Che cosa sono la continuità aziendale, la disponibilità elevata e il ripristino di emergenza?
Questo articolo definisce e descrive la pianificazione della continuità aziendale e della continuità aziendale in termini di gestione dei rischi tramite la progettazione di disponibilità elevata e ripristino di emergenza. Anche se questo articolo non fornisce indicazioni esplicite su come soddisfare le proprie esigenze di continuità aziendale, consente di comprendere i concetti usati in tutte le linee guida sull'affidabilità di Microsoft.
La continuità aziendale è lo stato in cui un'azienda può continuare le operazioni durante errori, interruzioni o emergenze. La continuità aziendale richiede una pianificazione, una preparazione proattiva e l'implementazione di sistemi e processi resilienti.
La pianificazione della continuità aziendale richiede l'identificazione, la comprensione, la classificazione e la gestione dei rischi. In base ai rischi e alle loro probabilità, progettare sia la disponibilità elevata che il ripristino di emergenza.
La disponibilità elevata riguarda la progettazione di una soluzione per essere resilienti ai problemi quotidiani e soddisfare le esigenze aziendali per la disponibilità.
Il ripristino di emergenza riguarda la pianificazione di come gestire rischi non comuni e le interruzioni irreversibili che possono comportare.
Continuità aziendale
In generale, le soluzioni cloud sono collegate direttamente alle operazioni aziendali. Ogni volta che una soluzione cloud non è disponibile o riscontra un problema grave, l'impatto sulle operazioni aziendali può essere grave. Un impatto grave può compromettere la continuità aziendale.
L'impatto grave sulla continuità aziendale può includere:
- Perdita di reddito aziendale.
- L'impossibilità di fornire un servizio importante agli utenti.
- Violazione di un impegno che è stato effettuato a un cliente o a un'altra parte.
È importante comprendere e comunicare le aspettative aziendali e le conseguenze degli errori, agli stakeholder importanti, inclusi quelli che progettano, implementano e gestiscono il carico di lavoro. Tali stakeholder rispondono quindi condividendo i costi necessari per soddisfare tale visione. C'è in genere un processo di negoziazione e revisioni di tale visione in base al budget e ad altri vincoli.
Pianificazione della continuità aziendale
Per controllare o evitare completamente un impatto negativo sulla continuità aziendale, è importante creare in modo proattivo un piano di continuità aziendale. Un piano di continuità aziendale si basa sulla valutazione dei rischi e sullo sviluppo di metodi di controllo di tali rischi tramite diversi approcci. I rischi e gli approcci specifici per mitigare variano a seconda dell'organizzazione e del carico di lavoro.
Un piano di continuità aziendale non prende in considerazione solo le funzionalità di resilienza della piattaforma cloud stessa, ma anche le funzionalità dell'applicazione. Un solido piano di continuità aziendale incorpora anche tutti gli aspetti del supporto nell'azienda, tra cui persone, processi manuali o automatizzati correlati all'azienda e altre tecnologie.
La pianificazione della continuità aziendale deve includere i passaggi sequenziali seguenti:
Identificazione dei rischi. Identificare i rischi per la disponibilità o la funzionalità di un carico di lavoro. I possibili rischi possono essere problemi di rete, errori hardware, errore umano, interruzione dell'area e così via. Comprendere l'impatto di ogni rischio.
Classificazione dei rischi. Classificare ogni rischio come un rischio comune, che deve essere inserito in piani per la disponibilità elevata o un rischio non comune, che deve far parte della pianificazione del ripristino di emergenza.
Mitigazione dei rischi. Progettare strategie di mitigazione per disponibilità elevata o ripristino di emergenza per ridurre al minimo o ridurre i rischi, ad esempio usando ridondanza, replica, failover e backup. Prendere in considerazione anche mitigazioni e controlli non tecnici e basati su processi.
La pianificazione della continuità aziendale è un processo, non un evento monouso. Qualsiasi piano di continuità aziendale creato deve essere esaminato e aggiornato regolarmente per garantire che rimanga pertinente ed efficace e che supporti le attuali esigenze aziendali.
Identificazione dei rischi
La fase iniziale della pianificazione della continuità aziendale consiste nell'identificare i rischi per la disponibilità o la funzionalità di un carico di lavoro. Ogni rischio deve essere analizzato per comprenderne la probabilità e la gravità. La gravità deve includere qualsiasi potenziale tempo di inattività o perdita di dati, nonché se eventuali aspetti del resto della progettazione della soluzione potrebbero compensare effetti negativi.
La tabella seguente è un elenco non esaustivo dei rischi, ordinati in base alla probabilità decrescente:
| Rischio di esempio | Descrizione | Regolarità (probabilità) |
|---|---|---|
| Problema di rete temporaneo | Un errore temporaneo in un componente dello stack di rete, che è recuperabile dopo un breve periodo di tempo (in genere alcuni secondi o meno). | Regolare |
| Riavvio della macchina virtuale | Riavvio di una macchina virtuale usata o usata da un servizio dipendente. I riavvii potrebbero verificarsi perché la macchina virtuale si arresta in modo anomalo o deve applicare una patch. | Regolare |
| Errore hardware | Errore di un componente all'interno di un data center, ad esempio un nodo hardware, un rack o un cluster. | Occasionale |
| Interruzione del data center | Interruzione che influisce sulla maggior parte o su tutti i data center, ad esempio un guasto di alimentazione, un problema di connettività di rete o problemi di riscaldamento e raffreddamento. | Insolito |
| Interruzione dell'area | Un'interruzione che interessa un'intera area metropolitana o più ampia, ad esempio una grave calamità naturale. | Molto insolito |
La pianificazione della continuità aziendale non riguarda solo la piattaforma cloud e l'infrastruttura. È importante considerare il rischio di errori umani. Inoltre, alcuni rischi che potrebbero essere tradizionalmente considerati rischi per la sicurezza, le prestazioni o i rischi operativi devono essere considerati anche rischi di affidabilità perché influiscono sulla disponibilità della soluzione.
Di seguito sono riportati alcuni esempi.
| Rischio di esempio | Descrizione |
|---|---|
| Perdita o danneggiamento dei dati | I dati sono stati eliminati, sovrascritti o altrimenti danneggiati da un incidente o da una violazione della sicurezza come un attacco ransomware. |
| Bug software | Una distribuzione di codice nuovo o aggiornato introduce un bug che influisce sulla disponibilità o sull'integrità, lasciando il carico di lavoro in uno stato di malfunzionamento. |
| Distribuzioni non riuscite | Una distribuzione di un nuovo componente o di una nuova versione non è riuscita, lasciando la soluzione in uno stato incoerente. |
| Attacchi Denial of Service | Il sistema è stato attaccato nel tentativo di impedire l'uso legittimo della soluzione. |
| Amministratori non autorizzati | Un utente con privilegi amministrativi ha intenzionalmente eseguito un'azione dannosa contro il sistema. |
| Flusso imprevisto di traffico verso un'applicazione | Un picco del traffico ha sovraccaricato le risorse del sistema. |
L'analisi della modalità di errore (FMA) è il processo di identificazione di potenziali modi in cui un carico di lavoro o dei relativi componenti potrebbe avere esito negativo e il comportamento della soluzione in tali situazioni. Per altre informazioni, vedere Raccomandazioni per l'esecuzione dell'analisi della modalità di errore.
Classificazione rischio
I piani di continuità aziendale devono affrontare rischi comuni e non comuni.
I rischi comuni sono pianificati e previsti. Ad esempio, in un ambiente cloud è comune che si verifichino errori temporanei, tra cui brevi interruzioni di rete, riavvii delle apparecchiature a causa di patch, timeout quando un servizio è occupato e così via. Poiché questi eventi si verificano regolarmente, i carichi di lavoro devono essere resilienti.
Una strategia di disponibilità elevata deve considerare e controllare per ogni rischio di questo tipo.
I rischi non comuni sono in genere il risultato di un evento imprevisto, ad esempio una calamità naturale o un grave attacco di rete, che può causare un'interruzione irreversibile.
I processi di ripristino di emergenza gestiscono questi rari rischi.
La disponibilità elevata e il ripristino di emergenza sono correlati ed è quindi importante pianificare le strategie per entrambi insieme.
È importante comprendere che la classificazione dei rischi dipende dall'architettura del carico di lavoro e dai requisiti aziendali e alcuni rischi possono essere classificati come disponibilità elevata per un carico di lavoro e ripristino di emergenza per un altro carico di lavoro. Ad esempio, un'interruzione completa dell'area di Azure viene in genere considerata un rischio di ripristino di emergenza per i carichi di lavoro in tale area. Tuttavia, per i carichi di lavoro che usano più aree di Azure in una configurazione attiva-attiva con replica completa, ridondanza e failover automatico dell'area, un'interruzione dell'area viene classificata come rischio a disponibilità elevata.
Mitigazione dei rischi
La mitigazione dei rischi consiste nello sviluppo di strategie per la disponibilità elevata o il ripristino di emergenza per ridurre al minimo o ridurre i rischi per la continuità aziendale. La mitigazione dei rischi può essere basata sulla tecnologia o basata sull'uomo.
Mitigazione dei rischi basata sulla tecnologia
La mitigazione dei rischi basata sulla tecnologia usa controlli di rischio basati sulla modalità di implementazione e configurazione del carico di lavoro, ad esempio:
- Ridondanza
- Replica dei dati
- Failover
- Backup
I controlli dei rischi basati sulla tecnologia devono essere considerati all'interno del contesto del piano di continuità aziendale.
Ad esempio:
Requisiti di tempi di inattività ridotti. Alcuni piani di continuità aziendale non sono in grado di tollerare alcuna forma di rischio di inattività a causa di requisiti rigorosi di disponibilità elevata. Esistono determinati controlli basati sulla tecnologia che potrebbero richiedere tempo per ricevere una notifica da parte di un essere umano e quindi rispondere. I controlli di rischio basati sulla tecnologia che includono processi manuali lenti potrebbero non essere adatti all'inclusione nella strategia di mitigazione dei rischi.
Tolleranza a un errore parziale. Alcuni piani di continuità aziendale sono in grado di tollerare un flusso di lavoro in esecuzione in uno stato danneggiato. Quando una soluzione opera in uno stato danneggiato, alcuni componenti potrebbero essere disabilitati o non funzionali, ma le operazioni aziendali di base possono continuare a essere eseguite. Per altre informazioni, vedere Raccomandazioni per la riparazione automatica e la conservazione automatica.
Mitigazione dei rischi basata sull'uomo
La mitigazione dei rischi basata sull'uomo usa controlli di rischio basati su processi aziendali, ad esempio:
- Attivazione di un playbook di risposta.
- Eseguire il fallback alle operazioni manuali.
- Formazione e cambiamenti culturali.
Importante
Gli individui che progettano, implementano, operano e si evolveno il carico di lavoro devono essere competenti, incoraggiati a parlare se hanno preoccupazioni e sentono un senso di responsabilità per il sistema.
Poiché i controlli dei rischi basati sull'uomo sono spesso più lenti rispetto ai controlli basati sulla tecnologia e più soggetti a errori umani, un buon piano di continuità aziendale deve includere un processo di controllo formale delle modifiche per qualsiasi cosa che altererebbe lo stato del sistema in esecuzione. Si consideri ad esempio l'implementazione dei processi seguenti:
- Testare rigorosamente i carichi di lavoro in base alla criticità del carico di lavoro. Per evitare problemi correlati alle modifiche, assicurarsi di testare le modifiche apportate al carico di lavoro.
- Introdurre controlli di qualità strategici come parte delle procedure di distribuzione sicure del carico di lavoro. Per altre informazioni, vedere Raccomandazioni per le procedure di distribuzione sicure.
- Formalizzare le procedure per l'accesso alla produzione ad hoc e la manipolazione dei dati. Queste attività, indipendentemente da quanto minori, possono presentare un rischio elevato di causare incidenti di affidabilità. Le procedure possono includere l'associazione con un altro tecnico, l'uso di elenchi di controllo e l'acquisizione di verifiche peer prima di eseguire script o applicare modifiche.
Disponibilità elevata
La disponibilità elevata è lo stato in cui un carico di lavoro specifico può mantenere il livello di tempo di attività necessario su base giornaliera, anche durante gli errori temporanei e gli errori intermittenti. Poiché questi eventi si verificano regolarmente, è importante che ogni carico di lavoro sia progettato e configurato per la disponibilità elevata in base ai requisiti dell'applicazione specifica e delle aspettative dei clienti. La disponibilità elevata di ogni carico di lavoro contribuisce al piano di continuità aziendale.
Poiché la disponibilità elevata può variare con ogni carico di lavoro, è importante comprendere i requisiti e le aspettative dei clienti quando si determina la disponibilità elevata. Ad esempio, un'applicazione usata dall'organizzazione per ordinare le forniture per uffici potrebbe richiedere un livello di tempo di attività relativamente basso, mentre un'applicazione finanziaria critica potrebbe richiedere tempi di attività molto più elevati. Anche all'interno di un carico di lavoro, diversi flussi potrebbero avere requisiti diversi. Ad esempio, in un'applicazione e-commerce, i flussi che supportano l'esplorazione e l'inserimento di ordini potrebbero essere più importanti rispetto all'evasione degli ordini e ai flussi di elaborazione back-office. Per altre informazioni sui flussi, vedere Raccomandazioni per l'identificazione e la classificazione dei flussi.
In genere, il tempo di attività viene misurato in base al numero di "nove" nella percentuale di tempo di attività. La percentuale di tempo di attività è correlata alla quantità di tempo di inattività consentita per un determinato periodo di tempo. Di seguito sono riportati alcuni esempi.
- Un requisito di tempo di attività del 99,9% (tre nove) consente circa 43 minuti di inattività in un mese.
- Un requisito di tempo di attività del 99,95% (tre e mezzo nove) consente circa 21 minuti di tempo di inattività in un mese.
Maggiore è il requisito di tempo di attività, minore è la tolleranza per le interruzioni e maggiore è il lavoro necessario per raggiungere tale livello di disponibilità. Il tempo di attività non viene misurato in base al tempo di attività di un singolo componente, ad esempio un nodo, ma alla disponibilità complessiva dell'intero carico di lavoro.
Importante
Non sovraccaricare la soluzione per raggiungere livelli di affidabilità superiori rispetto a quelli giustificati. Usare i requisiti aziendali per guidare le decisioni.
Elementi di progettazione a disponibilità elevata
Per ottenere i requisiti di disponibilità elevata, un carico di lavoro può includere diversi elementi di progettazione. Alcuni degli elementi comuni sono elencati e descritti di seguito in questa sezione.
Nota
Alcuni carichi di lavoro sono cruciali, il che significa che qualsiasi tempo di inattività può avere gravi conseguenze per la vita umana e la sicurezza o gravi perdite finanziarie. Se si progetta un carico di lavoro cruciale, è necessario considerare aspetti specifici quando si progetta la soluzione e si gestisce la continuità aziendale. Per altre informazioni, vedere Framework ben progettato di Azure: Carichi di lavoro cruciali.
Servizi e livelli di Azure che supportano la disponibilità elevata
Molti servizi di Azure sono progettati per essere a disponibilità elevata e possono essere usati per creare carichi di lavoro a disponibilità elevata. Di seguito sono riportati alcuni esempi.
- Azure set di scalabilità di macchine virtuali offrire disponibilità elevata per le macchine virtuali creando e gestendo automaticamente le istanze di macchine virtuali e distribuendo tali istanze di macchina virtuale per ridurre l'impatto degli errori dell'infrastruttura.
- app Azure Servizio offre disponibilità elevata tramite diversi approcci, tra cui lo spostamento automatico dei ruoli di lavoro da un nodo non integro a un nodo integro e la funzionalità per la riparazione automatica da molti tipi di errore comuni.
Usare ogni guida all'affidabilità del servizio per comprendere le funzionalità del servizio, decidere quali livelli usare e determinare quali funzionalità includere nella strategia di disponibilità elevata.
Esaminare i contratti di servizio per ogni servizio per comprendere i livelli di disponibilità previsti e le condizioni che è necessario soddisfare. Potrebbe essere necessario selezionare o evitare livelli specifici di servizi per ottenere determinati livelli di disponibilità. Alcuni servizi di Microsoft sono offerti con la comprensione che non viene fornito alcun contratto di servizio, ad esempio livelli di sviluppo o di base, o che la risorsa potrebbe essere recuperata dal sistema in esecuzione, ad esempio offerte basate su spot. Inoltre, alcuni livelli hanno aggiunto funzionalità di affidabilità, ad esempio il supporto per le zone di disponibilità.
Tolleranza di errore
La tolleranza di errore è la capacità di un sistema di continuare a funzionare, in alcune capacità definite, in caso di errore. Ad esempio, un'applicazione Web potrebbe essere progettata per continuare a funzionare anche se un singolo server Web ha esito negativo. La tolleranza di errore può essere ottenuta tramite ridondanza, failover, partizionamento, riduzione delle prestazioni normale e altre tecniche.
La tolleranza di errore richiede anche che le applicazioni gestisca errori temporanei. Quando si compila codice personalizzato, potrebbe essere necessario abilitare manualmente la gestione degli errori temporanei. Alcuni servizi di Azure offrono una gestione degli errori temporanei predefinita per alcune situazioni. Ad esempio, per impostazione predefinita App per la logica di Azure tentativi automatici di richieste non riuscite ad altri servizi. Per altre informazioni, vedere Raccomandazioni per la gestione degli errori temporanei.
Ridondanza
La ridondanza è la procedura per duplicare istanze o dati per aumentare l'affidabilità del carico di lavoro.
La ridondanza può essere ottenuta distribuendo repliche o istanze ridondanti in uno dei modi seguenti:
- All'interno di un data center (ridondanza locale)
- Tra le zone di disponibilità all'interno di un'area (ridondanza della zona)
- Tra aree (ridondanza geografica).
Ecco alcuni esempi di come alcuni servizi di Azure offrono opzioni di ridondanza:
- app Azure Servizio consente di eseguire più istanze dell'applicazione, per assicurarsi che l'applicazione rimanga disponibile anche se un'istanza ha esito negativo. Se si abilita la ridondanza della zona, tali istanze vengono distribuite tra più zone di disponibilità nell'area di Azure usata.
- Archiviazione di Azure offre disponibilità elevata replicando automaticamente i dati almeno tre volte. È possibile distribuire tali repliche tra zone di disponibilità abilitando l'archiviazione con ridondanza della zona e in molte aree è anche possibile replicare i dati di archiviazione tra aree usando l'archiviazione con ridondanza geografica.
- database SQL di Azure dispone di più repliche per assicurarsi che i dati rimangano disponibili anche se una replica ha esito negativo.
Per altre informazioni sulla ridondanza, vedere Raccomandazioni per la progettazione di ridondanza e raccomandazioni per l'uso di zone e aree di disponibilità.
Scalabilità ed elasticità
La scalabilità e l'elasticità sono le capacità di un sistema di gestire un carico maggiore aggiungendo e rimuovendo risorse (scalabilità) e di farlo rapidamente quando i requisiti cambiano (elasticità). La scalabilità e l'elasticità consentono a un sistema di mantenere la disponibilità durante i carichi di picco.
Molti servizi di Azure supportano la scalabilità. Di seguito sono riportati alcuni esempi.
- Azure set di scalabilità di macchine virtuali, Azure Gestione API e molti altri servizi supportano la scalabilità automatica di Monitoraggio di Azure. Con la scalabilità automatica di Monitoraggio di Azure è possibile specificare criteri come "quando la CPU supera costantemente l'80%, aggiungere un'altra istanza".
- Funzioni di Azure può effettuare il provisioning dinamico delle istanze per gestire le richieste.
- Azure Cosmos DB supporta la velocità effettiva con scalabilità automatica, in cui il servizio può gestire automaticamente le risorse assegnate ai database in base ai criteri specificati.
La scalabilità è un fattore chiave da considerare durante un malfunzionamento parziale o completo. Se una replica o un'istanza di calcolo non è disponibile, i componenti rimanenti potrebbero dover sopportare un carico maggiore per gestire il carico gestito in precedenza dal nodo con errori. Prendere in considerazione l'overprovisioning se il sistema non è in grado di ridimensionare abbastanza rapidamente per gestire le modifiche previste nel carico.
Per altre informazioni su come progettare un sistema scalabile ed elastico, vedere Raccomandazioni per la progettazione di una strategia di scalabilità affidabile.
Tecniche di distribuzione senza tempi di inattività
Le distribuzioni e altre modifiche di sistema comportano un rischio significativo di tempi di inattività. Poiché il rischio di tempo di inattività è una sfida per i requisiti di disponibilità elevata, è importante usare procedure di distribuzione senza tempi di inattività per apportare aggiornamenti e modifiche alla configurazione senza tempi di inattività necessari.
Le tecniche di distribuzione senza tempi di inattività possono includere:
- Aggiornamento di un subset delle risorse alla volta.
- Controllo della quantità di traffico che raggiunge la nuova distribuzione.
- Monitoraggio per qualsiasi impatto sugli utenti o sul sistema.
- Correzione rapida del problema, ad esempio eseguendo il rollback a una distribuzione valida nota precedente.
Per altre informazioni sulle tecniche di distribuzione senza tempi di inattività, vedere Procedure di distribuzione sicure.
Azure usa approcci di distribuzione senza tempi di inattività per i propri servizi. Quando si creano applicazioni personalizzate, è possibile adottare distribuzioni senza tempi di inattività tramite diversi approcci, ad esempio:
- App Azure Container offre più revisioni dell'applicazione, che possono essere usate per ottenere distribuzioni senza tempi di inattività.
- servizio Azure Kubernetes (servizio Azure Kubernetes) supporta un'ampia gamma di tecniche di distribuzione senza tempi di inattività.
Anche se le distribuzioni senza tempi di inattività sono spesso associate alle distribuzioni di applicazioni, devono essere usate anche per le modifiche alla configurazione. Ecco alcuni modi in cui è possibile applicare le modifiche di configurazione in modo sicuro:
- Archiviazione di Azure consente di modificare le chiavi di accesso dell'account di archiviazione in più fasi, impedendo così tempi di inattività durante le operazioni di rotazione delle chiavi.
- app Azure Configurazione fornisce flag di funzionalità, snapshot e altre funzionalità che consentono di controllare la modalità di applicazione delle modifiche alla configurazione.
Se si decide di non implementare distribuzioni senza tempi di inattività, assicurarsi di definire le finestre di manutenzione in modo da poter apportare modifiche al sistema in un momento in cui gli utenti lo prevedono.
Test automatizzati
È importante testare la capacità della soluzione di resistere alle interruzioni e agli errori considerati nell'ambito della disponibilità elevata. Molti di questi errori possono essere simulati in ambienti di test. Il test della capacità della soluzione di tollerare o ripristinare automaticamente da un'ampia gamma di tipi di errore è denominato chaos engineering. La progettazione di Chaos è fondamentale per le organizzazioni mature con standard rigorosi per la disponibilità elevata. Azure Chaos Studio è uno strumento di progettazione chaos che può simulare alcuni tipi di errore comuni.
Per altre informazioni, vedere Raccomandazioni per la progettazione di una strategia di test di affidabilità.
Monitoraggio e avvisi
Il monitoraggio consente di conoscere l'integrità del sistema, anche quando vengono eseguite mitigazioni automatizzate. Il monitoraggio è fondamentale per comprendere il comportamento della soluzione e per controllare i primi segnali di errori, ad esempio un aumento delle percentuali di errore o un utilizzo elevato delle risorse. Con gli avvisi, è possibile ricevere in modo proattivo modifiche importanti nell'ambiente.
Azure offre un'ampia gamma di funzionalità di monitoraggio e avviso, tra cui:
- Monitoraggio di Azure raccoglie log e metriche da risorse e applicazioni di Azure e può inviare avvisi e visualizzare i dati nei dashboard.
- Application Insights di Monitoraggio di Azure offre un monitoraggio dettagliato delle applicazioni.
- Integrità dei servizi di Azure e Azure Integrità risorse monitorare l'integrità della piattaforma Azure e delle risorse.
- Gli eventi pianificati consigliano quando la manutenzione è pianificata per le macchine virtuali.
Per altre informazioni, vedere Raccomandazioni per la progettazione di una strategia di monitoraggio e avviso affidabile.
Ripristino di emergenza
Un'emergenza è un evento distinto, insolito e importante che ha un impatto più ampio e duraturo rispetto a quello che un'applicazione può attenuare tramite l'aspetto della disponibilità elevata della progettazione. Esempi di emergenze includono:
- Calamità naturali, ad esempio uragani, terremoti, inondazioni o incendi.
- Errori umani che comportano un impatto significativo, ad esempio l'eliminazione accidentale dei dati di produzione o un firewall non configurato correttamente che espone dati sensibili.
- Eventi imprevisti di sicurezza principali, ad esempio attacchi Denial of Service o ransomware che portano a danneggiamento dei dati, perdita di dati o interruzioni del servizio.
Il ripristino di emergenza riguarda la pianificazione della risposta a questi tipi di situazioni.
Nota
È consigliabile seguire le procedure consigliate nella soluzione per ridurre al minimo la probabilità di questi eventi. Tuttavia, anche dopo un'attenta pianificazione proattiva, è prudente pianificare come rispondere a queste situazioni se si verificano.
Requisiti di ripristino di emergenza
A causa della rarità e della gravità degli eventi di emergenza, la pianificazione del ripristino di emergenza comporta aspettative diverse per la risposta. Molte organizzazioni accettano il fatto che, in uno scenario di emergenza, un certo livello di tempo di inattività o perdita di dati è inevitabile. Un piano di ripristino di emergenza completo deve specificare i requisiti aziendali critici seguenti per ogni flusso:
L'obiettivo del punto di ripristino (RPO) è la durata massima della perdita di dati accettabile in caso di emergenza. RPO viene misurato in unità di tempo, ad esempio "30 minuti di dati" o "quattro ore di dati".
L'obiettivo del tempo di ripristino (RTO) è la durata massima del tempo di inattività accettabile in caso di emergenza, in cui il tempo di inattività è definito dalla specifica. L'obiettivo RTO viene misurato anche in unità di tempo, ad esempio "otto ore di tempo di inattività".
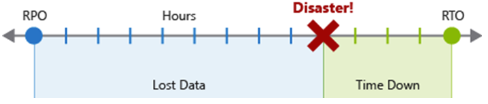
Ogni componente o flusso nel carico di lavoro può avere singoli valori RPO e RTO. Esaminare i rischi dello scenario di emergenza e le potenziali strategie di ripristino quando si decidono i requisiti. Il processo di specificare un RPO e un RTO crea in modo efficace i requisiti di ripristino di emergenza per il carico di lavoro in seguito a problemi aziendali univoci (costi, impatto, perdita di dati e così via).
Nota
Sebbene sia tentata di mirare a un obiettivo RTO e RPO pari a zero (nessun tempo di inattività e nessuna perdita di dati in caso di emergenza), in pratica è difficile e costoso implementare. È importante per gli stakeholder tecnici e aziendali discutere questi requisiti insieme e decidere i requisiti realistici. Per altre informazioni, vedere Consigli per la definizione degli obiettivi di affidabilità.
Piani di ripristino di emergenza
Indipendentemente dalla causa dell'emergenza, è importante creare un piano di ripristino di emergenza ben definito e testabile. Tale piano verrà usato come parte della progettazione dell'infrastruttura e dell'applicazione per supportarlo attivamente. È possibile creare più piani di ripristino di emergenza per diversi tipi di situazioni. I piani di ripristino di emergenza spesso si basano sui controlli dei processi e sull'intervento manuale.
Il ripristino di emergenza non è una funzionalità automatica di Azure. Tuttavia, molti servizi offrono funzionalità e funzionalità che è possibile usare per supportare le strategie di ripristino di emergenza. Esaminare le guide all'affidabilità per ogni servizio di Azure per comprendere il funzionamento del servizio e le relative funzionalità e quindi eseguire il mapping di tali funzionalità al piano di ripristino di emergenza.
Le sezioni seguenti elencano alcuni elementi comuni di un piano di ripristino di emergenza e descrivono in che modo Azure può essere utile per raggiungerli.
Failover e failback
Alcuni piani di ripristino di emergenza comportano il provisioning di una distribuzione secondaria in un'altra posizione. Se un'emergenza influisce sulla distribuzione primaria della soluzione, è possibile eseguire il failover del traffico verso l'altro sito. Il failover richiede un'attenta pianificazione e implementazione. Azure offre un'ampia gamma di servizi per facilitare il failover, ad esempio:
- Azure Site Recovery offre failover automatico per ambienti locali e soluzioni ospitate da macchine virtuali in Azure.
- Frontdoor di Azure e Gestione traffico di Azure supportano il failover automatico del traffico in ingresso tra distribuzioni diverse della soluzione, ad esempio in aree diverse.
In genere, un processo di failover richiede tempo per rilevare che l'istanza primaria non è riuscita e passare all'istanza secondaria. Assicurarsi che l'obiettivo RTO del carico di lavoro sia allineato al tempo di failover.
È anche importante considerare il failback, ovvero il processo con cui si ripristinano le operazioni nell'area primaria dopo il ripristino. Il failback può essere complesso da pianificare e implementare. Ad esempio, i dati nell'area primaria potrebbero essere stati scritti dopo l'inizio del failover. È necessario prendere decisioni aziendali accurate sulla modalità di gestione dei dati.
Backup
I backup comportano l'esecuzione di una copia dei dati e l'archiviazione sicura per un periodo di tempo definito. Con i backup è possibile eseguire il ripristino da situazioni di emergenza quando il failover automatico in un'altra replica non è possibile o quando si è verificato il danneggiamento dei dati.
Quando si usano i backup come parte di un piano di ripristino di emergenza, è importante prendere in considerazione quanto segue:
Posizione di archiviazione. Quando si usano i backup come parte di un piano di ripristino di emergenza, questi devono essere archiviati separatamente nei dati principali. I backup vengono in genere archiviati in un'altra area di Azure.
Perdita di dati. Poiché i backup vengono in genere eseguiti raramente, il ripristino del backup comporta in genere la perdita di dati. Per questo motivo, il ripristino di backup deve essere usato come ultima risorsa e un piano di ripristino di emergenza deve specificare la sequenza di passaggi e i tentativi di ripristino che devono essere eseguiti prima del ripristino da un backup. È importante assicurarsi che l'RPO del carico di lavoro sia allineato all'intervallo di backup.
Tempo di recupero. Il ripristino del backup richiede spesso tempo, quindi è fondamentale testare i backup e i processi di ripristino per verificarne l'integrità e comprendere il tempo necessario per il processo di ripristino. Assicurarsi che gli account RTO del carico di lavoro siano necessari per il tempo necessario per ripristinare il backup.
Molti servizi di archiviazione e dati di Azure supportano i backup, ad esempio i seguenti:
- Backup di Azure offre backup automatici per dischi di macchine virtuali, account di archiviazione, servizio Azure Kubernetes e un'ampia gamma di altre origini.
- Molti servizi di database di Azure, tra cui database SQL di Azure e Azure Cosmos DB, hanno una funzionalità di backup automatizzata per i database.
- Azure Key Vault offre funzionalità per eseguire il backup di segreti, certificati e chiavi.
Distribuzioni automatizzate
Per distribuire e configurare rapidamente le risorse necessarie in caso di emergenza, usare asset Di infrastruttura come codice (IaC), ad esempio file Bicep, modelli arm o file di configurazione Terraform. L'uso di IaC riduce il tempo di ripristino e il potenziale errore, rispetto alla distribuzione manuale e alla configurazione delle risorse.
Test ed esercitazioni
È fondamentale convalidare e testare regolarmente i piani di ripristino di emergenza, nonché la strategia di affidabilità più ampia. Includere tutti i processi umani nelle esercitazioni e non solo concentrarsi sui processi tecnici.
Se i processi di ripristino non sono stati testati in una simulazione di emergenza, è più probabile che si verifichino problemi gravi quando vengono usati in un'emergenza effettiva. Inoltre, testando i piani di ripristino di emergenza e i processi necessari, è possibile convalidare la fattibilità dell'RTO.
Per altre informazioni, vedere Raccomandazioni per la progettazione di una strategia di test di affidabilità.
Contenuto correlato
- Usare le guide all'affidabilità dei servizi di Azure per comprendere in che modo ogni servizio di Azure supporta l'affidabilità nella progettazione e per informazioni sulle funzionalità che è possibile integrare nei piani di disponibilità elevata e ripristino di emergenza.
- Usare azure Well-Architected Framework: pilastro affidabilità per altre informazioni su come progettare un carico di lavoro affidabile in Azure.
- Usare il punto di vista di Well-Architected Framework sui servizi di Azure per altre informazioni su come configurare ogni servizio di Azure per soddisfare i requisiti di affidabilità e negli altri pilastri del framework ben progettato.
- Per altre informazioni sulla pianificazione del ripristino di emergenza, vedere Raccomandazioni per la progettazione di una strategia di ripristino di emergenza.