Linee guida per la risoluzione dei problemi
Questo articolo tratta alcune domande frequenti relative all'utilizzo del prompt flow.
Problemi correlati alla creazione di flussi
L'errore "Strumento pacchetto non trovato" si verifica quando si aggiorna il flusso per un'esperienza code-first
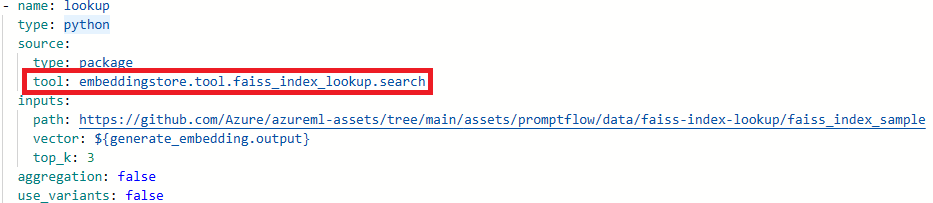
Quando si aggiornano i flussi per un'esperienza code-first, se il flusso ha utilizzato gli strumenti Ricerca nell'indice Faiss, Strumento di ricerca indice vettoriale, Ricerca database vettoriale o Sicurezza dei contenuti (testo), è possibile che venga visualizzato il messaggio di errore seguente:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Per risolvere il problema sono disponibili due opzioni:
Opzione 1
Aggiornare la sessione di calcolo alla versione più recente dell'immagine di base.
Selezionare Modalità file non elaborati per passare alla visualizzazione codice non elaborato. Aprire quindi il file flow.dag.yaml.

Aggiornare i nomi degli strumenti.
Tool Nome del nuovo strumento Ricerca nell'indice Faiss promptflow_vectordb.tool.faiss_index_lookup.FaissIndexLookup.search Strumento di ricerca indice vettoriale promptflow_vectordb.tool.vector_index_lookup.VectorIndexLookup.search Ricerca database vettoriale promptflow_vectordb.tool.vector_db_lookup.VectorDBLookup.search Sicurezza dei contenuti (testo) content_safety_text.tools.content_safety_text_tool.analyze_text Salvare il file flow.dag.yaml.
Opzione 2
- Aggiornare la sessione di calcolo alla versione più recente dell'immagine di base
- Rimuovere lo strumento precedente e ricreare un nuovo strumento.
Errore "Il file non esiste"
Il prompt flow si basa su un archivio di condivisione file per archiviare uno snapshot del flusso. Se l'archiviazione della condivisione file presenta un problema, è possibile che si verifichi il problema seguente. Ecco alcune soluzioni alternative che è possibile provare:
Se è in uso un account di archiviazione privato, vedere Isolamento della rete nel prompt flow per assicurarsi che l'area di lavoro possa accedere all'account di archiviazione.
Se l'account di archiviazione è abilitato per l'accesso pubblico, verificare se nell'area di lavoro è presente un archivio dati denominato
workspaceworkingdirectory. Deve essere un tipo di condivisione file.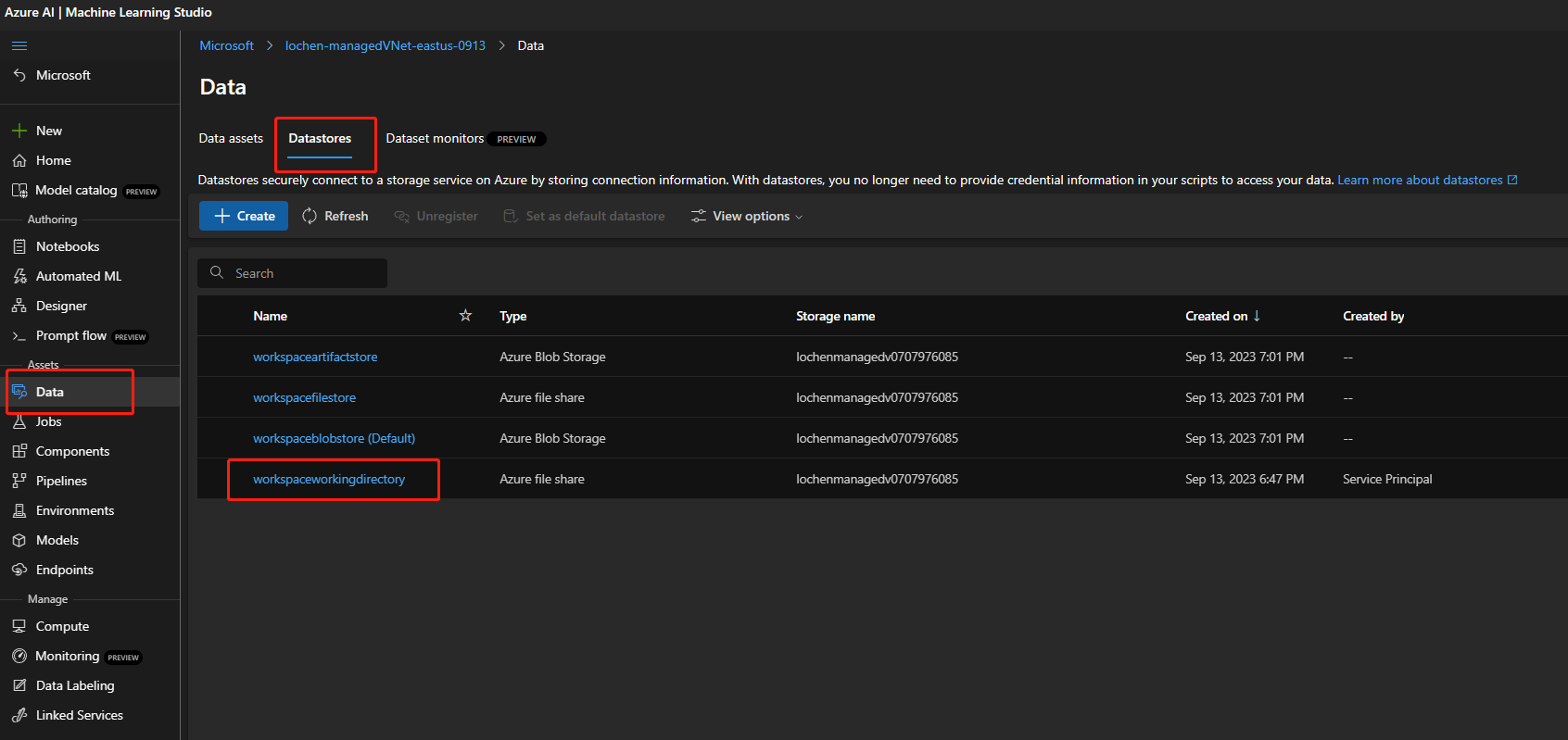
- Se non è stato recuperato questo archivio dati, è necessario aggiungerlo nell'area di lavoro.
- Creare una condivisione file denominata
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Creare un archivio dati denominato
workspaceworkingdirectory. Vedere Creare datastore.
- Creare una condivisione file denominata
- Se si dispone di un archivio dati
workspaceworkingdirectoryma il relativo tipo èblobanzichéfileshare, creare una nuova area di lavoro. Usare l'archiviazione che non abilita gli spazi dei nomi gerarchici per Azure Data Lake Storage Gen2 come account di archiviazione predefinito dell'area di lavoro. Per altre informazioni, consultare Creare un'area di lavoro.
- Se non è stato recuperato questo archivio dati, è necessario aggiungerlo nell'area di lavoro.

Flusso mancante

Le cause del problema possono essere:
Se l'accesso pubblico all'account di archiviazione è disabilitato, è necessario garantirlo aggiungendo l'indirizzo IP al firewall di archiviazione o abilitando l'accesso tramite una rete virtuale con un endpoint privato connesso all'account di archiviazione.
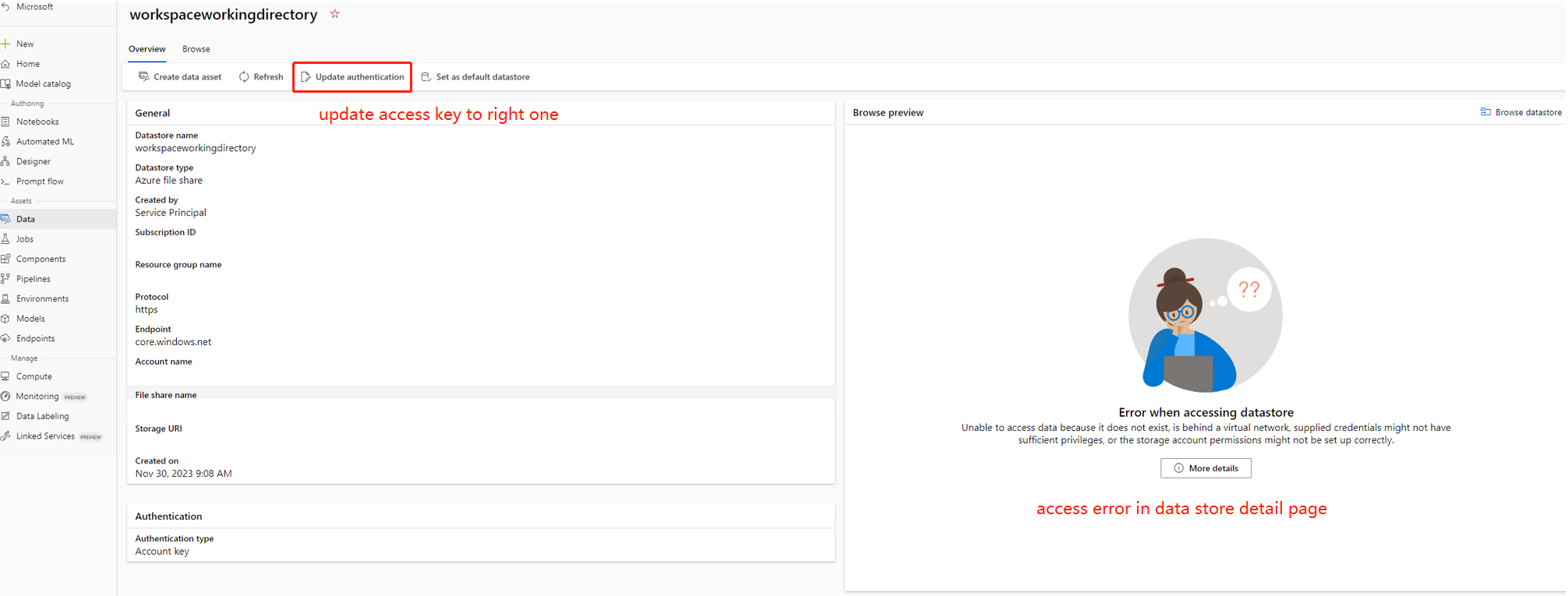
In alcuni casi, la chiave dell'account nell'archivio dati non è sincronizzata con l'account di archiviazione, è possibile provare ad aggiornare la chiave dell'account nella pagina dei dettagli dell'archivio dati per risolvere il problema.
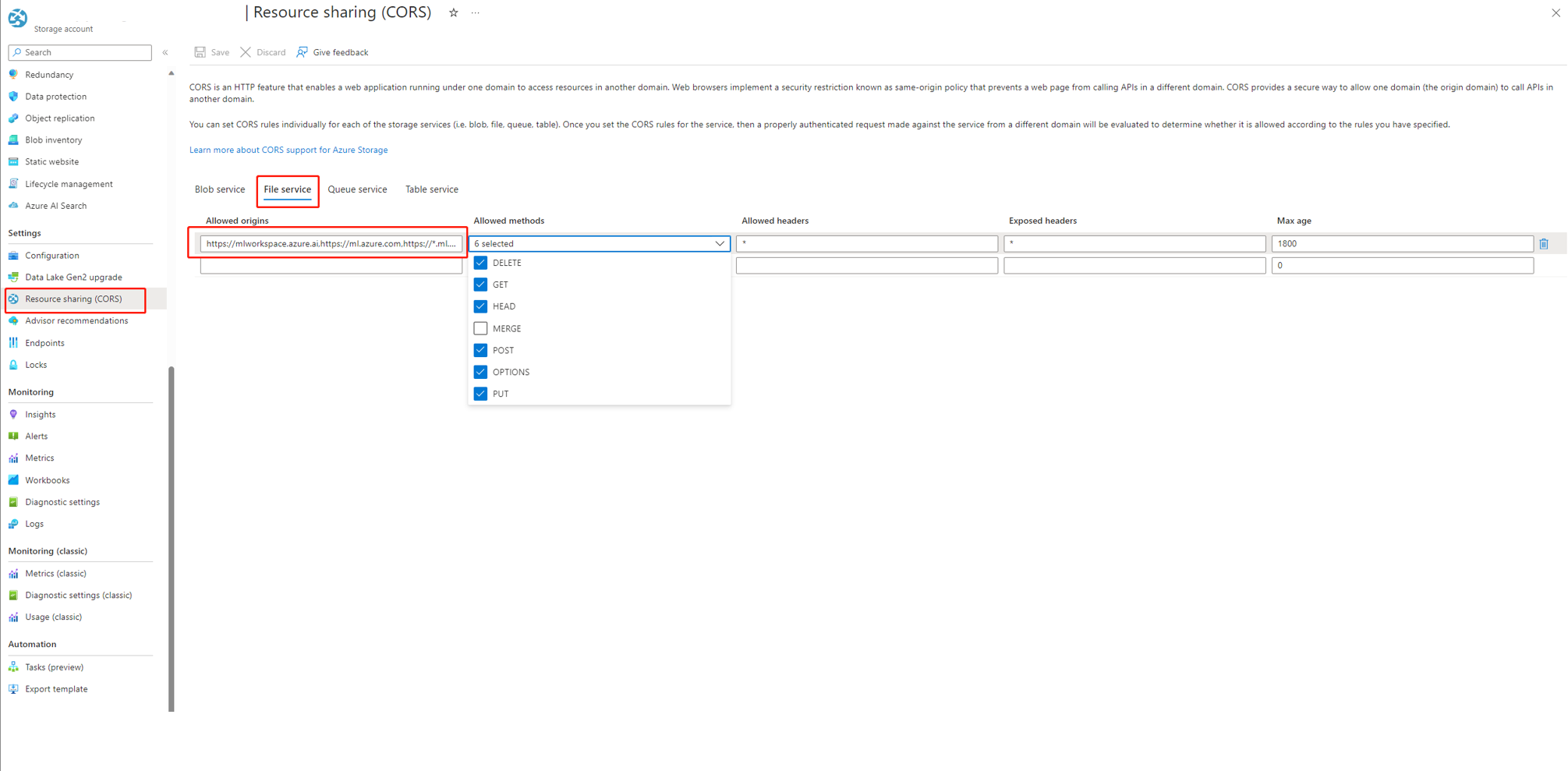
Se si usa Azure AI Foundry, l'account di archiviazione deve impostare CORS per consentire ad Azure AI Foundry di accedere all'account di archiviazione. In caso contrario, viene visualizzato il problema relativo al flusso mancante. Per risolvere questo problema, è possibile aggiungere le impostazioni CORS seguenti all'account di archiviazione.
- Passare alla pagina dell'account di archiviazione, selezionare
Resource sharing (CORS)insettingse selezionare la schedaFile service. - Origini consentite:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Metodi consentiti:
DELETE, GET, HEAD, POST, OPTIONS, PUT
- Passare alla pagina dell'account di archiviazione, selezionare



Problemi correlati alla sessione di calcolo
Esecuzione non riuscita a causa di "Nessun modulo denominato XXX"
Questo tipo di errore correlato alla sessione di calcolo non include pacchetti necessari. Se è in uso un ambiente predefinito, assicurarsi che l'immagine della sessione di calcolo usi la versione più recente. Se è in uso un'immagine di base personalizzata, assicurarsi di aver installato tutti i pacchetti necessari nel contesto Docker. Per altre informazioni, vedere Personalizzare l'immagine di base per la sessione di calcolo.
Dove trovare l'istanza serverless usata dalla sessione di calcolo?
È possibile visualizzare l'istanza serverless usata dalla sessione di calcolo nella scheda con l'elenco delle sessioni di calcolo nella pagina di calcolo. Altre informazioni su come gestire l'istanza serverless.
Errori della sessione di calcolo quando si usa un'immagine di base personalizzata
Errore di avvio della sessione di calcolo con immagine di base personalizzata o requirements.txt
Supporto della sessione di calcolo per usare requirements.txt o un'immagine di base personalizzata in flow.dag.yaml per personalizzare l'immagine. Per i casi comuni è consigliabile usare requirements.txt, che userà pip install -r requirements.txt per installare i pacchetti. Se si hanno dipendenze di più pacchetti Python, è necessario seguire Personalizzare l'immagine di base per creare una nuova base di immagini sopra l'immagine di base del prompt flow. Usarlo quindi in flow.dag.yaml. Altre informazioni su come specificare l'immagine di base nella sessione di calcolo.
- Non è possibile usare un'immagine di base arbitraria per creare una sessione di calcolo, è necessario usare l'immagine di base specificata dal flusso di richiesta.
- Non aggiungere le versioni di
promptflowepromptflow-toolsinrequirements.txt, perché sono già incluse nell'immagine di base. L'uso delle versioni precedenti dipromptflowepromptflow-toolspuò causare un comportamento imprevisto.
Problemi correlati all'esecuzione del flusso
Come trovare gli input e gli output non elaborati dello strumento LLM per ulteriori indagini?
Nel prompt flow, nella pagina del flusso con la pagina di esecuzione corretta ed esecuzione dettagli, è possibile trovare gli input e gli output non elaborati dello strumento LLM nella sezione Output. Selezionare il pulsante view full output per visualizzare l'output completo.

La sezione Trace include ogni richiesta e risposta allo strumento LLM. È possibile controllare il messaggio non elaborato inviato al modello LLM e la risposta non elaborata del modello LLM.

Come correggere l'errore 409 di Azure OpenAI?
È possibile che si verifichi un errore 409 di Azure OpenAI; questo significa che è stato raggiunto il limite di frequenza di Azure OpenAI. È possibile controllare il messaggio di errore nella sezione Output del nodo LLM. Altre informazioni sul limite di frequenza di Azure OpenAI.

Identificare il nodo che utilizza più tempo
Controllare i log delle sessioni di calcolo.
Provare a trovare il formato di log degli avvisi seguente:
{node_name} è in esecuzione da {duration} secondi.
Ad esempio:
Caso 1: il nodo dello script Python è eseguito da molto tempo.

In questo caso si potrebbe scoprire che
PythonScriptNodeera in esecuzione da molto tempo (quasi 300 secondi). È quindi possibile controllare i dettagli del nodo per scoprire qual è il problema.Caso 2: il nodo LLM è eseguito da molto tempo.
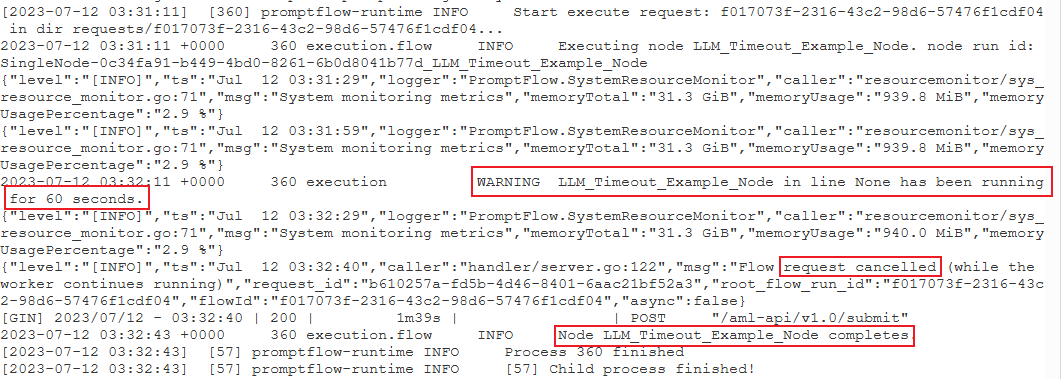
In questo caso, se si trova il messaggio
request cancelednei log, potrebbe essere perché la chiamata API OpenAI sta impiegando molto tempo e sta superando il limite di timeout.Un timeout dell'API OpenAI può essere causato da un problema di rete o da una richiesta complessa che richiede più tempo di elaborazione. Per altre informazioni, vedere Timeout dell'API OpenAI.
Attendere alcuni secondi, quindi riprovare la richiesta. Generalmente questa azione risolve gli eventuali problemi di rete.
Se i nuovi tentativi non funzionano, verificare se è in uso un modello di contesto lungo, ad esempio
gpt-4-32k, ed è stato impostato un valore elevato permax_tokens. In tal caso, il comportamento è previsto perché la richiesta potrebbe generare una risposta lunga che richiede più tempo rispetto alla soglia superiore della modalità interattiva. In questo caso, è consigliabile provareBulk testperché questa modalità non ha un'impostazione di timeout.
Se non è possibile trovare alcun elemento nei log per indicare che si tratta di un problema specifico del nodo:
- Contattare il team del prompt flow (promptflow-eng) con i log. Si tenta di identificare la causa radice.


Problemi relativi alla distribuzione del flusso
Non si dispone dell'autorizzazione a eseguire l'azione "Microsoft.MachineLearningService/workspaces/datastores/read"
Se il flusso contiene lo strumento Ricerca indice, dopo la distribuzione del flusso l'endpoint deve accedere all'archivio dati dell'area di lavoro per leggere il file YAML MLIndex o la cartella FAISS contenente blocchi e incorporamenti. È quindi necessario concedere manualmente l'autorizzazione a farlo all'identità dell'endpoint.
È possibile concedere l'identità dell'endpoint AzureML Data Scientist nell'ambito dell'area di lavoro o un ruolo personalizzato contenente l'azione "MachineLearningService/workspace/datastore/reader".
Problema di timeout della richiesta upstream durante l'utilizzo dell'endpoint
Se si usa l'interfaccia della riga di comando o l'SDK per distribuire il flusso, è possibile che si verifichi un errore di timeout. Per impostazione predefinita, il valore di request_timeout_ms è 5000. È possibile specificare un massimo di 5 minuti, ovvero 300.000 ms. Di seguito è riportato un esempio che illustra come specificare il timeout della richiesta nel file YAML della distribuzione. Per altre informazioni, vedere Schema di distribuzione.
request_settings:
request_timeout_ms: 300000
Errore di autenticazione dell'API OpenAI
Se si rigenera la chiave OpenAI di Azure e si aggiorna manualmente la connessione usata nel prompt flow, è possibile che vengano visualizzati errori come "Non autorizzato. Token di accesso mancante o non valido, i destinatari non sono corretti o sono scaduti" quando si richiama un endpoint esistente creato prima della rigenerazione della chiave.
Questo è dovuto al fatto che le connessioni usate negli endpoint/nelle distribuzioni non verranno aggiornate automaticamente. Le eventuali modifiche per la chiave o i segreti nelle distribuzioni devono essere eseguite tramite aggiornamento manuale, che mira a evitare di influire sulla distribuzione di produzione online a causa di un'operazione offline involontaria.
- Se l'endpoint è stato distribuito nell'interfaccia utente di Studio, è sufficiente ridistribuire il flusso all'endpoint esistente usando lo stesso nome di distribuzione.
- Se l'endpoint è stato distribuito usando l'SDK o l'interfaccia della riga di comando, è necessario apportare alcune modifiche alla definizione di distribuzione, ad esempio l'aggiunta di una variabile di ambiente fittizia, e quindi usare
az ml online-deployment updateper aggiornare la distribuzione.
Problemi di vulnerabilità nelle distribuzioni del prompt flow
Per le vulnerabilità correlate al runtime del prompt flow, sono possibili gli approcci seguenti, che consentono di attenuare i problemi:
- Aggiornare i pacchetti di dipendenza in requirements.txt nella cartella del flusso.
- Se è in uso un'immagine di base personalizzata per il flusso, è necessario aggiornare il runtime del prompt flow alla versione più recente e ricompilare l'immagine di base, quindi ridistribuire il flusso.
Per eventuali altre vulnerabilità delle distribuzioni online gestite, Azure Machine Learning risolve i problemi con cadenza mensile.
"Errore MissingDriverProgram" o "Impossibile trovare il programma driver nella richiesta"
Se si distribuisce il flusso e si verifica l'errore seguente, potrebbe essere correlato all'ambiente di distribuzione.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Esistono due modi per risolvere l'errore.
(Scelta consigliata) È possibile trovare l'URI dell'immagine del contenitore nella pagina dei dettagli dell'ambiente personalizzato e impostarlo come immagine di base del flusso nel file flow.dag.yaml. Quando si distribuisce il flusso nell'interfaccia utente, è sufficiente selezionare Usare l'ambiente della definizione del flusso corrente e il servizio back-end creerà l'ambiente personalizzato in base a questa immagine di base e al file
requirement.txtper la distribuzione. Altre informazioni sull'ambiente specificato nella definizione del flusso.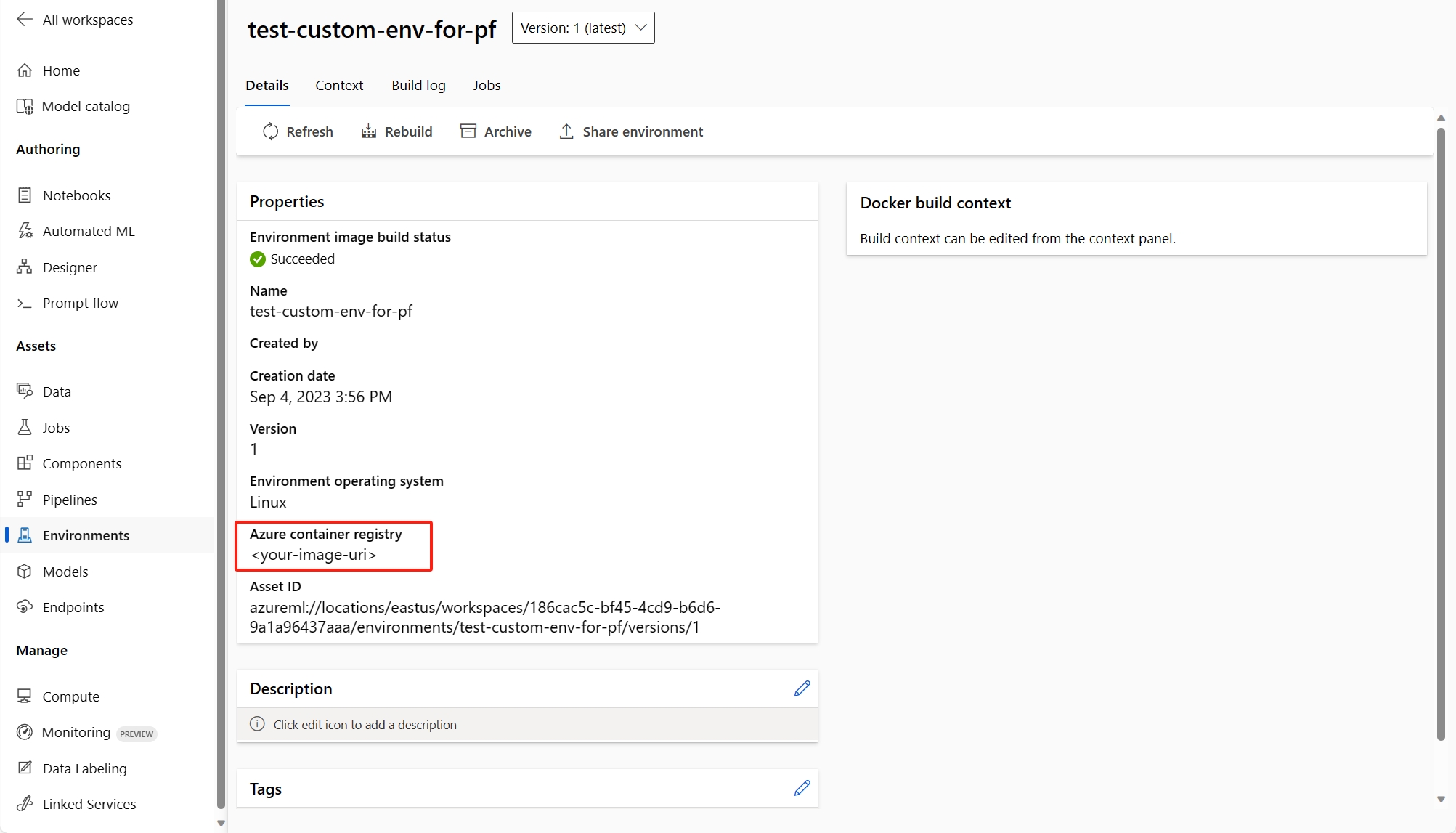
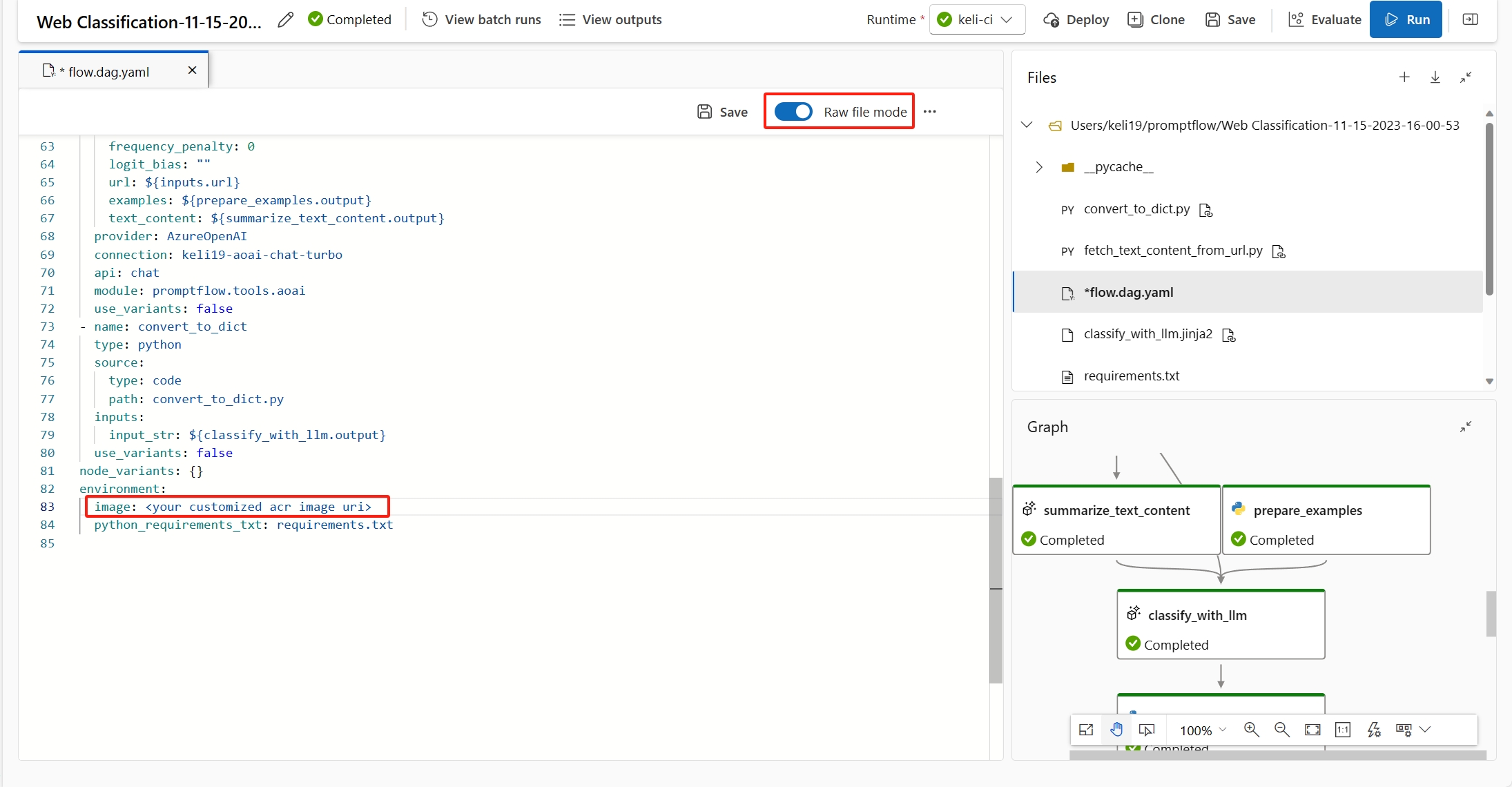
È possibile correggere questo errore aggiungendo
inference_confignella definizione dell'ambiente personalizzato.Di seguito è riportato un esempio di definizione di un ambiente personalizzato.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
La risposta del modello richiede troppo tempo
In alcuni casi, si può notare che la distribuzione richiede troppo tempo per rispondere. Ci sono diversi fattori potenziali che possono causare questo problema.
- Il modello usato nel flusso non è abbastanza potente (ad esempio: usare GPT 3.5 anziché text-ada)
- La query dell'indice non è ottimizzata e sta richiedendo troppo tempo
- Il flusso ha molti passaggi da elaborare
Provare a ottimizzare l'endpoint con le considerazioni precedenti per migliorare le prestazioni del modello.
Impossibile recuperare lo schema di distribuzione
Dopo aver distribuito l'endpoint e averlo testato nella scheda Test della pagina dei dettagli dell'endpoint, se la scheda Test mostra Non è possibile recuperare lo schema di distribuzione, è possibile provare i due metodi seguenti per attenuare il problema:

- Assicurarsi di avere concesso l'autorizzazione corretta all'identità dell'endpoint. Altre informazioni su come concedere l'autorizzazione all'identità dell'endpoint.
- Il problema potrebbe essere dovuto al fatto che il flusso è stato eseguito in una versione del runtime meno recente e quindi è stato distribuito. Anche la distribuzione ha usato l'ambiente del runtime con la versione meno recente. Per aggiornare il runtime, seguire Aggiornare un runtime dell'interfaccia utente e ripetere il flusso nel runtime più recente, quindi distribuire di nuovo il flusso.
Accesso negato all'elenco dei segreti dell'area di lavoro
Se si verifica un errore simile ad "Accesso negato all'elenco dei segreti dell'area di lavoro", verificare se è stata concessa l'autorizzazione corretta all'identità dell'endpoint. Altre informazioni su come concedere l'autorizzazione all'identità dell'endpoint.
Problemi relativi all'autenticazione e all'identità
Come usare l'archivio dati senza credenziali nel flusso immediato?
Per usare l'archiviazione senza credenziali nel portale di Azure AI Foundry, è necessario eseguire fondamentalmente le operazioni seguenti:
- Modificare il tipo di autenticazione dell'archivio dati in Nessuno.
- Concedere all'identità del servizio gestito del progetto e all'utente l'autorizzazione collaboratore ai dati blob/file per l'archiviazione.
Modificare il tipo di autenticazione dell'archivio dati in Nessuno
È possibile seguire l'autenticazione dei dati basata su identità questa parte per rendere le credenziali dell'archivio dati senza credenziali.
È necessario modificare il tipo di autenticazione dell'archivio dati in Nessuno, che è l'acronimo di meid_token'autenticazione basata su . È possibile apportare modifiche dalla pagina dei dettagli dell'archivio dati o dall'interfaccia della riga di comando/SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

Per l'archivio dati basato su BLOB, è possibile modificare il tipo di autenticazione e abilitare l'identità del servizio gestito dell'area di lavoro per accedere all'account di archiviazione.

Per l'archivio dati basato su condivisione file, è possibile modificare solo il tipo di autenticazione.

Concedere l'autorizzazione all'identità utente o all'identità gestita
Per usare l'archivio dati senza credenziali nel flusso di richiesta, è necessario concedere autorizzazioni sufficienti all'identità utente o all'identità gestita per accedere all'archivio dati.
- Assicurarsi che l'identità gestita assegnata dal sistema dell'area di lavoro abbia
Storage Blob Data ContributoreStorage File Data Privileged Contributornell'account di archiviazione almeno sia necessaria l'autorizzazione di lettura/scrittura (meglio includere anche l'eliminazione). - Se si usa l'identità utente questa opzione predefinita nel flusso di richiesta, è necessario assicurarsi che l'identità utente abbia il ruolo seguente nell'account di archiviazione:
Storage Blob Data Contributornell'account di archiviazione, è necessaria almeno l'autorizzazione di lettura/scrittura (meglio includere anche l'eliminazione).Storage File Data Privileged Contributornell'account di archiviazione, è necessaria almeno l'autorizzazione di lettura/scrittura (meglio includere anche l'eliminazione).
- Se si usa l'identità gestita assegnata dall'utente, è necessario assicurarsi che l'identità gestita abbia il ruolo seguente nell'account di archiviazione:
Storage Blob Data Contributornell'account di archiviazione, è necessaria almeno l'autorizzazione di lettura/scrittura (meglio includere anche l'eliminazione).Storage File Data Privileged Contributornell'account di archiviazione, è necessaria almeno l'autorizzazione di lettura/scrittura (meglio includere anche l'eliminazione).- Nel frattempo, è necessario assegnare almeno il ruolo di identità
Storage Blob Data Readutente all'account di archiviazione, se si vuole usare il flusso di richiesta per la creazione e il flusso di test.
- Se non è ancora possibile visualizzare la pagina dei dettagli del flusso e la prima volta che si usa il flusso di richiesta è precedente al 2024-01-01, è necessario concedere all'identità del servizio gestito dell'area di lavoro come
Storage Table Data Contributoraccount di archiviazione collegato all'area di lavoro.