Esercitazione: Ottimizzare l'indicizzazione usando l'API push
Ricerca di intelligenza artificiale di Azure supporta due approcci di base per l'importazione dei dati in un indice di ricerca: eseguire il push dei dati nell'indice a livello di codice o eseguire il pull dei dati puntando un indicizzatore di Ricerca intelligenza artificiale di Azure a un'origine dati supportata.
Questa esercitazione illustra come indicizzare i dati in modo efficiente con il modello push eseguendo l'invio in batch delle richieste e usando una strategia di ripetizione dei tentativi con backoff esponenziale. È possibile scaricare ed eseguire l'applicazione di esempio. Questo articolo illustra gli aspetti principali dell'applicazione e quali fattori sono da considerare quando si indicizzano i dati.
Questa esercitazione usa C# e la libreria Azure.Search.Documents di Azure SDK per .NET per eseguire le attività seguenti:
- Creare un indice
- Testare diverse dimensioni di batch per determinare quelle più efficienti
- Indicizzare i batch in modo asincrono
- Usare più thread per aumentare la velocità di indicizzazione
- Usare una strategia di ripetizione di tentativi di backoff esponenziale per eseguire nuovi tentativi con i documenti che presentano errori
Prerequisiti
Per questa esercitazione sono necessari i servizi e gli strumenti seguenti.
Una sottoscrizione di Azure. Se non si ha un account, è possibile crearne uno gratuito.
Visual Studio, qualsiasi edizione. Il codice di esempio e le istruzioni sono stati testati nell'edizione Community Edition gratuita.
Scaricare i file
Il codice sorgente per questa esercitazione si trova nella cartella optimize-data-indexing/v11 nel repository GitHub azure-Samples/azure-search-dotnet-scale .
Considerazioni essenziali
I fattori che influiscono sulla velocità di indicizzazione sono elencati di seguito. Per altre informazioni, vedere Indicizzare set di dati di grandi dimensioni.
- Livello di servizio e numero di partizioni/repliche: l'aggiunta di partizioni o l'aggiornamento del livello aumenta la velocità di indicizzazione.
- Complessità dello schema dell'indice: l'aggiunta di campi e proprietà dei campi riduce la velocità di indicizzazione. Gli indici più piccoli sono più veloci da indicizzare.
- Dimensioni batch: le dimensioni ottimali del batch variano in base allo schema dell'indice e al set di dati.
- Numero di thread/ruoli di lavoro: un singolo thread non sfrutta appieno le velocità di indicizzazione.
- Strategia di ripetizione dei tentativi: una strategia di ripetizione dei tentativi di backoff esponenziale è una procedura consigliata per l'indicizzazione ottimale.
- Velocità di trasferimento dei dati di rete: la velocità di trasferimento dei dati può essere un fattore di limitazione. Indicizzare i dati all'interno dell'ambiente Azure per aumentare la velocità di trasferimento dei dati.
Passaggio 1: Creare un servizio di ricerca di intelligenza artificiale di Azure
Per completare questa esercitazione, è necessario un servizio di ricerca di intelligenza artificiale di Azure, che è possibile creare nel portale di Azure o trovare un servizio esistente nella sottoscrizione corrente. È consigliabile usare lo stesso livello che si prevede di usare nell'ambiente di produzione, per poter testare e ottimizzare la velocità di indicizzazione in modo accurato.
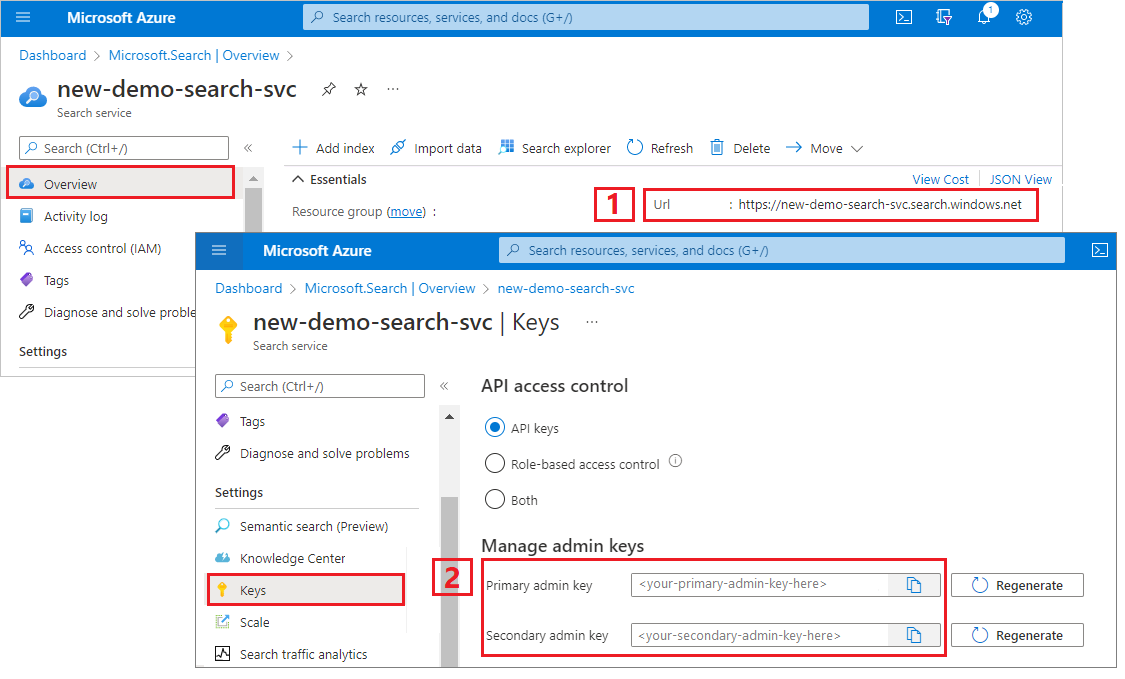
Ottenere una chiave di amministratore e un URL per Ricerca di intelligenza artificiale di Azure
Questa esercitazione usa l'autenticazione basata su chiave. Copiare una chiave API amministratore da incollare nel file appsettings.json.
Accedere al portale di Azure. Ottenere l'URL dell'endpoint dalla pagina panoramica del servizio di ricerca. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi ottenere una chiave amministratore per diritti completi sul servizio. Sono disponibili due chiavi amministratore interscambiabili, fornite per continuità aziendale nel caso in cui sia necessario eseguire il rollover di una di esse. È possibile usare la chiave primaria o secondaria nelle richieste per l'aggiunta, la modifica e l'eliminazione di oggetti.
Passaggio 2: Configurare l'ambiente
Avviare Visual Studio e aprire OptimizeDataIndexing.sln.
In Esplora soluzioni aprire appsettings.json per fornire le informazioni di connessione del servizio.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Passaggio 3: Esplorare il codice
Dopo l'aggiornamento di appsettings.json, il programma di esempio in OptimizeDataIndexing.sln sarà pronto per la compilazione e l'esecuzione.
Questo codice è derivato dalla sezione C# di Avvio rapido: Ricerca full-text con gli SDK di Azure. In tale articolo sono disponibili informazioni più dettagliate sulle nozioni di base per l'uso di .NET SDK.
Questa semplice app console in C#/.NET esegue le attività seguenti:
- Crea un nuovo indice basato sulla struttura dei dati della classe C#
Hotel(che fa riferimento anche allaAddressclasse ) - Testa diverse dimensioni di batch per determinare quelle più efficienti
- Indicizza i dati in modo asincrono
- Usando più thread per aumentare la velocità di indicizzazione
- Usando una strategia di ripetizione dei tentativi con backoff esponenziale per gli elementi con errori
Prima di eseguire il programma, esaminare il codice e le definizioni di indice per questo esempio. Il codice rilevante si trova in diversi file:
- Hotel.cs e Address.cs contengono lo schema che definisce l'indice
- DataGenerator.cs contiene una classe semplice per facilitare la creazione di grandi quantità di dati degli alberghi
- ExponentialBackoff.cs contiene il codice per ottimizzare il processo di indicizzazione, come descritto in questo articolo
- Program.cs contiene funzioni per creare ed eliminare l'indice di Ricerca di intelligenza artificiale di Azure, indicizza i batch di dati e testa diverse dimensioni di batch
Creare l'indice
Questo programma di esempio usa Azure SDK per .NET per definire e creare un indice di Ricerca di intelligenza artificiale di Azure. Sfrutta la classe FieldBuilder per generare una struttura di indice da una classe di modello di dati C#.
Il modello di dati è definito dalla Hotel classe , che contiene anche riferimenti alla Address classe . FieldBuilder esegue il drill-down attraverso più definizioni di classi per generare una struttura dei dati complessa per l'indice. I tag di metadati vengono usati per definire gli attributi di ogni campo, ad esempio se è ordinabile o ricercabile.
I frammenti di codice seguenti del file Hotel.cs illustrano come sia possibile specificare un singolo campo e un riferimento a un'altra classe di modello di dati.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Nel file Program.cs l'indice è definito con un nome e una raccolta di campi generata dal metodo FieldBuilder.Build(typeof(Hotel)) e viene quindi creato come segue:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Genera dati
Nel file DataGenerator.cs viene implementata una classe semplice per generare i dati per i test. L'unico scopo di questa classe è facilitare la creazione di un numero elevato di documenti con ID univoco per l'indicizzazione.
Per ottenere un elenco di 100.000 hotel con ID univoci, eseguire le righe di codice seguenti:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
A scopo di test, in questo esempio sono disponibili due tipi di albergo: small e large.
Lo schema dell'indice ha un effetto sulle velocità di indicizzazione. Per questo motivo, è opportuno convertire questa classe per generare dati che corrispondano meglio allo schema di indice previsto dopo l'esecuzione di questa esercitazione.
Passaggio 4: Testare le dimensioni dei batch
Per caricare uno o più documenti in un indice, Ricerca di intelligenza artificiale di Azure supporta le API seguenti:
L'indicizzazione di documenti in batch migliora significativamente le prestazioni di indicizzazione. Questi batch possono essere fino a 1.000 documenti o fino a circa 16 MB per batch.
Determinare le dimensioni ottimali dei batch per i dati è fondamentale per ottimizzare la velocità di indicizzazione. I due fattori principali che influiscono sulle dimensioni ottimali dei batch sono i seguenti:
- Schema dell'indice
- Dimensioni dei dati
Dato che le dimensioni ottimali dei batch dipendono dall'indice e dai dati, l'approccio migliore consiste nel testare dimensioni di batch diverse per determinare quali garantiscono la velocità di indicizzazione più elevata per lo scenario specifico.
La funzione seguente illustra un approccio semplice per testare le dimensioni dei batch.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Dato che non tutti i documenti sono delle stesse dimensioni (nonostante in questo esempio lo siano), si stimano le dimensioni dei dati inviati al servizio di ricerca. A tale scopo, è possibile usare la funzione seguente che converte prima l'oggetto in json e quindi ne determina le dimensioni in byte. Questa tecnica consente di determinare le dimensioni di batch più efficienti in termini di velocità di indicizzazione in MB/s.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
La funzione richiede un SearchClient più il numero di tentativi da testare per ogni dimensione di batch. Poiché potrebbe esserci variabilità nei tempi di indicizzazione per ogni batch, provare ogni batch tre volte per impostazione predefinita per rendere i risultati più significativi statisticamente.
await TestBatchSizesAsync(searchClient, numTries: 3);
Quando si esegue la funzione, nella console dovrebbe essere visualizzato un output simile all'esempio seguente:
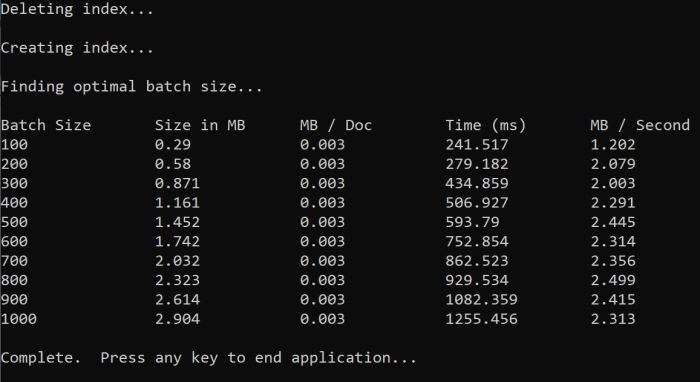
Identificare le dimensioni di batch più efficienti e quindi usare tali dimensioni nel passaggio successivo dell'esercitazione. Tra le diverse dimensioni di batch si potrebbe riscontrare una stabilizzazione dei MB/s.
Passaggio 5: Indicizzare i dati
Ora che sono state identificate le dimensioni del batch che si intende usare, il passaggio successivo consiste nell'iniziare a indicizzare i dati. Per indicizzare i dati in modo efficiente, questo esempio:
- usa più thread/ruoli di lavoro
- implementa una strategia di ripetizione dei tentativi di backoff esponenziale
Rimuovere il commento dalle righe da 41 a 49 e quindi rieseguire il programma. In questa esecuzione, l'esempio genera e invia batch di documenti, fino a 100.000 se si esegue il codice senza modificare i parametri.
Usare più thread/ruoli di lavoro
Per sfruttare appieno la velocità di indicizzazione di Ricerca di intelligenza artificiale di Azure, usare più thread per inviare simultaneamente richieste di indicizzazione in batch al servizio.
Alcune delle considerazioni chiave indicate in precedenza possono influire sul numero ottimale di thread. È possibile modificare questo esempio ed eseguire test con diversi conteggi dei thread per determinare il conteggio ottimale per lo scenario specifico. Con l'esecuzione simultanea di diversi thread, comunque, dovrebbe essere possibile sfruttare la maggior parte dei vantaggi in termini di efficienza.
Quando si aumentano le richieste che raggiungono il servizio di ricerca, potrebbero essere visualizzati codici di stato HTTP che indicano che la richiesta non è stata interamente completata. Durante l'indicizzazione, i due codici di stato HTTP comuni sono i seguenti:
- 503 Servizio non disponibile: questo errore indica che il sistema è sottoposto a un carico elevato e che la richiesta non può essere elaborata in questo momento.
- 207 Multi-Status: questo errore indica che alcuni documenti hanno avuto esito positivo, ma almeno un errore.
Implementare una strategia di ripetizione dei tentativi con backoff esponenziale
Se si verifica un errore, le richieste dovranno essere ripetute usando una strategia di ripetizione dei tentativi con backoff esponenziale.
.NET SDK di Ricerca di intelligenza artificiale di Azure ripete automaticamente le richieste con codice 503 e le altre richieste non riuscite, ma per ripetere le richieste con codice 207 è necessario implementare una logica personalizzata. Strumenti open source come Polly possono essere utili in una strategia di ripetizione dei tentativi.
In questo esempio si implementa una strategia di ripetizione dei tentativi con backoff esponenziale. Si definiscono prima di tutto alcune variabili, tra cui maxRetryAttempts e il valore iniziale di delay per una richiesta non riuscita:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
I risultati dell'operazione di indicizzazione sono archiviati nella variabile IndexDocumentResult result. Questa variabile è importante perché consente di verificare se i documenti nel batch non sono riusciti, come illustrato nell'esempio seguente. In caso di errore parziale, viene creato un nuovo batch in base all'ID dei documenti con l'errore.
È anche necessario rilevare le eccezioni RequestFailedException, perché indicano che la richiesta non è completamente riuscita e dovrà essere ritentata.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Da qui, eseguire il wrapping del codice backoff esponenziale in una funzione in modo che possa essere facilmente chiamato.
Viene quindi creata un'altra funzione per gestire i thread attivi. Per semplicità, questa funzione non è inclusa, ma è disponibile in ExponentialBackoff.cs. La funzione può essere chiamata con il comando seguente, dove hotels rappresenta i dati da caricare, 1000 la dimensione dei batch e 8 il numero di thread simultanei:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Quando si esegue la funzione, verrà visualizzato un output:
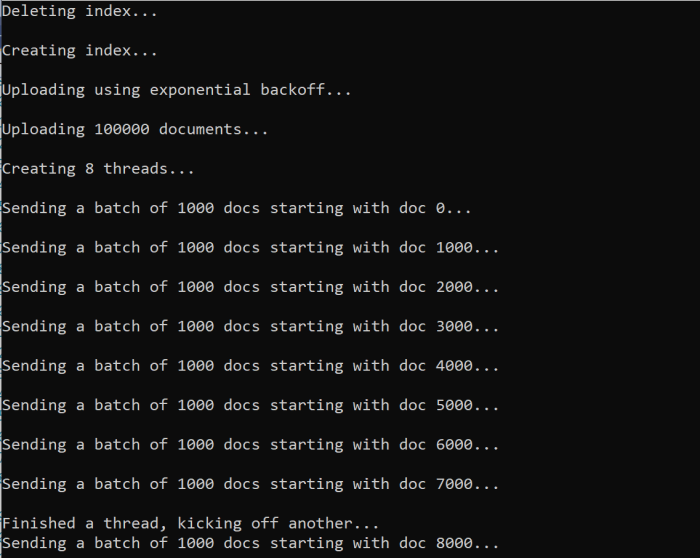
Quando un batch di documenti ha esito negativo, viene visualizzato un errore che indica l'errore e che verrà eseguito un nuovo tentativo:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Al termine dell'esecuzione della funzione, è possibile verificare che tutti i documenti siano stati aggiunti all'indice.
Passaggio 6: Esplorare l'indice
È possibile esplorare l'indice di ricerca popolato dopo l'esecuzione del programma a livello di codice o tramite Esplora ricerche nel portale di Azure.
A livello di codice
Per verificare il numero di documenti in un indice sono disponibili due opzioni principali: l'API di conteggio dei documenti e l'API di recupero delle statistiche dell'indice. Entrambi i percorsi richiedono tempo per l'elaborazione, quindi non essere allarmati se il numero di documenti restituiti inizialmente è inferiore a quello previsto.
Conteggio documenti
L'operazione di conteggio dei documenti recupera un conteggio del numero di documenti in un indice di ricerca:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Ottenere le statistiche di un indice
L'operazione di recupero delle statistiche dell'indice restituisce il numero di documenti per l'indice corrente, nonché l'utilizzo dello spazio di archiviazione. L'aggiornamento delle statistiche sugli indici richiede più tempo rispetto al numero di documenti.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Portale di Azure
Nel portale di Azure, dal riquadro di spostamento sinistro e trovare l'indice di ottimizzazione nell'elenco Indici.

I valori di Conteggio documenti e Dimensioni archiviazione sono basati sull'API di recupero delle statistiche dell'indice e il loro aggiornamento potrebbe richiedere alcuni minuti.
Reimpostare ed eseguire di nuovo
Nelle prime fasi di sviluppo sperimentali, l'approccio più pratico per l'iterazione di progetto consiste nell'eliminare gli oggetti da Azure AI Search e consentire al codice di ricompilarli. I nomi di risorsa sono univoci. L'eliminazione di un oggetto consente di ricrearlo usando lo stesso nome.
Il codice di esempio per questa esercitazione verifica la presenza di indici esistenti e li elimina affinché sia possibile eseguire nuovamente il codice.
È anche possibile usare il portale di Azure per eliminare gli indici.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggio successivo
Per altre informazioni sull'indicizzazione di grandi quantità di dati, provare l'esercitazione seguente.