Perché usare un approccio ai microservizi per la compilazione di applicazioni
Per gli sviluppatori di software, il factoring di un'applicazione in parti componenti non è una novità. In genere viene usato un approccio su più livelli con un archivio nel back-end, la logica di business al livello intermedio e l'interfaccia utente (UI) nel front-end. Ciò che è cambiato negli ultimi anni è il fatto che gli sviluppatori creano ora applicazioni distribuite per il cloud.
Alcune delle esigenze di business che stanno cambiando sono le seguenti:
- Un servizio creato e reso operativo su larga scala per raggiungere i clienti in nuove aree geografiche.
- Offerta più rapida di funzionalità e caratteristiche che rispondano alle richieste dei clienti in modo agile.
- Utilizzo delle risorse migliorato per ridurre i costi.
Queste esigenze aziendali incidono sul modo di compilare le applicazioni.
Per altre informazioni sull'approccio di Azure ai microservizi, vedere Microservizi: una rivoluzione delle applicazioni basata sul cloud.
Confronto tra la progettazione monolitico o quella basata su microservizi
Le applicazioni si evolvono con il trascorrere del tempo. Le applicazioni che hanno maggior successo si evolvono diventando utili per le persone. Le applicazioni che non hanno successo non si evolvono e alla fine vengono deprecate. Questo è il problema: quanto si sa attualmente dei propri requisiti e di come si svilupperanno in futuro? Si supponga, ad esempio, di dover compilare un'applicazione di reporting per un’azienda. Si è certi che l'applicazione viene usata solo in ambito aziendale e che i report non vengono mantenuti a lungo. L'approccio scelto sarà diverso, ad esempio, rispetto a quello che si adotterebbe per creare un servizio per la distribuzione di contenuti video a decine di milioni di clienti.
A volte, il fattore determinante è riuscire a produrre qualcosa che funga da modello di verifica. Si sa che l'applicazione può essere riprogettata in un secondo momento. Tuttavia, non ha molto senso ‘sovra-progettare’ qualcosa che non verrà mai usato. D'altra parte, quando le aziende si affidano al cloud, le loro aspettative sono la crescita e l’uso. La crescita e la scalabilità sono imprevedibili. L’obiettivo è creare un prototipo rapidamente, sapendo anche che l’approccio adottato sarà in grado di gestire il successo futuro. Questo è l'approccio di avvio snello: compilare, misurare, apprendere e ripetere.
Nell'era del client/server si tendeva a concentrarsi sulla compilazione di applicazioni a più livelli, usando tecnologie specifiche a ogni livello. Per questi approcci venne coniata l’espressione di applicazione monolitica. Le interfacce si trovavano di solito tra i diversi livelli e si usava una progettazione accoppiata più strettamente tra i componenti all'interno di ogni livello. Gli sviluppatori progettavano ed eseguivano il factoring delle classi compilate in librerie e collegate insieme in pochi file eseguibili e DLL.
Questo approccio alla progettazione monolitica presenta dei vantaggi. Le applicazioni monolitiche sono spesso più semplici da progettare e le chiamate tra i componenti sono più veloci perché queste chiamate sono spesso comunicazioni interprocesso (IPC). Inoltre, tutti testano un singolo prodotto, cosa che assicura un uso più efficiente delle risorse umane. Lo svantaggio è che si ottiene un accoppiamento stretto fra i livelli e non è possibile ridimensionare i singoli componenti. Se sono necessari aggiornamenti o correzioni, si deve attendere che altri completino i test. È più difficile essere agili.
I microservizi affrontano questi svantaggi e si allineano maggiormente ai requisiti aziendali precedenti. Tuttavia, presentano anche vantaggi e responsabilità. I vantaggi dei microservizi consistono nel fatto che ognuno incapsula solitamente funzionalità aziendali più semplici, che è possibile incrementare o ridurre, testare, distribuire e gestire in modo indipendente. Un vantaggio importante di un approccio incentrato sui microservizi è che i team si basano più sugli scenari aziendali che sulla tecnologia. Team più piccoli sviluppano un microservizio sulla base di uno scenario del cliente, usando le tecnologie che preferiscono.
In altre parole, l'organizzazione non deve necessariamente standardizzarsi sulla tecnologia per mantenere applicazioni di microservizi. I singoli team proprietari dei servizi possono procedere come meglio credono, a seconda dell'esperienza del team stesso o della soluzione più appropriata al problema da risolvere. In pratica, è preferibile avere un set di tecnologie consigliate, ad esempio un particolare archivio NoSQL o un framework di applicazioni Web.
Lo svantaggio dei microservizi è che è necessario gestire entità più separate e gestire distribuzioni e controllo delle versioni più complessi. Il traffico di rete tra i microservizi aumenta insieme alle latenze di rete corrispondenti. I molti servizi frammentati e granulari possono causare un incubo in termini di prestazioni. Senza strumenti che facilitino la visualizzazione di queste dipendenze è difficile avere una "visione" dell'intero sistema.
Sono gli standard che consentono il funzionamento dell'approccio basato su microservizi, definendo la modalità di comunicazione e accettando solo ciò che è necessario ottenere da un servizio, invece di rigidi contratti. È importante definire questi aspetti fin dall'inizio della progettazione, perché i servizi vengono aggiornati in modo indipendente gli uni dagli altri. Un'altra descrizione coniata per la progettazione con approccio basato su microservizi è "SOA (Service Oriented Architecture) con granularità fine".
Al livello più semplice, l'approccio di progettazione basato sui microservizi è una federazione di servizi disaccoppiata, con modifiche indipendenti di ciascuno e standard concordati per la comunicazione.
Man mano che vengono prodotte più app per cloud, si scopre che questa scomposizione dell'app complessiva in servizi indipendenti per scenari specifici è un approccio migliore a lungo termine.
Confronto tra approcci allo sviluppo di applicazioni
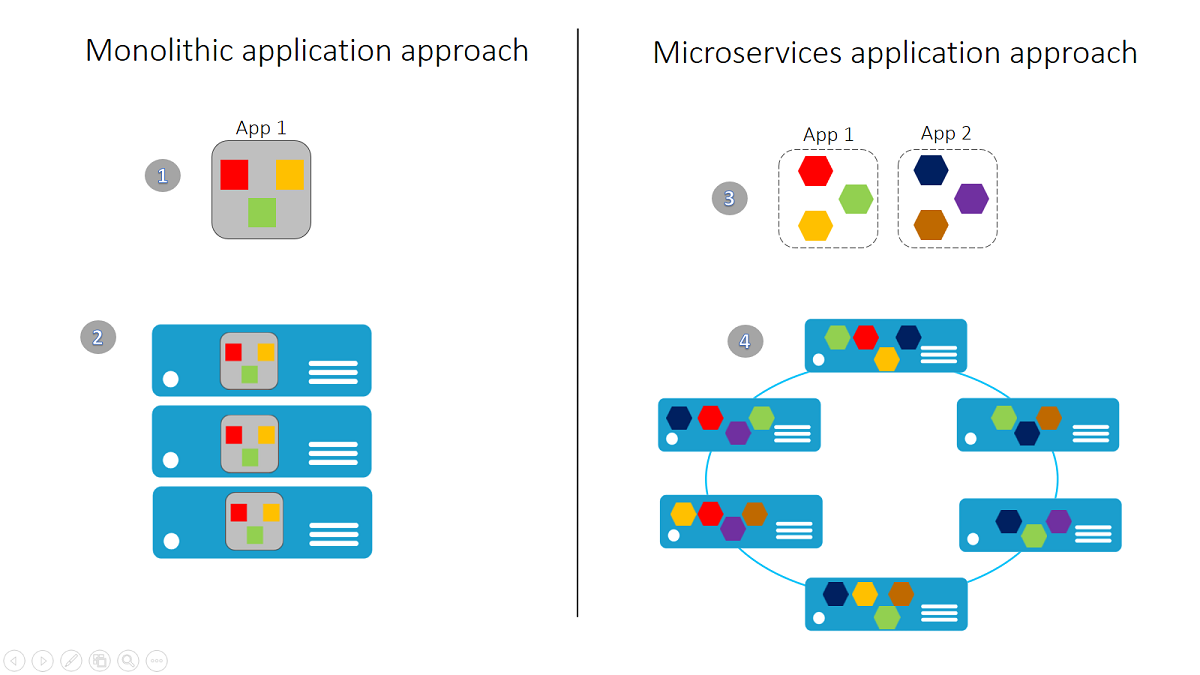
Un'app monolitica include funzionalità specifiche del dominio e normalmente è divisa per livelli di funzionalità, ad esempio Web, business e dati.
Per la scalabilità di un'app monolitica, occorre clonarla in più server/macchine virtuali/contenitori.
Un'applicazione di microservizi separa le funzionalità in servizi più piccoli distinti.
La scalabilità orizzontale di questo approccio basato sui microservizi si ottiene con la distribuzione di ogni servizio in modo indipendente e la creazione di istanze di questi servizi in server/macchine virtuali/contenitori.
La progettazione di un approccio basato sui microservizi non è appropriata per tutti i progetti, ma offre un maggiore allineamento con gli obiettivi di business descritti in precedenza. Un approccio iniziale monolitico può essere accettabile se si sa che in caso di necessità sarà possibile rielaborare il codice in una struttura a microservizi. In genere si inizia con un'applicazione monolitica e quindi la si suddivide lentamente in fasi, a partire dalle aree funzionali che devono essere maggiormente scalabili o agili.
Quando si usa un approccio basato sui microservizi, si compone l'applicazione usando molti servizi di piccole dimensioni. Questi servizi vengono eseguiti in contenitori distribuiti in un cluster di computer. Team più piccoli sviluppano un servizio focalizzato su uno scenario ed eseguono test, controllo delle versioni, distribuzione e ridimensionamento di ogni servizio in modo indipendente, contribuendo all'evoluzione complessiva dell'applicazione.
Che cos'è un microservizio?
Esistono diverse definizioni di microservizi. La maggior parte di queste caratteristiche dei microservizi è tuttavia ampiamente accettata:
- Incapsulano uno scenario aziendale o del cliente. Quale problema si desidera risolvere?
- Sono sviluppati da un piccolo team di progettazione.
- Sono scritti in qualsiasi linguaggio di programmazione usando qualsiasi framework.
- Sono costituiti da codice e facoltativamente da uno stato, entrambi sottoposti al controllo delle versioni, distribuiti e ridimensionati in maniera indipendente.
- Interagiscono con altri microservizi tramite interfacce e protocolli ben definiti.
- Hanno nomi univoci (URL) che vengono usati per risolvere la propria posizione.
- Rimangono coerenti e disponibili in caso di errori.
Per riepilogare:
Le applicazioni di microservizi sono costituite da piccoli servizi rivolti ai clienti, scalabili e sottoposti al controllo delle versioni indipendentemente, che comunicano tra di essi tramite protocolli standard e interfacce ben definite.
Sono scritti in qualsiasi linguaggio di programmazione usando qualsiasi framework.
Gli sviluppatori vogliono essere liberi di scegliere il linguaggio o il framework che preferiscono, a seconda delle loro competenze o delle esigenze del servizio che stanno creando. Per alcuni servizi i vantaggi offerti dalle prestazioni di C++ superano talvolta qualsiasi altro aspetto. Per altri, la facilità di sviluppo gestito ottenuta da C# o Java potrebbe essere più importante. In alcuni casi potrebbe essere necessaria una libreria di terze parti, una tecnologia di archiviazione dati o mezzi per l'esposizione del servizio a client specifici.
Dopo aver scelto una tecnologia, è necessario esaminare la gestione operativa o del ciclo di vita e il ridimensionamento del servizio.
Consentono di sottoporre al controllo delle versioni, distribuire e ridimensionare indipendentemente codice e stato
In qualsiasi modo si decida di scrivere i propri microservizi, il codice e, facoltativamente, lo stato devono poter essere distribuiti, aggiornati e ridimensionati in modo indipendente. Questo problema è difficile da risolvere perché dipende dalla scelta delle tecnologie. Per il ridimensionamento, sapere come partizionare (o condividere) sia il codice che lo stato è complesso. Quando il codice e lo stato usano tecnologie distinte, una tendenza comune al giorno d’oggi, gli script di distribuzione del microservizio devono essere in grado di ridimensionare entrambe. Questa separazione ha a che fare anche con l'agilità e la flessibilità con cui si possono aggiornare alcuni microservizi senza doverli aggiornare tutti contemporaneamente.
Torniamo per un momento al confronto tra l’approccio monolitico e quello basato sui microservizi. Questo diagramma mostra le differenze negli approcci all'archiviazione dello stato:
Archiviazione dello stato nei due approcci
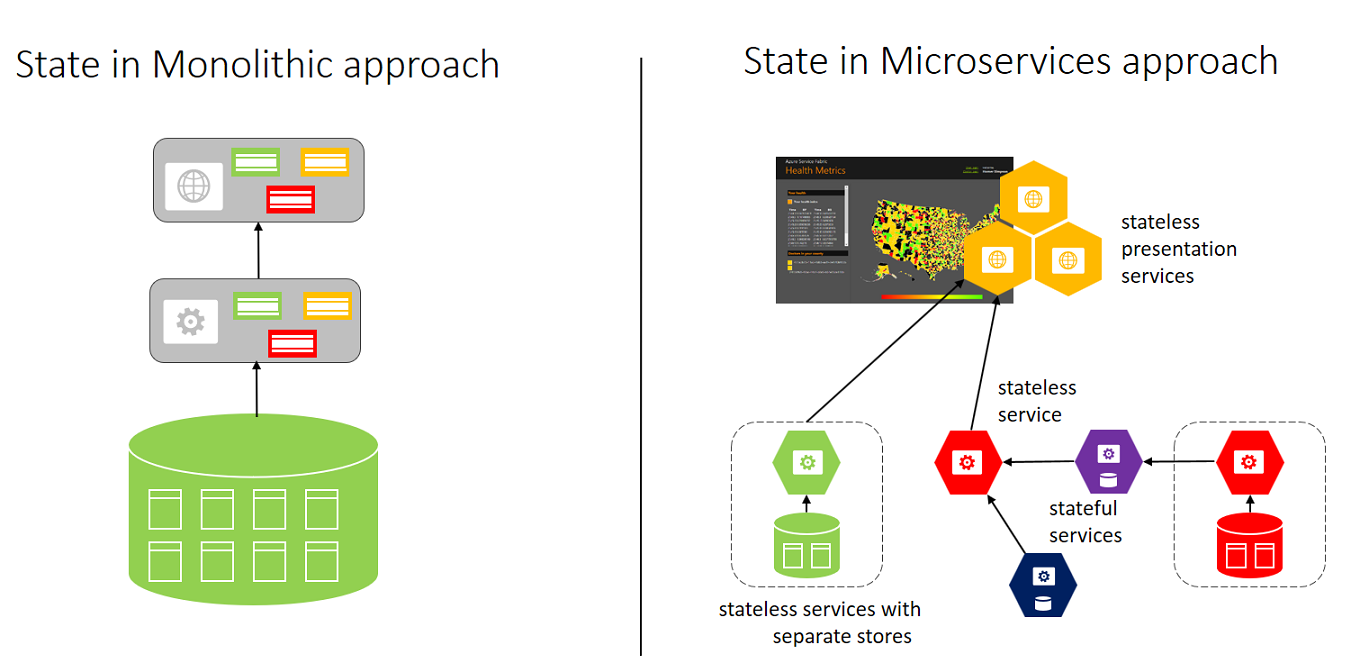
A sinistra l'approccio monolitico con un database singolo e livelli di tecnologie specifiche.
A destra è illustrato l'approccio basato su microservizi, con un grafico dei microservizi interconnessi in cui lo stato presenta in genere un ambito limitato al microservizio e vengono usate molteplici tecnologie.
In un approccio monolitico, l'applicazione usa in genere un database singolo. Il vantaggio di usare un database deriva dal fatto che semplifica la distribuzione poiché si trova in un'unica posizione. Ogni componente può avere una tabella singola per l'archiviazione del relativo stato. La parte più difficile riguarda la necessità che il team separi scrupolosamente lo stato. È inevitabile che qualcuno sia tentato di aggiungere una nuova colonna a una tabella esistente del cliente, creare un join tra le tabelle e creare dipendenze a livello di archiviazione. In questo caso, non sarà possibile ridimensionare i singoli componenti.
Con l'approccio dei microservizi, ogni servizio gestisce e archivia il proprio stato. Ogni servizio è responsabile di ridimensionare sia il codice che lo stato insieme, in modo da soddisfare le richieste del servizio. Un aspetto negativo deriva dal fatto che quando occorre creare viste o query dei dati dell'applicazione, le query devono essere eseguite su archivi che si trovano in più stati. In genere, questo problema si risolve con un microservizio separato che crea una visualizzazione della raccolta di microservizi. Se è necessario eseguire più query specifiche sui dati, sarà necessario valutare se è opportuno scrivere i dati in un servizio di data warehousing per le analisi offline per ogni microservizio.
I microservizi hanno una loro versione. È possibile che versioni diverse di un microservizio vengano eseguite in modalità affiancata. Una versione più recente di un microservizio può generare un errore durante un aggiornamento, nel qual caso è necessario eseguire il rollback a una versione precedente. Il controllo delle versioni è utile anche per l'esecuzione dei test di tipo A/B in cui utenti diversi provano versioni diverse del servizio. Ad esempio, è normale aggiornare un microservizio per consentire a un set specifico di clienti di testare nuove funzionalità prima di implementarlo più diffusamente.
Interagiscono con altri microservizi tramite interfacce ben definite e protocolli.
Negli ultimi 10 anni sono state pubblicate ampie informazioni che descrivono i modelli di comunicazione nelle architetture orientate ai servizi. Di solito la comunicazione tra servizi usa un approccio REST con i protocolli HTTP e TCP e XML o JSON come formato di serializzazione. A livello di interfaccia, si tratta di adottare un approccio di progettazione Web. Nulla vieta tuttavia di usare protocolli binari o formati di dati personalizzati. Tenere presente che gli utenti avranno più difficoltà a usare i microservizi se questi protocolli e formati non sono liberamente disponibili.
Hanno un nome (URL) univoco usato per risolvere il percorso
Il microservizio deve essere indirizzabile ovunque venga eseguito. Se si inizia a pensare ai computer e a chiedersi quale computer esegue un determinato microservizio, presto inizieranno le difficoltà.
Così come il DNS risolve un URL particolare in un computer specifico, il microservizio deve avere un nome univoco per consentire l'individuazione della sua posizione attuale. I microservizi devono avere nomi indirizzabili che siano indipendenti dall'infrastruttura in cui sono in esecuzione. Ciò implica che vi sia un'interazione tra il modo in cui il servizio viene distribuito e il modo in cui viene individuato perché è necessario un registro del servizio. In caso di errore in un computer, il registro del servizio deve indicare dove è stato spostato il servizio.
Rimangono coerenti e disponibili in caso di errori.
Affrontare gli errori imprevisti è uno dei problemi più difficili da risolvere, specialmente in un sistema distribuito. Gran parte del codice scritto dagli sviluppatori serve per gestire le eccezioni. Inoltre, durante i test viene dedicato più tempo alla gestione delle eccezioni. Il problema è più complesso della semplice scrittura di codice per la gestione degli errori. Cosa accade infatti in caso di errore del computer in cui è in esecuzione il microservizio? È necessario rilevare l'errore, che è di per sé un grosso problema. Inoltre, è anche necessario riavviare il microservizio.
Per essere disponibile, un microservizio deve essere resiliente in caso di errori e deve poter essere riavviato in un altro computer. Oltre a questi requisiti di resilienza, non ci devono essere perdite di dati e i dati devono rimanere coerenti.
La resilienza è difficile da raggiungere quando si verificano errori durante l'aggiornamento di un'applicazione. Il microservizio, che interagisce con il sistema di distribuzione, non deve essere ripristinato. Deve decidere se può continuare e passare alla versione più recente oppure eseguire il rollback a una versione precedente, per mantenere uno stato coerente. Occorre porsi alcune domande, ad esempio se sono disponibili computer sufficienti per continuare e come ripristinare le versioni precedenti del microservizio. Per poter prendere queste decisioni, il microservizio deve fornire informazioni sull'integrità.
Segnalano integrità e diagnostica
Anche se è un concetto apparentemente ovvio e spesso trascurato, un microservizio deve segnalare il proprio stato di integrità e fornire dati di diagnostica. In caso contrario, saranno disponibili pochi dettagli relativi all'integrità da un punto di vista operativo. Correlare gli eventi di diagnostica in un set di servizi indipendenti e gestire le differenze di orario dei computer per comprendere l'ordine degli eventi è difficile. Nello stesso modo in cui si interagisce con un microservizio usando protocolli e formati dati concordati, è necessaria una standardizzazione della modalità di registrazione delle informazioni sull'integrità e degli eventi di diagnostica che, alla fine, si traduce in un archivio di eventi che possono essere visualizzati e su cui si possono eseguire query. Con un approccio basato su microservizi, i diversi team devono approvare un unico formato di registrazione. È necessario un approccio coerente alla visualizzazione degli eventi di diagnostica nell'applicazione nel suo complesso.
L'integrità è diversa dalla diagnostica. Per integrità si intende la segnalazione dello stato corrente da parte del microservizio per consentire l'esecuzione di azioni appropriate. Un esempio efficace riguarda l'interazione con i meccanismi di aggiornamento e distribuzione per assicurare la disponibilità. Benché un servizio possa non essere attualmente integro a causa dell'arresto anomalo di un processo o del riavvio di un computer, potrebbe comunque essere ancora operativo. L'ultima cosa di cui uno ha bisogno è che la situazione peggiori quando di avvia un aggiornamento. L'approccio migliore è procedere prima di tutto a un'indagine o attendere il ripristino del microservizio. Gli eventi di integrità di un microservizio consentono di prendere decisioni informate e favoriscono in effetti la creazione di servizi con funzionalità di riparazione automatica.
Linee guida per la progettazione di microservizi in Azure
Visitare il Centro architetture di Azure per indicazioni sulla progettazione e compilazione di microservizi in Azure.
Service Fabric come piattaforma di microservizi
Azure Service Fabric è nato in seguito alla transizione operata da Microsoft dalla fornitura di prodotti preconfezionati, generalmente di tipo monolitico, alla fornitura di servizi. Service Fabric è stato plasmato dall'esperienza acquisita con la creazione e la gestione di servizi di grandi dimensioni, come database SQL di Azure e Azure Cosmos DB. La piattaforma si è evoluta nel tempo con l'adozione di un numero di servizi sempre maggiore. Service Fabric doveva poter essere eseguito non solo in Azure, ma anche autonomamente nelle distribuzioni di Windows Server.
Lo scopo di Service Fabric consiste nel risolvere i difficili problemi di compilazione ed esecuzione di un servizio e di utilizzo efficiente delle risorse dell'infrastruttura, per consentire ai team di risolvere i problemi aziendali tramite un approccio basato su microservizi.
Service Fabric consente di creare applicazioni che usano un approccio basato sui microservizi offrendo:
- Piattaforma con servizi di sistema per distribuire, aggiornare e trovare servizi, rilevare e riavviare i servizi con problemi, inoltrare messaggi, gestire lo stato e monitorare l'integrità.
- Possibilità di distribuire applicazioni eseguite in contenitori o sotto forma di processi. Service Fabric è una struttura per la gestione di contenitori e processi.
- API di programmazione produttive che facilitano la compilazione di applicazioni come microservizi: ASP.NET Core, Reliable Actors e Reliable Services. Ad esempio, è possibile ottenere informazioni su integrità e diagnostica o sfruttare la disponibilità elevata predefinita.
Service Fabric è indipendente dalla modalità di compilazione del servizio, quindi è possibile usare qualsiasi tecnologia. Tuttavia offre API di programmazione predefinite che facilitano la compilazione dei microservizi.
Migrazione di applicazioni esistenti a Service Fabric
Service Fabric consente di riutilizzare il codice esistente e di modernizzarlo con nuovi microservizi. La modernizzazione delle applicazioni prevede cinque fasi ed è possibile iniziare e terminare con una qualsiasi di queste. Le fasi sono:
- Iniziare con un'applicazione monolitica tradizionale.
- Migrazione. Usare contenitori o file eseguibili guest per ospitare in Service Fabric il codice esistente.
- Modernizzare. Aggiungere nuovi microservizi insieme al codice in contenitori esistente.
- Innova. Suddividere l'applicazione monolitica in microservizi in base alle esigenze.
- Trasformare le applicazioni in microservizi. Trasformare le applicazioni monolitiche esistenti o creare nuove applicazioni greenfield.
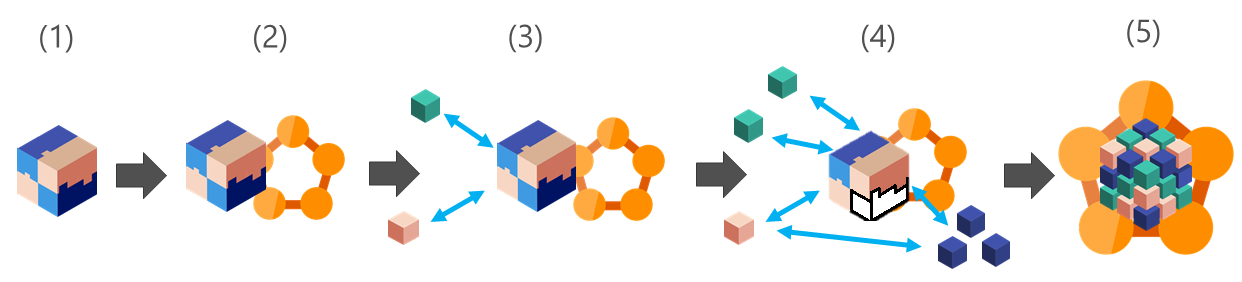
Tenere presente che è possibile iniziare e arrestarsi in una di queste fasi. Non è necessario passare alla fase successiva.
Di seguito sono elencati esempi per ogni fase.
Migrazione
Molte aziende stanno eseguendo la migrazione di applicazioni monolitiche esistenti in contenitori per due motivi:
- Riduzione dei costi derivante dal consolidamento e dalla rimozione dell'hardware esistente o dall'esecuzione di applicazioni a maggior densità.
- Contratti di distribuzione uniformi tra i settori sviluppo e operazioni.
Facilità di riduzione dei costi. In Microsoft molte applicazioni esistenti vengono incluse in contenitori, con un conseguente risparmio di milioni di dollari. L'impatto della distribuzione uniforme è più difficile da valutare, ma ugualmente importante. Significa che gli sviluppatori possono scegliere le tecnologie adatte, ma che le operazioni accetteranno solo un unico metodo per la distribuzione e la gestione delle applicazioni. Riduce le attività operative derivanti dalla necessità di gestire la complessità del supporto di tecnologie diverse senza forzare gli sviluppatori a scegliere solo determinate tecnologie. In termini semplici, ogni applicazione viene inserita in un'immagine di distribuzione autonoma.
Per molte organizzazioni il processo termina qui. I vantaggi dei contenitori sono già presenti e Service Fabric offre un'esperienza di gestione completa con distribuzione, inclusi gli aggiornamenti, il controllo delle versioni, il ripristino dello stato precedente, il monitoraggio dell'integrità e così via.
Modernizzare
La modernizzazione consiste nell'aggiunta di nuovi servizi al codice esistente nei contenitori. Se si prevede di scrivere nuovo codice, è consigliabile orientarsi gradualmente verso i microservizi. Questo approccio può comportare aggiungere un nuovo endpoint API REST o una nuova logica di business. In questo modo è possibile iniziare a compilare nuovi microservizi e acquisire pratica con lo sviluppo e la distribuzione.
Innovazione
Un approccio basato su microservizi è in grado di gestire eventuali cambiamenti nelle esigenze aziendali. In questa fase, è necessario decidere se iniziare a suddividere l'applicazione monolitica in servizi o innovare. Un esempio classico è quando un database usato come coda del flusso di lavoro diventa un collo di bottiglia a livello di elaborazione. Se il numero di richieste del flusso di lavoro aumenta è necessario suddividere in scala il carico di lavoro. Questo è il caso di un componente dell'applicazione che non supporta il ridimensionamento o che necessita di aggiornamenti più frequenti per il quale è opportuno adottare un approccio innovativo e ripartire il carico tra più microservizi.
Trasformare le applicazioni in microservizi
In questa fase, l'applicazione è completamente composta (o suddivisa in) microservizi. Per raggiungere questo risultato, è stato seguito l’approccio ai microservizi. È possibile iniziare da questa fase, ma una scelta di questo tipo senza il supporto di una piattaforma per microservizi rappresenta un investimento significativo.
I microservizi sono appropriati per l'applicazione in uso?
È possibile. In Microsoft, molti hanno realizzato i vantaggi derivanti dall'adozione di un approccio simile a un microservizio man mano che più team hanno iniziato a creare per il cloud per motivi aziendali. Bing, ad esempio, usa i microservizi da anni. Per altri team, l'approccio basato su microservizi era una novità. I team riscontravano problemi difficili da risolvere ed estranei alle loro aree di competenza principali. Ecco perché Service Fabric si è affermato come tecnologia preferita per la compilazione di servizi.
L'obiettivo di Service Fabric è ridurre le complessità della compilazione di applicazioni di microservizi, in modo da evitare di dover affrontare molte attività di riprogettazione costose. Iniziare con piccole soluzioni, ridimensionarle secondo le esigenze, deprecare servizi, aggiungerne di nuovi ed evolversi secondo le esigenze di utilizzo del cliente. È anche evidente che devono essere ancora risolti molti altri problemi per rendere i microservizi più accessibili per la maggior parte degli sviluppatori. I contenitori e il modello di programmazione degli attori sono esempi di piccoli passaggi in questa direzione. Si è certi che emergeranno più innovazioni per semplificare l'approccio ai microservizi.