Disponibilità di SAP HANA in un'area di Azure
Questo articolo descrive diversi scenari di disponibilità per SAP HANA in un'area di Azure. Azure ha molte aree, distribuite in tutto il mondo. Per l'elenco delle aree di Azure, vedere Aree di Azure. Per la distribuzione di SAP HANA in macchine virtuali in un'area di Azure, Microsoft offre la possibilità di distribuire una singola macchina virtuale con un'istanza di HANA. Per una maggiore disponibilità, è possibile distribuire due macchine virtuali con due istanze HANA usando un set di scalabilità flessibile con FD=1, zone di disponibilità o un set di disponibilità che usa la replica di sistema HANA per la disponibilità.
Le aree di Azure che forniscono zone di disponibilità sono costituite da più data center, ognuno con una propria fonte di alimentazione, raffreddamento e infrastruttura di rete. Lo scopo dell'offerta di zone differenti all'interno di una singola area di Azure consiste nell'abilitare la distribuzione delle applicazioni in due o tre zone di disponibilità disponibili. Distribuendo l’implementazione dell'applicazione tra zone, eventuali problemi di alimentazione o di rete che interessano un'infrastruttura specifica della zona di disponibilità di Azure non interromperebbero completamente le funzionalità dell'applicazione all'interno dell'area di Azure. Anche se una determinata capacità potrebbe rivelarsi ridotta, come ad esempio la potenziale perdita di macchine virtuali in un'unica zona, le macchine virtuali nelle zone rimanenti continueranno a funzionare senza interruzioni. Per configurare due istanze di HANA in macchine virtuali separate che si estendono tra zone differenti, è possibile distribuire le macchine virtuali usando il set di scalabilità flessibile con FD=1 o l'opzione di distribuzione zone di disponibilità.
Per una maggiore disponibilità all'interno di un'area, è consigliabile distribuire due macchine virtuali con due istanze HANA usando un set di disponibilità. Un set di disponibilità di Azure è una funzionalità di raggruppamento logico che garantisce che le risorse delle macchine virtuali configurate nel set di disponibilità siano isolate tra loro in caso di errore quando vengono distribuite all'interno di un data center di Azure. Azure garantisce che le macchine virtuali inserite all'interno di un set di disponibilità vengano eseguite tra più server fisici, rack di calcolo, unità di archiviazione e commutatori di rete. In alcuni esempi di documentazione su Azure, queste configurazioni vengono definite come inserimenti in diversi domini di aggiornamento e di errore. Questi inserimenti avvengono in genere all'interno di un data center di Azure. Supponendo che i problemi relativi alle fonti di alimentazione e alla rete interessino il data center in cui ha luogo la distribuzione, risulterebbe interessata l'intera capacità in un'area di Azure.
L'inserimento di data center che rappresentano zone di disponibilità di Azure è un compromesso tra una latenza di rete accettabile tra i servizi distribuiti in zone diverse e una distanza tra i data center. Eventuali catastrofi naturali non avrebbero ripercussioni su alimentazione, fornitura di rete e infrastruttura per tutte le zone di disponibilità in quest'area. Tuttavia, come hanno dimostrato catastrofi naturali di grave entità, non sempre le zone di disponibilità potrebbero fornire la disponibilità desiderata in un'area. Basti pensare all'uragano Maria che ha colpito l'isola di Porto Rico il 20 settembre 2017. L'uragano ha causato un black out quasi totale per tutti i 140 chilometri dell'isola.
Scenario basato su una singola macchina virtuale
In uno scenario basato su una singola macchina virtuale si crea una VM di Azure per l'istanza di SAP HANA. Si usa Archiviazione Premium di Azure per ospitare il disco del sistema operativo e tutti i dischi dati. Il contratto di servizio per il tempo di attività di Azure del 99,9% e i contratti di servizio degli altri componenti di Azure sono sufficienti per soddisfare i contratti di servizio relativi alla disponibilità per i clienti. In questo scenario non occorre fare ricorso a un set di disponibilità di Azure per le macchine virtuali che eseguono il livello DBMS. Questo scenario si basa su due diverse funzionalità:
- Riavvio automatico della macchina virtuale di Azure (noto anche come correzione del servizio di Azure)
- Riavvio automatico di SAP HANA
Il riavvio automatico della macchina virtuale di Azure o correzione del servizio è una caratteristica di Azure che funziona su due livelli:
- L'host del server di Azure verifica l'integrità di una macchina virtuale ospitata nell'host del server.
- Il controller di infrastruttura di Azure monitora l'integrità e la disponibilità dell'host del server.
Una funzionalità di controllo dell'integrità monitora l'integrità di ogni VM ospitata in un host del server di Azure. Se una macchina virtuale passa a uno stato non integro, il riavvio della macchina virtuale può essere attivato dall'agente host di Azure che controlla l'integrità della macchina virtuale. Il controller di infrastruttura verifica l'integrità dell'host controllando numerosi parametri diversi che potrebbero indicare problemi con l'hardware dell'host. Verifica anche l'accessibilità dell'host tramite la rete. Un'indicazione di problemi a livello di host può portare agli eventi seguenti:
- Se l'host segnala uno stato non integro, viene attivato il riavvio dell'host e delle macchine virtuali in esecuzione nell'host.
- Se l'host non è in uno stato integro dopo il riavvio, viene avviata una ridistribuzione delle macchine virtuali originariamente presenti nel nodo non integro in un server host integro. In questo caso, l'host originale viene contrassegnato come non integro. Non verrà usato per ulteriori distribuzioni, fino a quando non verrà pulito o sostituito.
- Se l'host non integro ha problemi durante il processo di riavvio, viene attivato un riavvio immediato delle macchine virtuali in un host integro.
Con il monitoraggio degli host e delle macchine virtuali offerto da Azure, le macchine virtuali di Azure in cui si verificano problemi a livello di host vengono riavviate automaticamente in un host di Azure integro.
Importante
La correzione del servizio di Azure non riavvia le macchine virtuali Linux in cui il sistema operativo guest si trova in uno stato di allarme del kernel. Le impostazioni predefinite delle versioni Linux usate comunemente non riavviano automaticamente le macchine virtuali o il server in cui il kernel Linux si trova in uno stato di allarme. Per impostazione predefinita, invece, il sistema operativo nel kernel viene mantenuto in stato di allarme per poter collegare un debugger del kernel per l'analisi. Azure rispetta questo comportamento evitando di riavviare automaticamente una macchina virtuale quando il sistema operativo guest si trova in tale stato. Il presupposto è che tali occorrenze siano estremamente rare. È possibile sovrascrivere il comportamento predefinito per consentire il riavvio della macchina virtuale. Per modificare il comportamento predefinito, abilitare il parametro "kernel.panic" in /etc/sysctl.conf. Il tempo impostato per questo parametro è espresso in secondi. In genere, è consigliata un'attesa di circa 20-30 secondi prima di attivare il riavvio tramite questo parametro. Per ulteriori informazioni, vedere sysctl.conf.
La seconda funzionalità su cui si può fare affidamento in questo scenario è l'avvio automatico del servizio HANA eseguito in una macchina virtuale riavviata dopo il reboot della macchina virtuale. È possibile configurare il riavvio automatico del servizio HANA tramite i servizi watchdog dei differenti servizi HANA.
È possibile ottimizzare questo scenario basato su una singola macchina virtuale con l'aggiunta di un nodo di failover a freddo a una configurazione di SAP HANA. Nella documentazione di SAP HANA, questa configurazione è chiamata failover automatico dell'host. Questa configurazione potrebbe risultare utile in una situazione di distribuzione locale in cui l'hardware del server è limitato e si designa un singolo nodo server come nodo di failover automatico dell'host per un set di host di produzione. Ma in Azure, la cui l'infrastruttura soggiacente fornisce un server di destinazione integro per il corretto riavvio di una macchina virtuale, non è utile distribuire il failover automatico dell'host di SAP HANA. A causa della correzione del servizio di Azure, non è disponibile un'architettura di riferimento che preveda un nodo di standby per il failover automatico dell'host HANA.
Caso speciale di configurazioni scale-out SAP HANA in Azure
Le architetture a disponibilità elevata basate sul nodo standby o sulla replica di sistema HANA sono disponibili nei documenti seguenti. Nei casi in cui i nodi di standby o la disponibilità elevata della replica di sistema HANA non vengono usati nelle configurazioni con scalabilità orizzontale di SAP HANA, è possibile dipendere dalle funzionalità di correzione del servizio delle macchine virtuali di Azure e dal riavvio automatico dell'istanza di SAP HANA quando la macchina virtuale è nuovamente operativa.
- RedHat Enterprise Linux
- SuSE Linux Enterprise Server
Scenari di disponibilità per due diverse macchine virtuali
Per garantire la disponibilità del sistema HANA all'interno di un'area specifica, è possibile configurare due macchine virtuali tra le zone di disponibilità dell'area o all'interno dell'area. Per raggiungere questo obiettivo, è possibile configurare le macchine virtuali usando un set di scalabilità flessibile, zone di disponibilità o un'opzione di distribuzione del set di disponibilità. La configurazione di base in Azure sarà simile alla seguente:
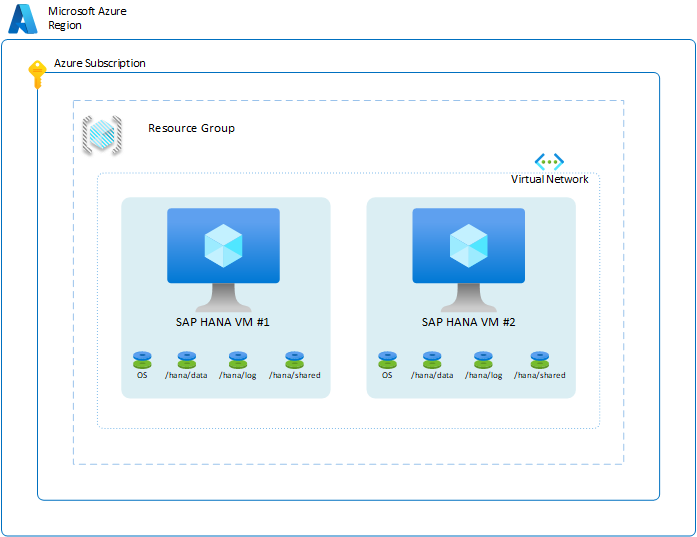
Per illustrare i diversi scenari di disponibilità di SAP HANA, alcuni dei livelli nel diagramma vengono omessi. Il diagramma mostra solo i livelli che rappresentano macchine virtuali, host, set di disponibilità e aree di Azure. Le istanze di Rete virtuale Azure, i gruppi di risorse e le sottoscrizioni non svolgono alcun ruolo negli scenari descritti in questa sezione.
Replicare i backup in una seconda macchina virtuale
Una delle configurazioni più elementari consiste nell'usare i backup. In particolare, i backup del log delle transazioni potrebbero essere forniti da una macchina virtuale a un'altra macchina virtuale di Azure. È possibile scegliere il tipo di archiviazione di Azure. In questa configurazione sarà necessario creare uno script della copia dei backup pianificati eseguiti nella prima macchina virtuale per la seconda macchina virtuale. Se è necessario usare le istanze della seconda macchina virtuale, è necessario ripristinare i backup completi, incrementali/differenziali e del log delle transazioni fino al punto necessario.
L'architettura è simile a quanto segue:
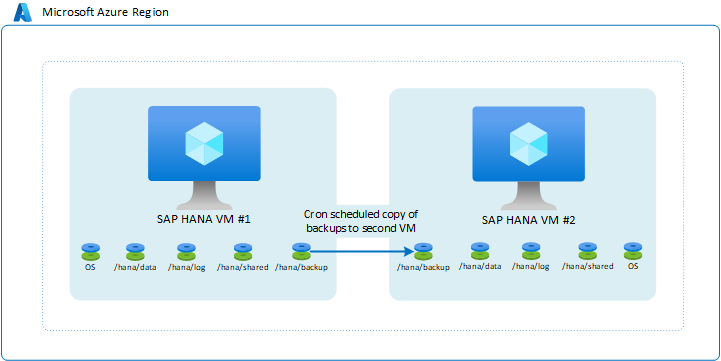
Questa configurazione non è adatta per ottenere tempi di obiettivo del punto di ripristino (RPO) e di obiettivo del tempo di ripristino (RTO) ottimali. In particolare i tempi di RTO ne risentirebbero a causa della necessità di ripristinare interamente il database completo usando i backup copiati. Tuttavia, questa configurazione è utile per il recupero in caso di eliminazione accidentale dei dati nelle istanze principali. Con questa configurazione, in qualsiasi momento, è possibile eseguire il ripristino fino a un determinato punto nel tempo, estrarre i dati e importare i dati eliminati nell'istanza principale. Di conseguenza, potrebbe risultare vantaggioso usare un metodo di copia di backup in combinazione con altre funzionalità per la disponibilità elevata.
Mentre vengono copiati i backup, è possibile usare una macchina virtuale più piccola della macchina virtuale principale in cui è in esecuzione l'istanza di SAP HANA. Tenere presente che è possibile collegare un numero inferiore di dischi rigidi virtuali a macchine virtuali più piccole. Per informazioni sui limiti dei singoli tipi di macchine virtuali, vedere Dimensioni delle macchine virtuali Linux in Azure.
Replica di sistema SAP HANA senza failover automatico
Gli scenari descritti in questa sezione usano la replica di sistema SAP HANA. Per la documentazione su SAP, vedere System replication (Replica di sistema). Gli scenari senza failover automatico non sono comuni per le configurazioni in un'area di Azure. Una configurazione senza failover automatico evita la configurazione di Pacemaker, ma obbliga a eseguire manualmente il monitoraggio e il failover. Poiché anche in questo caso è necessario del lavoro, la maggior parte dei clienti si affida alla correzione del servizio di Azure. Ci sono alcuni casi limite in cui questa configurazione potrebbe essere utile in termini di scenari di errore o, in alcuni casi, un cliente potrebbe voler raggiungere una maggiore efficienza.
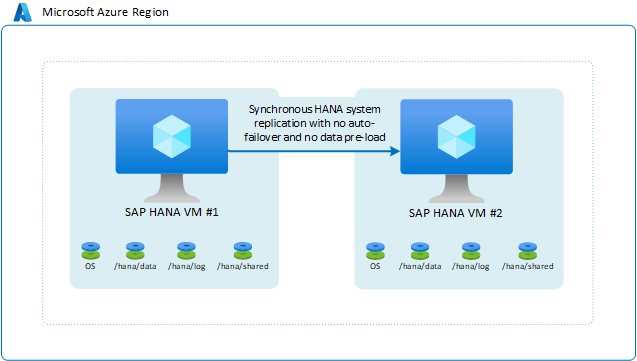
Replica di sistema SAP HANA senza failover automatico e senza precaricamento dei dati
In questo scenario si usa la replica di sistema SAP HANA per spostare i dati in modo sincrono per poter ottenere un RPO pari a 0. D'altro canto, la lunghezza dell'RTO è tale da non richiedere il failover né il precaricamento dei dati nella cache dell'istanza di HANA. In questo caso, è possibile ridurre ancora di più la configurazione eseguendo queste azioni:
- Eseguire un'altra istanza di SAP HANA nella seconda macchina virtuale. L'istanza di SAP HANA nella seconda macchina virtuale accetta la maggior parte della memoria della macchina virtuale. In caso di failover nella seconda macchina virtuale, è necessario arrestare l'istanza di SAP HANA con i dati completamente caricati nella seconda macchina virtuale, in modo che i dati replicati possano essere caricati nella cache dell'istanza di HANA di destinazione nella seconda macchina virtuale.
- Usare dimensioni della macchina virtuale inferiori nella seconda macchina virtuale. Se si verifica un failover, è necessario eseguire un passaggio aggiuntivo prima del failover manuale. In questo passaggio si ridimensiona la macchina virtuale alle dimensioni della macchina virtuale di origine.
Lo scenario è simile al seguente:
Nota
Anche se non si usa il precaricamento dei dati nella destinazione della replica di sistema HANA, sono necessari almeno 64 GB di memoria. È anche necessaria una quantità di memoria sufficiente, oltre ai 64 GB, per conservare i dati rowstore nella memoria dell'istanza di destinazione.
Replica di sistema SAP HANA senza failover automatico e con precaricamento dei dati
In questo scenario i dati replicati nell'istanza di HANA nella seconda macchina virtuale vengono precaricati. Vengono così eliminati i due vantaggi derivanti dal non dover precaricare i dati. In questo caso, non è possibile eseguire un altro sistema SAP HANA nella seconda macchina virtuale, né usare dimensioni della macchina virtuale inferiori. Di conseguenza, i clienti raramente implementano questo scenario.
Replica di sistema SAP HANA con failover automatico
In un'area di Azure, la configurazione di disponibilità standard e più comune è quella in cui due macchine virtuali di Azure che eseguono Linux con pacchetti a disponibilità elevata hanno un cluster di failover definito. Il cluster Linux a disponibilità elevata si basa sul Pacemaker framework che usa SLES o RHEL con fencing device SLES o RHEL come esempio.
Da una prospettiva SAP HANA, la modalità di replica usata è sincronizzata ed è configurato un failover automatico. Nella seconda macchina virtuale l'istanza di SAP HANA agisce come un nodo di hot standby. Il nodo in standby riceve un flusso sincrono di record di modifiche dall'istanza di SAP HANA primaria. Mentre l'applicazione esegue il commit delle transazioni in corrispondenza del nodo HANA primario, il nodo HANA primario attende per confermare il commit all'applicazione fino a quando il nodo SAP HANA secondario non conferma di avere ricevuto il record di commit. SAP HANA offre due modalità di replica sincrona. Per informazioni dettagliate e una descrizione delle differenze tra queste due modalità di replica sincrona, vedere l'articolo di SAP Replication modes for SAP HANA System Replication (Modalità di replica per la replica di sistema SAP HANA).
La configurazione complessiva è simile a quanto segue:
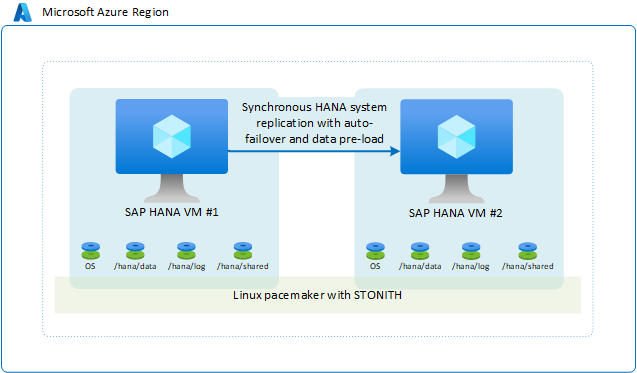
È possibile scegliere questa soluzione perché consente di ottenere un obiettivo del punto di ripristino (RPO) pari a 0 e un obiettivo del tempo di ripristino (RTO) basso. Configurare la connettività client SAP HANA in modo che i client SAP HANA usino l'indirizzo IP virtuale per la connessione alla configurazione della replica di sistema HANA. Una configurazione di questo tipo elimina la necessità di riconfigurare l'applicazione in caso di failover nel nodo secondario. In questo scenario gli SKU della macchina virtuale di Azure per le VM primaria e secondaria devono essere gli stessi.
Passaggi successivi
Per istruzioni dettagliate sull'impostazione di queste configurazioni in Azure, vedere:
- Configurare la replica di sistema SAP HANA nelle macchine virtuali di Azure
- High availability for SAP HANA by using system replication (Disponibilità elevata per SAP HANA tramite la replica di sistema)
Per altre informazioni sulla disponibilità di SAP HANA tra le aree di Azure, vedere: