Distribuire modelli per l'assegnazione dei punteggi negli endpoint batch
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Gli endpoint batch offrono un modo pratico per distribuire modelli che eseguono l'inferenza su grandi volumi di dati. Questi endpoint batch semplificano il processo di hosting dei modelli per l’assegnazione punteggi batch, in modo da potersi concentrare sull'apprendimento automatico piuttosto che sull'infrastruttura.
Usare endpoint batch per la distribuzione di modelli quando:
- Si dispone di modelli dispendiosi che richiedono più tempo per l'esecuzione dell'inferenza.
- È necessario eseguire l'inferenza su grandi quantità di dati distribuiti in più file.
- Non si dispone di requisiti di bassa latenza.
- È possibile sfruttare la parallelizzazione.
In questo articolo si usa un endpoint batch per distribuire un modello di apprendimento automatico che risolve il classico problema di riconoscimento delle cifre MNIST (Modified National Institute of Standards and Technology). Il modello distribuito, quindi, esegue l'inferenza batch su grandi quantità di dati, in questo caso file di immagine. Si comincia creando una distribuzione batch di un modello creato usando Torch. Questa distribuzione diventa quella predefinita nell'endpoint. Successivamente, si crea una seconda distribuzione di una modalità creata con TensorFlow (Keras), si testa la seconda distribuzione, quindi si imposta come distribuzione predefinita dell'endpoint.
Per seguire gli esempi di codice e i file necessari per eseguire i comandi in questo articolo in locale, vedere la sezione Clonare il repository di esempi. Gli esempi di codice e i file sono contenuti nel repository azureml-examples.
Prerequisiti
Prima di seguire la procedura descritta in questo articolo, accertarsi di disporre dei prerequisiti seguenti:
Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning. Se non se ne ha una, seguire la procedura descritta nell'articolo Come gestire le aree di lavoro per crearne una.
Per eseguire le attività seguenti, accertarsi di disporre di queste autorizzazioni nell’area di lavoro:
Per creare/gestire endpoint e distribuzioni batch: usare il ruolo Proprietario, il ruolo Collaboratore o un ruolo personalizzato che consenta
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Per creare distribuzioni ARM nel gruppo di risorse dell'area di lavoro: usare il ruolo Proprietario, il ruolo Collaboratore o un ruolo personalizzato che consenta
Microsoft.Resources/deployments/writenel gruppo di risorse in cui viene distribuita l'area di lavoro.
Per usare Azure Machine Learning, è necessario installare il software seguente:
Clonare il repository di esempi
L'esempio contenuto in questo articolo si basa sugli esempi di codice contenuti nel repository azureml-examples. Per eseguire i comandi in locale senza dover copiare o incollare il file YAML e altri file, innanzitutto clonare il repository quindi cambiare le directory nella cartella:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Preparare il sistema
Connettersi all'area di lavoro
Connettersi prima di tutto all'area di lavoro di Azure Machine Learning in cui si lavorerà.
Se le impostazioni predefinite per l'interfaccia della riga di comando di Azure non sono già state impostate, salvare le proprie impostazioni predefinite. Per evitare di passare più volte i valori per la sottoscrizione, l'area di lavoro, il gruppo di risorse e la posizione, eseguire questo codice:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Creare l'ambiente di calcolo
Gli endpoint batch vengono eseguiti in cluster di calcolo e supportano sia cluster di calcolo di Azure Machine Learning (AmlCompute) che cluster Kubernetes. I cluster sono una risorsa condivisa, quindi un solo cluster può ospitare una o più distribuzioni batch (insieme ad altri carichi di lavoro, se lo si desidera).
Creare un ambiente di calcolo denominato batch-cluster, come mostrato nel codice seguente. Modificarlo in base alle esigenze e fare riferimento all'ambiente di calcolo usando azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Nota
A questo punto, non viene addebitato alcun costo per l'ambiente di calcolo, perché il cluster rimane a 0 nodi fino a quando non viene richiamato un endpoint batch e non viene inviato un processo di assegnazione punteggi batch. Per altre informazioni sui costi di calcolo, vedere Gestire e ottimizzare i costi per AmlCompute.
Creare un endpoint batch
Un endpoint batch è un endpoint HTTPS che i client possono chiamare per attivare un processo di assegnazione punteggi batch. Un processo di assegnazione punteggi batch è un processo che assegna punteggi a più input. Una distribuzione batch è un set di risorse di calcolo che ospitano il modello che esegue l'assegnazione punteggi batch (o inferenza batch) effettiva. Un endpoint batch può avere più distribuzioni batch. Per altre informazioni sugli endpoint batch, vedere Cosa sono gli endpoint?.
Suggerimento
Una delle distribuzioni batch fungerà da distribuzione predefinita per l'endpoint. Quando viene richiamato l'endpoint, la distribuzione predefinita esegue l'assegnazione punteggi batch effettiva. Per altre informazioni su endpoint e distribuzioni, vedere endpoint batch e distribuzione batch.
Assegnare un nome all'endpoint. Il nome dell’endpoint deve essere univoco all'interno di un'area di Azure, poiché il nome è incluso nell'URI dell'endpoint. Ad esempio, può esistere solo un endpoint batch con il nome
mybatchendpointinwestus2.Inserire il nome dell'endpoint in una variabile in modo da potervi fare riferimento con facilità in un secondo momento.
ENDPOINT_NAME="mnist-batch"Configurare l'endpoint batch
Il file YAML seguente definisce un endpoint batch. È possibile usare questo file con il comando dell'interfaccia della riga di comando per la creazione di un endpoint batch.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningNella tabella seguente sono descritte le proprietà chiave dell'endpoint. Per lo schema YAML completo dell'endpoint batch, vedere Schema YAML dell'endpoint batch dell'interfaccia della riga di comando (v2).
Chiave Descrizione nameNome dell'endpoint batch. Deve essere univoco a livello di area di Azure. descriptionDescrizione dell'endpoint batch. Questa proprietà è facoltativa. tagsTag da includere nell'endpoint. Questa proprietà è facoltativa. Creare l'endpoint:
Eseguire il codice seguente per creare l'endpoint.
az ml batch-endpoint create --file endpoint.yml --name $ENDPOINT_NAME
Creare una distribuzione batch
Una distribuzione modello è un set di risorse necessarie per ospitare il modello che esegue l'inferenza. Per creare una distribuzione modello batch, sono necessari gli elementi seguenti:
- Un modello registrato nell'area di lavoro
- Il codice per assegnare punteggi al modello
- Un ambiente con le dipendenze del modello installate
- Le impostazioni dell’ambiente di calcolo e delle risorse già create
Cominciare registrando il modello da distribuire, un modello Torch per il noto problema di riconoscimento delle cifre (MNIST). Le distribuzioni batch possono distribuire solo modelli registrati nell'area di lavoro. È possibile ignorare questo passaggio se il modello da distribuire è già registrato.
Suggerimento
I modelli sono associati alla distribuzione anziché all'endpoint. Ciò implica che un singolo endpoint può gestire modelli diversi o versioni di modelli diversi nello stesso endpoint, purché vengano distribuiti in distribuzioni differenti.
MODEL_NAME='mnist-classifier-torch' az ml model create --name $MODEL_NAME --type "custom_model" --path "deployment-torch/model"Ora è il momento di creare uno script di assegnazione dei punteggi. Le distribuzioni batch richiedono uno script di assegnazione dei punteggi che indica come deve essere eseguito un determinato modello e come devono essere elaborati i dati di input. Gli endpoint batch supportano script creati in Python. In questo caso, viene distribuito un modello che legge i file di immagine che rappresentano cifre e restituisce la cifra corrispondente. Lo script di assegnazione dei punteggi è il seguente:
Nota
Per i modelli MLflow, Azure Machine Learning genera automaticamente lo script di assegnazione dei punteggi, quindi non è necessario specificarne uno. Se il modello è un modello MLflow, è possibile ignorare questo passaggio. Per altre informazioni sul funzionamento degli endpoint batch con modelli MLflow, vedere l'articolo Uso di modelli MLflow in distribuzioni batch.
Avviso
Se si distribuisce un modello di Machine Learning automatizzato (AutoML) in un endpoint batch, tenere presente che lo script di assegnazione punteggi fornito da AutoML funziona solo per gli endpoint online e non è concepito per l'esecuzione batch. Per informazioni su come creare uno script di assegnazione punteggi per una distribuzione batch, vedere Creare script di assegnazione punteggi per distribuzioni batch.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Creare un ambiente in cui verrà eseguita la distribuzione batch. L’ambiente deve includere i pacchetti
azureml-coreeazureml-dataset-runtime[fuse], necessari per gli endpoint batch, oltre a tutte le dipendenze richieste dal codice per l'esecuzione. In questo caso, le dipendenze sono state acquisite in un fileconda.yaml:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Importante
I pacchetti
azureml-coreeazureml-dataset-runtime[fuse]sono necessari per le distribuzioni batch e devono essere inclusi nelle dipendenze dell'ambiente.Specificare l'ambiente nel modo seguente:
La definizione dell'ambiente verrà inclusa nella definizione di distribuzione stessa come ambiente anonimo. Nella distribuzione verranno visualizzate le righe seguenti:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlAvviso
Gli ambienti curati non sono supportati nelle distribuzioni batch. È necessario specificare il proprio ambiente. È sempre possibile usare l'immagine di base di un ambiente curato come il proprio per semplificare il processo.
Creare una definizione della distribuzione
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoNella tabella seguente sono descritte le proprietà chiave della distribuzione batch. Per lo schema YAML completo della distribuzione batch, vedere Schema YAML della distribuzione batch dell'interfaccia della riga di comando (v2).
Chiave Descrizione nameNome della distribuzione. endpoint_nameNome dell'endpoint in cui creare la distribuzione. modelModello da usare per l'assegnazione dei punteggi batch. L'esempio definisce un modello inline usando path. Questa definizione consente il caricamento e la registrazione automatica dei file del modello con un nome e una versione generati automaticamente. Per altre opzioni, vedere lo Schema del modello. Come procedura consigliata per gli scenari di produzione, è necessario creare il modello separatamente e farvi riferimento qui. Per fare riferimento a un modello esistente, usare la sintassiazureml:<model-name>:<model-version>.code_configuration.codeDirectory locale che contiene tutto il codice sorgente Python per assegnare un punteggio al modello. code_configuration.scoring_scriptIl file Python nella directory code_configuration.code. Questo file deve avere una funzioneinit()e una funzionerun(). Usare la funzioneinit()per qualunque preparazione dispendiosa o comune, ad esempio caricare il modello in memoria.init()verrà chiamato una sola volta all'inizio del processo. Usarerun(mini_batch)per assegnare un punteggio a ogni voce; il valore dimini_batchè un elenco di percorsi di file. La funzionerun()deve restituire un DataFrame Pandas o una matrice. Ogni elemento restituito indica un'esecuzione riuscita dell'elemento di input inmini_batch. Per altre informazioni su come creare uno script di assegnazione punteggi, vedere Informazioni sullo script di assegnazione punteggi.environmentAmbiente per assegnare un punteggio al modello. L'esempio definisce un ambiente inline usando conda_fileeimage. Le dipendenze diconda_fileverranno installate sopraimage. L'ambiente verrà registrato automaticamente con un nome e una versione generati automaticamente. Per altre opzioni, vedere lo Schema dell'ambiente. Come procedura consigliata per gli scenari di produzione, è necessario creare l'ambiente separatamente e farvi riferimento qui. Per fare riferimento a un ambiente esistente, usare la sintassiazureml:<environment-name>:<environment-version>.computeAmbiente di calcolo per eseguire l'assegnazione dei punteggi batch. Nell'esempio viene usato il batch-clustercreato all'inizio, a cui viene fatto riferimento usando la sintassiazureml:<compute-name>.resources.instance_countNumero di istanze da usare per ogni processo di assegnazione dei punteggi batch. settings.max_concurrency_per_instanceIl numero massimo di esecuzioni scoring_scriptparallele per ogni istanza.settings.mini_batch_sizeIl numero di file che scoring_scriptpuò elaborare in un'unica chiamatarun().settings.output_actionModalità di organizzazione dell'output nel file di output. append_rowunirà tutti i risultati di output restituiti darun()in un unico file denominatooutput_file_name.summary_onlynon unisce i risultati dell'output e calcola soloerror_threshold.settings.output_file_nameIl nome del file di output di assegnazione punteggi batch per append_rowoutput_action.settings.retry_settings.max_retriesIl numero massimo di tentativi per scoring_scriptrun()non riuscito.settings.retry_settings.timeoutIl timeout in secondi per un scoring_scriptrun()per l'assegnazione punteggi a un mini-batch.settings.error_thresholdNumero di errori di assegnazione dei punteggi del file di input che devono essere ignorati. Se il numero di errori per l'intero input supera questo valore, il processo di assegnazione dei punteggi batch verrà terminato. L'esempio usa -1, che indica che è consentito un numero qualsiasi di errori senza terminare il processo di assegnazione dei punteggi batch.settings.logging_levellivello di dettaglio del log. I valori in ordine crescente di livello di dettaglio sono: WARNING, INFO e DEBUG. settings.environment_variablesDizionario delle coppie nome-valore della variabile di ambiente da impostare per ogni processo di assegnazione dei punteggi batch. Creare la distribuzione:
Eseguire il codice seguente per creare una distribuzione batch nell'endpoint batch e impostarla come distribuzione predefinita.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultSuggerimento
Il parametro
--set-defaultimposta la distribuzione appena creata come distribuzione predefinita dell'endpoint. È un modo pratico per creare una nuova distribuzione predefinita dell'endpoint, soprattutto per la prima creazione della distribuzione. Come procedura consigliata per gli scenari di produzione, è possibile creare una nuova distribuzione senza impostarla come predefinita. Accertarsi che la distribuzione funzioni come previsto, quindi aggiornare la distribuzione predefinita in un secondo momento. Per altre informazioni sull'implementazione di questo processo, vedere la sezione Distribuire un nuovo modello.Controllare i dettagli dell'endpoint e della distribuzione batch.
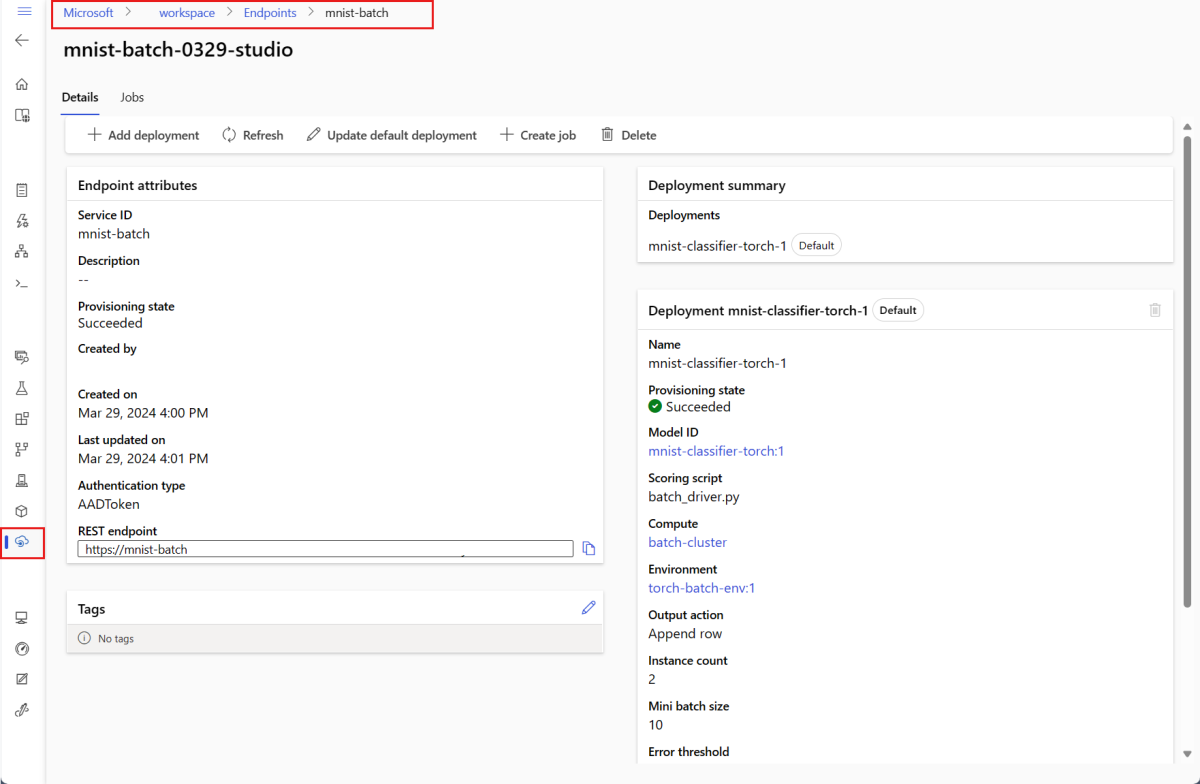
Usare
showper controllare i dettagli dell'endpoint e della distribuzione. Per controllare una distribuzione batch, eseguire il codice seguente:DEPLOYMENT_NAME="mnist-torch-dpl" az ml batch-deployment show --name $DEPLOYMENT_NAME --endpoint-name $ENDPOINT_NAME

Eseguire endpoint batch e accedere ai risultati
La chiamata di un endpoint batch attiva un processo di assegnazione dei punteggi batch. Il processo name viene restituito dalla risposta alla chiamata e può essere usato per tenere traccia dello stato di assegnazione punteggi batch. Quando si eseguono modelli per l'assegnazione punteggi in endpoint batch, è necessario specificare il percorso dei dati di input in cui gli endpoint possono trovare i dati a cui assegnare punteggi. L'esempio seguente illustra come avviare un nuovo processo su dati di esempio del set di dati MNIST archiviato in un account di archiviazione di Azure.
È possibile eseguire e richiamare un endpoint batch usando l'interfaccia della riga di comando di Azure, Azure Machine Learning SDK o gli endpoint REST. Per altri dettagli su queste opzioni, vedere Creare processi e dati di input per endpoint batch.
Nota
Come funziona la parallelizzazione?
Le distribuzioni batch distribuiscono il lavoro a livello di file, il che significa che una cartella contenente 100 file con mini batch di 10 file genererà 10 batch di 10 file ciascuno. Tenere presente che ciò avviene indipendentemente dalle dimensioni dei file coinvolti. Se i file sono troppo grandi per essere elaborati in mini-batch di grandi dimensioni, è consigliabile suddividere i file in file più piccoli per ottenere un livello di parallelismo superiore o ridurre il numero di file per mini-batch. Al momento, la distribuzione batch non può tenere conto delle differenze in una distribuzione delle dimensioni del file.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Gli endpoint batch supportano la lettura di file o cartelle che si trovano in posizioni diverse. Per altre informazioni sui tipi supportati e su come specificarli, leggere Accesso ai dati da processi di endpoint batch.
Monitorare lo stato di esecuzione del processo batch
I processi di assegnazione dei punteggi batch richiedono in genere del tempo per elaborare l'intero set di input.
Il codice seguente controlla lo stato del processo e restituisce un collegamento allo studio di Azure Machine Learning per altri dettagli.
az ml job show -n $JOB_NAME --web

Controllare i risultati dell'assegnazione dei punteggi batch
Gli output del processo vengono archiviati nell'archiviazione nel cloud, nell'archiviazione BLOB predefinita dell'area di lavoro o nell'archiviazione specificata dall'utente. Per informazioni su come modificare le impostazioni predefinite, vedere Configurare il percorso di output. La procedura seguente consente di visualizzare i risultati di assegnazione punteggi in Azure Storage Explorer una volta completato il processo:
Eseguire il codice seguente per aprire il processo di assegnazione punteggi batch in Azure Machine Learning Studio. Il collegamento allo studio del processo è incluso anche nella risposta di
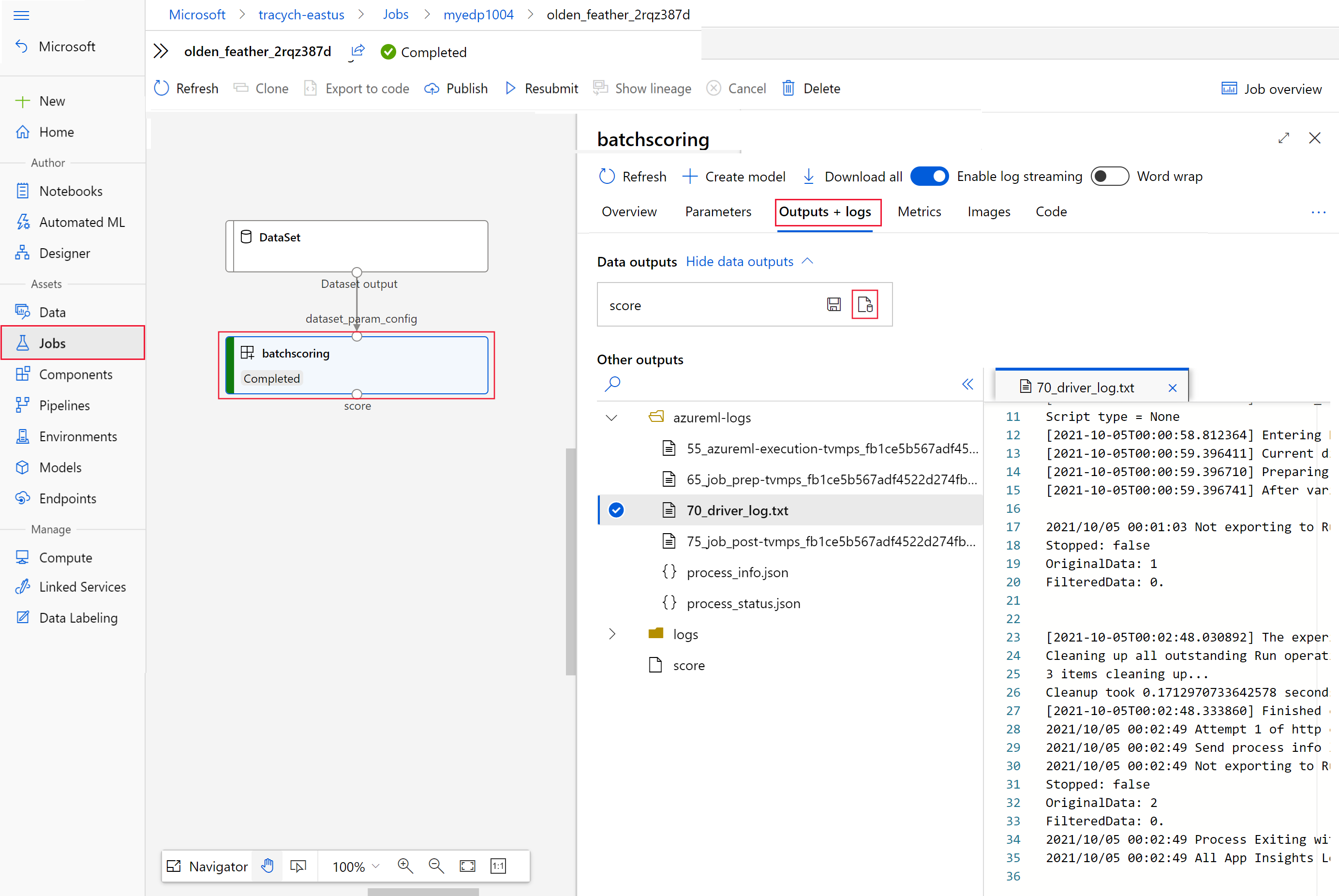
invoke, come valore diinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webNel grafico del processo selezionare il passaggio
batchscoring.Selezionare la scheda Output e log, quindi scegliere Mostra output dei dati.
In Output dei dati selezionare l'icona per aprire Storage Explorer.
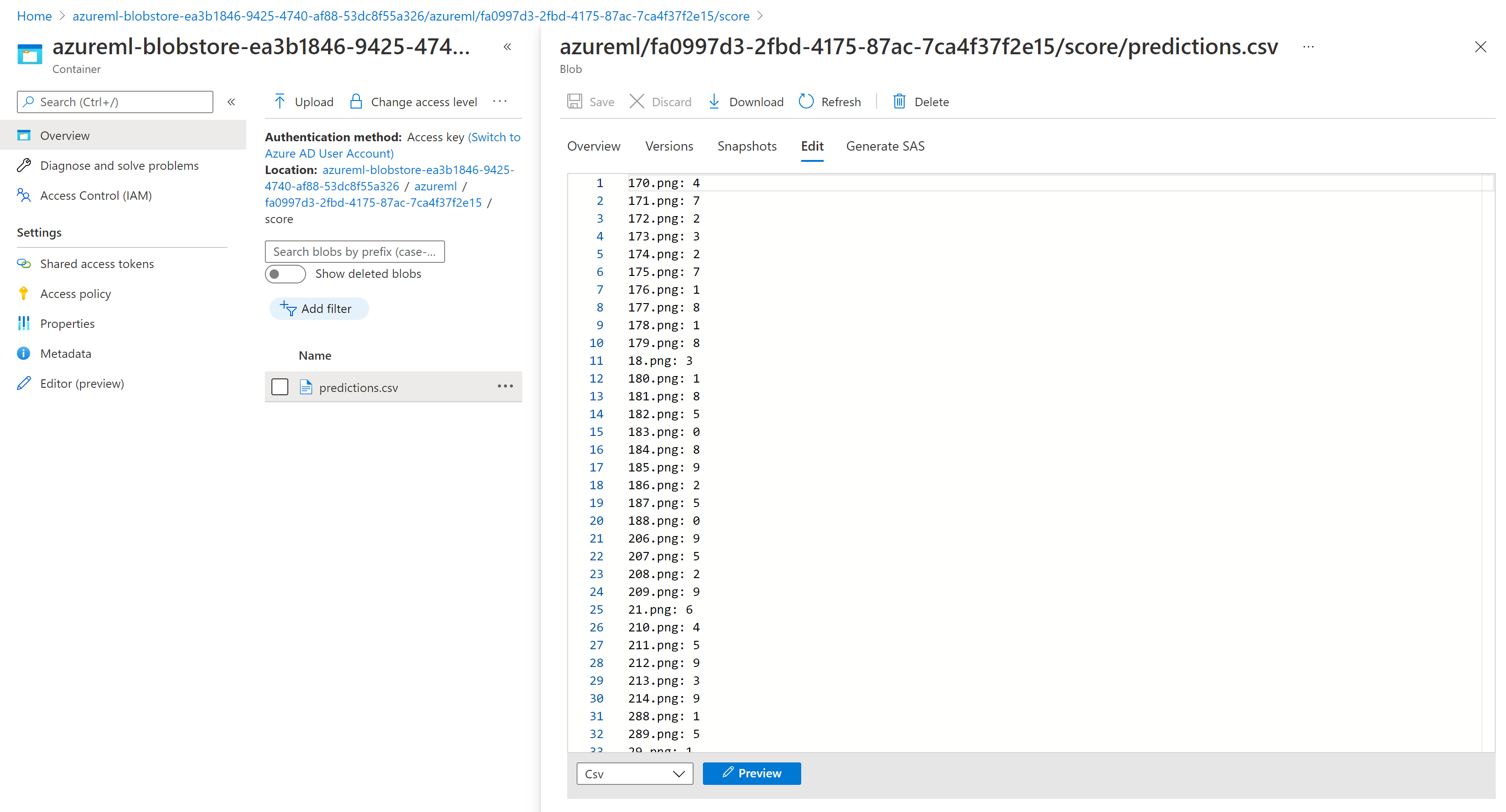
I risultati di assegnazione dei punteggi in Storage Explorer sono simili alla pagina di esempio seguente:


Configurare il percorso di output
Per impostazione predefinita, i risultati dell’assegnazione punteggi batch vengono archiviati nell'archivio BLOB predefinito dell'area di lavoro, all'interno di una cartella denominata in base al nome del processo (un GUID generato dal sistema). È possibile configurare dove archiviare gli output di assegnazione dei punteggi quando si richiama l'endpoint batch.
Usare output-path per configurare qualsiasi cartella in un archivio dati registrato di Azure Machine Learning. La sintassi per --output-path equivale a --input quando si specifica una cartella, ovvero azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Usare --set output_file_name=<your-file-name> per configurare un nuovo nome di file di output.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Avviso
È necessario usare un percorso di output univoco. Se il file di output esiste, il processo di assegnazione dei punteggi batch avrà esito negativo.
Importante
A differenza degli input, gli output possono essere archiviati solo in archivi dati di Azure Machine Learning eseguiti in account di archiviazione BLOB.
Sovrascrivere la configurazione della distribuzione per ogni processo
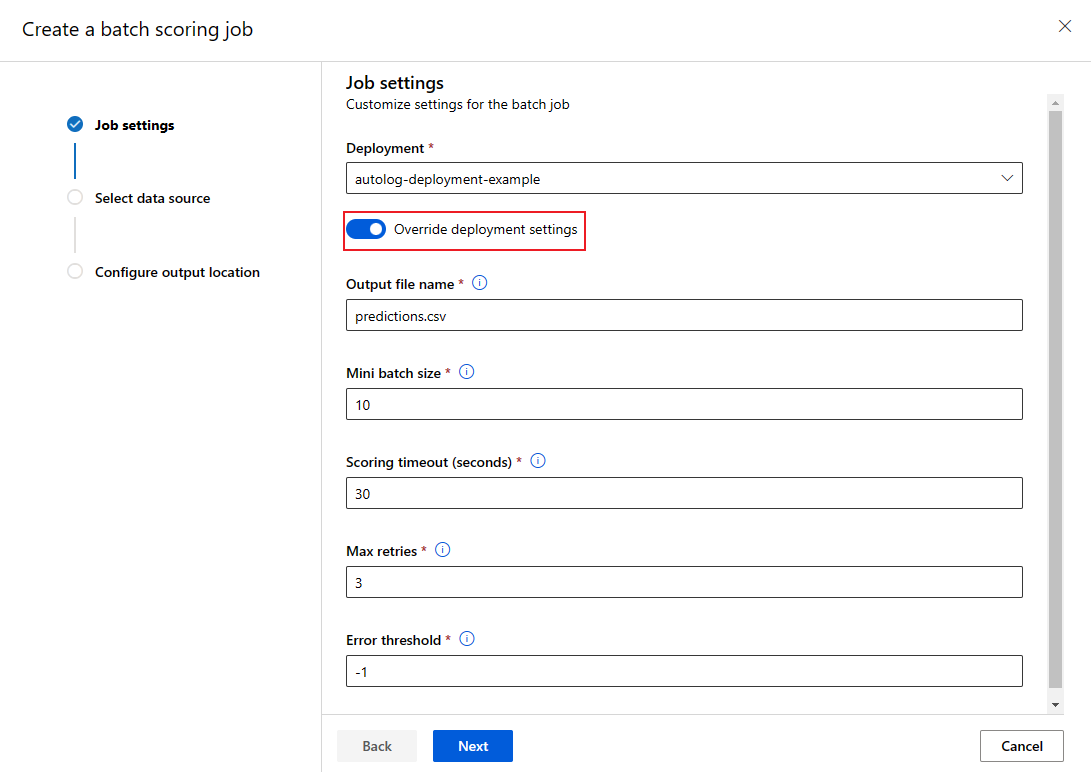
Quando si richiama un endpoint batch, alcune impostazioni possono essere sovrascritte per usare al meglio le risorse di calcolo e migliorare le prestazioni. Le impostazioni seguenti possono essere configurate in base al processo:
- Numero di istanze: usare questa impostazione per sovrascrivere il numero di istanze da richiedere al cluster di elaborazione. Ad esempio, per un volume maggiore di input di dati, è possibile usare più istanze per velocizzare l'assegnazione dei punteggi batch end-to-end.
- Dimensione mini-batch: usare questa impostazione per sovrascrivere il numero di file da includere in ogni mini-batch. Il numero di mini-batch viene deciso in base al numero totale di file di input e dalle dimensioni del mini-batch. Dimensioni più piccole del mini-batch generano più mini-batch. I mini batch possono essere eseguiti in parallelo, ma potrebbe verificarsi un sovraccarico aggiuntivo di pianificazione e di chiamata.
- È possibile sovrascrivere altre impostazioni, ad esempio Numero massimo di tentativi, Timeout e Soglia di errore. Queste impostazioni potrebbero influire sul tempo di assegnazione punteggi batch end-to-end per carichi di lavoro diversi.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Aggiungere distribuzioni a un endpoint
Dopo aver creato un endpoint batch con una distribuzione, è possibile continuare a perfezionare il modello e aggiungere nuove distribuzioni. Gli endpoint batch continueranno a gestire la distribuzione predefinita durante lo sviluppo e la distribuzione di nuovi modelli nello stesso endpoint. Le distribuzioni non possono influire l'una sull'altra.
In questo esempio, si aggiunge una seconda distribuzione che usa un modello creato con Keras e TensorFlow per risolvere lo stesso problema MNIST.
Aggiungere una seconda distribuzione
Creare un ambiente in cui verrà eseguita la distribuzione batch. Includere nell'ambiente qualsiasi dipendenza richiesta dal codice per l'esecuzione. È anche possibile aggiungere la libreria
azureml-core, perché è necessaria per il funzionamento delle distribuzioni batch. La definizione di ambiente seguente include le librerie necessarie per eseguire un modello con TensorFlow.La definizione dell'ambiente viene inclusa nella definizione della distribuzione stessa come ambiente anonimo.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlIl file conda usato è simile al seguente:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Creare uno script di assegnazione di punteggi per il modello:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Creare una definizione della distribuzione
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvCreare la distribuzione:
Eseguire il codice seguente per creare una distribuzione batch nell'endpoint batch e impostarla come distribuzione predefinita.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMESuggerimento
In questo caso manca il parametro
--set-default. Come procedura consigliata per gli scenari di produzione, creare una nuova distribuzione senza impostarla come predefinita. Quindi verificarla e aggiornare la distribuzione predefinita in un secondo momento.
Testare una distribuzione batch non predefinita
Per testare la nuova distribuzione non predefinita, è necessario conoscere il nome della distribuzione da eseguire.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Tenere presente che --deployment-name viene usato per specificare la distribuzione da eseguire. Questo parametro consente invoke per una distribuzione non predefinita senza aggiornare la distribuzione predefinita dell'endpoint batch.
Aggiornare la distribuzione batch predefinita
Anche se è possibile richiamare una distribuzione specifica all'interno di un endpoint, generalmente si desidera richiamare l'endpoint stesso e consentire all'endpoint di decidere quale distribuzione usare — la distribuzione predefinita. È possibile modificare la distribuzione predefinita, e quindi modificare il modello che gestisce la distribuzione, senza modificare il contratto con l'utente che richiama l'endpoint. Usare il codice seguente per aggiornare la distribuzione predefinita:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
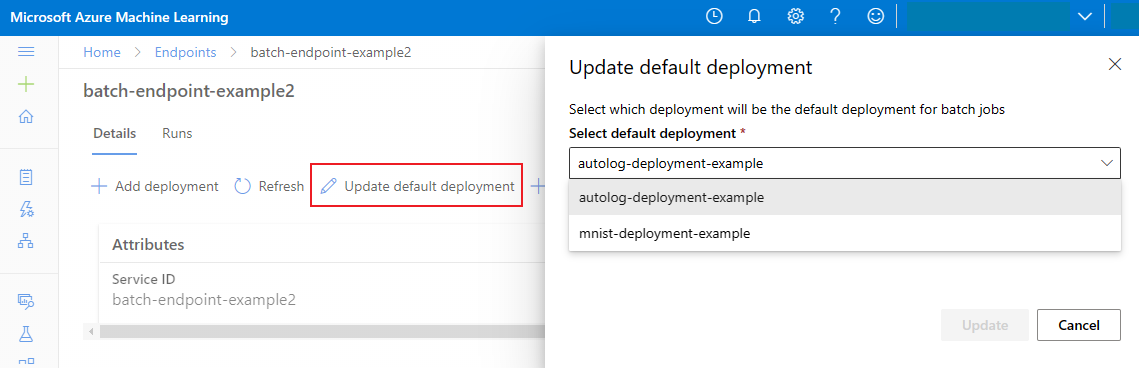
Eliminare l'endpoint e la distribuzione batch
Se la vecchia distribuzione batch non verrà utilizzata, eliminarla eseguendo il codice seguente. --yes viene usato per confermare l'eliminazione.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Eseguire il codice seguente per eliminare l'endpoint batch e tutte le distribuzioni sottostanti. I processi di assegnazione dei punteggi batch non verranno eliminati.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes