Esercitazione: Indicizzare i dati di Azure SQL con .NET SDK
Configurare un indicizzatore per estrarre i dati ricercabili da Database SQL di Azure e inviarli a un indice di ricerca in Azure AI Search.
Questa esercitazione usa C# e Azure SDK per .NET per eseguire le attività seguenti:
- Creare un'origine dati che si connette al database SQL di Azure
- Creare un indicizzatore
- Eseguire un indicizzatore per caricare i dati in un indice
- Eseguire query su un indice come passaggio di verifica
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Database SQL di Azure con l'autenticazione di SQL Server
- Visual Studio
- Azure AI Search. Creare o trovare un servizio di ricerca esistente
Nota
Per questa esercitazione è possibile usare un servizio di ricerca gratuito. Il livello gratuito consente di usare solo tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
Scaricare i file
Il codice sorgente per questa esercitazione si trova nella cartella DotNetHowToIndexer nel repository Azure-Samples/search-dotnet-getting-started GitHub.
1 - Creare i servizi
Questa esercitazione usa Azure AI Search per l'indicizzazione e le query e un database SQL di Azure come origine dati esterna. Se possibile, creare entrambi i servizi nella stessa area e nello stesso gruppo di risorse per motivi di prossimità e gestibilità. In pratica, il database SQL di Azure può trovarsi in qualsiasi area.
Iniziare con il database SQL di Azure
Questa esercitazione fornisce il file hotels.sql nel download di esempi per popolare il database. Azure AI Search utilizza set di righe bidimensionali, come quello generato da una visualizzazione o una query. Il file SQL nella soluzione di esempio crea e popola una singola tabella.
Se è presente una risorsa di database SQL di Azure esistente, è possibile aggiungere a tale risorsa la tabella relativa agli hotel, a partire dal passaggio Apri query.
Creare un database SQL di Azure usando le istruzioni riportate in Guida introduttiva: Creare un database singolo.
La configurazione del server per il database è importante.
Scegliere l'opzione di autenticazione di SQL Server che richiede di specificare un nome utente e una password. Questa operazione è necessaria per la stringa di connessione ADO.NET usata dall'indicizzatore.
Scegliere una connessione pubblica. Questo approccio semplifica il completamento dell'esercitazione. L'opzione pubblica non è consigliata per la produzione ed è consigliabile eliminare questa risorsa alla fine dell'esercitazione.
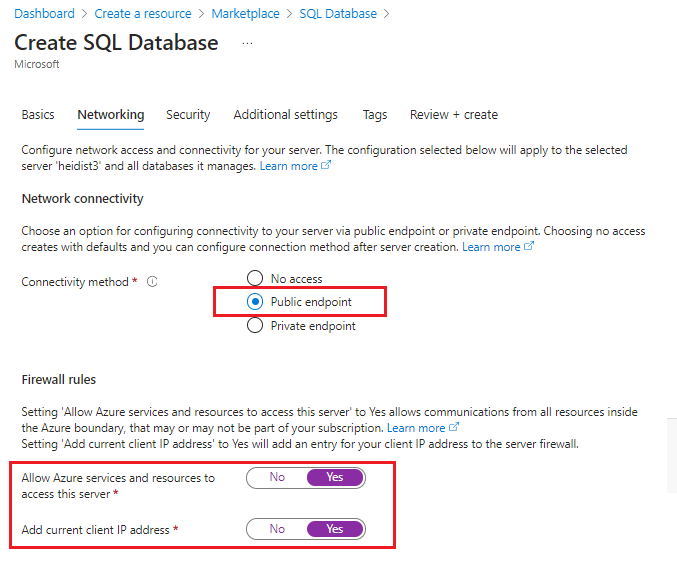
Nel portale di Azure passare alla nuova risorsa.
Aggiungere una regola del firewall per consentire l'accesso dal client usando le istruzioni riportate in Guida introduttiva: Creare una regola del firewall a livello di server nel portale di Azure. È possibile eseguire
ipconfigda un prompt dei comandi per ottenere l'indirizzo IP.Usare l'editor di query per caricare i dati di esempio. Nel riquadro di spostamento selezionare Editor di query (anteprima) e immettere il nome utente e la password dell'amministratore del server.
Se viene visualizzato un errore di accesso negato, copiare l'indirizzo IP del client dal messaggio di errore, aprire la pagina di sicurezza di rete per il server e aggiungere una regola in ingresso che consenta l'accesso dal client.
Nell'Editor di query selezionare Apri query e passare al percorso del file hotels.sql nel computer locale.
Selezionare il file e selezionare Apri. Lo script dovrebbe essere simile allo screenshot seguente:
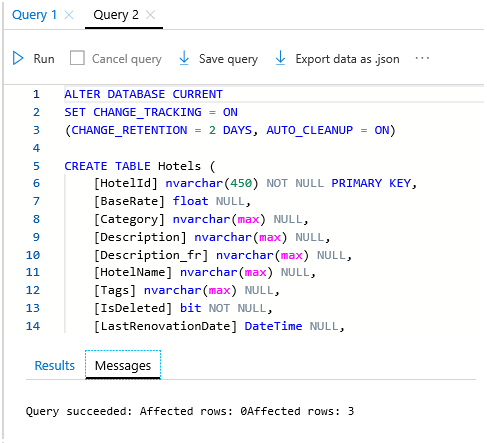
Selezionare Esegui per eseguire la query. Nel riquadro Risultati dovrebbe essere visualizzato un messaggio di esito positivo della query, per tre righe.
Per restituire un set di righe da questa tabella, è possibile eseguire la query seguente come passaggio di verifica:
SELECT * FROM HotelsCopiare la stringa di connessione ADO.NET per il database. In Impostazioni>Stringhe di connessione copiare la stringa di connessione ADO.NET simile all'esempio seguente.
Server=tcp:<YOUR-DATABASE-NAME>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<YOUR-USER-NAME>;Password=<YOUR-PASSWORD>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
Questa stringa di connessione sarà necessaria nell'esercizio successivo per la configurazione dell'ambiente.
Azure AI Search
Il componente successivo è Ricerca di intelligenza artificiale di Azure, che è possibile creare nel portale di Azure. Per completare questa procedura dettagliata, è possibile usare il livello gratuito.
Ottenere un URL e una chiave API di amministrazione per Azure AI Search
Le chiamate API richiedono l'URL del servizio e una chiave di accesso. Con entrambi gli elementi viene creato un servizio di ricerca, quindi se si è aggiunto Azure AI Search alla sottoscrizione, seguire questi passaggi per ottenere le informazioni necessarie:
Accedere al portale di Azure e ottenere l'URL nella pagina Panoramica del servizio di ricerca. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi ottenere una chiave amministratore per diritti completi sul servizio. Sono disponibili due chiavi amministratore interscambiabili, fornite per continuità aziendale nel caso in cui sia necessario eseguire il rollover di una di esse. È possibile usare la chiave primaria o secondaria nelle richieste per l'aggiunta, la modifica e l'eliminazione di oggetti.
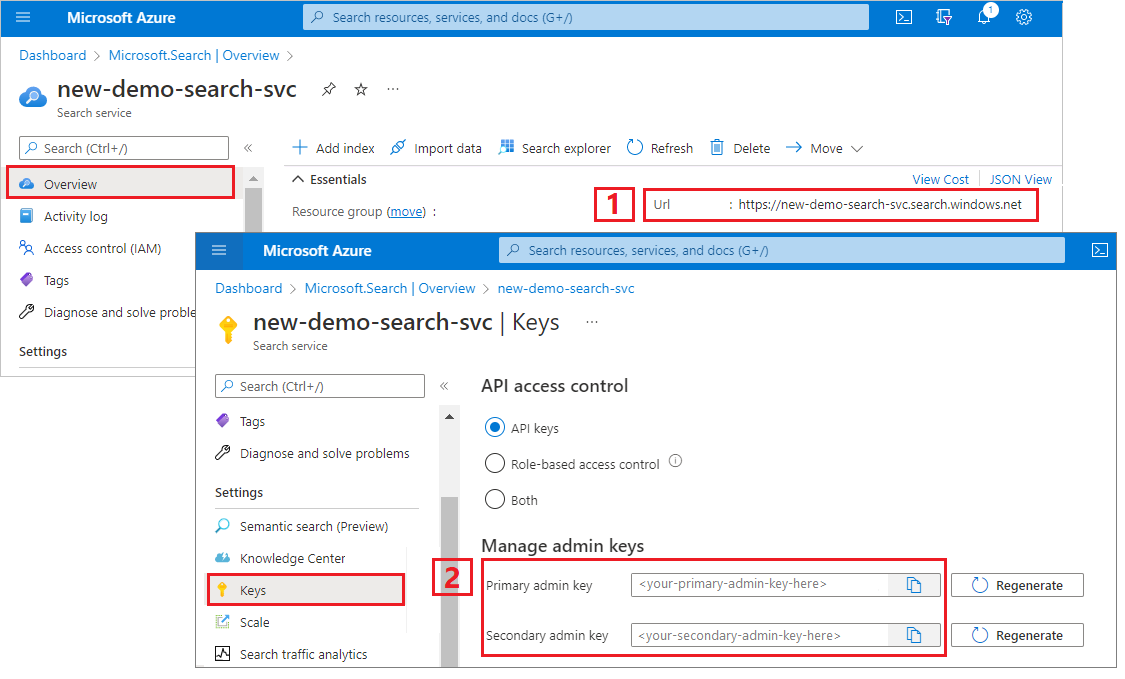
2 - Configurare l'ambiente
Avviare Visual Studio e aprire il file DotNetHowToIndexers.sln.
In Esplora soluzioni aprire il file appsettings.json per aggiungervi le informazioni sulla connessione.
Per
SearchServiceEndPoint, se l'URL completo nella pagina di panoramica del servizio è "https://my-demo-service.search.windows.net"", il valore da fornire è l'intero URL.Per
AzureSqlConnectionString, il formato della stringa è simile al seguente:"Server=tcp:<your-database-name>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<your-user-name>;Password=<your-password>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"{ "SearchServiceEndPoint": "<placeholder-search-full-url>", "SearchServiceAdminApiKey": "<placeholder-admin-key-for-search-service>", "AzureSqlConnectionString": "<placeholder-ADO.NET-connection-string", }Sostituire la password utente nella stringa di connessione SQL con una password valida. Il nome del database e il nome utente verranno copiati automaticamente, ma la password deve essere immessa manualmente.
3 - Creare la pipeline
Gli indicizzatori richiedono un oggetto origine dati e un indice. Il codice rilevante è disponibile in due file:
hotel.cs, contenente uno schema che definisce l'indice
Program.cs, contenente le funzioni per la creazione e la gestione delle strutture nel servizio
In hotel.cs
Lo schema dell'indice definisce la raccolta di campi, inclusi gli attributi che specificano le operazioni consentite, ad esempio se un campo è compatibile con la ricerca full-text, filtrabile oppure ordinabile, come mostrato nella definizione di campo seguente per HotelName. Un SearchableField è ricercabile full-text per definizione. Gli altri attributi vengono assegnati in modo esplicito.
. . .
[SearchableField(IsFilterable = true, IsSortable = true)]
[JsonPropertyName("hotelName")]
public string HotelName { get; set; }
. . .
Uno schema può includere anche altri elementi, tra cui l'assegnazione di punteggi ai profili per il boosting del punteggio di una ricerca, analizzatori personalizzati e altri costrutti. Per le finalità specifiche di questa esercitazione, tuttavia, lo schema è scarsamente definito ed è costituito solo dai campi disponibili nel set di dati di esempio.
In Program.cs
Il programma principale include la logica per la creazione di un client indicizzatore, un indice, un'origine dati e un indicizzatore. Il codice cerca ed elimina le risorse esistenti con lo stesso nome, presupponendo che sia possibile che il programma venga eseguito più volte.
L'oggetto origine dati è configurato con le impostazioni specifiche per le risorse di Database SQL di Azure, tra cui l'indicizzazione parziale o incrementale per usare le funzionalità di rilevamento delle modifiche predefinite di Azure SQL. Il database degli hotel demo in Azure SQL include una colonna di "eliminazione temporanea" denominata IsDeleted. Quando questa colonna è impostata su true nel database, l'indicizzatore rimuove il documento corrispondente dall'indice di Azure AI Search.
Console.WriteLine("Creating data source...");
var dataSource =
new SearchIndexerDataSourceConnection(
"hotels-sql-ds",
SearchIndexerDataSourceType.AzureSql,
configuration["AzureSQLConnectionString"],
new SearchIndexerDataContainer("hotels"));
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
Un oggetto indicizzatore non dipende dalla piattaforma, ovvero la configurazione, la pianificazione e la chiamata sono uguali, indipendentemente dall'origine. Questo esempio di indicizzatore include una pianificazione, un'opzione di ripristino che cancella la cronologia dell'indicizzatore e chiama un metodo per creare ed eseguire immediatamente l'indicizzatore. Per creare o aggiornare un indicizzatore, usare CreateOrUpdateIndexerAsync.
Console.WriteLine("Creating Azure SQL indexer...");
var schedule = new IndexingSchedule(TimeSpan.FromDays(1))
{
StartTime = DateTimeOffset.Now
};
var parameters = new IndexingParameters()
{
BatchSize = 100,
MaxFailedItems = 0,
MaxFailedItemsPerBatch = 0
};
// Indexer declarations require a data source and search index.
// Common optional properties include a schedule, parameters, and field mappings
// The field mappings below are redundant due to how the Hotel class is defined, but
// we included them anyway to show the syntax
var indexer = new SearchIndexer("hotels-sql-idxr", dataSource.Name, searchIndex.Name)
{
Description = "Data indexer",
Schedule = schedule,
Parameters = parameters,
FieldMappings =
{
new FieldMapping("_id") {TargetFieldName = "HotelId"},
new FieldMapping("Amenities") {TargetFieldName = "Tags"}
}
};
await indexerClient.CreateOrUpdateIndexerAsync(indexer);
Le esecuzioni dell'indicizzatore sono in genere pianificate, ma durante lo sviluppo potrebbe essere necessario eseguire immediatamente l'indicizzatore usando RunIndexerAsync.
Console.WriteLine("Running Azure SQL indexer...");
try
{
await indexerClient.RunIndexerAsync(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
4 - Compilare la soluzione
Premere F5 per compilare ed eseguire la soluzione. Il programma viene eseguito in modalità di debug. Una finestra della console indica lo stato di ogni operazione.
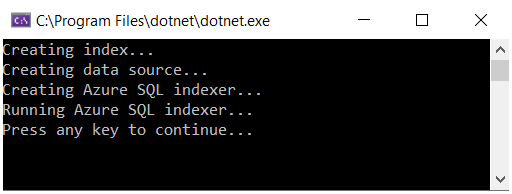
Il codice viene eseguito localmente in Visual Studio, connettendosi al servizio di ricerca in Azure, che a sua volta si connette al database SQL di Azure e recupera il set di dati. Un numero così elevato di operazione comporta molti punti di errore potenziali. Se si verifica un errore, verificare prima di tutto le condizioni seguenti:
Le informazioni di connessione al servizio di ricerca fornite sono l'URL completo. Se è stato immesso solo il nome del servizio, le operazioni si arrestano alla creazione dell'indice, con un errore relativo all'impossibilità di connettersi.
Informazioni sulla connessione al database in appsettings.json. Deve essere il ADO.NET stringa di connessione ottenuto dal portale di Azure, modificato per includere un nome utente e una password validi per il database. L'account utente deve avere l'autorizzazione necessaria per recuperare i dati. All'indirizzo IP del client locale deve essere consentito l'accesso in ingresso attraverso il firewall.
Limiti delle risorse. Tenere presente che il livello gratuito prevede limiti di tre indici, indicizzatori e origini dati. Un servizio che ha raggiunto il limite massimo non può creare nuovi oggetti.
5 - Eseguire ricerche
Usare il portale di Azure per verificare la creazione dell'oggetto e quindi usare Esplora ricerche per eseguire una query sull'indice.
Accedere al portale di Azure e nel riquadro di spostamento sinistro del servizio di ricerca aprire ogni pagina a turno per verificare che l'oggetto sia stato creato. I valori per Indici, Indicizzatori e Origini dati saranno rispettivamente "hotels-sql-idx", "hotels-sql-indexer" e "hotels-sql-ds".
Nella scheda Indici selezionare l'indice hotels-sql-idx. Nella pagina hotels Esplora ricerche è la prima scheda.
Selezionare Cerca per eseguire una query vuota.
Le tre voci nell'indice vengono restituite come documenti JSON. Esplora ricerche restituisce documenti in JSON, per consentire di visualizzare l'intera struttura.
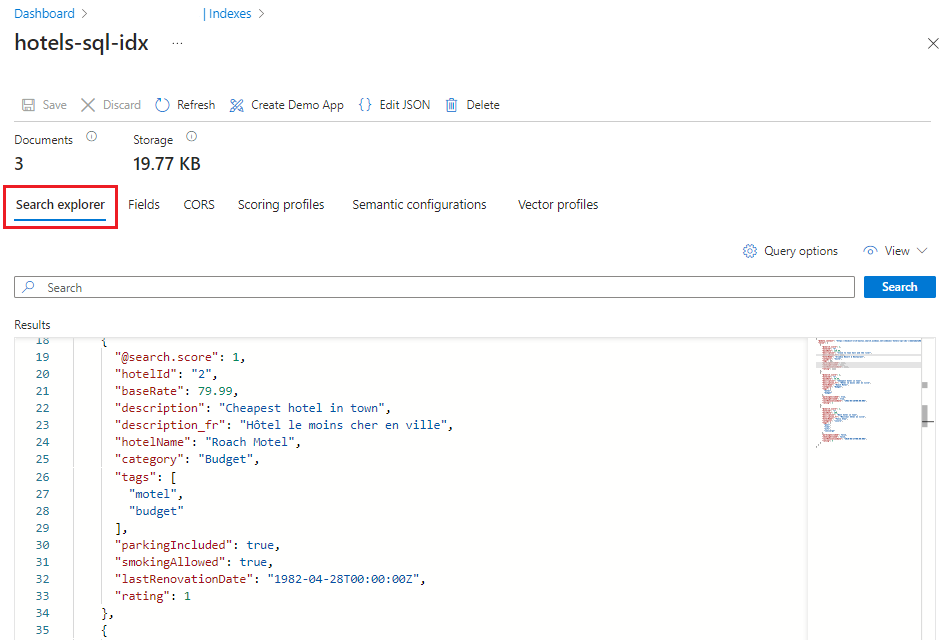
Successivamente, passare a Visualizzazione JSON in modo da poter immettere i parametri di query:
{ "search": "river", "count": true }Questa query richiama una ricerca full-text sul termine
rivere il risultato include un conteggio dei documenti corrispondenti. La restituzione del numero di documenti corrispondenti risulta utile negli scenari di test quando è presente un indice di grandi dimensioni con migliaia o milioni di documenti. In questo caso, solo un documento corrisponde alla query.Immettere infine i parametri che limitano i risultati della ricerca ai campi di interesse:
{ "search": "river", "select": "hotelId, hotelName, baseRate, description", "count": true }La risposta della query viene ridotta ai campi selezionati e si otterrà quindi un output più conciso.
Reimpostare ed eseguire di nuovo
Nelle prime fasi di sviluppo sperimentali, l'approccio più pratico per l'iterazione di progetto consiste nell'eliminare gli oggetti da Azure AI Search e consentire al codice di ricompilarli. I nomi di risorsa sono univoci. L'eliminazione di un oggetto consente di ricrearlo usando lo stesso nome.
Il codice di esempio per questa esercitazione verifica la presenza di oggetti esistenti e li elimina in modo da poter eseguire nuovamente il codice.
È anche possibile usare il portale di Azure per eliminare indici, indicizzatori e origini dati.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
Dopo aver acquisito familiarità con i concetti di base dell'indicizzazione del database SQL, si esaminerà in dettaglio la configurazione dell'indicizzatore.