Usare processi in parallelo nelle pipeline
SI APPLICA A: Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo illustra come usare l'interfaccia della riga di comando v2 e Python SDK v2 per eseguire processi in parallelo nelle pipeline di Azure Machine Learning. I processi in parallelo accelerano l'esecuzione dei processi distribuendo attività ripetute in cluster di calcolo multinodo efficienti.
I tecnici che si occupano di apprendimento automatico hanno sempre requisiti di scalabilità per le attività di training o inferenza. Ad esempio, quando un data scientist fornisce un singolo script per eseguire il training di un modello di stima delle vendite, i tecnici che si occupano di apprendimento automatico devono applicare questa attività di training a ogni singolo archivio dati. Le problematiche poste da questo processo di scale-out includono tempi di esecuzione lunghi che causano ritardi e problemi imprevisti che richiedono l'intervento manuale per mantenere l'attività in esecuzione.
Il processo principale della parallelizzazione di Azure Machine Learning consiste nel suddividere una singola attività seriale in mini-batch e inviare tali mini batch a più ambienti di calcolo per l'esecuzione in parallelo. I processi in parallelo riducono significativamente il tempo di esecuzione end-to-end e gestiscono automaticamente gli errori. È consigliabile usare il processo in parallelo di Azure Machine Learning per eseguire il training di vari modelli sui dati partizionati o accelerare le attività di inferenza batch su larga scala.
Ad esempio, in uno scenario in cui si esegue un modello di rilevamento di oggetti in un set di immagini di grandi dimensioni, i processi in parallelo di Azure Machine Learning consentono di distribuire facilmente le immagini per eseguire codice personalizzato in parallelo in un cluster di calcolo specifico. La parallelizzazione può ridurre significativamente i tempi. L'uso del processo in parallelo di Azure Machine Learning consente inoltre di semplificare e automatizzare il processo per renderlo più efficiente.
Prerequisiti
- Avere un account e un'area di lavoro di Azure Machine Learning.
- Comprendere le pipeline di Azure Machine Learning.
- Installare l'interfaccia della riga di comando di Azure e l'estensione
ml. Per altre informazioni, vedere Installare, configurare e usare l'interfaccia della riga di comando (v2). L'estensionemlinstalla automaticamente la prima volta che si esegue un comandoaz ml. - Informazioni su come creare ed eseguire pipeline e componenti di Azure Machine Learning con l'interfaccia della riga di comando v2.
Creare ed eseguire una pipeline con un passaggio di processo in parallelo
Un processo in parallelo di Azure Machine Learning può essere usato solo come passaggio in un processo della pipeline.
Gli esempi seguenti provengono da Eseguire un processo della pipeline usando un processo in parallelo nella pipeline nel repository di esempi di Azure Machine Learning.
Prepararsi per la parallelizzazione
Questo passaggio di processo in parallelo richiede preparazione. È necessario uno script di immissione che implementa le funzioni predefinite. È anche necessario impostare gli attributi nella definizione del processo in parallelo che:
- Definire e associare i dati di input.
- Impostare il metodo di divisione dati.
- Configurare le risorse di calcolo.
- Chiamare lo script di immissione.
Le sezioni seguenti descrivono come preparare il processo in parallelo.
Dichiarare gli input e l'impostazione di divisione dati
Un processo in parallelo richiede la suddivisione e l'elaborazione di un input principale in parallelo. Il formato dei dati di input principale può essere costituito da dati tabulari o da un elenco di file.
Formati di dati diversi hanno tipi di input, modalità di input e metodi di divisione dati differenti. Nella tabella seguente vengono descritte le opzioni disponibili:
| Formato dati | Tipo di input | Modalità di input | Metodo di divisione dati |
|---|---|---|---|
| Elenco di file | mltable oppure uri_folder |
ro_mount oppure download |
In base a dimensione (numero di file) o partizione |
| Dati tabulari | mltable |
direct |
In base a dimensione (dimensione fisica stimata) o partizione |
Nota
Se si usa mltable tabulare come dati di input principali, è necessario:
- Installare la libreria
mltablenell'ambiente, come nella riga 9 di questo file conda. - Disporre di un file di specifica MLTable nel percorso specificato con la sezione
transformations: - read_delimited:compilata. Per esempi, vedere Creare e gestire asset di dati.
È possibile dichiarare i dati di input principali con l'attributo input_data nel processo in parallelo YAML o Python e associare i dati con il input definito del processo parallelo usando ${{inputs.<input name>}}. Definire quindi l'attributo di divisione dati per l'input principale a seconda del metodo di divisione dati.
| Metodo di divisione dati | Attribute name | Tipo di attributo | Esempio di processo |
|---|---|---|---|
| Per dimensioni | mini_batch_size |
string | Stima batch Iris |
| In base a partizione | partition_keys |
Elenco di stringhe | Stima delle vendite di succo d'arancia |
Configurare le risorse di calcolo per la parallelizzazione
Dopo aver definito l'attributo di divisione dati, configurare le risorse di calcolo per la parallelizzazione impostando gli attributi instance_count e max_concurrency_per_instance.
| Attribute name | Type | Descrizione | Default value |
|---|---|---|---|
instance_count |
integer | Numero di nodi da usare per il processo. | 1 |
max_concurrency_per_instance |
integer | Numero di processori in ogni nodo. | Per un calcolo GPU: 1. Per un calcolo CPU: numero di core. |
Questi attributi interagiscono con il cluster di calcolo specificato, come illustrato nel diagramma seguente:
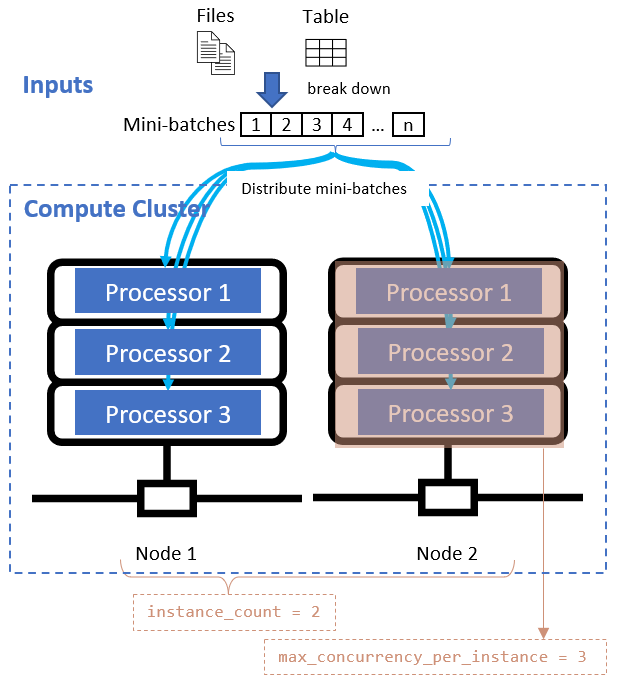
Chiamare lo script di immissione
Lo script di immissione è un singolo file Python che implementa le tre funzioni predefinite seguenti con codice personalizzato.
| Nome della funzione | Richiesto | Descrzione | Input | Restituzione |
|---|---|---|---|---|
Init() |
Y | Preparazione comune prima di iniziare a eseguire mini-batch. Ad esempio, usare questa funzione per caricare il modello in un oggetto globale. | -- | -- |
Run(mini_batch) |
Y | Implementa la logica di esecuzione principale per mini-batch. | mini_batch è il dataframe Pandas se i dati di input sono tabulari o un elenco di percorsi di file se i dati di input sono una directory. |
Dataframe, elenco o tupla. |
Shutdown() |
N | Funzione facoltativa per eseguire operazioni di pulizia personalizzate prima di calcolare il pool. | -- | -- |
Importante
Per evitare eccezioni durante l'analisi di argomenti in funzioni Init() o Run(mini_batch), usare parse_known_args anziché parse_args. Vedere l'esempio iris_score per uno script di immissione con parser di argomenti.
Importante
La funzione Run(mini_batch) richiede la restituzione di un dataframe, un elenco o una tupla. Il processo in parallelo usa il conteggio di tali elementi restituiti per misurare gli elementi con esito positivo in tale mini-batch. Il numero di mini-batch deve essere uguale al conteggio dell'elenco restituito se tutti gli elementi sono stati elaborati.
Il processo in parallelo esegue le funzioni in ogni processore, come illustrato nel diagramma seguente.
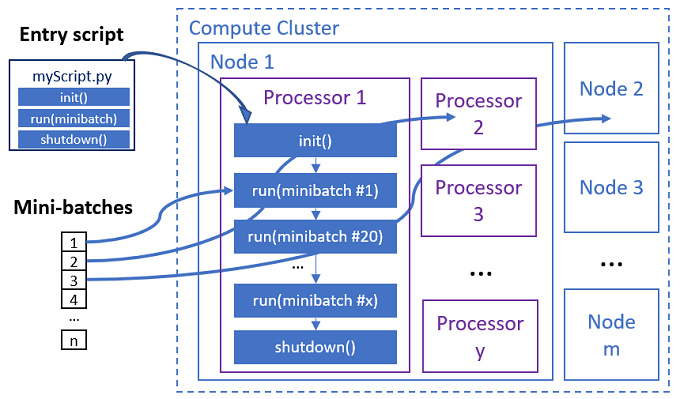
Vedere gli esempi di script di immissione seguenti:
- Identificazione immagine per un elenco di file di immagine
- Classificazione Iris per dati Iris tabulari
Per chiamare lo script di immissione, impostare i due attributi seguenti nella definizione del processo in parallelo:
| Attribute name | Type | Descrizione |
|---|---|---|
code |
stringa | Percorso locale della directory del codice sorgente da caricare e usare per il processo. |
entry_script |
string | File Python che contiene l'implementazione di funzioni parallele predefinite. |
Esempio di passaggio del processo in parallelo
Il passaggio di processo in parallelo seguente dichiara il tipo di input, la modalità e il metodo di divisione dati, associa l'input, configura il calcolo e chiama lo script di immissione.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Prendere in considerazione le impostazioni di automazione
Il processo in parallelo di Azure Machine Learning espone numerose impostazioni opzionali in grado di controllare automaticamente il processo senza intervento manuale. La tabella seguente descrive le singole impostazioni.
| Chiave | Type | Descrizione | Valori consentiti | Default value | Impostare nell'attributo o nell'argomento programma |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Numero di mini-batch non riusciti da ignorare in questo processo in parallelo. Se il numero di mini-batch non riusciti è superiore a questa soglia, il processo in parallelo è contrassegnato come non riuscito. Il mini batch viene contrassegnato come non riuscito se: - Il numero di elementi restituiti da run() è inferiore al numero di input di mini-batch.- Le eccezioni vengono rilevate nel codice personalizzato run(). |
[-1, int.max] |
-1, ovvero ignorare tutti i mini-batch non riusciti |
Attributo mini_batch_error_threshold |
mini_batch_max_retries |
integer | Numero di tentativi quando il mini-batch ha esito negativo o si verifica il timeout. Se tutti i tentativi hanno esito negativo, il mini-batch viene contrassegnato come non riuscito in base al calcolo mini_batch_error_threshold. |
[0, int.max] |
2 |
Attributo retry_settings.max_retries |
mini_batch_timeout |
integer | Timeout in secondi per l'esecuzione della funzione personalizzata run(). Se il tempo di esecuzione è superiore a questa soglia, il mini-batch verrà interrotto e contrassegnato come non riuscito per attivare nuovi tentativi. |
(0, 259200] |
60 |
Attributo retry_settings.timeout |
item_error_threshold |
integer | Soglia di elementi non riusciti. Gli elementi non riusciti vengono conteggiati in base al divario numerico tra gli input e gli elementi restituiti da ogni mini batch. Se la somma degli elementi non riusciti è superiore a questa soglia, il processo in parallelo è contrassegnato come non riuscito. | [-1, int.max] |
-1, ovvero ignorare tutti gli errori durante il processo in parallelo |
Argomento programma--error_threshold |
allowed_failed_percent |
integer | Simile a mini_batch_error_threshold, ma usa la percentuale di mini batch non riusciti anziché il conteggio. |
[0, 100] |
100 |
Argomento programma--allowed_failed_percent |
overhead_timeout |
integer | Timeout in secondi per l'inizializzazione di ogni mini-batch. Ad esempio, caricare i dati del mini batch e passarli alla funzione run(). |
(0, 259200] |
600 |
Argomento programma--task_overhead_timeout |
progress_update_timeout |
integer | Timeout in secondi per il monitoraggio dello stato di avanzamento dell'esecuzione di mini-batch. Se non vengono ricevuti aggiornamenti dello stato entro questa impostazione di timeout, il processo in parallelo viene contrassegnato come non riuscito. | (0, 259200] |
Calcolato dinamicamente da altre impostazioni | Argomento programma--progress_update_timeout |
first_task_creation_timeout |
integer | Timeout in secondi per il monitoraggio del tempo tra l'avvio del processo e l'esecuzione del primo mini-batch. | (0, 259200] |
600 |
Argomento programma--first_task_creation_timeout |
logging_level |
string | Livello di log di cui eseguire il dump nei file di log utente. | INFO, WARNING o DEBUG |
INFO |
Attributo logging_level |
append_row_to |
string | Aggregare tutti i valori restituiti da ogni esecuzione di mini-batch ed emetterli come output in questo file. Può fare riferimento a uno degli output del processo in parallelo usando l'espressione ${{outputs.<output_name>}} |
Attributo task.append_row_to |
||
copy_logs_to_parent |
string | Opzione booleana per specificare se copiare lo stato del processo, la panoramica e i log nel processo della pipeline padre. | True oppure False |
False |
Argomento programma--copy_logs_to_parent |
resource_monitor_interval |
integer | Intervallo di tempo in secondi per eseguire il dump dell'utilizzo delle risorse del nodo (ad esempio CPU o memoria) nella cartella di log nel percorso logs/sys/perf. Nota: i log delle risorse di dump frequenti rallentano leggermente la velocità di esecuzione. Impostare questo valore su 0 per interrompere il dump dell'utilizzo delle risorse. |
[0, int.max] |
600 |
Argomento programma--resource_monitor_interval |
Il codice di esempio seguente aggiorna queste impostazioni:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Creare la pipeline con il passaggio del processo in parallelo
L'esempio seguente mostra il processo della pipeline completo con il passaggio di processo in parallelo inline:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Inviare il processo della pipeline
Inviare il processo della pipeline con un passaggio parallelo usando il comando dell'interfaccia della riga di comandoaz ml job create:
az ml job create --file pipeline.yml
Controllare il passaggio parallelo nell'interfaccia utente di Studio
Dopo aver inviato un processo della pipeline, il widget dell'SDK o dell'interfaccia della riga di comando fornisce un collegamento URL Web al grafico della pipeline nell'interfaccia utente di Azure Machine Learning Studio.
Per visualizzare i risultati dei processi in parallelo, fare doppio clic sul passaggio parallelo nel grafico della pipeline, selezionare la scheda Impostazioni nel pannello dei dettagli, espandere Impostazioni esecuzione e successivamente la sezione Parallelo.

Per eseguire il debug di un errore di processo in parallelo, selezionare la scheda Output + log, espandere la cartella logs e controllare job_result.txt per stabilire il motivo per cui il processo in parallelo non è riuscito. Per informazioni sulla struttura di registrazione dei processi in parallelo, vedere readme.txt nella stessa cartella.
