Esercitazione: Indicizzare da più origini dati con .NET SDK
Azure AI Search consente di importare, analizzare e indicizzare i dati provenienti da più origini dati in un singolo indice di ricerca consolidato.
Questa esercitazione su C# usa la libreria client Azure.Search.Documents in Azure SDK per .NET per indicizzare dati di hotel di esempio di un database Azure Cosmos DB, e unirli ai dettagli sulle camere di hotel tratti dai documenti di Archiviazione BLOB di Azure. Il risultato sarà un indice di ricerca hotel combinato contenente documenti di hotel, con le camere come tipi di dati complessi.
In questa esercitazione verranno eseguite le attività seguenti:
- Caricare dati di esempio e creare le origini dati
- Identificare la chiave dei documenti
- Definire e creare l'indice
- Indicizzare i dati dell'hotel da Azure Cosmos DB
- Unire i dati delle camere provenienti da Archiviazione BLOB
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Panoramica
Questa esercitazione usa Azure.Search.Documents per creare ed eseguire più indicizzatori. In questa esercitazione si configureranno due origini dati di Azure in modo da configurare un indicizzatore che esegue il pull da entrambe per popolare un singolo indice di ricerca. I due set di dati devono avere un valore in comune per supportare l'unione. In questo esempio tale campo è un ID. Purché sia presente un campo in comune per supportare il mapping, un indicizzatore può unire i dati provenienti da più origini: dati strutturati di Azure SQL, dati non strutturati dell’archiviazione BLOB o qualsiasi combinazione di origini dati supportate in Azure.
Una versione completa del codice di questa esercitazione si trova nel progetto seguente:
Prerequisiti
- Azure Cosmos DB for NoSQL
- Archiviazione di Azure
- Visual Studio
- Pacchetto NuGet di Azure AI Search (versione 11.x)
- Azure AI Search
Nota
Per questa esercitazione è possibile usare un servizio di ricerca gratuito. Il livello gratuito consente di usare solo tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
1 - Creare i servizi
Questa esercitazione usa Azure AI Search per l'indicizzazione e le query, Azure Cosmos DB per un set di dati e Archiviazione BLOB di Azure per il secondo set di dati.
Se possibile, creare tutti i servizi nella stessa area e nello stesso gruppo di risorse per motivi di prossimità e gestibilità. In pratica, i servizi possono risiedere in qualsiasi area.
Questo esempio usa due piccoli set di dati che descrivono sette hotel fittizi. Un set descrive gli hotel stessi e verrà caricato in un database Azure Cosmos DB. L'altro set contiene i dettagli delle camere di hotel ed è suddiviso in sette file JSON separati da caricare in Archiviazione BLOB di Azure.
Iniziare con Azure Cosmos DB
Accedere al portale di Azure e passare alla pagina Panoramica dell'account Azure Cosmos DB.
Selezionare Esplora dati, quindi selezionare Nuovo database.
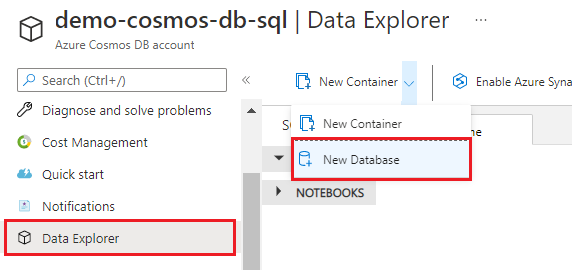
Immettere il nome hotel-rooms-db. Accettare i valori predefiniti per le impostazioni rimanenti.
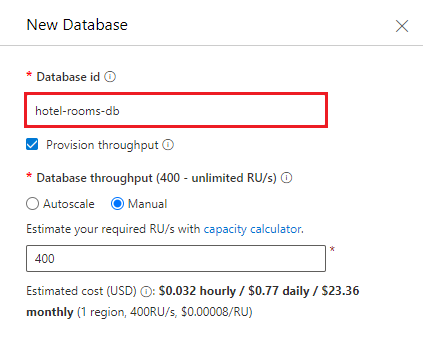
Crea un nuovo contenitore. Usare il database esistente appena creato. Immettere hotels come nome del contenitore e usare /HotelId come chiave di partizione.
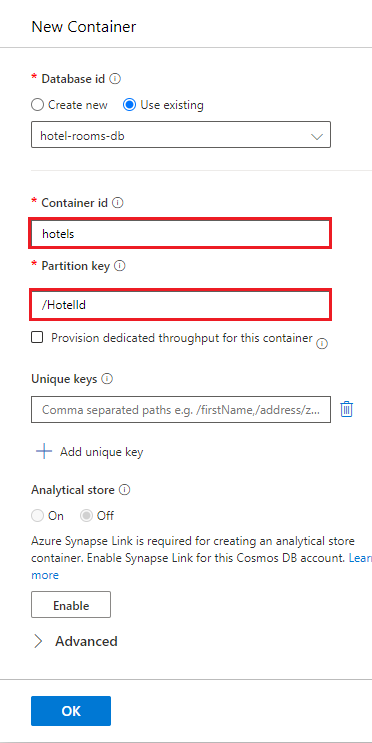
In hotels selezionare Elementi e quindi selezionare Carica elemento sulla barra dei comandi. Passare alla cartella di progetto e selezionare il file cosmosdb/HotelsDataSubset_CosmosDb.json.
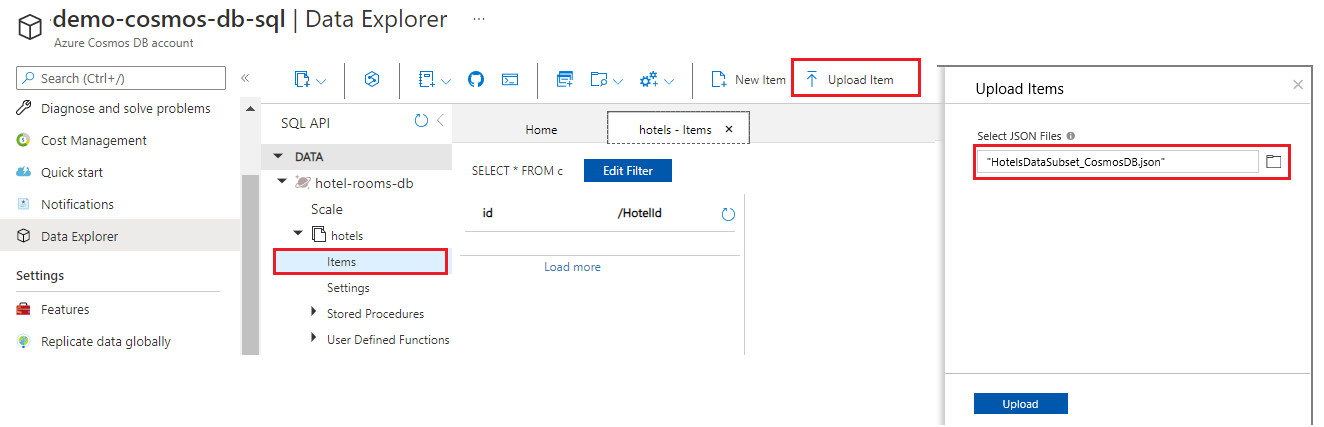
Premere Aggiorna per aggiornare la visualizzazione degli elementi nella raccolta di hotel. Dovrebbero essere visualizzati sette nuovi documenti di database.
Copiare nel Blocco note una stringa di connessione dalla pagina Chiavi. Questo valore sarà necessario per appsettings.json in un passaggio successivo. Se non è stato usato il nome di database suggerito "hotel-rooms-db", copiare anche il nome del database.
Archiviazione BLOB di Azure
Accedere al portale di Azure, passare all'account di archiviazione di Azure, selezionare BLOB e quindi selezionare + Contenitore.
Creare un contenitore BLOB denominato hotel-rooms in cui archiviare i file JSON delle camere di hotel di esempio. È possibile impostare il livello di accesso pubblico su uno qualsiasi dei relativi valori validi.
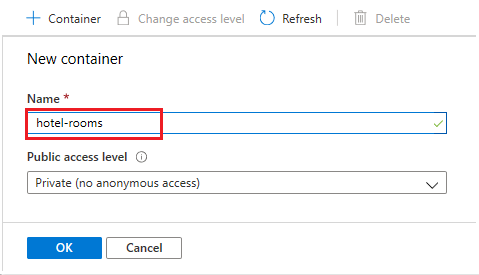
Dopo aver creato il contenitore, aprirlo e selezionare Carica nella barra dei comandi. Passare alla cartella contenente i file di esempio. Selezionarli tutti e quindi selezionare Carica.
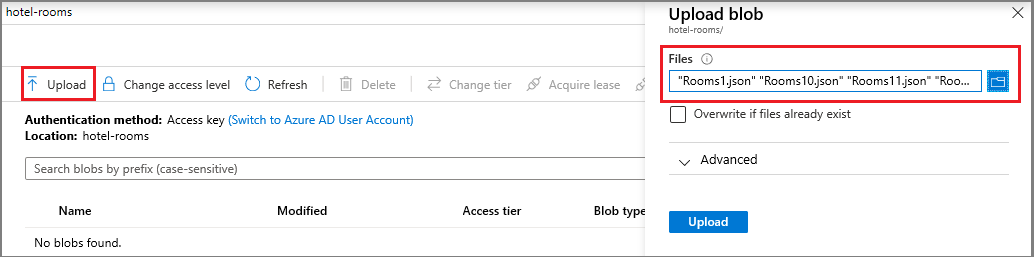
Copiare nel Blocco note il nome dell'account di archiviazione e una stringa di connessione dalla pagina Chiavi di accesso. Questi valori saranno necessari per appsettings.json in un passaggio successivo.
Azure AI Search
Il terzo componente è Ricerca di intelligenza artificiale di Azure, che è possibile creare nella portale di Azure o trovare un servizio di ricerca esistente nelle risorse di Azure.
Copiare un URL e una chiave API di amministrazione per Azure AI Search
Per autenticare il servizio di ricerca, è necessario avere l'URL del servizio e una chiave di accesso.
Accedere al portale di Azure e ottenere l'URL nella pagina Panoramica del servizio di ricerca. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi ottenere una chiave amministratore per diritti completi sul servizio. Sono disponibili due chiavi amministratore interscambiabili, fornite per continuità aziendale nel caso in cui sia necessario eseguire il rollover di una di esse. È possibile usare la chiave primaria o secondaria nelle richieste per l'aggiunta, la modifica e l'eliminazione di oggetti.
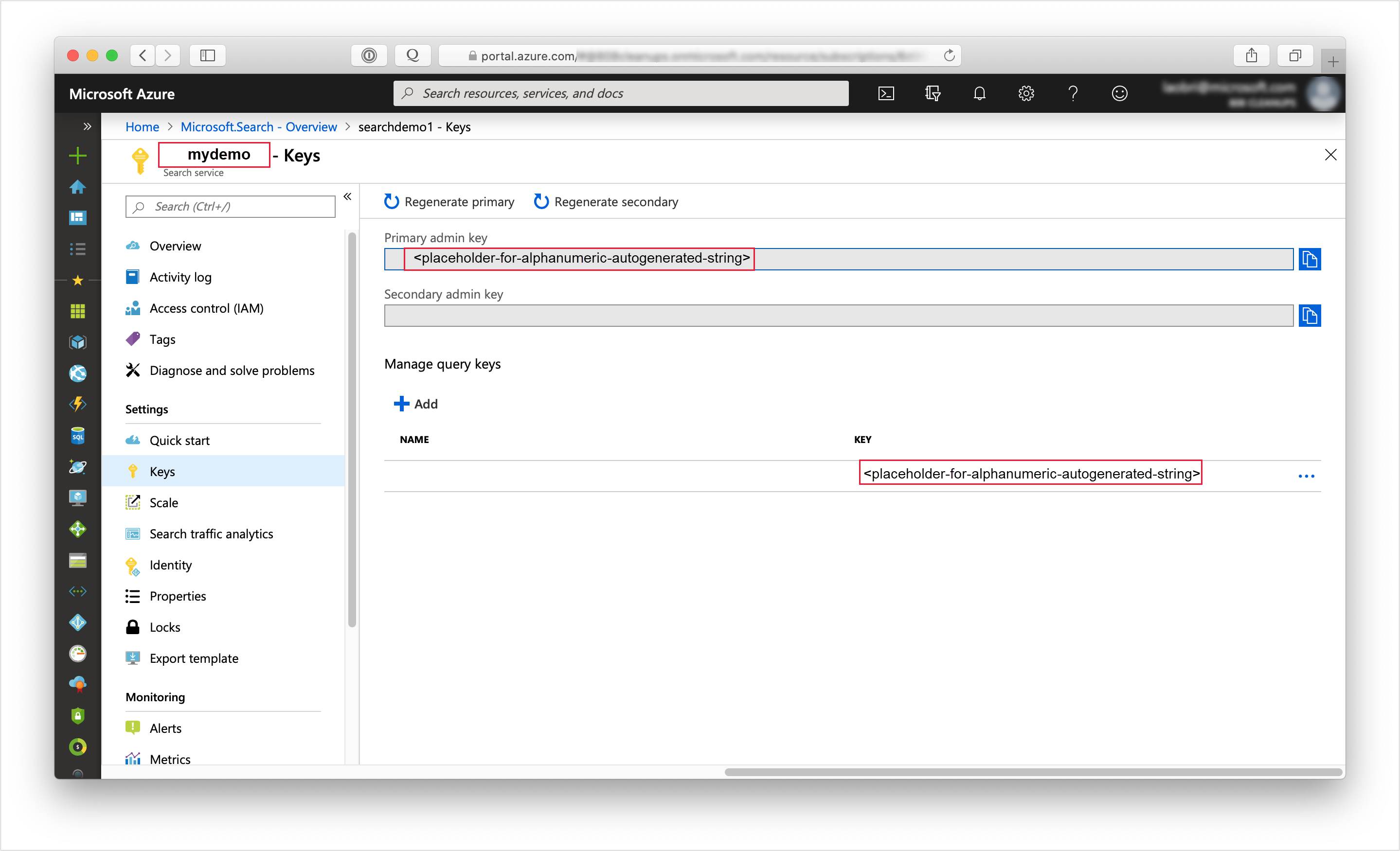
La presenza di una chiave valida stabilisce una relazione di trust, in base alle singole richieste, tra l'applicazione che invia la richiesta e il servizio che la gestisce.
2 - Configurare l'ambiente
Avviare Visual Studio, quindi scegliere Gestione pacchetti NuGet dal menu Strumenti e poi selezionare Gestisci pacchetti NuGet per la soluzione.
Nella scheda Sfoglia trovare e quindi installare Azure.Search.Documents (versione 11.0 o successiva).
Cercare i pacchetti NuGet Microsoft.Extensions.Configuration e Microsoft.Extensions.Configuration.Json e installare anche questi.
Aprire il file di soluzione /v11/AzureSearchMultipleDataSources.sln.
In Esplora soluzioni modificare il file appsettings.json per aggiungervi le informazioni sulla connessione.
{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Le prime due voci sono l'URL e le chiavi di amministratore per un servizio di ricerca. Usare l'endpoint completo, ad esempio https://mydemo.search.windows.net.
Per le voci successive specificare i nomi di account e le informazioni sulla stringa di connessione per le origini dati di Archiviazione BLOB di Azure e Azure Cosmos DB.
3 - Eseguire il mapping dei campi delle chiavi
Per unire il contenuto è necessario che entrambi i flussi di dati siano destinati agli stessi documenti nell'indice di ricerca.
In Azure AI Search il campo della chiave identifica in modo univoco ogni documento. Ogni indice di ricerca deve avere esclusivamente un campo chiave di tipo Edm.String. Questo campo deve essere presente per ogni documento di un'origine dati aggiunto all'indice. È l'unico campo obbligatorio.
Durante l'indicizzazione dei dati da più origini dati, assicurarsi che ogni riga o documento in ingresso contenga una chiave del documento comune per unire i dati da due documenti di origine fisicamente distinti in un nuovo documento di ricerca nell'indice combinato.
È spesso necessaria una pianificazione anticipata per identificare una chiave del documento significativa per l'indice e assicurarsi che sia presente in entrambe le origini dati. In questa demo la chiave HotelId per ogni hotel in Azure Cosmos DB è presente anche nei BLOB JSON delle camere in archiviazione BLOB.
Gli indicizzatori di Azure AI Search possono usare i mapping dei campi per rinominare e perfino riformattare i campi dati durante il processo di indicizzazione, così che l'origine dati possa essere indirizzata al campo indice corretto. Ad esempio, in Azure Cosmos DB, l'identificatore dell'hotel viene chiamato HotelId. Nei file BLOB JSON relativi alle camere di hotel, l'identificatore di hotel è denominato Id. Il programma gestisce questa discrepanza eseguendo il mapping del campo Id dei BLOB al campo della chiave HotelId nell'indicizzatore.
Nota
Nella maggior parte dei casi, le chiavi dei documenti generate automaticamente, come quelle create per impostazione predefinita da alcuni indicizzatori, non costituiscono la scelta ottimale per gli indici combinati. In generale, è consigliabile usare un valore di chiave univoco e significativo che esiste già nelle origini dati o può essere aggiunto facilmente.
4 - Esplorare il codice
Dopo aver definito dati e impostazioni di configurazione, dovrebbe essere possibile compilare ed eseguire il programma di esempio in /v11/AzureSearchMultipleDataSources.sln.
Questa semplice app console in C#/.NET esegue le attività seguenti:
- Crea un nuovo indice basato sulla struttura dei dati della classe Hotel in C# (che fa anche riferimento alle classi Address e Room).
- Crea una nuova origine dati e un indicizzatore che esegue il mapping dei dati di Azure Cosmos DB ai campi dell'indice. Si tratta di entrambi gli oggetti in Azure AI Search.
- Esegue l'indicizzatore per caricare i dati degli hotel da Azure Cosmos DB.
- Crea una seconda origine e un indicizzatore per il mapping dei dati BLOB JSON ai campi dell'indice.
- Esegue il secondo indicizzatore per caricare i dati delle camere dall'archivio BLOB.
Prima di eseguire il programma, esaminare il codice e le definizioni di indice e indicizzatore per questo esempio. Il codice rilevante è disponibile in due file:
- Hotel.cs contiene lo schema che definisce l'indice
- Program.cs contiene le funzioni che creano l'indice di Azure AI Search, le origini dati e gli indicizzatori; quindi carica i risultati combinati nell'indice.
Creare un indice
Questo programma di esempio usa CreateIndexAsync per definire e creare un indice di Azure AI Search. Sfrutta la classe FieldBuilder per generare una struttura di indice da una classe di modello di dati C#.
Il modello di dati è definito dalla classe Hotel, che contiene anche i riferimenti alle classi Address e Rooms. FieldBuilder esegue il drill-down attraverso più definizioni di classi per generare una struttura dei dati complessa per l'indice. I tag di metadati vengono usati per definire gli attributi di ogni campo, ad esempio se è ordinabile o ricercabile.
Il programma eliminerà eventuali indici esistenti con lo stesso nome prima di creare quello nuovo, nel caso si voglia eseguire questo esempio più volte.
I frammenti di codice seguenti del file Hotel.cs mostrano campi singoli, seguiti da un riferimento a un'altra classe del modello di dati, Room[], che a sua volta è definita nel file Room.cs (non mostrato).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
Nel file Program.cs un oggetto SearchIndex è definito con un nome e una raccolta di campi generati dal metodo FieldBuilder.Build e viene quindi creato come segue:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Creare un'origine dati e un indicizzatore di Azure Cosmos DB
Il programma principale include la logica per creare l'origine dati di Azure Cosmos DB per i dati degli hotel.
Concatena prima di tutto il nome del database Azure Cosmos DB alla stringa di connessione. Definisce quindi un oggetto SearchIndexerDataSourceConnection.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Dopo aver creato l'origine dati, il programma configura un indicizzatore di Azure Cosmos DB denominato hotel-rooms-cosmos-indexer.
Il programma aggiornerà gli indicizzatori esistenti con lo stesso nome, sovrascrivendoli con il contenuto del codice precedente. Include inoltre azioni di reimpostazione ed esecuzione, nel caso si voglia eseguire questo esempio più volte.
L'esempio seguente definisce una pianificazione per l'indicizzatore, in modo che venga eseguito una volta al giorno. È possibile rimuovere la proprietà relativa alla pianificazione da questa chiamata se non si vuole che l'indicizzatore venga eseguito di nuovo automaticamente in futuro.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Questo esempio include un semplice blocco try-catch per segnalare gli eventuali errori che potrebbero verificarsi durante l'esecuzione.
Dopo l'esecuzione dell'indicizzatore di Azure Cosmos DB, l'indice di ricerca conterrà un set completo di documenti di hotel di esempio. Tuttavia, il campo delle camere per ogni hotel sarà una matrice vuota, perché l'origine dati di Azure Cosmos DB omette i relativi dettagli. Quindi, il programma esegue il pull da Archiviazione BLOB per caricare e unire i dati delle camere.
Creare l'origine dati e l'indicizzatore di Archiviazione BLOB
Per ottenere i dettagli delle camere, il programma configura prima di tutto un'origine dati di Archiviazione BLOB per fare riferimento a un set di singoli file BLOB JSON.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Dopo aver creato l'origine dati, il programma configura un indicizzatore BLOB denominato hotel-rooms-blob-indexer, illustrato di seguito.
I BLOB JSON contengono un campo della chiave denominato Id anziché HotelId. Il codice usa la classe FieldMapping per indicare all'indicizzatore di indirizzare il valore del campo Id alla chiave del documento HotelId nell'indice.
Gli indicizzatori di Archiviazione BLOB possono usare IndexingParameters per specificare una modalità di analisi. È consigliabile impostare modalità di analisi diverse a seconda che il BLOB rappresenti un singolo documento oppure più documenti all'interno dello stesso BLOB. In questo esempio ogni BLOB rappresenta un singolo documento JSON, quindi il codice usa la modalità di analisi json. Per altre informazioni sui parametri di analisi dell'indicizzatore per i BLOB JSON, vedere Indicizzare i BLOB JSON.
Questo esempio definisce una pianificazione per l'indicizzatore, in modo che venga eseguito una volta al giorno. È possibile rimuovere la proprietà relativa alla pianificazione da questa chiamata se non si vuole che l'indicizzatore venga eseguito di nuovo automaticamente in futuro.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Poiché l'indice è già stato popolato con i dati degli hotel del database Azure Cosmos DB, l'indicizzatore BLOB aggiorna i documenti esistenti nell'indice e aggiunge i dettagli delle camere.
Nota
Se entrambe le origini dati contengono gli stessi campi non di chiave e i dati all'interno di tali campi non corrispondono, l'indice conterrà i valori di qualsiasi indicizzatore eseguito più di recente. In questo esempio entrambe le origini dati contengono un campo HotelName. Se per qualche motivo i dati di questo campo sono diversi per i documenti con lo stesso valore di chiave, il valore archiviato nell'indice corrisponderà ai dati HotelName dell'origine dati data indicizzata più di recente.
5 - Eseguire ricerche
È possibile esplorare l'indice di ricerca popolato dopo l'esecuzione del programma, usando Esplora ricerche nella portale di Azure.
Nel portale di Azure aprire la pagina Panoramica del servizio di ricerca e individuare l'indice hotel-rooms-sample nell'elenco Indici.

Fare clic sull’indice hotel-rooms-sample nell'elenco. Verrà visualizzata l'interfaccia di Esplora ricerche per l'indice. Immettere una query per un termine tipo "Luxury". I risultati dovrebbero contenere almeno un documento, che dovrebbe mostrare un elenco di oggetti camera nella matrice di camere.
Reimpostare ed eseguire di nuovo
Nelle prime fasi di sviluppo sperimentali, l'approccio più pratico per l'iterazione di progetto consiste nell'eliminare gli oggetti da Azure AI Search e consentire al codice di ricompilarli. I nomi di risorsa sono univoci. L'eliminazione di un oggetto consente di ricrearlo usando lo stesso nome.
Il codice di esempio verifica la presenza di oggetti esistenti e li elimina o li aggiorna in modo da poter eseguire nuovamente il programma.
È anche possibile usare il portale di Azure per eliminare indici, indicizzatori e origini dati.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
Dopo aver acquisito familiarità con il concetto di inserimento di dati da più origini, si esaminerà più in dettaglio la configurazione dell'indicizzatore, a partire da Azure Cosmos DB.