionalità relazionali avanzate di SQL, ad esempio join e gruppi per aggregazioni, non sono supportate. L'accelerazione delle query supporta i dati in formato CSV e JSON come input per ogni richiesta.
La funzionalità di accelerazione delle query non è limitata alle Data Lake Storage (account di archiviazione in cui è abilitato lo spazio dei nomi gerarchico). L'accelerazione delle query è compatibile con i BLOB negli account di archiviazione in cui non è abilitato uno spazio dei nomi gerarchico. Ciò significa che è possibile ottenere la stessa riduzione della latenza di rete e dei costi di calcolo quando si elaborano i dati già archiviati come BLOB negli account di archiviazione.
Per un esempio di come usare l'accelerazione delle query in un'applicazione client, vedere Filtrare i dati usando Azure Data Lake Storage accelerazione delle query.
Flusso di dati
Il diagramma seguente illustra come un'applicazione tipica usa l'accelerazione delle query per elaborare i dati.
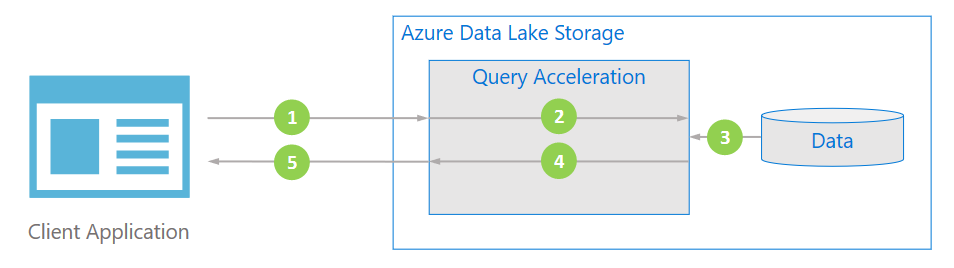
L'applicazione client richiede i dati dei file specificando predicati e proiezioni di colonne.
L'accelerazione delle query analizza la query SQL specificata e distribuisce il lavoro per analizzare e filtrare i dati.
I processori leggono i dati dal disco, analizzano i dati usando il formato appropriato e quindi filtrano i dati applicando i predicati e le proiezioni di colonna specificati.
L'accelerazione delle query combina le partizioni di risposta per eseguire il flusso all'applicazione client.
L'applicazione client riceve e analizza la risposta trasmessa. L'applicazione non deve filtrare altri dati e può applicare direttamente il calcolo o la trasformazione desiderata.
Prestazioni migliori a un costo inferiore
L'accelerazione delle query ottimizza le prestazioni riducendo la quantità di dati trasferiti ed elaborati dall'applicazione.
Per calcolare un valore aggregato, le applicazioni in genere recuperano tutti i dati da un file e quindi elaborano e filtrano i dati in locale. Un'analisi dei modelli di input/output per i carichi di lavoro di analisi rivela che le applicazioni richiedono in genere solo il 20% dei dati letti per eseguire qualsiasi calcolo specificato. Questa statistica è vera anche dopo l'applicazione di tecniche come l'eliminazione della partizione. Ciò significa che l'80% dei dati viene trasferito in modo inutile attraverso la rete, analizzato e filtrato dalle applicazioni. Questo modello, progettato per rimuovere i dati non necessario, comporta un costo di calcolo significativo.
Anche se Azure offre una rete leader del settore, in termini di velocità effettiva e latenza, il trasferimento dei dati in tutta la rete è comunque costoso per le prestazioni dell'applicazione. Filtrando i dati indesiderati durante la richiesta di archiviazione, l'accelerazione delle query elimina questo costo.
Inoltre, il carico della CPU necessario per analizzare e filtrare i dati non necessari richiede all'applicazione di effettuare il provisioning di un numero maggiore e di macchine virtuali di dimensioni maggiori per svolgere il proprio lavoro. Trasferendo questo carico di calcolo all'accelerazione delle query, le applicazioni possono realizzare risparmi significativi sui costi.
Applicazioni che possono trarre vantaggio dall'accelerazione delle query
L'accelerazione delle query è progettata per framework di analisi distribuiti e applicazioni di elaborazione dati.
I framework di analisi distribuiti, ad esempio Apache Spark e Apache Hive, includono un livello di astrazione di archiviazione all'interno del framework. Questi motori includono anche Query Optimizer che possono incorporare le conoscenze delle funzionalità del servizio di I/O sottostante durante la determinazione di un piano di query ottimale per le query utente. Questi framework stanno iniziando a integrare l'accelerazione delle query. Di conseguenza, gli utenti di questi framework vedono una latenza delle query migliorata e un costo totale inferiore di proprietà senza dover apportare modifiche alle query.
L'accelerazione delle query è progettata anche per le applicazioni di elaborazione dati. Questi tipi di applicazioni in genere eseguono trasformazioni di dati su larga scala che potrebbero non portare direttamente a informazioni dettagliate sull'analisi, in modo che non usino sempre framework di analisi distribuiti stabiliti. Queste applicazioni spesso hanno una relazione più diretta con il servizio di archiviazione sottostante, in modo che possano trarre vantaggio direttamente da funzionalità come l'accelerazione delle query.
Per un esempio di come un'applicazione può integrare l'accelerazione delle query, vedere Filtrare i dati usando Azure Data Lake Storage'accelerazione delle query.
Prezzi
A causa dell'aumento del carico di calcolo all'interno del servizio Azure Data Lake Storage, il modello tariffario per l'uso dell'accelerazione delle query è diverso dal modello di transazione Azure Data Lake Storage normale. L'accelerazione delle query addebita un costo per la quantità di dati analizzati, nonché un costo per la quantità di dati restituiti al chiamante. Per altre informazioni, vedere prezzi di Azure Data Lake Storage Gen2.
Nonostante la modifica al modello di fatturazione, il modello di determinazione prezzi dell'accelerazione delle query è progettato per ridurre il costo totale di proprietà per un carico di lavoro, data la riduzione dei costi di macchina virtuale molto più costosi.