Ottimizzare i prompt usando varianti
La creazione di un buon prompt è un compito impegnativo che richiede creatività, chiarezza e pertinenza. Un buon prompt consente di ottenere l'output desiderato da un modello linguistico già sottoposto a training, mentre un prompt scadente può causare output non accurati, irrilevanti o senza senso. È quindi necessario ottimizzare i prompt per migliorare le prestazioni e l'affidabilità per attività e domini diversi.
A questo scopo viene introdotto il concetto di varianti, utili per testare il comportamento del modello in condizioni diverse, ad esempio con opzioni differenti di formattazione, contesto, temperatura o top-k, nonché per confrontare e trovare il prompt e la configurazione migliori che offrono accuratezza, diversità o coerenza del modello ottimali.
Questo articolo illustra come usare le varianti per ottimizzare i prompt e valutare le prestazioni di varianti diverse.
Prerequisiti
Prima di leggere questo articolo, vedere:
Come ottimizzare i prompt usando varianti?
In questo articolo verrà usato il flusso di esempio di classificazione Web.
Per prima cosa, aprire il flusso di esempio e rimuovere il nodo prepare_examples.
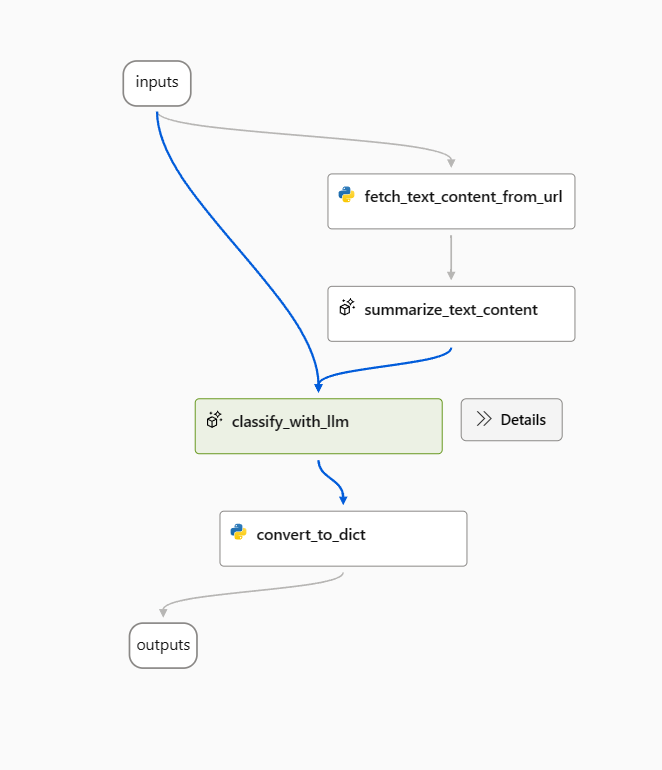
Usare il prompt seguente come prompt di base nel nodo classify_with_llm.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
È possibile ottimizzare questo flusso in più modi e di seguito sono illustrate due opzioni:
Per il nodo classify_with_llm usare il prompt seguente: Ho scoperto dalla community e da alcuni paper che una temperatura più bassa fornisce una maggiore precisione, ma meno creatività e sorpresa, quindi una temperatura più bassa è adatta per i compiti di classificazione e anche un prompt di pochi tentativi può aumentare le prestazioni di LLM. Vorrei quindi verificare come si comporta il mio flusso quando la temperatura passa da 1 a 0 e quando il prompt viene effettuato con pochi esempi.
Per il nodo summarize_text_content usare il prompt seguente: Voglio anche testare il comportamento del mio flusso quando cambio il sommario da 100 a 300 parole, per vedere se un maggior contenuto testuale può contribuire a migliorare le prestazioni.
Creare varianti
- Selezionare il pulsante Mostra varianti nell'angolo in alto a destra del nodo LLM. Il nodo LLM esistente è variant_0 ed è la variante predefinita.
- Selezionare il pulsante Clona per variant_0 per generare variant_1 e quindi configurare i parametri usando valori diversi o aggiornare il prompt in variant_1.
- Ripetere il passaggio per creare altre varianti.
- Selezionare Nascondi varianti per interrompere l'aggiunta di varianti. Tutte le varianti sono visualizzate in modo ridotto. Per il nodo viene visualizzata la variante predefinita.
Per il nodo classify_with_llm basato su variant_0:
- Creare variant_1 in cui la temperatura viene modificata da 1 a 0.
- Creare variant_2 in cui la temperatura è 0 ed è possibile usare il prompt seguente, inclusi alcuni esempi.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
Per il nodo summarize_text_content basato su variant_0 è possibile creare variant_1 modificando 100 words in 300 nel prompt.
Il flusso avrà ora l'aspetto seguente: 2 varianti per il nodo summarize_text_content e 3 per il nodo classify_with_llm.

Eseguire tutte le varianti con una singola riga di dati e controllare gli output
Per assicurarsi che tutte le varianti possano essere eseguite correttamente e funzionino come previsto, è possibile eseguire il flusso con una singola riga di dati da testare.
Nota
Ogni volta è possibile selezionare un solo nodo LLM con varianti da eseguire, mentre altri nodi LLM useranno la variante predefinita.
In questo esempio vengono configurate varianti sia per il nodo summarize_text_content che per il nodo classify_with_llm, quindi è necessario ripetere l'esecuzione due volte per testare tutte le varianti.
- Selezionare il pulsante Esegui in alto a destra.
- Selezionare un nodo LLM con varianti. Gli altri nodi LLM useranno la variante predefinita.
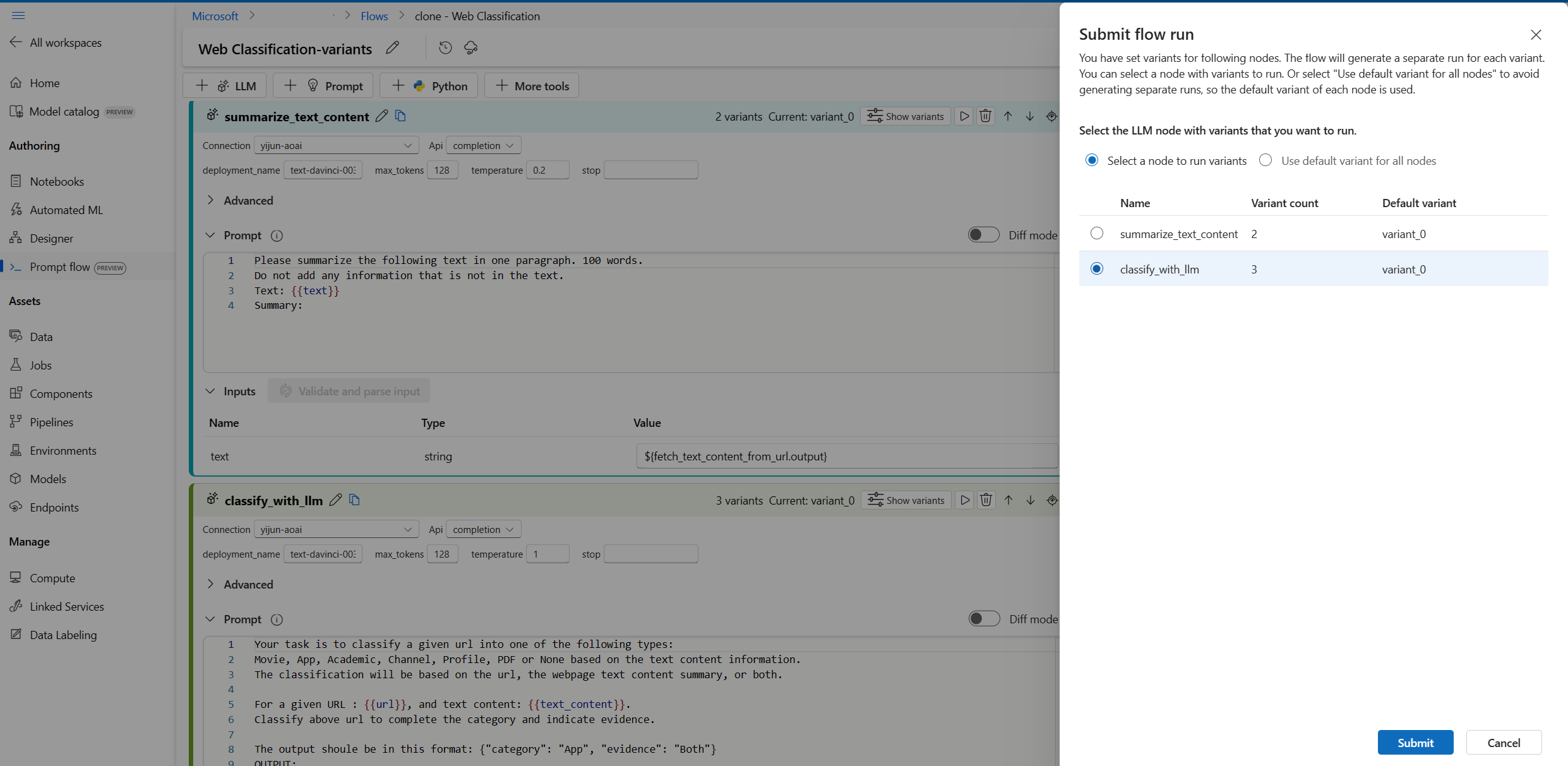
- Inviare l'esecuzione del flusso.
- Al termine dell'esecuzione del flusso, è possibile controllare il risultato corrispondente per ogni variante.
- Inviare un'altra esecuzione del flusso con l'altro nodo LLM con varianti e controllare gli output.
- È possibile modificare altri dati di input (ad esempio, usare un URL di pagina di Wikipedia) e ripetere i passaggi precedenti per testare le varianti con dati diversi.

Valutare le varianti
Quando si eseguono le varianti con pochi dati e si controllano i risultati, non è possibile riflettere la complessità e la diversità dei dati del mondo reale. L'output inoltre non è misurabile, quindi è difficile confrontare l'efficacia delle diverse varianti e scegliere la migliore.
È possibile inviare un'esecuzione batch, che consente di testare le varianti con una grande quantità di dati e valutarle con le metriche, per trovare la soluzione più adatta.
Prima di tutto, è necessario preparare un set di dati che sia sufficientemente rappresentativo del problema reale che si vuole risolvere con il prompt flow. In questo esempio si tratta di un elenco di URL con i relativi dati reali di riferimento per la classificazione. Le prestazioni delle varianti verranno valutate in base all'accuratezza.
Selezionare Valuta in alto a destra nella pagina.
Verrà eseguita una procedura guidata di esecuzione e valutazione batch. Il primo passaggio consiste nel selezionare un nodo per eseguire tutte le relative varianti.
Per testare il funzionamento delle diverse varianti per ogni nodo in un flusso, è necessario avviare un'esecuzione batch per ogni nodo con varianti, una per volta. Ciò consente di evitare l'influenza delle varianti di altri nodi e di concentrarsi sui risultati delle varianti del nodo da valutare. Viene seguita la regola dell'esperimento controllato, ovvero viene modificato un solo elemento alla volta, mantenendo identico tutto il resto.
È ad esempio possibile selezionare il nodo classify_with_llm per eseguire tutte le varianti e il nodo summarize_text_content userà la variante predefinita per l'esecuzione batch.
Successivamente, in Impostazioni esecuzione batch è possibile impostare il nome dell'esecuzione batch, scegliere un runtime e caricare i dati preparati.
In Impostazioni di valutazione selezionare quindi un metodo di valutazione.
Poiché il flusso è destinato alla classificazione, è possibile selezionare il metodo di valutazione dell'accuratezza della classificazione per valutare l'accuratezza.
L'accuratezza viene calcolata confrontando le etichette previste assegnate dal flusso (stima) con le etichette effettive dei dati (dati reali di riferimento) e conteggiando il numero di corrispondenze.
Nella sezione Mapping input di valutazione è necessario specificare che i dati reali di riferimento provengono dalla colonna relativa alla categoria del set di dati di input e la stima proviene dalla colonna relativa alla categoria di uno degli output del flusso.
Dopo avere esaminato tutte le impostazioni, è possibile inviare l'esecuzione batch.
Dopo l'invio dell'esecuzione, selezionare il collegamento e passare alla pagina dei dettagli dell'esecuzione.
Nota
Il completamento dell'esecuzione può richiedere alcuni minuti.
Visualizzare gli output
- Al termine dell'esecuzione batch e dell'esecuzione di valutazione, nella pagina dei dettagli dell'esecuzione selezionare più esecuzioni batch per ogni variante e quindi scegliere Visualizza output. Verranno visualizzate le metriche di tre varianti per il nodo classify_with_llm e gli output di stima per il nodo LLM per ogni record di dati.
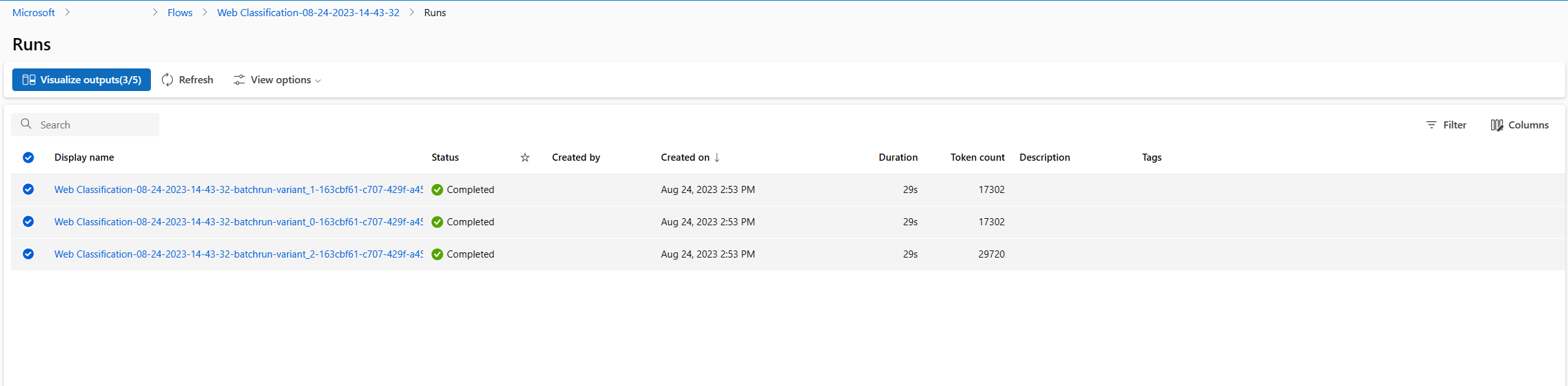
- Dopo avere identificato la variante migliore, è possibile tornare alla pagina di creazione del flusso e impostare tale variante come predefinita per il nodo
- È possibile ripetere i passaggi precedenti per valutare anche le varianti del nodo summarize_text_content.
Il processo di ottimizzazione dei prompt tramite le varianti è ora completato. È possibile applicare questa tecnica al prompt flow personalizzato per trovare la variante migliore per il nodo LLM.