Aumentare le prestazioni di un tipo di nodo primario di un cluster di Service Fabric
Questo articolo descrive come aumentare le prestazioni di un tipo di nodo primario del cluster di Service Fabric con tempi di inattività minimi. Gli aggiornamenti dello SKU sul posto non sono supportati nei nodi del cluster di Service Fabric, in quanto tali operazioni comportano potenzialmente la perdita di dati e disponibilità. Il metodo più sicuro, affidabile e consigliato per aumentare le prestazioni di un tipo di nodo di Service Fabric è il seguente:
Aggiungere un nuovo tipo di nodo al cluster di Service Fabric, supportato dallo SKU e dalla configurazione del set di scalabilità di macchine virtuali aggiornati (o modificati). Questo passaggio comporta anche la configurazione di un nuovo servizio di bilanciamento del carico, una subnet e un indirizzo IP pubblico per il set di scalabilità.
Dopo che i set di scalabilità originali e aggiornati vengono eseguiti side-by-side, disabilitare le istanze del nodo originali una alla volta in modo che i servizi di sistema (o le repliche dei servizi con stato) eseguano la migrazione al nuovo set di scalabilità.
Verificare che il cluster e i nuovi nodi siano integri, quindi rimuovere il set di scalabilità originale (e le risorse correlate) e lo stato del nodo per i nodi eliminati.
Di seguito viene illustrato il processo per aggiornare le dimensioni della macchina virtuale e il sistema operativo di macchine virtuali di tipo nodo primario di un cluster di esempio con durabilità Silver, supportato da un singolo set di scalabilità con cinque nodi usati come tipo di nodo secondario. Verrà aggiornato il tipo di nodo primario:
- Dalle dimensioni della macchina virtuale Standard_D2_V2 a Standard D4_V2e
- Dal sistema operativo della macchina virtuale Windows Server 2019 Datacenter a Windows Server 2022 Datacenter.
Avviso
Prima di provare a eseguire questa procedura su un cluster di produzione, è consigliabile esaminare i modelli di esempio e verificare il processo su un cluster di test. Il cluster potrebbe anche non essere disponibile per un breve periodo di tempo.
Non tentare una procedura di aumento delle prestazioni del tipo di nodo primario se lo stato del cluster non è integro, in quanto ciò destabilizzerà ulteriormente il cluster.
I modelli di distribuzione di Azure step-by-step che verranno usati per completare questo scenario di aggiornamento di esempio sono disponibili in GitHub.
Configurare il cluster di test
Configurare il cluster di test iniziale di Service Fabric. Prima di tutto, scaricare i modelli di esempio di Azure Resource Manager che verranno usati per completare questo scenario.
Successivamente, accedere all'account Azure.
# Sign in to your Azure account
Login-AzAccount -SubscriptionId "<subscription ID>"
Aprire quindi il file parameters.json e aggiornare il valore clusterName con un valore univoco (all'interno di Azure).
I comandi seguenti consentono di generare un nuovo certificato autofirmato e di distribuire il cluster di test. Se si ha già un certificato da usare, andare a Usare un certificato esistente per distribuire il cluster.
Generare un certificato autofirmato e distribuire il cluster
Per prima cosa, assegnare le variabili necessarie per la distribuzione del cluster Service Fabric. Modificare i valori per resourceGroupName, certSubjectName, parameterFilePathe templateFilePath per l'account e l'ambiente specifici:
# Assign deployment variables
$resourceGroupName = "sftestupgradegroup"
$certOutputFolder = "c:\certificates"
$certPassword = "Password!1" | ConvertTo-SecureString -AsPlainText -Force
$certSubjectName = "sftestupgrade.southcentralus.cloudapp.azure.com"
$parameterFilePath = "C:\parameters.json"
$templateFilePath = "C:\Initial-TestClusterSetup.json"
Nota
Prima di eseguire il comando per distribuire un nuovo cluster Service Fabric, verificare che nel computer locale esista il percorso certOutputFolder.
Quindi distribuire il cluster di test di Service Fabric:
# Deploy the initial test cluster
New-AzServiceFabricCluster `
-ResourceGroupName $resourceGroupName `
-CertificateOutputFolder $certOutputFolder `
-CertificatePassword $certPassword `
-CertificateSubjectName $certSubjectName `
-TemplateFile $templateFilePath `
-ParameterFile $parameterFilePath
Al termine della distribuzione, individuare il file .pfx ($certPfx) nel computer locale e importarlo nell'archivio certificati:
cd c:\certificates
$certPfx = ".\sftestupgradegroup20200312121003.pfx"
Import-PfxCertificate `
-FilePath $certPfx `
-CertStoreLocation Cert:\CurrentUser\My `
-Password (ConvertTo-SecureString Password!1 -AsPlainText -Force)
L'operazione restituisce l'identificazione personale del certificato, che ora è possibile usare per connettersi al nuovo cluster e controllarne lo stato di integrità. (ignorare la sezione seguente, ovvero un approccio alternativo alla distribuzione del cluster).
Usare un certificato esistente per distribuire il cluster
In alternativa, è possibile usare un certificato di Azure Key Vault esistente per distribuire il cluster di test. A tale scopo, è necessario ottenere riferimenti all'insieme di credenziali delle chiavi e all'identificazione personale del certificato.
# Key Vault variables
$certUrlValue = "https://sftestupgradegroup.vault.azure.net/secrets/sftestupgradegroup20200309235308/dac0e7b7f9d4414984ccaa72bfb2ea39"
$sourceVaultValue = "/subscriptions/########-####-####-####-############/resourceGroups/sftestupgradegroup/providers/Microsoft.KeyVault/vaults/sftestupgradegroup"
$thumb = "BB796AA33BD9767E7DA27FE5182CF8FDEE714A70"
Successivamente, designare un nome di gruppo di risorse per il cluster e impostare i percorsi templateFilePath e parameterFilePath:
Nota
Il gruppo di risorse designato deve già esistere e trovarsi nella stessa area dell'insieme di credenziali delle chiavi.
$resourceGroupName = "sftestupgradegroup"
$templateFilePath = "C:\Initial-TestClusterSetup.json"
$parameterFilePath = "C:\parameters.json"
Eseguire infine il comando seguente per distribuire il cluster di test iniziale:
# Deploy the initial test cluster
New-AzResourceGroupDeployment `
-ResourceGroupName $resourceGroupName `
-TemplateFile $templateFilePath `
-TemplateParameterFile $parameterFilePath `
-CertificateThumbprint $thumb `
-CertificateUrlValue $certUrlValue `
-SourceVaultValue $sourceVaultValue `
-Verbose
Connettersi al nuovo cluster e controllarne lo stato di integrità
Connettersi al cluster e assicurarsi che tutti e cinque i relativi nodi siano integri (sostituire le variabili clusterName e thumb con i propri valori):
# Connect to the cluster
$clusterName = "sftestupgrade.southcentralus.cloudapp.azure.com:19000"
$thumb = "BB796AA33BD9767E7DA27FE5182CF8FDEE714A70"
Connect-ServiceFabricCluster `
-ConnectionEndpoint $clusterName `
-KeepAliveIntervalInSec 10 `
-X509Credential `
-ServerCertThumbprint $thumb `
-FindType FindByThumbprint `
-FindValue $thumb `
-StoreLocation CurrentUser `
-StoreName My
# Check cluster health
Get-ServiceFabricClusterHealth
È ora possibile iniziare la procedura di aggiornamento.
Distribuire un nuovo tipo di nodo primario con un set di scalabilità aggiornato
Per aggiornare (dimensionare verticalmente) un tipo di nodo, è prima necessario distribuire un nuovo tipo di nodo supportato da un nuovo set di scalabilità e risorse di supporto. Il nuovo set di scalabilità verrà contrassegnato come primario (isPrimary: true), proprio come il set di scalabilità originale. Per aumentare le prestazioni di un tipo di nodo non primario, vedere Aumentare le prestazioni di un tipo di nodo non primario del cluster di Service Fabric. Le risorse create nella sezione seguente diventeranno infine il nuovo tipo di nodo primario nel cluster e le risorse del tipo di nodo primario originale sono eliminate.
Aggiornare il modello di cluster con il set di scalabilità aggiornato
Di seguito sono riportate le modifiche sezione per sezione del modello di distribuzione del cluster originale per l'aggiunta di un nuovo tipo di nodo primario e risorse di supporto.
Le modifiche necessarie per questo passaggio sono già state apportate nel file modello Step1-AddPrimaryNodeType.json e le seguenti illustrano in dettaglio queste modifiche. Se si preferisce, è possibile ignorare la spiegazione e continuare a ottenere i riferimenti a Key Vault e distribuire il modello aggiornato che aggiunge un nuovo tipo di nodo primario al cluster.
Nota
Assicurarsi di usare nomi univoci dal tipo di nodo originale, dal set di scalabilità, dal servizio di bilanciamento del carico, dall'indirizzo IP pubblico e dalla subnet del tipo di nodo primario originale, perché queste risorse sono eliminate in un passaggio successivo del processo.
Creare una nuova subnet nella rete virtuale esistente
{
"name": "[variables('subnet1Name')]",
"properties": {
"addressPrefix": "[variables('subnet1Prefix')]"
}
}
Creare un nuovo indirizzo IP pubblico con domainNameLabel univoco
{
"apiVersion": "[variables('publicIPApiVersion')]",
"type": "Microsoft.Network/publicIPAddresses",
"name": "[concat(variables('lbIPName'),'-',variables('vmNodeType1Name'))]",
"location": "[variables('computeLocation')]",
"properties": {
"dnsSettings": {
"domainNameLabel": "[concat(variables('dnsName'),'-','nt1')]"
},
"publicIPAllocationMethod": "Dynamic"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
}
Creare un nuovo servizio di bilanciamento del carico per l'indirizzo IP pubblico
"dependsOn": [
"[concat('Microsoft.Network/publicIPAddresses/',concat(variables('lbIPName'),'-',variables('vmNodeType1Name')))]"
]
Creare un nuovo set di scalabilità di macchine virtuali (con SKU di macchina virtuale e sistema operativo aggiornati)
Riferimento al tipo di nodo
"nodeTypeRef": "[variables('vmNodeType1Name')]"
SKU di VM
"sku": {
"name": "[parameters('vmNodeType1Size')]",
"capacity": "[parameters('nt1InstanceCount')]",
"tier": "Standard"
}
OS SKU
"imageReference": {
"publisher": "[parameters('vmImagePublisher1')]",
"offer": "[parameters('vmImageOffer1')]",
"sku": "[parameters('vmImageSku1')]",
"version": "[parameters('vmImageVersion1')]"
}
Se si sta modificando lo SKU del sistema operativo in un cluster Linux
Nel cluster Windows il valore per la proprietà vmImage è 'Windows' mentre il valore della stessa proprietà per il cluster Linux è il nome dell'immagine del sistema operativo usata. Ad esempio, Ubuntu20_04(usare il nome dell'immagine della macchina virtuale più recente).
Quindi, se si modifica l'immagine della macchina virtuale (SKU del sistema operativo) in un cluster Linux, aggiornare anche l'impostazione vmImage nella risorsa cluster di Service Fabric.
#Update the property vmImage with the required OS name in your ARM template
{
"vmImage": "[parameter(newVmImageName]”
}
Nota: esempio di newVmImageName: Ubuntu20_04
È anche possibile aggiornare la risorsa cluster usando il comando di PowerShell seguente:
# Update cluster vmImage to target OS. This registers the SF runtime package type that is supplied for upgrades.
Update-AzServiceFabricVmImage -ResourceGroupName $resourceGroup -ClusterName $clusterName -VmImage Ubuntu20_04
Assicurarsi inoltre di includere eventuali estensioni aggiuntive necessarie per il carico di lavoro.
Aggiungere un nuovo tipo di nodo primario al cluster
Ora che il nuovo tipo di nodo (vmNodeType1Name) ha nome, subnet, IP, servizio di bilanciamento del carico e set di scalabilità propri, può riutilizzare tutte le altre variabili dal tipo di nodo originale ( ad esempio nt0applicationEndPort, nt0applicationStartPorte nt0fabricTcpGatewayPort):
"name": "[variables('vmNodeType1Name')]",
"applicationPorts": {
"endPort": "[variables('nt0applicationEndPort')]",
"startPort": "[variables('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[variables('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Bronze",
"ephemeralPorts": {
"endPort": "[variables('nt0ephemeralEndPort')]",
"startPort": "[variables('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[variables('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"reverseProxyEndpointPort": "[variables('nt0reverseProxyEndpointPort')]",
"vmInstanceCount": "[parameters('nt1InstanceCount')]"
Dopo aver implementato tutte le modifiche apportate ai file di modello e parametri, andare alla sezione successiva per acquisire i riferimenti a Key Vault e distribuire gli aggiornamenti nel cluster.
Ottenere i riferimenti a Key Vault
Per distribuire la configurazione aggiornata, sono necessari diversi riferimenti al certificato del cluster archiviato nell'insieme di credenziali delle chiavi. Il modo più semplice per trovare questi valori è tramite il portale di Azure. È necessario:
URL dell'insieme di credenziali delle chiavi del certificato del cluster. Nell'insieme di credenziali delle chiavi nel portale di Azure selezionare Certificati>certificato desiderato>Identificatore segreto:
$certUrlValue="https://sftestupgradegroup.vault.azure.net/secrets/sftestupgradegroup20200309235308/dac0e7b7f9d4414984ccaa72bfb2ea39"Identificazione personale del certificato del cluster. (probabilmente si dispone già del certificato se si è connessi al cluster iniziale per verificarne lo stato di integrità). Dallo stesso pannello del certificato (Certificati>certificato desiderato) nel portale di Azure copiare l'identificazione personale SHA-509 SHA-1 (in cifre esadecimali):
$thumb = "BB796AA33BD9767E7DA27FE5182CF8FDEE714A70"ID risorsa dell'insieme di credenziali delle chiavi. Nell'insieme di credenziali delle chiavi nel portale di Azure selezionare Proprietà>ID risorsa:
$sourceVaultValue = "/subscriptions/########-####-####-####-############/resourceGroups/sftestupgradegroup/providers/Microsoft.KeyVault/vaults/sftestupgradegroup"
Distribuire il modello aggiornato
Modificare templateFilePath in base alle esigenze ed eseguire il comando seguente:
# Deploy the new node type and its resources
$templateFilePath = "C:\Step1-AddPrimaryNodeType.json"
New-AzResourceGroupDeployment `
-ResourceGroupName $resourceGroupName `
-TemplateFile $templateFilePath `
-TemplateParameterFile $parameterFilePath `
-CertificateThumbprint $thumb `
-CertificateUrlValue $certUrlValue `
-SourceVaultValue $sourceVaultValue `
-Verbose
Al termine della distribuzione, controllare di nuovo l'integrità del cluster e assicurarsi che tutti i nodi in entrambi i tipi di nodo siano integri.
Get-ServiceFabricClusterHealth
Eseguire la migrazione dei nodi di inizializzazione al nuovo tipo di nodo
A questo punto è possibile aggiornare il tipo di nodo originale come non primario e iniziare a disabilitarne i nodi. Quando i nodi vengono disabilitati, i servizi di sistema e i nodi di inizializzazione del cluster vengono migrati al nuovo set di scalabilità.
Deselezionare il tipo di nodo originale come primario
Rimuovere prima di tutto la designazione isPrimary nel modello dal tipo di nodo originale.
{
"isPrimary": false,
}
Distribuire quindi il modello con l'aggiornamento. Questa distribuzione avvia la migrazione dei nodi di inizializzazione al nuovo set di scalabilità.
$templateFilePath = "C:\Step2-UnmarkOriginalPrimaryNodeType.json"
New-AzResourceGroupDeployment `
-ResourceGroupName $resourceGroupName `
-TemplateFile $templateFilePath `
-TemplateParameterFile $parameterFilePath `
-CertificateThumbprint $thumb `
-CertificateUrlValue $certUrlValue `
-SourceVaultValue $sourceVaultValue `
-Verbose
Nota
Il completamento della migrazione del nodo di inizializzazione al nuovo set di scalabilità richiederà del tempo. Per garantire la coerenza dei dati, è possibile modificare un solo nodo di inizializzazione alla volta. Per ogni modifica del nodo di inizializzazione è necessario un aggiornamento del cluster. La sostituzione di un nodo di inizializzazione richiede quindi due aggiornamenti del cluster, uno ciascuno per l'aggiunta e la rimozione di nodi. L'aggiornamento dei cinque nodi di inizializzazione in questo scenario di esempio comporterà dieci aggiornamenti del cluster.
Usare Service Fabric Explorer per monitorare la migrazione dei nodi di inizializzazione al nuovo set di scalabilità. I nodi del tipo di nodo originale (nt0vm) devono essere tutti false nella colonna Is Seed Node e quelli del nuovo tipo di nodo (nt1vm) devono essere true.
Disabilitare i nodi nel set di scalabilità del tipo di nodo originale
Dopo aver eseguito la migrazione di tutti i nodi di inizializzazione al nuovo set di scalabilità, è possibile disabilitare i nodi del set di scalabilità originale.
# Disable the nodes in the original scale set.
$nodeType = "nt0vm"
$nodes = Get-ServiceFabricNode
Write-Host "Disabling nodes..."
foreach($node in $nodes)
{
if ($node.NodeType -eq $nodeType)
{
$node.NodeName
Disable-ServiceFabricNode -Intent RemoveNode -NodeName $node.NodeName -Force
}
}
Usare Service Fabric Explorer per monitorare l'avanzamento dei nodi nel set di scalabilità originale da Disabilitazione allo stato Disabilitato.
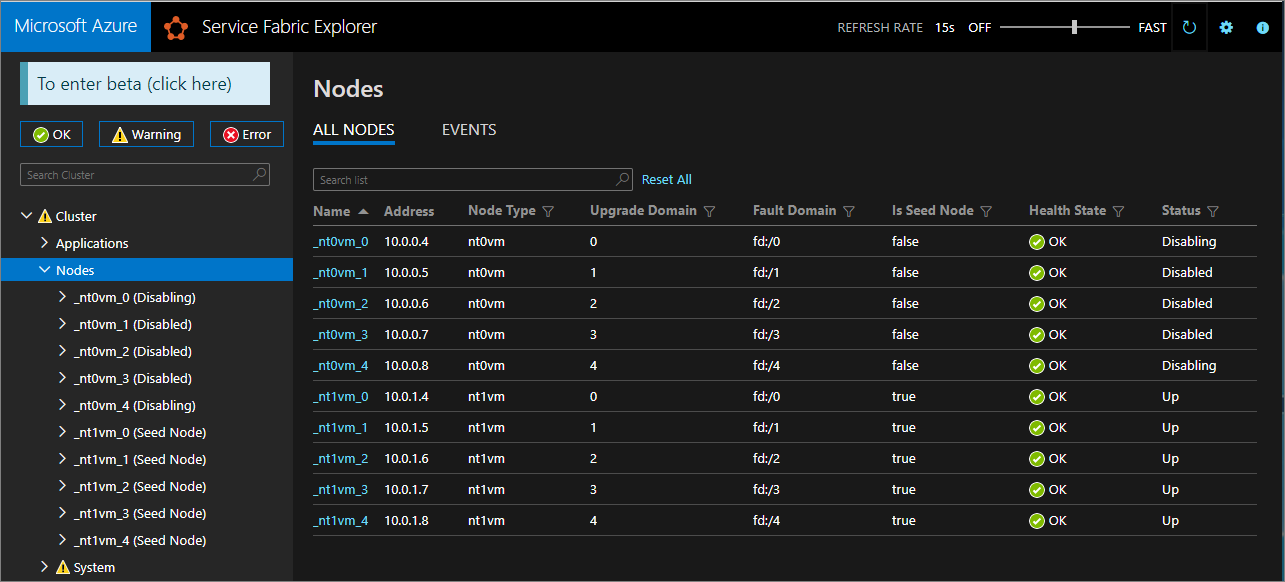
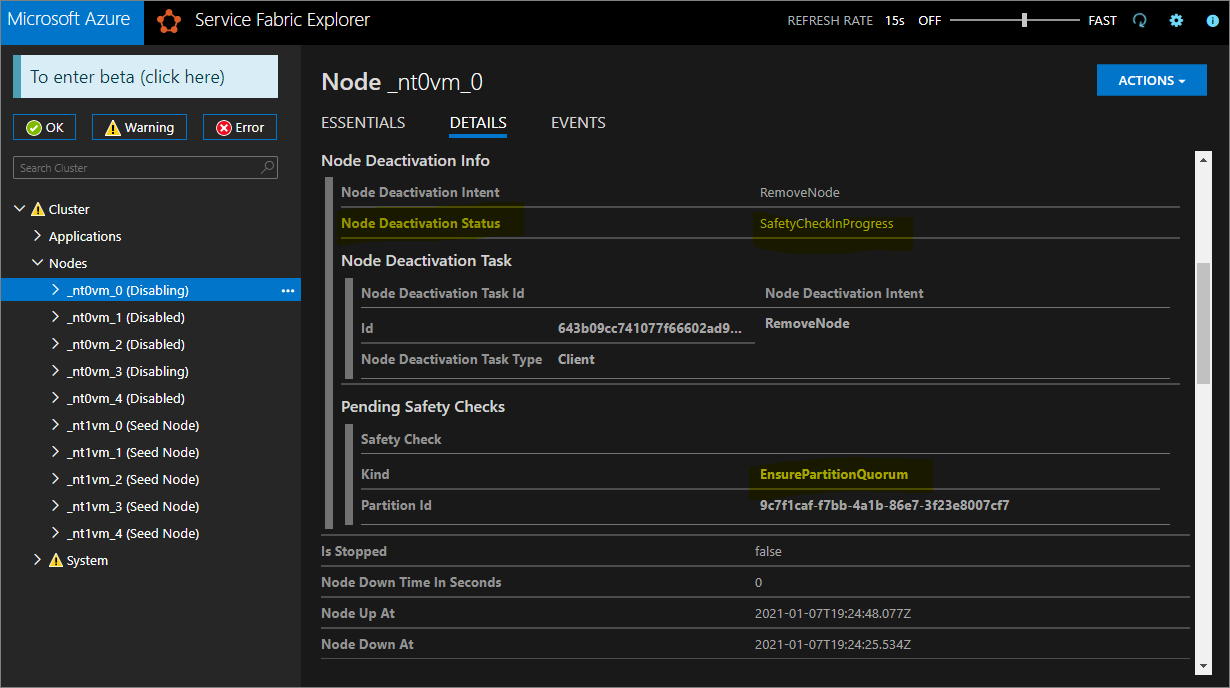
Per la durabilità Silver e Gold, alcuni nodi passeranno allo stato Disabilitato, mentre altri potrebbero rimanere in uno stato di disabilitazione. In Service Fabric Explorer selezionare la scheda Dettagli dei nodi nello stato Disabilitazione. Se mostrano un Controllo di sicurezza in sospeso di tipo EnsurePartitionQuorem (che verifica il quorum per le partizioni del servizio di infrastruttura), è sicuro continuare.
Se il cluster è durabilità Bronze, attendere che tutti i nodi raggiungano lo stato Disabilitato.
Arrestare i dati nei nodi disabilitati
È ora possibile arrestare i dati nei nodi disabilitati.
# Stop data on the disabled nodes.
foreach($node in $nodes)
{
if ($node.NodeType -eq $nodeType)
{
$node.NodeName
Start-ServiceFabricNodeTransition -Stop -OperationId (New-Guid) -NodeInstanceId $node.NodeInstanceId -NodeName $node.NodeName -StopDurationInSeconds 10000
}
}
Rimuovere il tipo di nodo originale e pulire le risorse
È possibile rimuovere il tipo di nodo originale e le risorse associate per concludere la procedura di ridimensionamento verticale.
Rimuovere il set di scalabilità originale
Rimuovere prima di tutto il set di scalabilità di backup del tipo di nodo.
$scaleSetName = "nt0vm"
$scaleSetResourceType = "Microsoft.Compute/virtualMachineScaleSets"
Remove-AzResource -ResourceName $scaleSetName -ResourceType $scaleSetResourceType -ResourceGroupName $resourceGroupName -Force
Eliminare gli indirizzi IP originali e le risorse del servizio di bilanciamento del carico
È ora possibile eliminare l'IP originale e le risorse di bilanciamento del carico. In questo passaggio si aggiornerà anche il nome DNS.
Nota
Questo passaggio è facoltativo se si usa già un indirizzo IP pubblico Standard e un servizio di bilanciamento del carico. In questo caso è possibile avere più set di scalabilità/tipi di nodo nello stesso servizio di bilanciamento del carico.
Eseguire i comandi seguenti, modificando il valore $lbname in base alle esigenze.
# Delete the original IP and load balancer resources
$lbName = "LB-sftestupgrade-nt0vm"
$lbResourceType = "Microsoft.Network/loadBalancers"
$ipResourceType = "Microsoft.Network/publicIPAddresses"
$oldPublicIpName = "PublicIP-LB-FE-nt0vm"
$newPublicIpName = "PublicIP-LB-FE-nt1vm"
$oldPrimaryPublicIP = Get-AzPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $resourceGroupName
$primaryDNSName = $oldPrimaryPublicIP.DnsSettings.DomainNameLabel
$primaryDNSFqdn = $oldPrimaryPublicIP.DnsSettings.Fqdn
Remove-AzResource -ResourceName $lbName -ResourceType $lbResourceType -ResourceGroupName $resourceGroupName -Force
Remove-AzResource -ResourceName $oldPublicIpName -ResourceType $ipResourceType -ResourceGroupName $resourceGroupName -Force
$PublicIP = Get-AzPublicIpAddress -Name $newPublicIpName -ResourceGroupName $resourceGroupName
$PublicIP.DnsSettings.DomainNameLabel = $primaryDNSName
$PublicIP.DnsSettings.Fqdn = $primaryDNSFqdn
Set-AzPublicIpAddress -PublicIpAddress $PublicIP
Rimuovere lo stato del nodo dal tipo di nodo originale
I nodi del tipo di nodo originale visualizzeranno ora Errore per lo Stato di integrità. Rimuovere lo stato del nodo dal cluster.
# Remove state of the obsolete nodes from the cluster
$nodeType = "nt0vm"
$nodes = Get-ServiceFabricNode
Write-Host "Removing node state..."
foreach($node in $nodes)
{
if ($node.NodeType -eq $nodeType)
{
$node.NodeName
Remove-ServiceFabricNodeState -NodeName $node.NodeName -Force
}
}
Service Fabric Explorer dovrebbe ora riflettere solo i cinque nodi del nuovo tipo di nodo (nt1vm), tutti con valori dello stato di integrità OK. Lo stato di integrità del cluster continuerà a visualizzare un errore. La correzione verrà eseguita successivamente aggiornando il modello in modo da riflettere le modifiche più recenti e la ridistribuzione.
Aggiornare il modello di distribuzione in modo che rifletta il nuovo tipo di nodo primario con scalabilità orizzontale
Le modifiche necessarie per questo passaggio sono già state apportate nel file modello Step3-CleanupOriginalPrimaryNodeType.json e le sezioni seguenti illustrano in dettaglio queste modifiche al modello. Se si preferisce, è possibile ignorare la spiegazione e continuare a distribuire il modello aggiornato e completare l'esercitazione.
Aggiornare l'endpoint di gestione del cluster
Aggiornare il valore managementEndpoint del cluster nel modello di distribuzione per fare riferimento al nuovo IP (aggiornando vmNodeType0Name con vmNodeType1Name).
"managementEndpoint": "[concat('https://',reference(concat(variables('lbIPName'),'-',variables('vmNodeType1Name'))).dnsSettings.fqdn,':',variables('nt0fabricHttpGatewayPort'))]",
Rimuovere il riferimento al tipo di nodo originale
Rimuovere il riferimento al tipo di nodo originale dalla risorsa di Service Fabric nel modello di distribuzione:
"name": "[variables('vmNodeType0Name')]",
"applicationPorts": {
"endPort": "[variables('nt0applicationEndPort')]",
"startPort": "[variables('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[variables('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Bronze",
"ephemeralPorts": {
"endPort": "[variables('nt0ephemeralEndPort')]",
"startPort": "[variables('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[variables('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"reverseProxyEndpointPort": "[variables('nt0reverseProxyEndpointPort')]",
"vmInstanceCount": "[parameters('nt0InstanceCount')]"
Configurare i criteri di integrità per ignorare gli errori esistenti
Solo per i cluster Silver e con durabilità superiore, aggiornare la risorsa cluster nel modello e configurare i criteri di integrità per ignorare l'integrità dell'applicazione fabric:/System aggiungendo applicationDeltaHealthPolicies nelle proprietà delle risorse del cluster, come indicato di seguito. I criteri seguenti ignorano gli errori esistenti, ma non consentono nuovi errori di integrità.
"upgradeDescription":
{
"forceRestart": false,
"upgradeReplicaSetCheckTimeout": "10675199.02:48:05.4775807",
"healthCheckWaitDuration": "00:05:00",
"healthCheckStableDuration": "00:05:00",
"healthCheckRetryTimeout": "00:45:00",
"upgradeTimeout": "12:00:00",
"upgradeDomainTimeout": "02:00:00",
"healthPolicy": {
"maxPercentUnhealthyNodes": 100,
"maxPercentUnhealthyApplications": 100
},
"deltaHealthPolicy":
{
"maxPercentDeltaUnhealthyNodes": 0,
"maxPercentUpgradeDomainDeltaUnhealthyNodes": 0,
"maxPercentDeltaUnhealthyApplications": 0,
"applicationDeltaHealthPolicies":
{
"fabric:/System":
{
"defaultServiceTypeDeltaHealthPolicy":
{
"maxPercentDeltaUnhealthyServices": 0
}
}
}
}
}
Rimuovere le risorse di supporto per il tipo di nodo originale
Rimuovere tutte le altre risorse correlate al tipo di nodo originale dal modello di Resource Manager e dal file dei parametri. Eliminare quanto segue:
"vmImagePublisher": {
"value": "MicrosoftWindowsServer"
},
"vmImageOffer": {
"value": "WindowsServer"
},
"vmImageSku": {
"value": "2019-Datacenter"
},
"vmImageVersion": {
"value": "latest"
},
Distribuire il modello finalizzato
Distribuire infine il modello di Azure Resource Manager modificato.
# Deploy the updated template file
$templateFilePath = "C:\Step3-CleanupOriginalPrimaryNodeType"
New-AzResourceGroupDeployment `
-ResourceGroupName $resourceGroupName `
-TemplateFile $templateFilePath `
-TemplateParameterFile $parameterFilePath `
-CertificateThumbprint $thumb `
-CertificateUrlValue $certUrlValue `
-SourceVaultValue $sourceVaultValue `
-Verbose
Nota
Questo passaggio richiederà un po' di tempo, in genere fino a due ore.
L'aggiornamento modificherà le impostazioni a InfrastructureService; pertanto, è necessario un riavvio del nodo. In questo caso, forceRestart viene ignorato. Il parametro upgradeReplicaSetCheckTimeout specifica il tempo massimo in cui Service Fabric attende che una partizione sia in uno stato sicuro, se non lo è già. Dopo aver superato i controlli di sicurezza per tutte le partizioni in un nodo, Service Fabric procederà con l'aggiornamento in tale nodo. Il valore del parametro upgradeTimeout può essere ridotto a 6 ore, ma per garantire la massima sicurezza è consigliabile usare 12 ore.
Al termine della distribuzione, verificare nel portale di Azure che lo stato della risorsa di Service Fabric sia Pronto. Verificare che sia possibile raggiungere il nuovo endpoint di Service Fabric Explorer, lo Stato di integrità del cluster sia OK e tutte le applicazioni distribuite funzionino correttamente.
A questo punto, è stato ridimensionato verticalmente un tipo di nodo primario del cluster!
Passaggi successivi
- Informazioni su come aggiungere un tipo di nodo a un cluster
- Informazioni sulla scalabilità delle applicazioni.
- Ridimensionamento orizzontale di un cluster di Azure.
- Ridimensionamento di un cluster di Azure a livello di codice tramite l'SDK di calcolo di Azure Fluent.
- Ridimensionamento orizzontale di un cluster autonomo.