Esercitazione 1: Sviluppare e registrare un set di funzionalità con l'archivio delle funzionalità gestite
Questa serie di esercitazioni illustra come le funzionalità integrano perfettamente tutte le fasi del ciclo di vita di apprendimento automatico: prototipazione, training e operazionalizzazione.
È possibile usare l'archivio delle funzionalità gestite di Azure Machine Learning per individuare, creare e operazionalizzare le funzionalità. Il ciclo di vita di apprendimento automatico include una fase di prototipazione in cui si sperimentano varie funzionalità. Include anche una fase di operazionalizzazione, in cui vengono distribuiti i modelli e vengono eseguiti i passaggi di inferenza per cercare i dati delle funzionalità. Le funzionalità fungono da tessuto connettivo nel ciclo di vita di apprendimento automatico. Per altre informazioni sui concetti di base per archivio delle funzionalità gestite, vedere Informazioni sulle archivio delle funzionalità gestite e Informazioni sulle entità di primo livello nelle risorse di archivio delle funzionalità gestite.
Questa esercitazione descrive come creare una specifica del set di funzionalità con trasformazioni personalizzate. Questo set di funzionalità viene quindi usato per generare dati di training, abilitare la materializzazione ed eseguire un back-fill. La materializzazione calcola i valori delle funzionalità di una finestra e quindi li archivia in un archivio di materializzazione. Tutte le query sulle funzionalità possono quindi attingere a tali valori dall'archivio di materializzazione.
Senza materializzazione, una query del set di funzionalità applica le trasformazioni all'origine in tempo reale, per calcolare le funzionalità prima che la query restituisca i valori. Questo processo offre buoni risultati per la fase di prototipazione. Tuttavia, per le operazioni di training e inferenza in un ambiente di produzione, è consigliabile materializzare le funzionalità per una maggiore affidabilità e disponibilità.
Questa è la prima parte di una serie di esercitazioni sull'archivio delle funzionalità gestite. Si apprenderà come:
- Creare una nuova risorsa minima dell'archivio delle funzionalità.
- Sviluppare e testare in locale un set di funzionalità con trasformazione delle funzionalità.
- Registrare un'entità dell'archivio delle funzionalità con l'archivio delle funzionalità.
- Registrare il set di funzionalità sviluppato con l'archivio delle funzionalità.
- Generare un dataframe di training di esempio usando le funzionalità create.
- Abilitare la materializzazione offline nei set di funzionalità ed eseguire il back-fill dei dati delle funzionalità.
Questa serie di esercitazioni include due tracce:
- La traccia solo SDK usa solo gli SDK Python. Scegliere questa traccia per lo sviluppo e la distribuzione di tipo puro basati su Python.
- La traccia SDK e interfaccia della riga di comando usa l'SDK Python solo per lo sviluppo e il test del set di funzionalità e usa l'interfaccia della riga di comando per le operazioni CRUD (creazione, lettura, aggiornamento ed eliminazione). Questa traccia è utile negli scenari di integrazione continua e recapito continuo (CI/CD) o GitOps, in cui è preferibile usare l'interfaccia della riga di comando/YAML.
Prerequisiti
Prima di procedere con questa esercitazione, assicurarsi di soddisfare questi prerequisiti:
Un'area di lavoro di Azure Machine Learning. Per altre informazioni sulla creazione dell'area di lavoro, vedere Avvio rapido: Creare risorse dell'area di lavoro.
Nell'account utente è necessario il ruolo Proprietario per il gruppo di risorse in cui viene creato l'archivio funzionalità.
Se si sceglie di usare un nuovo gruppo di risorse per questa esercitazione, è possibile eliminare facilmente tutte le risorse eliminando il gruppo di risorse.
Preparare l'ambiente del notebook
Questa esercitazione usa un notebook Spark di Azure Machine Learning per lo sviluppo.
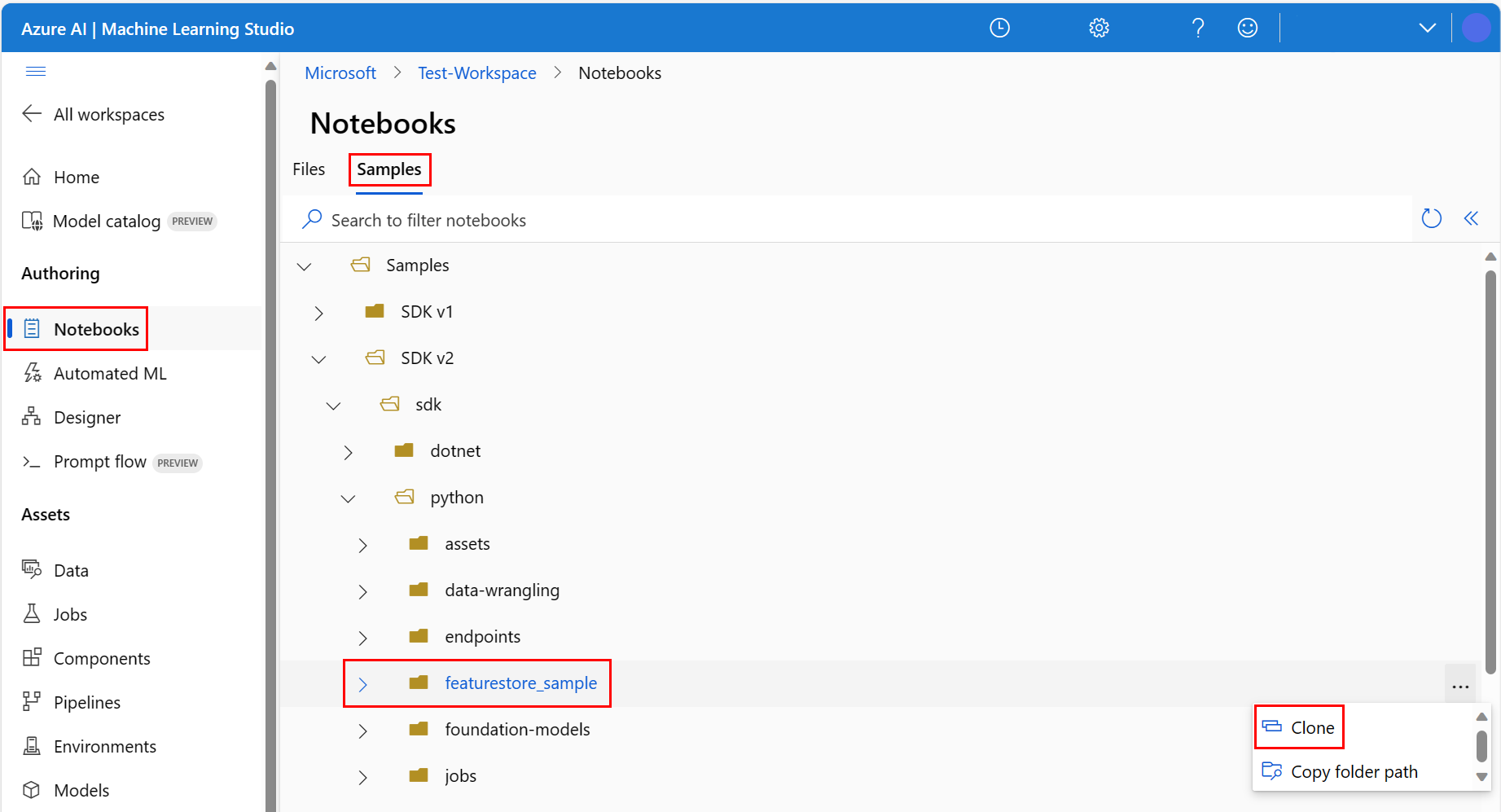
Nell'ambiente studio di Azure Machine Learning selezionare Notebook nel riquadro sinistro e quindi selezionare la scheda Esempi.
Passare alla directory featurestore_sample (selezionare Esempi>SDK v2>sdk>python>featurestore_sample) e quindi selezionare Clona.
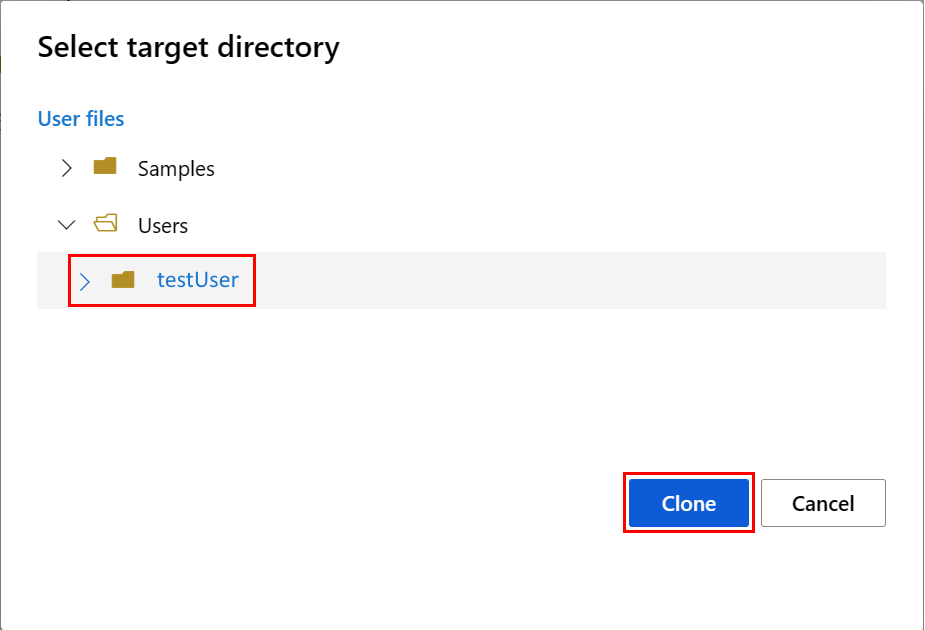
Viene visualizzato il pannello Seleziona la directory di destinazione. Selezionare la directory Utenti, quindi selezionare il proprio nome utente e infine selezionare Clona.
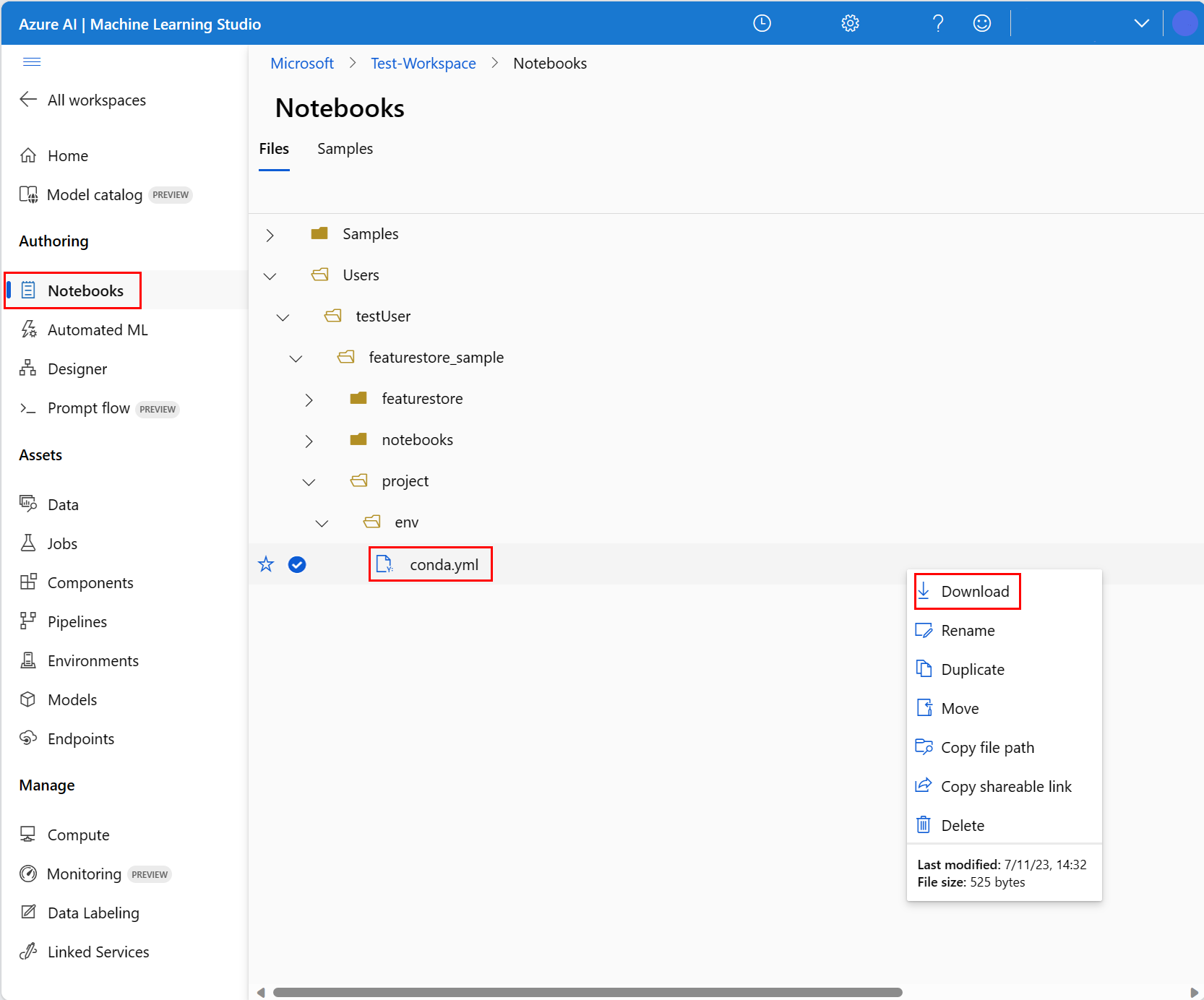
Per configurare l'ambiente notebook, è necessario caricare il file conda.yml:
- Selezionare Notebook nel riquadro sinistro e quindi selezionare la scheda File.
- Passare alla directory env (selezionare Utenti>nome_utente>featurestore_sample>project>env), quindi selezionare il file conda.yml.
- Selezionare Download.
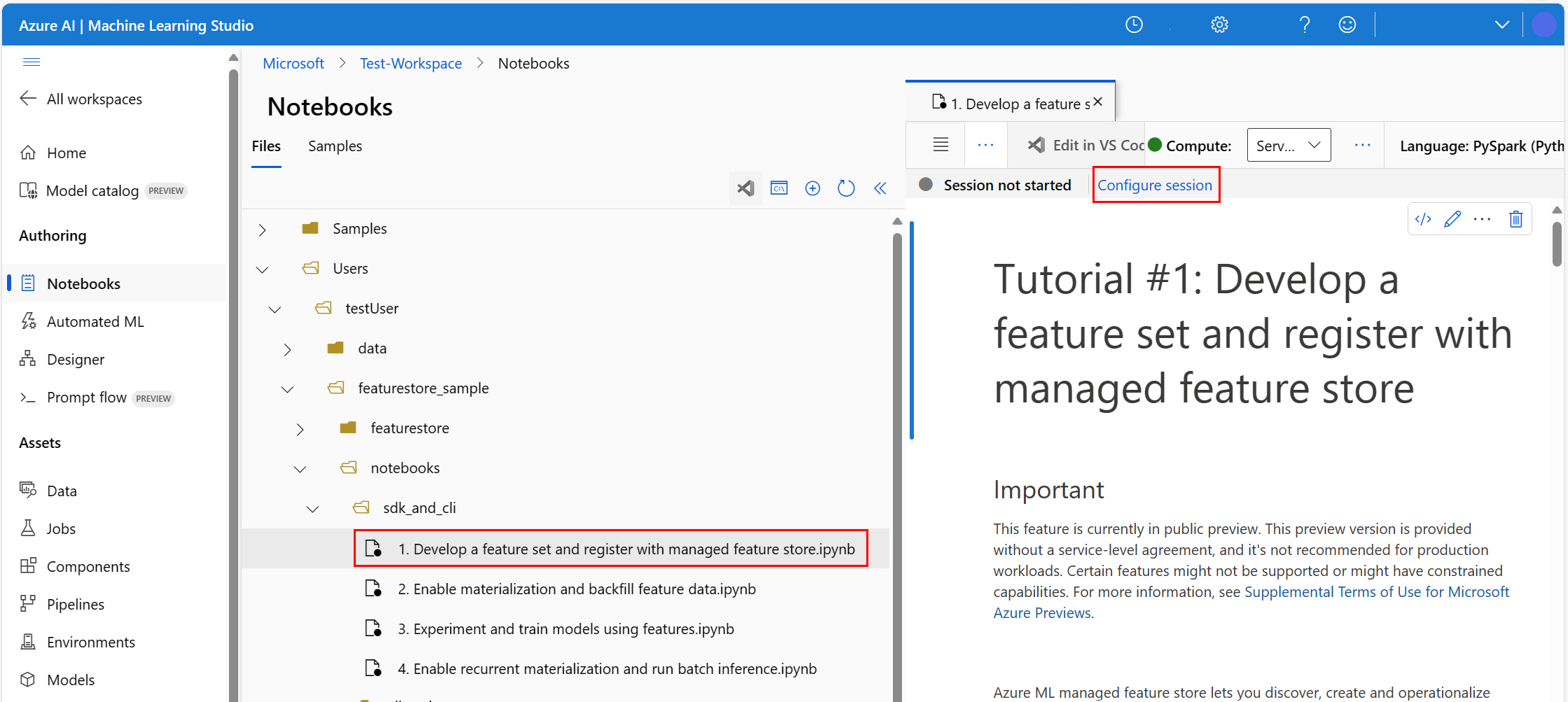
- Nell'elenco a discesa Ambiente di calcolo sulla barra di spostamento in alto selezionare Ambiente di calcolo Spark serverless. L'operazione potrebbe richiedere uno o due minuti. Attendere che sulla barra di stato in alto venga visualizzata l'opzione Configura sessione.
- Selezionare Configura sessione sulla barra di stato in alto.
- Selezionare Pacchetti Python.
- Selezionare Carica file Conda.
- Selezionare il file
conda.ymlscaricato nel dispositivo locale. - (Facoltativo) Aumentare il timeout della sessione (tempo di inattività in minuti) per ridurre il tempo di avvio del cluster Spark serverless.
Nell'ambiente Azure Machine Learning aprire il notebook e quindi selezionare Configura sessione.
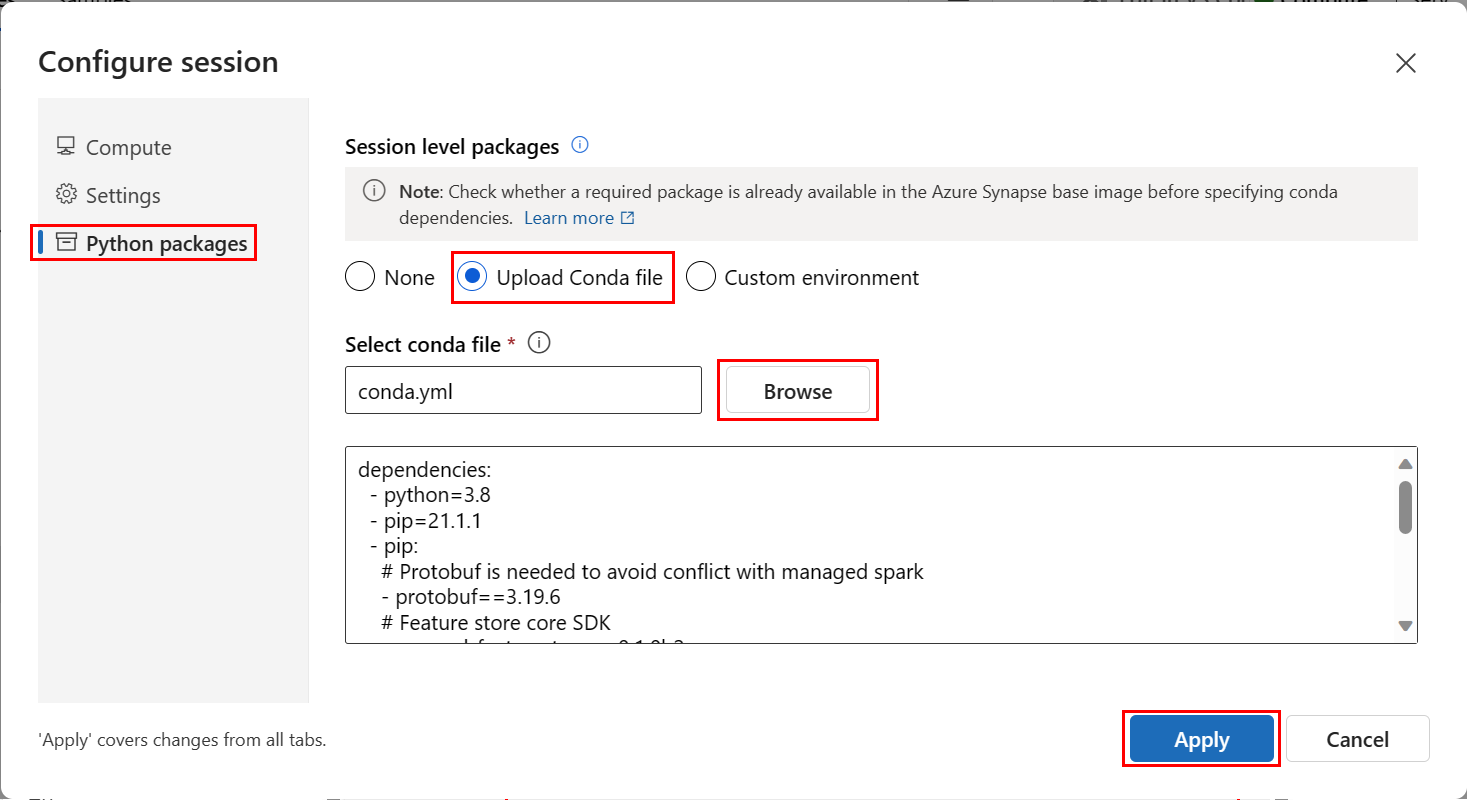
Nel pannello Configura sessione selezionare Pacchetti Python.
Caricare il file Conda:
- Nella scheda Pacchetti Python selezionare Carica file Conda.
- Passare alla directory che ospita il file Conda.
- Selezionare conda.yml e quindi Apri.
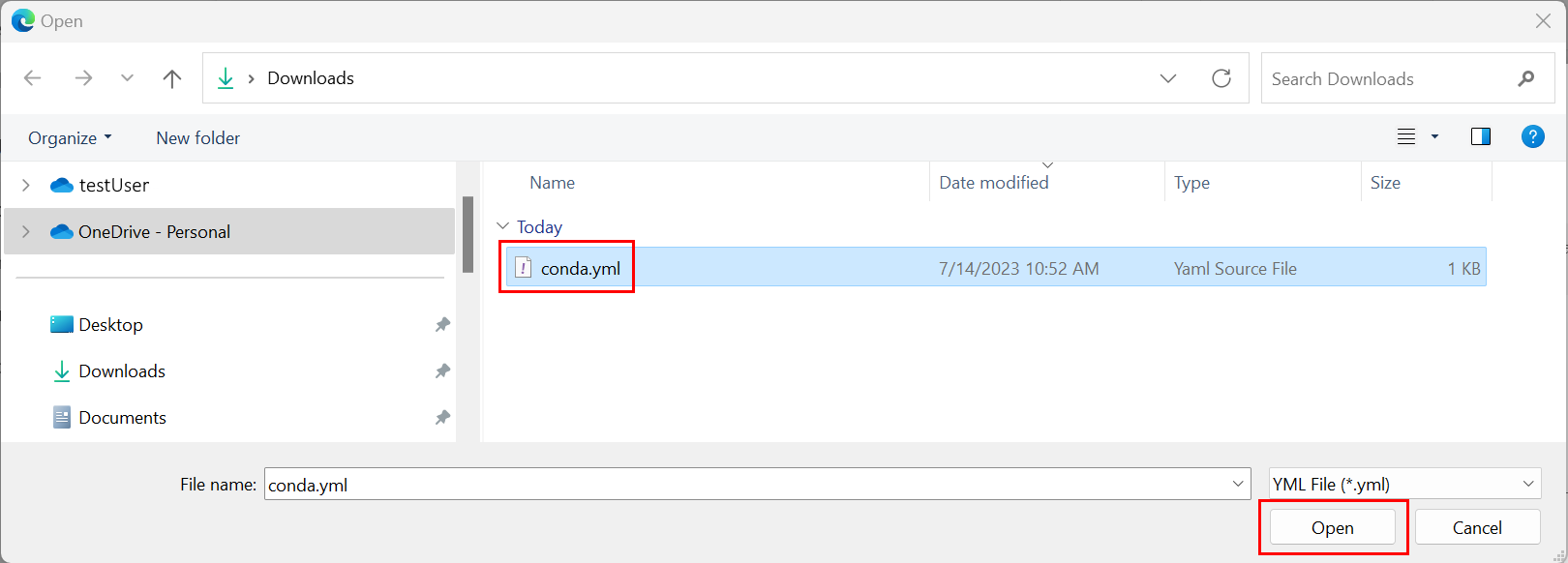
Selezionare Applica.






Avviare la sessione Spark
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Configurare la directory radice per gli esempi
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Configurare l'interfaccia della riga di comando
Non applicabile.
Nota
Usare un archivio delle funzionalità per riutilizzare le funzionalità tra i progetti. Usare un'area di lavoro del progetto (un'area di lavoro di Azure Machine Learning) per eseguire il training dei modelli di inferenza sfruttando le funzionalità degli archivi delle funzionalità. Molte aree di lavoro del progetto possono condividere e riutilizzare lo stesso archivio delle funzionalità.
Questa esercitazione usa due SDK:
SDK CRUD per l'archivio delle funzionalità
Si usa lo stesso SDK
MLClient(nome del pacchettoazure-ai-ml) usato con l'area di lavoro di Azure Machine Learning. Un archivio delle funzionalità viene implementato come tipo di area di lavoro. Di conseguenza, questo SDK viene usato per le operazioni CRUD per gli archivi delle funzionalità, i set di funzionalità e le entità degli archivi delle funzionalità.SDK principale per l'archivio delle funzionalità
Questo SDK (
azureml-featurestore) è destinato allo sviluppo e all'utilizzo dei set di funzionalità. I passaggi successivi di questa esercitazione descrivono queste operazioni:- Sviluppare una specifica del set di funzionalità.
- Recuperare i dati delle funzionalità.
- Elencare o ottenere un set di funzionalità registrato.
- Generare e risolvere le specifiche di recupero delle funzionalità.
- Generare dati di training e inferenza usando join temporizzati.
Questa esercitazione non richiede l'installazione esplicita di tali SDK, perché questo passaggio è previsto nelle istruzioni precedenti sul file conda.yml.
Creare un archivio delle funzionalità minimo
Impostare i parametri dell'archivio delle funzionalità, inclusi il nome, la posizione e altri valori.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Creare l'archivio delle funzionalità.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Inizializzare un client SDK principale per l'archivio delle funzionalità per Azure Machine Learning.
Come illustrato in precedenza in questa esercitazione, il client SDK principale per l'archivio funzionalità viene usato per lo sviluppo e l'utilizzo di funzionalità.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Concedere il ruolo "Data scientist di Azure Machine Learning" per l'archivio delle funzionalità all'identità utente. Ottenere il valore dell'ID oggetto Microsoft Entra dal portale di Azure, come descritto in Trovare l'ID oggetto utente.
Assegnare il ruolo Data scientist di AzureML all'identità utente, in modo che possa creare risorse nell'area di lavoro dell'archivio delle funzionalità. La propagazione delle autorizzazioni potrebbe richiedere del tempo.
Per altre informazioni sul controllo di accesso, vedere Gestire il controllo di accesso per archivio delle funzionalità gestite risorsa.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Prototipare e sviluppare un set di funzionalità
In questi passaggi viene creato un set di funzionalità denominato transactions con funzionalità basate sull'aggregazione di finestre mobili:
Esplorare i dati di origine di
transactions.Questo notebook usa dati di esempio ospitati in un contenitore BLOB accessibile pubblicamente. Può essere letto in Spark solo tramite un driver
wasbs. Quando si creano set di funzionalità usando i propri dati di origine, ospitarli in un account Azure Data Lake Storage Gen2 e usare un driverabfssnel percorso dati.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueSviluppare il set di funzionalità in locale.
Una specifica del set di funzionalità è una definizione autonoma che è possibile sviluppare e testare in locale. A questo punto, creare queste funzionalità di aggregazione di finestre mobili:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Esaminare il file di codice di trasformazione delle funzionalità: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Si noti l'aggregazione mobile definita per le funzionalità. Si tratta di un trasformatore Spark.
Per altre informazioni sul set di funzionalità e sulle trasformazioni, visitare la risorsa Che cos'è archivio delle funzionalità gestite?
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Esportare come specifica del set di funzionalità.
Per registrare la specifica del set di funzionalità con l'archivio delle funzionalità, è necessario salvare tale specifica in un formato particolare.
Esaminare la specifica del set di funzionalità
transactionsgenerata. Aprire questo file dall'albero dei file per visualizzare la specifica featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml .La specifica contiene questi elementi:
source: un riferimento a una risorsa di archiviazione. In questo caso, si tratta di un file parquet in una risorsa di archiviazione BLOB.features: un elenco delle funzionalità e dei relativi tipi di dati. Se si fornisce il codice di trasformazione, tale codice deve restituire un dataframe mappato alle funzionalità e ai tipi di dati.index_columns: le chiavi di join necessarie per accedere ai valori del set di funzionalità.
Per altre informazioni sulla specifica, vedere Informazioni sulle entità di primo livello nelle risorse dello schema YAML archivio delle funzionalità gestite e dell'interfaccia della riga di comando (v2).
La persistenza della specifica del set di funzionalità offre un altro vantaggio: la specifica del set di funzionalità supporta il controllo del codice sorgente.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Registrare un'entità dell'archivio delle funzionalità
Come procedura consigliata, le entità consentono di applicare l'uso della stessa definizione di chiave di join, in set di funzionalità che usano le stesse entità logiche. Gli esempi di entità includono account e clienti. Le entità vengono in genere create una sola volta e quindi riutilizzate tra set di funzionalità. Per altre informazioni, vedere Informazioni sulle entità di primo livello in archivio delle funzionalità gestite.
Inizializzare il client CRUD per l'archivio delle funzionalità.
Come illustrato in precedenza in questa esercitazione,
MLClientviene usato per creare, leggere, aggiornare ed eliminare un asset dell'archivio funzionalità. L'esempio di cella di codice del notebook illustrato qui cerca l'archivio delle funzionalità creato in un passaggio precedente. In questo caso non è possibile riutilizzare lo stessoml_clientvalore usato in precedenza in questa esercitazione, perché tale valore è limitato a livello di gruppo di risorse. La definizione corretta dell'ambito è un prerequisito per la creazione dell'archivio delle funzionalità.In questo esempio di codice l'ambito del client è a livello di archivio delle funzionalità.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registrare l'entità
accountcon l'archivio delle funzionalità.Creare un'entità
accountcon la chiave di joinaccountIDdi tipostring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Registrare il set di funzionalità transaction con l'archivio delle funzionalità
Usare questo codice per registrare un asset del set di funzionalità caricato con l'archivio delle funzionalità. È quindi possibile riutilizzare tale asset e condividerlo facilmente. La registrazione di un asset del set di funzionalità offre funzionalità gestite, tra cui il controllo delle versioni e la materializzazione. I passaggi successivi di questa serie di esercitazioni illustrano le funzionalità gestite.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Esplorare l'interfaccia utente dell'archivio delle funzionalità
La creazione e gli aggiornamenti degli asset dell'archivio delle funzionalità possono essere eseguiti solo tramite l'SDK e l'interfaccia della riga di comando. È possibile usare l'interfaccia utente per eseguire ricerche o per esplorare l'archivio delle funzionalità:
- Aprire la pagina di destinazione globale di Azure Machine Learning.
- Selezionare Archivi delle funzionalità nel riquadro sinistro.
- Nell'elenco degli archivi delle funzionalità accessibili selezionare quello creato in precedenza in questa esercitazione.
Concedere al Ruolo con autorizzazioni di lettura per i dati dei BLOB di archiviazione l'accesso al proprio account utente nell'archivio offline
Il Ruolo con autorizzazioni di lettura per i dati dei BLOB di archiviazione deve essere assegnato al proprio account utente nell'archivio offline. Ciò garantisce che l'account utente possa leggere i dati delle funzionalità materializzati dall'archivio di materializzazione offline.
Ottenere il valore dell'ID oggetto Microsoft Entra dal portale di Azure, come descritto in Trovare l'ID oggetto utente.
Ottenere informazioni sull'archivio di materializzazione offline nella pagina Panoramica dell'interfaccia utente dell'archivio delle funzionalità. È possibile trovare l'ID sottoscrizione dell'account di archiviazione, il nome del gruppo di risorse dell'account di archiviazione e il nome dell'account di archiviazione per l'archivio di materializzazione offline nella scheda Archivio di materializzazione offline.
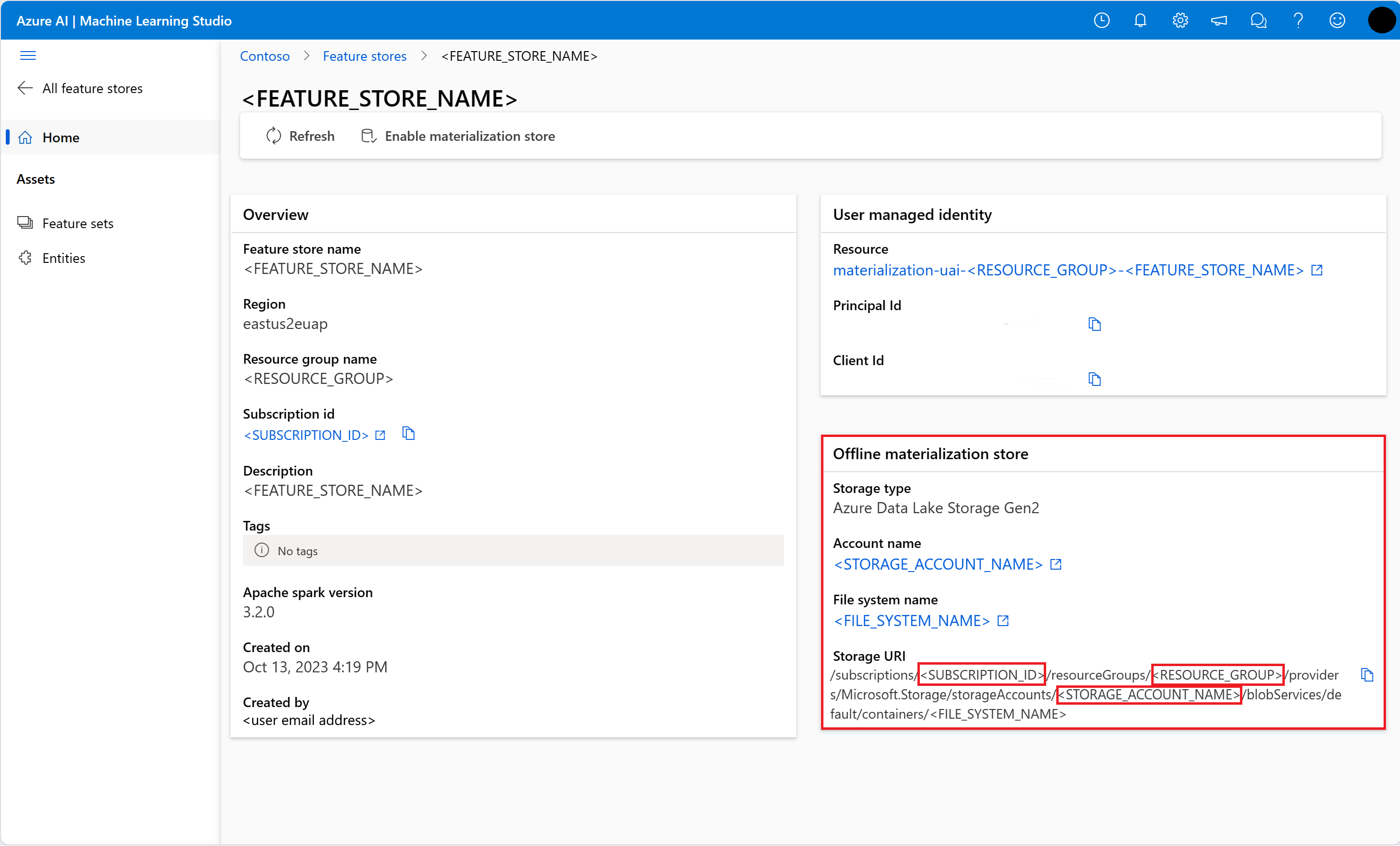
Per altre informazioni sul controllo di accesso, vedere Gestire il controllo di accesso per archivio delle funzionalità gestite risorsa.
Eseguire questa cella di codice per l'assegnazione di ruolo. La propagazione delle autorizzazioni potrebbe richiedere del tempo.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Generare un dataframe dei dati di training usando il set di funzionalità registrato
Caricare i dati di osservazione.
I dati di osservazione in genere contengono i dati principali usati per il training e l'inferenza. Questi dati vengono aggiunti ai dati delle funzionalità per creare la risorsa dati di training completa.
I dati di osservazione vengono acquisiti durante l'evento stesso. In questo caso, includono i dati delle transazioni principali, tra cui i valori di ID transazione, ID account e importo transazione. Poiché vengono usati per il training, includono anche una variabile di destinazione aggiunta (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueOttenere il set di funzionalità registrato ed elencare le relative funzionalità.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Selezionare le funzionalità che diventano parte dei dati di training. Usare quindi l'SDK dell'archivio delle funzionalità per generare i dati di training stessi.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueUn join temporizzato aggiunge le funzionalità ai dati di training.
Abilitare la materializzazione offline nel set di funzionalità transactions
Dopo aver abilitato la materializzazione del set di funzionalità, è possibile eseguire un back-fill. È anche possibile pianificare processi di materializzazione ricorrenti. Per altre informazioni, vedere la terza esercitazione nella risorsa serie .
Impostare spark.sql.shuffle.partitions nel file yaml in base alle dimensioni dei dati delle funzionalità
La configurazione Spark spark.sql.shuffle.partitions è un parametro FACOLTATIVO che può influire sul numero di file Parquet generati (al giorno) quando il set di funzionalità viene materializzato nell'archivio offline. Il valore predefinito di questo parametro è 200. Come procedura consigliata, evitare di generare molti file Parquet di piccole dimensioni. Se il recupero delle funzionalità offline diventa lento dopo la materializzazione del set di funzionalità, passare alla cartella corrispondente nell'archivio offline per verificare se il problema riguarda un numero eccessivo di file Parquet di piccole dimensioni (al giorno) e modificare il valore di questo parametro di conseguenza.
Nota
I dati di esempio usati in questo notebook sono di piccole dimensioni. Pertanto, questo parametro è impostato su 1 nel file featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())È possibile salvare l'asset del set di funzionalità come risorsa YAML.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Back-fill dei dati per il set di funzionalità transactions
Come illustrato in precedenza, la materializzazione calcola i valori delle funzionalità per una finestra delle funzionalità e archivia questi valori calcolati in un archivio di materializzazione. La materializzazione delle funzionalità aumenta l'affidabilità e la disponibilità dei valori calcolati. Tutte le query sulle funzionalità ora usano i valori dell'archivio di materializzazione. Questo passaggio esegue un back-fill una tantum per una finestra di funzionalità di 18 mesi.
Nota
Potrebbe essere necessario determinare un valore per la finestra dei dati di back-fill. La finestra deve corrispondere alla finestra dei dati di training. Ad esempio, per usare 18 mesi di dati per il training, è necessario recuperare le funzionalità per 18 mesi. Ciò significa che è necessario eseguire il back-fill per una finestra di 18 mesi.
Questa cella di codice materializza i dati in base allo stato corrente Nessuno o Incompleto per la finestra di funzionalità definita.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Suggerimento
- La colonna
timestampdeve seguire il formatoyyyy-MM-ddTHH:mm:ss.fffZ. - La granularità di
feature_window_start_timeefeature_window_end_timeè limitata ai secondi. Gli eventuali millisecondi specificati nell'oggettodatetimeverranno ignorati. - Un processo di materializzazione verrà inviato solo se nella finestra delle funzionalità sono presenti dati corrispondenti a
data_status, definito durante l'invio del processo di back-fill.
Stampare i dati di esempio del set di funzionalità. Le informazioni di output mostrano che i dati sono stati recuperati dall'archivio di materializzazione. Il metodo get_offline_features() ha recuperato i dati di training e inferenza. Usa anche l'archivio di materializzazione per impostazione predefinita.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Esplorare ulteriormente la materializzazione delle funzionalità offline
È possibile esplorare lo stato di materializzazione delle funzionalità per un set di funzionalità nell'interfaccia utente dei processi di materializzazione.
Aprire la pagina di destinazione globale di Azure Machine Learning.
Selezionare Archivi delle funzionalità nel riquadro sinistro.
Nell'elenco degli archivi delle funzionalità accessibili selezionare quello per cui è stato eseguito il back-fill.
Selezionare la scheda Processi di materializzazione.
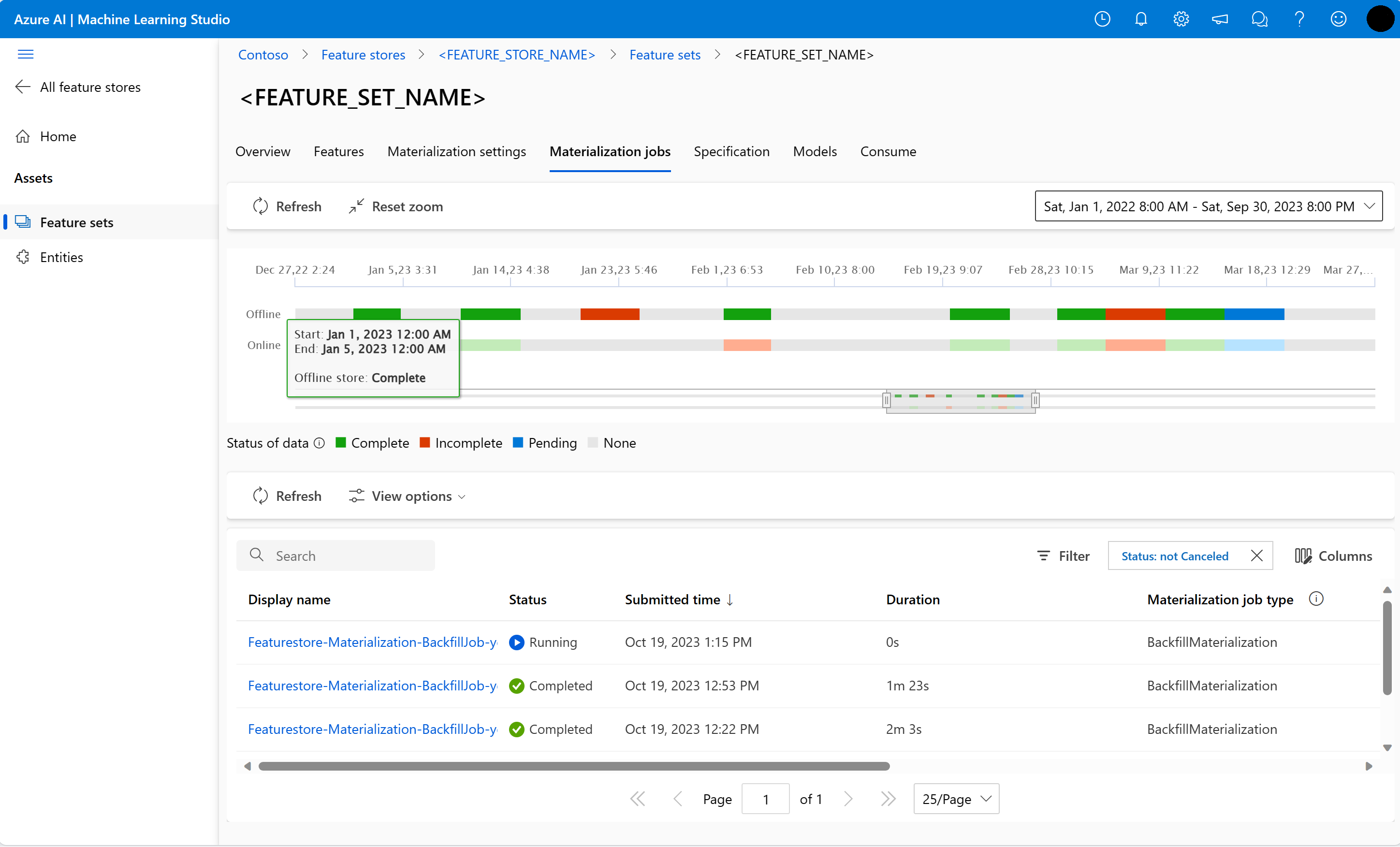

Lo stato di materializzazione dei dati può essere
- Completo (verde)
- Incompleto (rosso)
- In sospeso (blu)
- Nessuno (grigio)
Un intervallo di dati rappresenta una parte contigua di dati con lo stesso stato di materializzazione. Ad esempio, lo snapshot precedente ha 16 intervalli di dati nell'archivio di materializzazione offline.
I dati possono avere un massimo di 2.000 intervalli di dati. Se i dati contengono più di 2.000 intervalli di dati, creare una nuova versione del set di funzionalità.
È possibile fornire un elenco di più stati dei dati (ad esempio,
["None", "Incomplete"]) in un singolo processo di back-fill.Durante il back-fill, viene inviato un nuovo processo di materializzazione per ogni intervallo di dati che rientra nella finestra di funzionalità definita.
Se un processo di materializzazione è in sospeso o se è in esecuzione per un intervallo di dati per cui non è stato ancora eseguito il back-fill, per tale intervallo di dati non viene inviato un nuovo processo.
È possibile riprovare a eseguire un processo di materializzazione non riuscito.
Nota
Per ottenere l'ID di un processo di materializzazione non riuscito:
- Passare all'interfaccia utente dei processi di materializzazione del set di funzionalità.
- Selezionare il nome visualizzato di un processo specifico con Stato Non riuscito.
- Individuare l'ID processo nella proprietà Nome disponibile nella pagina Panoramica del processo. Inizia con
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Aggiornamento dell'archivio di materializzazione offline
- Se un archivio di materializzazione offline deve essere aggiornato a livello di archivio delle funzionalità, tutti i set di funzionalità nell'archivio delle funzionalità devono avere la materializzazione offline disabilitata.
- Se la materializzazione offline è disabilitata in un set di funzionalità, lo stato di materializzazione dei dati già materializzati nell'archivio di materializzazione offline viene reimpostato. La reimpostazione rende inutilizzabili i dati già materializzati. È necessario inviare di nuovo i processi di materializzazione dopo aver abilitato la materializzazione offline.
In questa esercitazione sono stati creati i dati di training con le funzionalità dell'archivio delle funzionalità, è stata abilitata la materializzazione per l'archivio delle funzionalità offline ed è stato eseguito un back-fill. Successivamente, si eseguirà il training del modello usando queste funzionalità.
Eseguire la pulizia
La quinta esercitazione della serie descrive come eliminare le risorse.
Passaggi successivi
- Vedere l'esercitazione successiva della serie: Sperimentare ed eseguire il training dei modelli usando le funzionalità.
- Vedere informazioni sui concetti relativi all'archivio delle funzionalità e sulle entità di primo livello nell'archivio delle funzionalità gestite.
- Vedere informazioni sull'identità e sul controllo di accesso per l'archivio delle funzionalità gestite.
- Visualizzare la guida alla risoluzione dei problemi per l'archivio delle funzionalità gestite.
- Visualizzare il riferimento YAML.