Architettura di Service Fabric
Service Fabric è costituito da sottosistemi a più livelli. Tali sottosistemi consentono di scrivere applicazioni con le caratteristiche seguenti:
- Disponibilità elevata
- Scalabile
- Gestione
- Testabilità
Il diagramma seguente illustra i sottosistemi principali di Service Fabric.
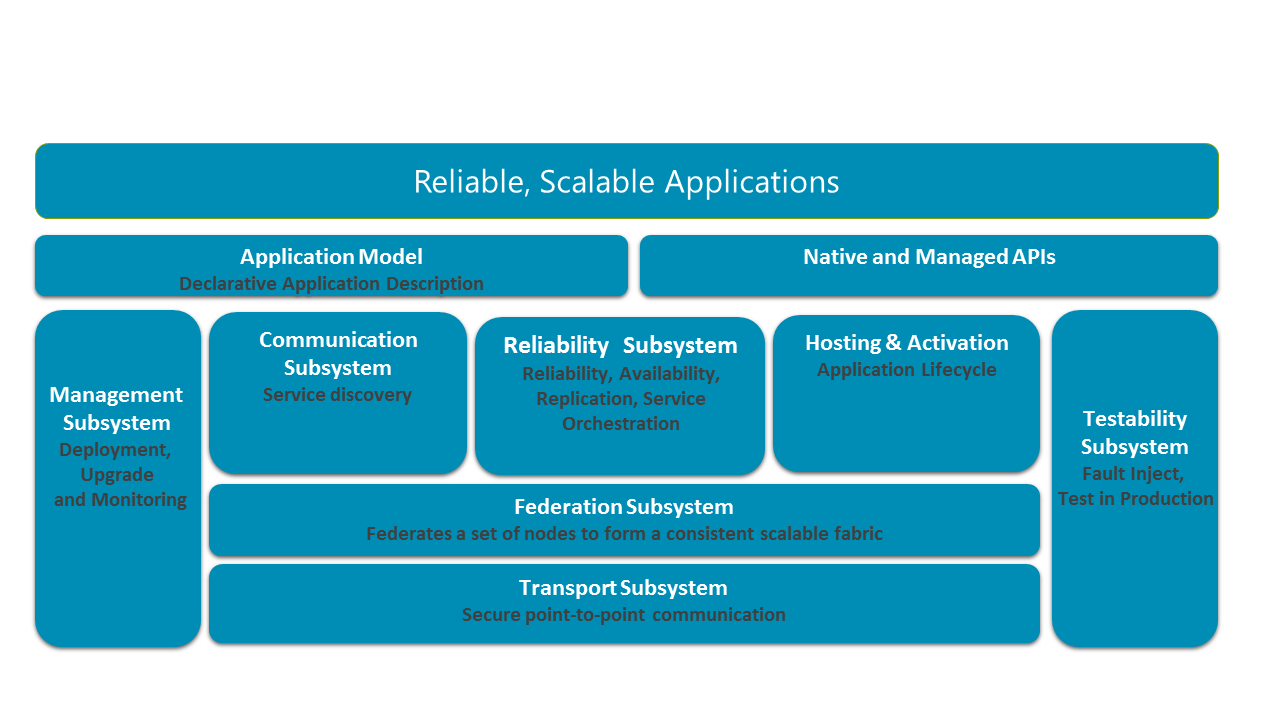
In un sistema distribuito è fondamentale poter comunicare in modo sicuro tra nodi in un cluster. Alla base dello stack è presente il sottosistema di trasporto, che fornisce una comunicazione sicura tra i nodi. Al di sopra del sottosistema di trasporto si trova il sottosistema di federazione, che raggruppa i diversi nodi in una singola entità denominata cluster, in modo che Service Fabric possa rilevare gli errori, eseguire l'algoritmo di elezione e garantire la coerenza del routing. Il sottosistema di affidabilità, posizionato al di sopra del sottosistema di federazione, è responsabile dell'affidabilità dei servizi di Service Fabric mediante meccanismi come la replica, la gestione delle risorse e il failover. Al di sotto del sottosistema di federazione si trova anche il sottosistema di hosting e attivazione, che gestisce il ciclo di vita di un'applicazione in un singolo nodo. Il sottosistema di gestione gestisce il ciclo di vita di applicazioni e servizi. Il sottosistema di testabilità consente agli sviluppatori di applicazioni di testare i servizi mediante errori simulati prima e dopo aver distribuito applicazioni e servizi in ambienti di produzione. Service Fabric consente anche di risolvere le posizioni dei servizi mediante il sottosistema di comunicazione. I modelli di programmazione delle applicazioni esposti agli sviluppatori sono disposti sopra questi sottosistemi con il modello di applicazione per abilitare gli strumenti.
Sottosistema di trasporto
Il sottosistema di trasporto implementa un canale di comunicazione tramite diagrammi point-to-point. Questo canale viene usato per le comunicazioni all'interno del cluster di Service Fabric e tra il cluster e i client di Service Fabric. Supporta i modelli di comunicazione di richiesta/risposta e unidirezionali, che forniscono la base per l'implementazione di broadcast e multicast a livello di federazione. Il sottosistema di trasporto protegge le comunicazioni mediante certificati X509 o la sicurezza di Windows. Questo sottosistema viene usato internamente da Service Fabric e non è direttamente accessibile agli sviluppatori per la programmazione di un'applicazione.
Sottosistema di federazione
Per controllare un set di nodi in un sistema distribuito, è necessaria una vista uniforme del sistema. Il sottosistema di federazione usa le primitive di comunicazione fornite dal sottosistema di trasporto e unisce i diversi nodi in un singolo cluster unificato che è in grado di controllare. Fornisce ai sistemi distribuiti le primitive necessarie per gli altri sottosistemi, ovvero il rilevamento degli errori, l'algoritmo di elezione e la coerenza del routing, Il sottosistema di federazione si basa su tabelle hash distribuite con uno spazio di token di 128 bit. Il sottosistema crea una topologia ad anello sui nodi, in cui a ogni nodo dell'anello viene allocato un sottoinsieme dello spazio di token per la proprietà. Per il rilevamento degli errori, il livello usa un meccanismo di lease basato su heartbeat e arbitraggio. Il sottosistema di federazione garantisce inoltre tramite intricati protocolli di join e partenza che esista un solo proprietario di token per volta. Ciò consente di offrire garanzie di algoritmi di elezione e routing coerenti.
Sottosistema di affidabilità
Il sottosistema di affidabilità offre il meccanismo che consente l'elevata disponibilità dello stato di un servizio di Service Fabric tramite l'uso del replicatore, di Gestione failover e del servizio di bilanciamento delle risorse.
- Il replicatore verifica che i cambiamenti di stati nella replica di servizi primaria vengano replicati automaticamente nelle repliche secondarie, mantenendo la coerenza tra le repliche primaria e secondarie in un set di repliche di servizi. Il replicatore è responsabile della gestione del quorum tra le repliche nel set di repliche. Interagisce con l'unità di failover per ottenere l'elenco di operazioni da replicare e l'agente di riconfigurazione gli fornisce la configurazione del set di repliche. Tale configurazione indica le operazioni di replica che devono essere replicate. Service Fabric fornisce un replicatore predefinito denominato Fabric Replicator, che può essere usato dall'API del modello di programmazione in modo da garantire l'elevata disponibilità e l'affidabilità dello stato dei servizi.
- Gestione failover garantisce che con l'aggiunta o la rimozione di nodi dal cluster, il carico venga automaticamente ridistribuito tra i nodi disponibili. Se si verifica un errore in un nodo del cluster, il cluster riconfigurerà automaticamente le repliche di servizi per mantenere la disponibilità.
- Resource Manager inserisce le repliche del servizio tra domini di errore nel cluster e garantisce che tutte le unità di failover siano operative. Resource Manager applica inoltre il bilanciamento delle risorse del servizio al pool condiviso sottostante di nodi del cluster per garantire una distribuzione del carico uniforme e ottimale.
Sottosistema di gestione
Il sottosistema di gestione offre una gestione del ciclo di vita dell'applicazione e dei servizi end-to-end. I cmdlet di PowerShell e le API amministrative consentono di effettuare il provisioning, la distribuzione, l'applicazione di patch, l'aggiornamento e il deprovisioning di applicazioni senza perdita di disponibilità. A tale scopo, il sottosistema di gestione usa i servizi seguenti:
- Cluster Manager: servizio primario che interagisce con Gestione failover dai componenti di affidabilità per posizionare le applicazioni nei nodi in base ai vincoli di posizionamento dei servizi. Resource Manager nei sottosistemi di failover garantisce che i vincoli non vengano mai violati. Cluster Manager gestisce il ciclo di vita delle applicazioni dal provisioning al deprovisioning. Si integra con Health Manager per garantire che durante gli aggiornamenti la disponibilità delle applicazioni non vada perduta dal punto di vista dell'integrità semantica.
- Health Manager: questo servizio consente il monitoraggio dell'integrità di applicazioni e servizi ed entità del cluster. Le entità del cluster, ad esempio nodi, partizioni di servizi e repliche, possono segnalare informazioni sull'integrità, che vengono quindi aggregate nell'archivio integrità centralizzato. Queste informazioni sull'integrità forniscono uno snapshot dell'integrità globale in un determinato momento per i servizi e i nodi distribuiti in più nodi del cluster, consentendo così di intraprendere le azioni correttive necessarie. Le API di query sull'integrità consentono di eseguire query sugli eventi di integrità segnalati al sottosistema di integrità. Queste API restituiscono dati sull'integrità non elaborati archiviati nell'archivio integrità oppure restituiscono i dati sull'integrità interpretati e aggregati per una specifica entità del cluster.
- Archivio immagini: questo servizio consente l'archiviazione e la distribuzione di file binari delle applicazioni. Offre un semplice archivio di file distribuito in cui vengono caricate o da cui vengono scaricate le applicazioni.
Sottosistema di hosting
Cluster Manager indica al sottosistema di hosting (in esecuzione in ogni nodo) i servizi che devono essere gestiti per un determinato nodo. Il sottosistema di hosting gestisce quindi il ciclo di vita dell'applicazione in tale nodo. Interagisce con i componenti di affidabilità e integrità per garantire che le repliche siano posizionate correttamente e siano integre.
Sottosistema di comunicazione
Questo sottosistema offre messaggistica affidabile nel cluster e rilevamento dei servizi mediante il servizio Naming. Il servizio Naming risolve i nomi del servizio in una posizione nel cluster e consente agli utenti di gestire i nomi e le proprietà del servizio. Usando il servizio Naming, i client possono comunicare in modo sicuro con i nodi del cluster per risolvere il nome di un servizio e recuperare i metadati di un servizio. Usando una semplice API client Naming, gli utenti di Service Fabric possono sviluppare servizi e client in grado di risolvere il percorso di rete corrente nonostante il dinamismo dei nodi o il ridimensionamento del cluster.
Sottosistema di testabilità
Il sottosistema di testabilità è costituito da strumenti progettati specificamente per il test di servizi basati su Service Fabric. Gli strumenti consentono a uno sviluppatore di causare, in modo semplice, errori significativi ed eseguire scenari di test per verificare e convalidare i numerosi stati e le transizioni sperimentate da un servizio nel corso della durata, il tutto in modo controllato e sicuro. Questo sottosistema fornisce anche un meccanismo per eseguire test prolungati in grado di eseguire l'iterazione di diversi possibili errori senza perdere la disponibilità fornendo un ambiente di testing in produzione.