Configurare MLOps con Azure DevOps
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Azure Machine Learning consente di eseguire l'integrazione con la pipeline di Azure DevOps per automatizzare il ciclo di vita di apprendimento automatico. Alcune delle operazioni che è possibile automatizzare sono:
- Distribuzione dell'infrastruttura di Azure Machine Learning
- Preparazione dei dati (estrazione, trasformazione, operazioni di caricamento)
- Training di modelli di Machine Learning con scale-out e scale-up su richiesta
- Distribuzione di modelli di Machine Learning come servizi Web pubblici o privati
- Monitoraggio dei modelli di Machine Learning distribuiti (ad esempio per l'analisi delle prestazioni)
Questo articolo illustra come usare Azure Machine Learning per configurare una pipeline MLOps end-to-end che esegue una regressione lineare per stimare le tariffe dei taxi a NYC. La pipeline è costituita da componenti, ognuno dei quali gestisce funzioni differenti, che è possibile registrare nell'area di lavoro, eseguire il controllo delle versioni e riutilizzare con vari input e output. Si utilizzerà l'architettura di Azure consigliata per MLOps e l'acceleratore di soluzioni Azure MLOps (v2) per configurare rapidamente un progetto MLOps in Azure Machine Learning.
Suggerimento
È consigliabile comprendere alcune delle architetture di Azure consigliate per MLOps prima di implementare una soluzione. È necessario scegliere l'architettura migliore per il progetto di Machine Learning specificato.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
- Un'area di lavoro di Azure Machine Learning.
- Git in esecuzione nel computer locale.
- Un'organizzazione in Azure DevOps.
- Progetto Azure DevOps che ospiterà i repository e le pipeline di origine.
- L'estensione Terraform per Azure DevOps se si usa Azure DevOps con Terraform per creare rapidamente l'infrastruttura
Nota
È necessario Git versione 2.27 o successiva. Per altre informazioni sull'installazione del comando Git, vedere https://git-scm.com/downloads e selezionare il sistema operativo
Importante
I comandi dell'interfaccia della riga di comando in questo articolo sono stati testati usando Bash. Se si usa una shell diversa, è possibile che si verifichino errori.
Configurare l'autenticazione con Azure e DevOps
Prima di configurare un progetto MLOps con Azure Machine Learning, è necessario configurare l'autenticazione per Azure DevOps.
Creare un'entità servizio
Per l'uso della demo, è necessaria la creazione di uno o due principi di servizio, a seconda del numero di ambienti su cui si vuole lavorare (sviluppo o produzione o entrambi). Questi principi possono essere creati usando uno dei metodi seguenti:
Avviare il Azure Cloud Shell.
Suggerimento
Al primo avvio di Cloud Shell, verrà richiesto di creare un account di archiviazione per Cloud Shell.
Se richiesto, scegliere Bash come ambiente usato in Cloud Shell. È anche possibile modificare gli ambienti nell'elenco a discesa sulla barra di navigazione superiore
Copiare i seguenti comandi bash nel computer e aggiornare le variabili projectName, subscriptionId e environment con i valori relativi al progetto. Se si sta creando un ambiente sia Dev che Prod, sarà necessario eseguire questo script una volta per ogni ambiente, in modo da creare un'entità servizio per ogni ambiente. Questo comando concederà anche il ruolo Collaboratore all'entità servizio nella sottoscrizione specificata. Questa operazione è necessaria perché Azure DevOps sia in grado di usare correttamente le risorse in tale sottoscrizione.
projectName="<your project name>" roleName="Contributor" subscriptionId="<subscription Id>" environment="<Dev|Prod>" #First letter should be capitalized servicePrincipalName="Azure-ARM-${environment}-${projectName}" # Verify the ID of the active subscription echo "Using subscription ID $subscriptionID" echo "Creating SP for RBAC with name $servicePrincipalName, with role $roleName and in scopes /subscriptions/$subscriptionId" az ad sp create-for-rbac --name $servicePrincipalName --role $roleName --scopes /subscriptions/$subscriptionId echo "Please ensure that the information created here is properly save for future use."Copiare i comandi modificati in Azure Shell ed eseguirli (Ctrl + Maiusc + v).
Dopo aver eseguito questi comandi, verranno visualizzate informazioni correlate all'entità servizio. Salvare queste informazioni in un percorso sicura, che verrà usato più avanti nella demo per configurare Azure DevOps.
{ "appId": "<application id>", "displayName": "Azure-ARM-dev-Sample_Project_Name", "password": "<password>", "tenant": "<tenant id>" }Ripetere il passaggio 3 se si creano entità servizio per gli ambienti di sviluppo e produzione. Per questa demo verrà creato solo l'ambiente di produzione (Prod).
Una volta create le entità servizio, chiudere Cloud Shell.
Configurare Azure DevOps
Passare ad Azure DevOps.
Selezionare Crea nuovo progetto (in questa esercitazione denominare il progetto
mlopsv2).
Nel progetto, in Impostazioni progetto (in basso a sinistra della pagina del progetto) selezionare Connessioni al servizio.
Selezionare Crea connessione al servizio.
Selezionare Azure Resource Manager e scegliere Avanti, selezionare Entità servizio (manuale) e scegliere Avanti, quindi impostare Livello ambito su Sottoscrizione.
- Nome sottoscrizione: usare il nome della sottoscrizione in cui è archiviata l'entità servizio.
- ID sottoscrizione: usare il valore
subscriptionIdusato nel passaggio 1 come ID sottoscrizione - ID entità servizio: usare il valore
appIdusato nel passaggio 1 come ID entità servizio - Chiave entità servizio: usare il valore
passwordusato nel passaggio 1 come chiave dell'entità servizio - ID tenant: usare il valore
tenantusato nel passaggio 1 come ID tenant
Denominare la connessione al servizio Azure-ARM-Prod.
Selezionare Concedi l'autorizzazione di accesso a tutte le pipeline, quindi selezionare Verifica e salva.
La configurazione di Azure DevOps è stata completata correttamente.
Configurare il repository di origine con Azure DevOps
Aprire il progetto creato in Azure DevOps.
Aprire la sezione Repository e selezionare Importa repository.
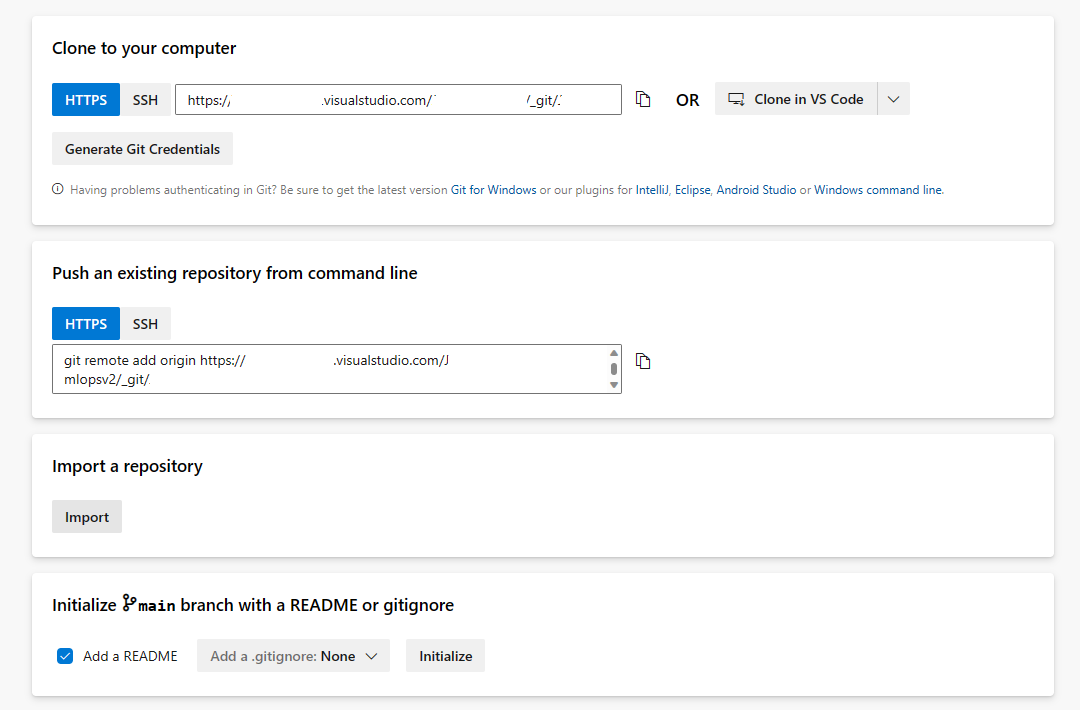
Immettere https://github.com/Azure/mlops-v2-ado-demo nel campo URL clone. Selezionare Importa nella parte inferiore della pagina.
Aprire la sezione Impostazioni del progetto nella parte inferiore del riquadro di spostamento a sinistra
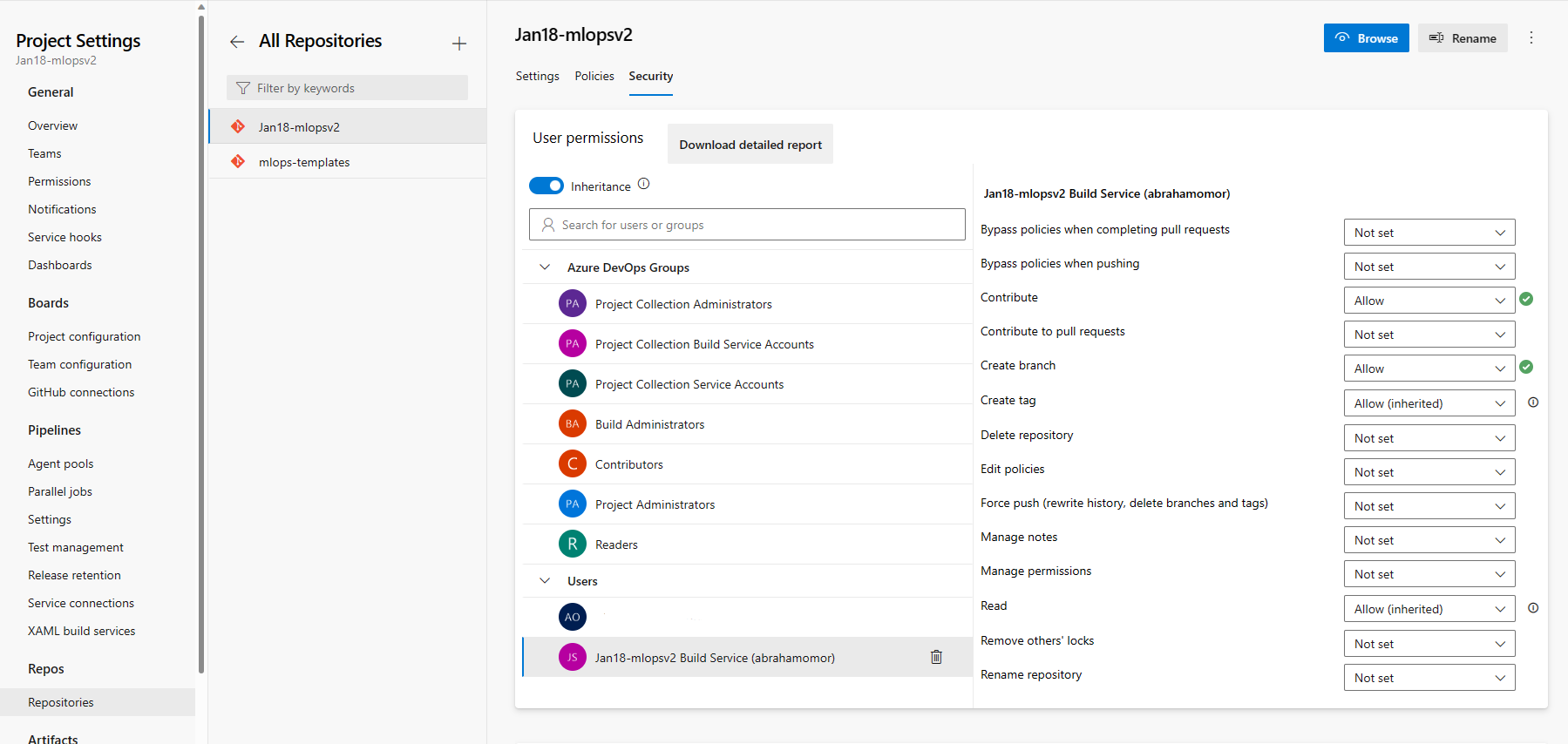
Nella sezione Repository selezionare Repository. Selezionare il repository creato nel passaggio precedente. Selezionare la scheda Sicurezza.
Nella sezione Autorizzazioni utente selezionare l'utente mlopsv2 Build Service. Impostare l'autorizzazione Contribuire su Consenti e l'autorizzazione Crea ramo su Consenti.
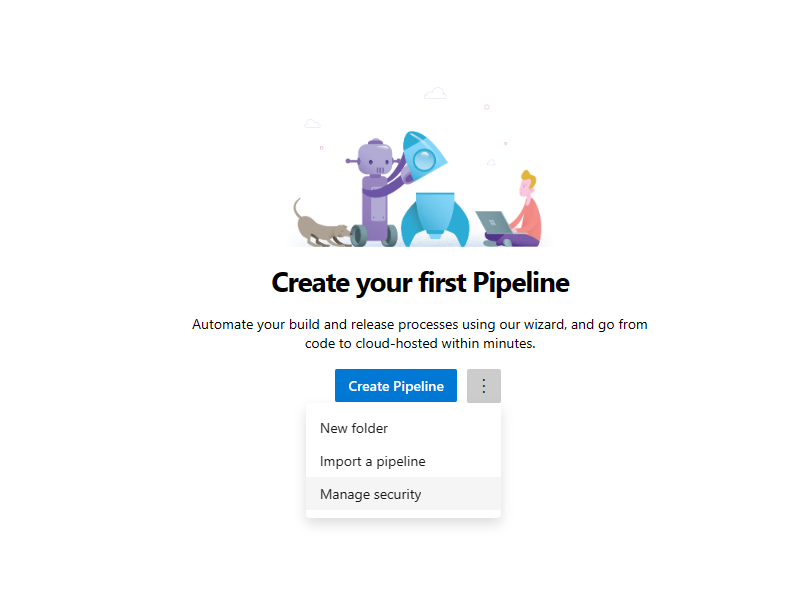
Aprire la sezione Pipeline nel riquadro di spostamento a sinistra e selezionare i tre punti verticali accanto al pulsante Crea pipeline. Selezionare Gestisci sicurezza.
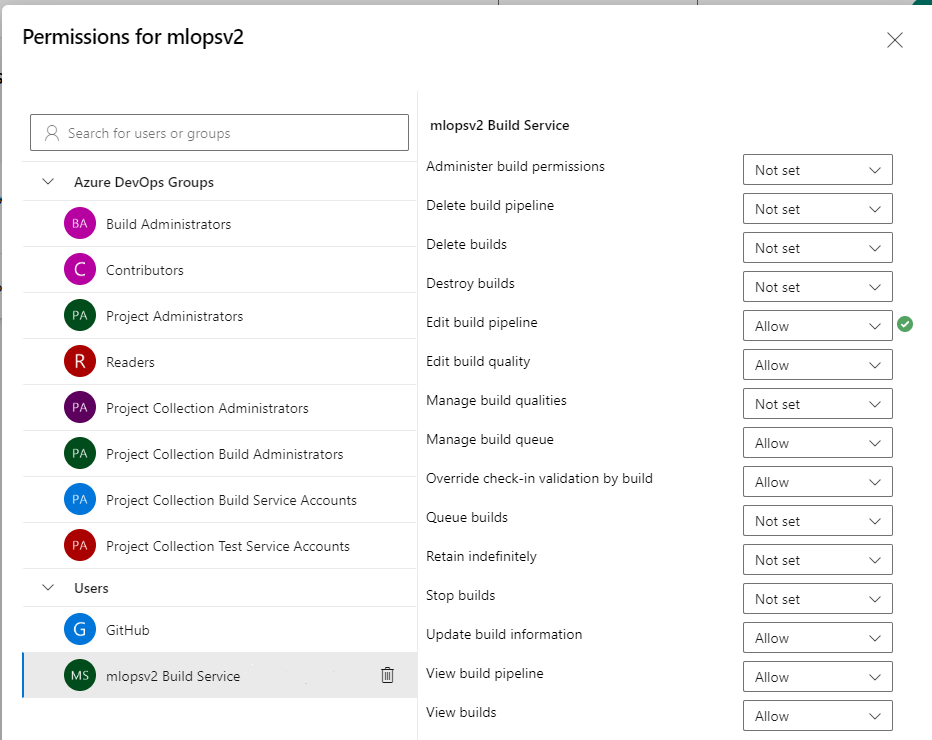
Selezionare l'account mlopsv2 Build Service per il progetto nella sezione Utenti. Impostare l'autorizzazione Modifica pipeline di compilazione su Consenti.
Nota
Questa operazione termina la sezione dei prerequisiti e la distribuzione dell'acceleratore di soluzioni può avere luogo di conseguenza.
Distribuzione dell'infrastruttura tramite Azure DevOps
Questo passaggio distribuisce la pipeline di training nell'area di lavoro di Azure Machine Learning creata nei passaggi precedenti.
Suggerimento
Prima di esaminare il repository MLOps v2 e distribuire l'infrastruttura, assicurarsi di comprendere i modelli architetturali dell'acceleratore di soluzioni. Negli esempi si userà il tipo di progetto ML classico.
Eseguire la pipeline dell'infrastruttura di Azure
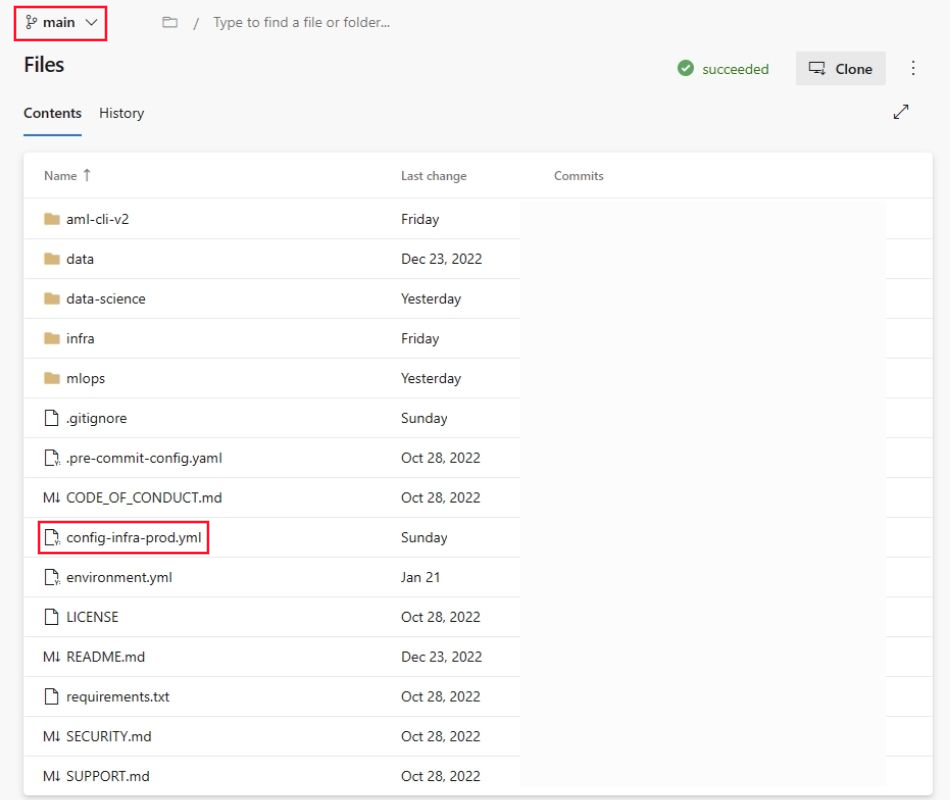
Passare al repository
mlops-v2-ado-demoe selezionare il file config-infra-prod.yml.Importante
Assicurarsi di aver selezionato il ramo principale del repository.
Questo file di configurazione usa i valori dello spazio dei nomi e del suffisso nei nomi degli artefatti per garantire l'univocità. Aggiornare la sezione seguente nella configurazione in base alle proprie esigenze.
namespace: [5 max random new letters] postfix: [4 max random new digits] location: eastusNota
Se si esegue un carico di lavoro di Deep Learning, ad esempio CV o NLP, assicurarsi che il calcolo GPU sia disponibile nella zona di distribuzione.
Selezionare Commit e push codice per recuperare questi valori nella pipeline.
Passare alla sezione Pipeline.
Seleziona Crea pipeline.
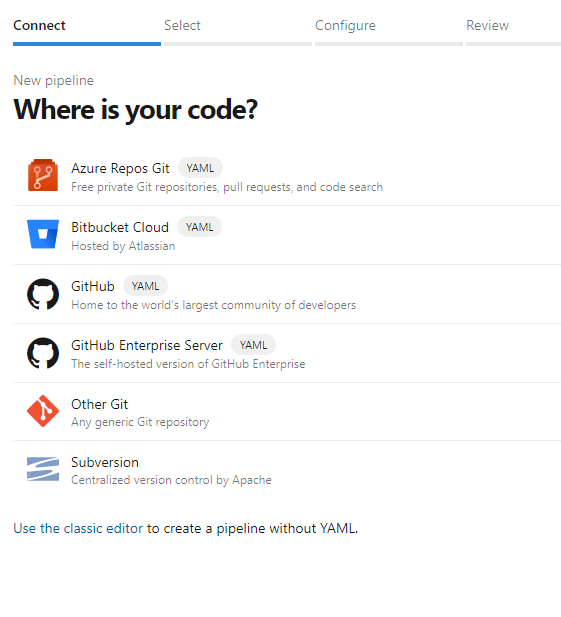
Selezionare GIT Azure Repos.
Selezionare il repository clonato nella sezione
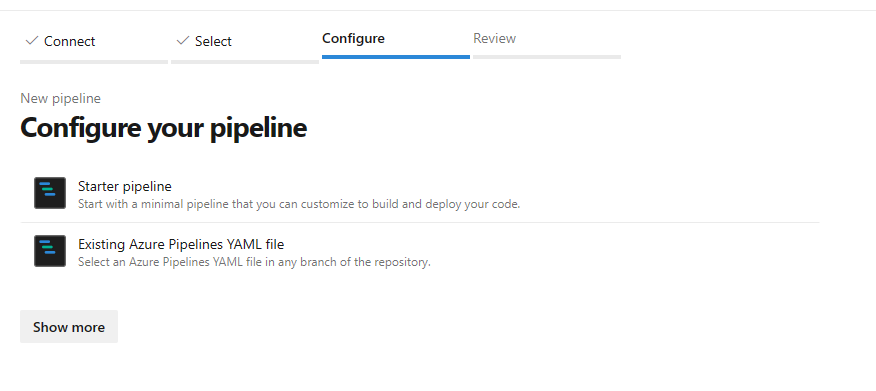
mlops-v2-ado-demoprecedente.Selezionare File YAML di Azure Pipelines esistente.
Selezionare il ramo
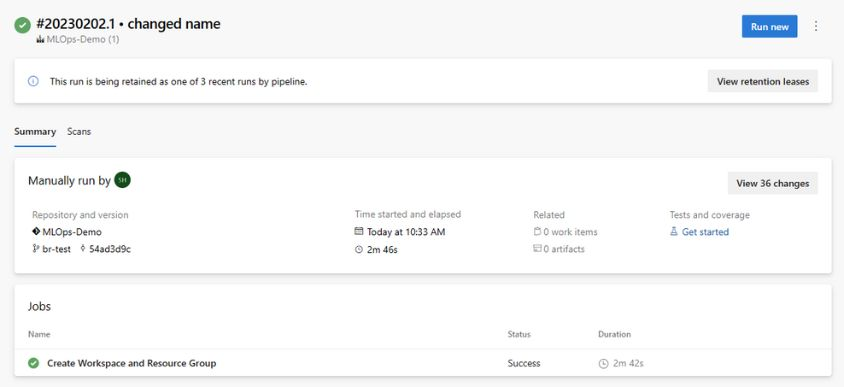
maine sceglieremlops/devops-pipelines/cli-ado-deploy-infra.yml, quindi selezionare Continua.Eseguire la pipeline; il completamento richiederà alcuni minuti. La pipeline deve creare gli artefatti seguenti:
- Gruppo di risorse per l'area di lavoro, tra cui account di archiviazione, Registro Container, Application Insights, Keyvault e area di lavoro di Azure Machine Learning stessa.
- Nell'area di lavoro è presente anche un cluster di elaborazione creato.
Ora viene distribuita l'infrastruttura per il progetto MLOps.
Nota
Gli avvisi relativi all'impossibilità di spostare e riutilizzare il repository esistente nella posizione richiesta possono essere ignorati.
Scenario di training e distribuzione di esempio
L'acceleratore di soluzione include codice e dati per una pipeline di Machine Learning end-to-end di esempio che esegue una regressione lineare per stimare le tariffe dei taxi a NYC. La pipeline è costituita da componenti, ognuno dei quali gestisce funzioni differenti, che è possibile registrare nell'area di lavoro, eseguire il controllo delle versioni, e riutilizzare con vari input e output. Le pipeline e i flussi di lavoro di esempio per gli scenari di Visione artificiale e NLP avranno passaggi e fasi di distribuzione differenti.
Questa pipeline di training contiene i passaggi seguenti:
Preparare i dati
- Questo componente accetta diversi set di dati sui taxi (gialli e verdi), unisce/filtra i dati e prepara i set di dati train/val e valutazione.
- Input: dati locali in ./data/ (diversi file .csv)
- Output: singolo set di dati preparato (.csv) e set di dati train/val/test.
Eseguire il training del modello
- Questo componente esegue il training di un regressore lineare con il set di training.
- Input: set di dati di training
- Output: modello sottoposto a training (formato pickle)
Evaluate Model (Valuta modello)
- Questo componente usa il modello sottoposto a training per stimare le tariffe dei taxi nel set di test.
- Input: modello di ML e set di dati di test
- Output: prestazioni del modello e flag di distribuzione se distribuire o meno.
- Questo componente confronta le prestazioni del modello con tutti i modelli distribuiti precedenti nel nuovo set di dati di test e decide se promuovere o meno il modello nell'ambiente di produzione. La promozione del modello nell'ambiente di produzione avviene registrando il modello nell'area di lavoro AML.
Registrare il modello
- Questo componente assegna un punteggio al modello in base alla precisione delle stime nel set di test.
- Input: modello con training e flag di distribuzione.
- Output: modello registrato in Azure Machine Learning.
Distribuzione della pipeline di training del modello
Passare alle pipeline ADO.
Selezionare Nuova pipeline.

Selezionare GIT Azure Repos.
Selezionare il repository clonato nella sezione
mlopsv2precedente.Selezionare File YAML di Azure Pipelines esistente.
Selezionare
maincome ramo e scegliere/mlops/devops-pipelines/deploy-model-training-pipeline.yml, quindi selezionare Continua.Salvare ed eseguire la pipeline
Nota
A questo punto, l'infrastruttura è configurata e viene distribuito il ciclo di prototipazione dell'architettura MLOps. A questo punto è possibile passare al modello con training nell'ambiente di produzione.
Distribuzione del modello con training
Questo scenario include flussi di lavoro predefiniti per due approcci alla distribuzione di un modello con training, l'assegnazione di punteggi batch o la distribuzione di un modello a un endpoint per l'assegnazione dei punteggi in tempo reale. È possibile eseguire uno o entrambi questi flussi di lavoro per testare le prestazioni del modello nell'area di lavoro di Azure Machine Learning. In questo esempio verrà usato l'assegnazione dei punteggi in tempo reale.
Distribuire l'endpoint del modello di Machine Learning
Passare alle pipeline ADO.
Selezionare Nuova pipeline.
Selezionare GIT Azure Repos.
Selezionare il repository clonato nella sezione
mlopsv2precedente.Selezionare File YAML di Azure Pipelines esistente.
Selezionare
maincome ramo, scegliere l'endpoint online gestito/mlops/devops-pipelines/deploy-online-endpoint-pipeline.ymle quindi selezionare Continua.I nomi degli endpoint online devono essere univoci, quindi impostare
taxi-online-$(namespace)$(postfix)$(environment)su un nome univoco diverso e quindi selezionare Esegui. Non è necessario modificare l'impostazione predefinita se non ha esito negativo.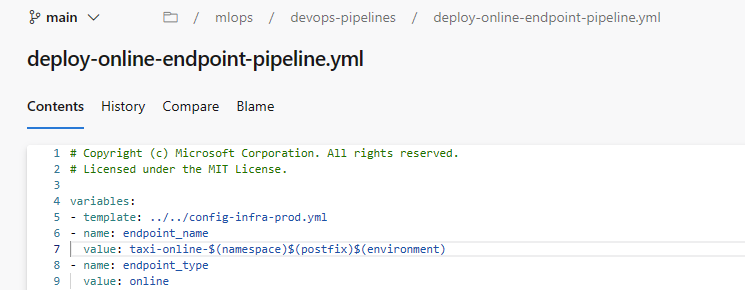
Importante
Se l'esecuzione non riesce a causa di un nome di endpoint online esistente, ricreare la pipeline come descritto in precedenza e modificare [nome-endpoint] impostandolo su [nome endpoint (numero casuale)].
Al termine dell'esecuzione, l'output generato sarà simile al seguente:
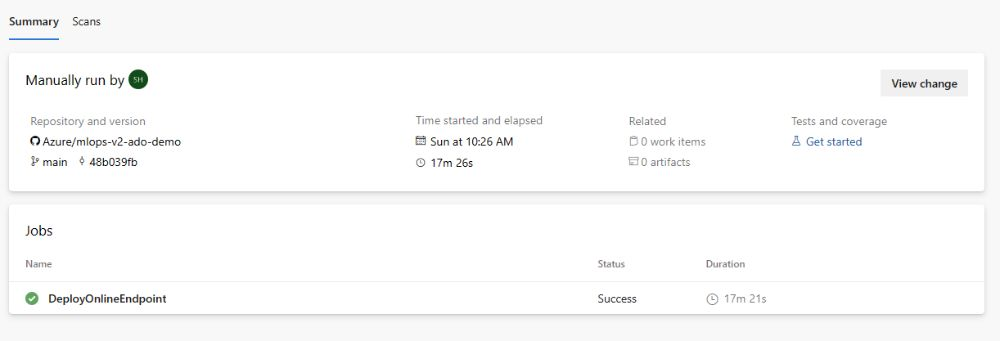
Per testare questa distribuzione, passare alla scheda Endpoint nell'area di lavoro di Azure Machine Learning, selezionare l'endpoint e fare clic sulla scheda Test. È possibile usare i dati di input di esempio presenti nel repository clonato in
/data/taxi-request.jsonper testare l'endpoint.
Pulire le risorse
- Se non si intende continuare a usare la pipeline, eliminare il progetto Azure DevOps.
- Nel portale di Azure eliminare il gruppo di risorse e l'istanza di Azure Machine Learning.
Passaggi successivi
- Installare e configurare Python SDK v2
- Installare e configurare Python CLI v2
- Acceleratore di soluzioni Azure MLOps (v2) in GitHub
- Corso di formazione su MLOps con Machine Learning
- Altre informazioni su Azure Pipelines con Azure Machine Learning
- Altre informazioni su GitHub Actions con Azure Machine Learning
- Distribuire MLOps in Azure in meno di un'ora - Video dell'acceleratore MLOps V2 della community