Configurare un progetto di etichettatura del testo ed esportare le etichette
In Azure Machine Learning è possibile apprendere come creare ed eseguire i progetti di etichettatura dei dati per aggiungere etichette ai dati di testo. Specificare una singola etichetta o più etichette da applicare a ogni elemento di testo.
È anche possibile usare lo strumento di etichettatura dei dati in Azure Machine Learning per creare un progetto di etichettatura delle immagini.
Funzionalità di etichettatura del testo
L'etichettatura dei dati di Azure Machine Learning è uno strumento che è possibile usare per creare, gestire e monitorare i progetti di etichettatura dei dati. Usarlo per:
- Coordinare i dati, le etichette e i membri del team per gestire in modo efficiente le attività di etichettatura.
- Tenere traccia dello stato di avanzamento e mantenere la coda delle attività di etichettatura incomplete.
- Avviare e arrestare il progetto e controllare lo stato di avanzamento dell'etichettatura.
- Esaminare ed esportare i dati etichettati come set di dati di Azure Machine Learning.
Importante
I dati di testo usati nello strumento di etichettatura dei dati di Azure Machine Learning devono essere disponibili in un archivio dati di Archiviazione BLOB di Azure. Se non si ha un archivio dati esistente, è possibile caricare i file di dati in un nuovo archivio dati quando si crea un progetto.
Per i dati di testo sono disponibili questi formati di dati:
- TXT: ogni file rappresenta un elemento da etichettare.
- CSV o TSV: ogni riga rappresenta un elemento presentato all'etichettatore. Si decide quali colonne l'etichettatore può visualizzare quando etichettano la riga.
Prerequisiti
Questi elementi vengono usati per configurare l'etichettatura del testo in Azure Machine Learning:
- I dati da etichettare, inclusi in file locali o nell'Archiviazione BLOB di Azure.
- I set di etichette da applicare.
- Le istruzioni per l'etichettatura.
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Un'area di lavoro di Azure Machine Learning. Vedere Creare un'area di lavoro di Azure Machine Learning.
Creare un progetto di etichettatura del testo
I progetti di etichettatura vengono amministrati in Azure Machine Learning. Usare la pagina Etichettatura dei dati in Machine Learning per gestire i progetti.
Se i dati sono già presenti in Archiviazione Blob di Azure, assicurarsi che siano disponibili come archivio dati prima di creare il progetto di etichettatura.
Per creare un progetto, scegliere Aggiungi il progetto.
Per Nome progetto immettere un nome per il progetto.
Non è possibile riutilizzare il nome del progetto, anche se si elimina il progetto.
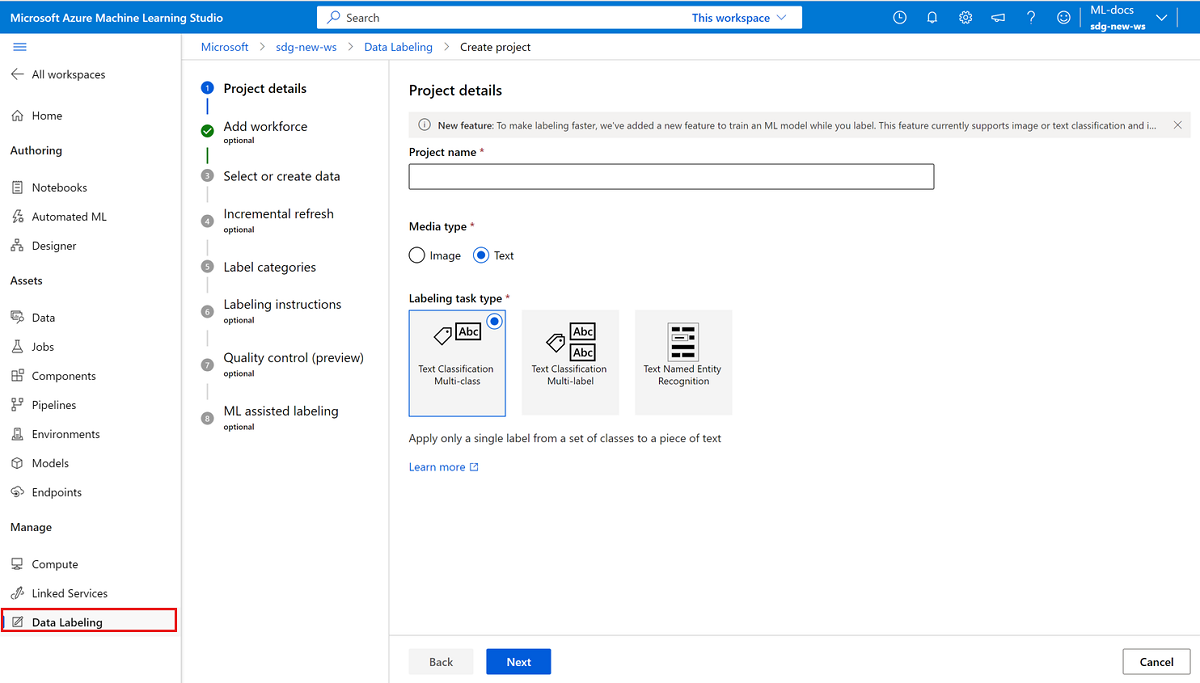
Per creare un progetto di etichettatura del testo, per Tipo di supporto selezionare Testo.
Per Tipo di attività etichettatura selezionare un'opzione per lo scenario:
- Per applicare solo un'etichetta singola a ogni parte di testo da un set di etichette, selezionare Classificazione di testo multi-classe.
- Per applicare una o più etichette a ogni parte di testo da un set di etichette, selezionare Classificazione di testo multi-classe.
- Per applicare etichette a singole parole del testo o a più parole del testo in ogni voce, selezionare Riconoscimento entità denominata testo.
Selezionare Avanti per continuare.
Aggiungere forza lavoro (facoltativo)
Selezionare Usa una società fornitrice di etichettatura da Azure Marketplace solo se ci si è rivolti a un'azienda di etichettatura dati da Azure Marketplace. Selezionare quindi il fornitore. Se il fornitore non viene visualizzato nell'elenco, deselezionare questa opzione.
Assicurarsi di contattare prima il fornitore e firmare un contratto. Per altre informazioni, vedere Usare una società fornitrice di etichettatura (anteprima).
Selezionare Avanti per continuare.
Selezionare o creare un set di dati
Se è già stato creato un set di dati contenente i dati da usare, selezionarlo nell'elenco a discesa Seleziona un set di dati esistente. È anche possibile selezionare Crea un set di dati per usare un archivio dati di Azure esistente o per caricare i file locali.
Nota
Un progetto non può contenere più di 500.000 file. Se il set di dati supera questo numero di file, vengono caricati solo i primi 500.000 file.
Creare un set di dati da un archivio dati di Azure
In molti casi è possibile caricare i file locali. Azure Storage Explorer offre tuttavia un modo più rapido e affidabile per trasferire una grande quantità di dati. È consigliabile usare Storage Explorer come modalità predefinita per lo spostamento dei file.
Per creare un set di dati dai dati già archiviati in Archiviazione Blob:
- Seleziona Crea.
- In Nome immettere un nome per il set di dati. Facoltativamente, immetti una descrizione.
- Scegliere il Tipo di set di dati:
- Se si usa un file CSV o TSV e ogni riga contiene una risposta, selezionare Tabulare.
- Se si usano file TXT separati per ogni risposta, selezionare File.
- Selezionare Avanti.
- Selezionare Da Archiviazione di Azure e quindi selezionare Avanti.
- Selezionare l'archivio dati e quindi selezionare Avanti.
- Se i dati si trovano in una sottocartella all'interno dell'Archiviazione Blob, scegliere Sfoglia per selezionare il percorso.
- Per includere tutti i file nelle sottocartelle del percorso selezionato, aggiungere
/**al percorso. - Per includere tutti i dati nel contenitore corrente e le relative sottocartelle, aggiungere
**/*.*al percorso.
- Per includere tutti i file nelle sottocartelle del percorso selezionato, aggiungere
- Seleziona Crea.
- Selezionare l'asset di dati creato.
Creare un set di dati dai dati caricati
Per caricare direttamente i dati:
- Seleziona Crea.
- In Nome immettere un nome per il set di dati. Facoltativamente, immetti una descrizione.
- Scegliere il Tipo di set di dati:
- Se si usa un file CSV o TSV e ogni riga contiene una risposta, selezionare Tabulare.
- Se si usano file TXT separati per ogni risposta, selezionare File.
- Selezionare Avanti.
- Selezionare Da file locali e quindi selezionare Avanti.
- (Facoltativo) Selezionare un archivio dati. Per impostazione predefinita, viene eseguito il caricamento nell'archivio BLOB predefinito (workspaceblobstore) per l'area di lavoro di Machine Learning.
- Selezionare Avanti.
- Selezionare Carica>Carica file o Carica>Carica cartella per selezionare i file o le cartelle locali da caricare.
- Trovare i file o la cartella nella finestra del browser e quindi selezionare Apri.
- Continuare a selezionare Carica fino a quando non si specificano tutti i file e le cartelle.
- Facoltativamente, selezionare la casella di controllo Sovrascrivi se esiste già. Verificare l'elenco di file e cartelle.
- Selezionare Avanti.
- Confermare i dettagli. Selezionare Indietro per modificare le impostazioni oppure selezionare Crea per creare il set di dati.
- Selezionare infine l'asset di dati creato.
Configurare l'aggiornamento incrementale
Se si prevede di aggiungere nuovi file di dati al set di dati, usare l'aggiornamento incrementale per aggiungere i file al progetto.
Quando l'opzione Abilita aggiornamento incrementale a intervalli regolari è impostata, il set di dati viene controllato periodicamente per verificare se sono presenti nuovi file da caricare in un progetto in base alla frequenza di completamento dell'etichettatura. Il controllo della presenza di nuovi dati viene interrotto quando il progetto raggiunge il limite massimo di 500.000 file.
Selezionare Abilita aggiornamento incrementale a intervalli regolari quando si vuole che il progetto monitori continuamente la presenza di nuovi dati nell'archivio dati.
Cancellare la selezione se non si vuole aggiungere automaticamente nuovi file nell'archivio dati al progetto.
Importante
Quando l'aggiornamento incrementale è abilitato, è consigliabile non creare una nuova versione per il set di dati da aggiornare. In tal caso, gli aggiornamenti non verranno visualizzati perché il progetto di etichettatura dei dati viene aggiunto alla versione iniziale. Usare invece Azure Storage Explorer per modificare i dati nella cartella appropriata in Archiviazione Blob.
Inoltre, non rimuovere i dati. La rimozione dei dati dal set di dati usato dal progetto causa un errore nel progetto stesso.
Dopo aver creato il progetto, usare la scheda Dettagli per modificare l'aggiornamento incrementale, visualizzare il timestamp per l'ultimo aggiornamento e richiedere un aggiornamento immediato dei dati.
Nota
I progetti che usano l'input di set di dati tabulare (CSV o TSV) possono usare l'aggiornamento incrementale. L'aggiornamento incrementale aggiunge tuttavia solo nuovi file tabulari. L'aggiornamento non riconosce le modifiche apportate ai file tabulari esistenti.
Specificare le categorie di etichette
Nella pagina Categorie etichette specificare un set di classi per classificare i dati.
La capacità di scegliere tra le classi influisce sull'accuratezza e sulla velocità degli etichettatori. Ad esempio, invece di includere genere e specie completi per le piante o gli animali, usare i codici di campo o abbreviare il genere.
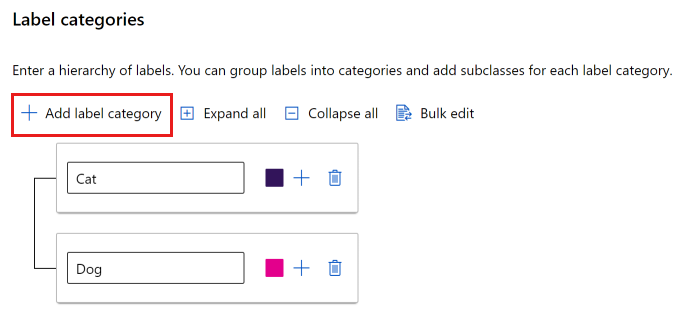
È possibile usare un elenco semplice o creare gruppi di etichette.
Per creare un elenco semplice, selezionare Aggiungi categoria di etichette per creare ogni etichetta.
Per creare etichette in gruppi diversi, selezionare Aggiungi categoria di etichette per creare le etichette di primo livello. Selezionare quindi il segno più (+) in ogni livello principale per creare il livello successivo di etichette per tale categoria. È possibile creare fino a sei livelli per qualsiasi raggruppamento.
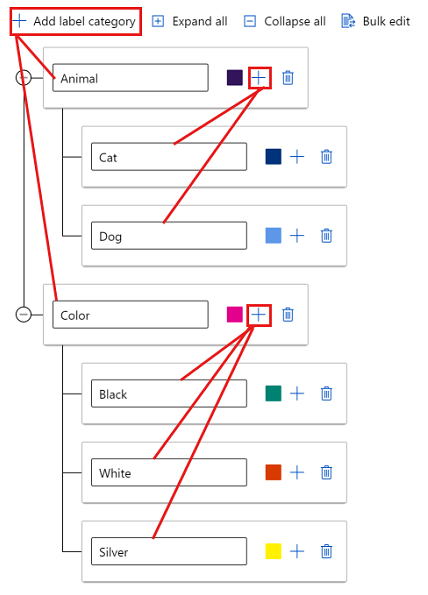
È possibile selezionare etichette a qualsiasi livello durante il processo di assegnazione di tag. Ad esempio, le etichette Animal, Animal/Cat, Animal/Dog, Color, Color/Black, Color/White e Color/Silver sono tutte opzioni disponibili per un'etichetta. In un progetto con più etichette non è necessario selezionare una opzione di ogni categoria. Se si vuole che questa operazione venga eseguita, assicurarsi di includere queste informazioni nelle istruzioni.
Descrivere l'attività di etichettatura del testo
È importante spiegare chiaramente l'attività di etichettatura. Nella pagina Istruzioni di etichettatura è possibile aggiungere un collegamento a un sito esterno che include tali istruzioni o fornire le istruzioni nella casella di modifica della pagina. Le istruzioni devono essere basate sull'attività e appropriate per i destinatari. Considerare queste domande:
- Quali sono le etichette che saranno visibili agli etichettatori e come potranno scegliere tra le etichette? Esiste un testo di riferimento da consultare?
- Cosa è necessario fare se nessuna etichetta risulta appropriata?
- Cosa è necessario fare se più etichette risultano appropriate?
- Qual è la soglia di attendibilità da applicare a un'etichetta? In caso di subbio, si vuole usare l'ipotesi migliore dell'etichettatore?
- Cosa è necessario fare con gli oggetti di interesse parzialmente bloccati o sovrapposti?
- Cosa è necessario fare se un oggetto di interesse è tagliato dal bordo dell'immagine?
- Cosa dovrebbero fare se pensano di aver commesso un errore dopo aver inviato un'etichetta?
- Cosa dovrebbero fare se individuano problemi di qualità delle immagini, tra cui condizioni di illuminazione scadenti, riflessi, sfocatura, sfondo indesiderato incluso, angoli anomali della fotocamera e così via?
- Cosa dovrebbero fare se più revisori hanno opinioni diverse sull'applicazione di un'etichetta?
Nota
Gli etichettatori possono selezionare le prime nove etichette usando i tasti numerici da 1 a 9.
Controllo qualità (anteprima)
Per ottenere etichette più accurate, usare la pagina Controllo qualità per inviare ogni elemento a più etichettatori.
Importante
L'etichettatura basata su consenso è attualmente disponibile in anteprima pubblica.
La versione di anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Per inviare ogni elemento a più etichettatori, selezionare Abilita etichettatura basata su consenso (anteprima). Impostare quindi i valori per Numero minimo etichettatori e Numero massimo etichettatori per specificare quanti etichettatori usare. Assicurarsi che il numero di etichettatori disponibili corrisponda al numero massimo specificato. Non è possibile modificare queste impostazioni dopo l'avvio del progetto.
Se viene raggiunto un consenso dal numero minimo di etichettatori, l'elemento viene etichettato. Se non viene raggiunto un consenso, l'elemento viene inviato a più etichettatori. Se il consenso non viene raggiunto dopo il passaggio dell'elemento al numero massimo di etichettatori, il relativo stato è Da rivedere e il proprietario del progetto è responsabile dell'etichettatura dell'elemento.
Usare l'etichettatura assistita da ML
Per accelerare le attività di etichettatura, la pagina Etichettatura assistita da ML può attivare modelli di Machine Learning automatici. L'etichettatura assistita da Machine Learning (ML) può gestire sia input di dati di testo di tipo file (TXT) e tabulari (CSV).
Per usare l'etichettatura assistita da ML
- Selezionare Abilita etichettatura assistita da ML.
- Selezionare Lingua del set di dati per il progetto. Questo elenco mostra tutte le lingue supportate dalla classe TextDNNLanguages Class.
- Specificare una destinazione di calcolo da usare. Se non si ha una destinazione di calcolo nell'area di lavoro, questo passaggio crea un cluster di calcolo e lo aggiunge all'area di lavoro. Il cluster viene creato con un minimo di zero nodi e non costa nulla quando non è in uso.
Altre informazioni sull'etichettatura assistita da ML
All'inizio del progetto di etichettatura, gli elementi vengono mescolati in modo casuale per ridurre le potenziali distorsioni. Tuttavia, il modello sottoposto a training riflette eventuali distorsioni presenti nel set di dati. Ad esempio, se l'80% degli elementi è di una singola classe, circa l'80% dei dati usati per eseguire il training del modello rientrerà in tale classe.
Per eseguire il training del modello DNN di testo usato dall'etichettatura assistita da ML, il testo di input per ogni esempio di training è limitato alle prime 128 parole circa del documento. Per l'input tabulare, tutte le colonne di testo vengono concatenate prima dell'applicazione di questo limite. Questo limite pratico consente il completamento del training del modello in un periodo di tempo ragionevole. Il testo effettivo in un documento (per l'input di tipo file) o un set di colonne di testo (per l'input tabulare) può superare le 128 parole. Il limite riguarda solo ciò che il modello usa internamente durante il processo di training.
Il numero di elementi etichettati necessari per avviare l'etichettatura assistita non è un numero fisso. Questo numero può variare in modo significativo da un progetto di etichettatura a un altro. La varianza dipende da molti fattori, tra cui il numero di classi di etichette e la distribuzione delle etichette.
Quando si usa l'etichettatura basata su consenso, l'etichetta basata su consenso viene usata per il training.
Poiché le etichette finali si basano ancora sull'input dell'etichettatore, questa tecnologia viene a volte chiamata etichettatura human-in-the-loop.
Nota
L'etichettatura dei dati assistita da ML non supporta gli account di archiviazione predefiniti protetti da una rete virtuale. È necessario usare un account di archiviazione non predefinito per l'etichettatura dei dati assistita da ML. L'account di archiviazione non predefinito può essere protetto tramite la rete virtuale.
Pre-etichettatura
Dopo aver inviato etichette sufficienti per il training, il modello sottoposto a training viene usato per stimare i tag. L'etichettatore visualizza ora le pagine che mostrano le etichette stimate già presenti in ogni elemento. L'attività implica quindi la revisione di queste stime e la correzione di eventuali elementi etichettati in modo errato prima dell'invio della pagina.
Dopo aver eseguito il training del modello di Machine Learning sui dati etichettati manualmente, il modello viene valutato su un set di test di elementi etichettati manualmente. La valutazione consente di determinare l'accuratezza del modello in base a soglie di confidenza diverse. Il processo di valutazione imposta una soglia di confidenza oltre la quale il modello è abbastanza accurato per mostrare le pre-etichette. Il modello viene quindi valutato in base ai dati non etichettati. Gli elementi con stime con confidenza maggiore rispetto alla soglia vengono usati per l'etichettatura preliminare.
Inizializzare il progetto di etichettatura del testo
Dopo l'inizializzazione del progetto di etichettatura, alcuni aspetti non saranno modificabili. Non è possibile cambiare il tipo di attività o il set di dati. È invece possibile modificare le etichette e l'URL per la descrizione dell'attività. Esaminare attentamente le impostazioni prima di creare il progetto. Dopo aver inviato il progetto, tornare alla pagina di panoramica Etichettatura dei dati, che mostra il progetto come Inizializzazione.
Nota
La pagina di panoramica potrebbe non essere aggiornata automaticamente. Dopo una pausa, aggiornare manualmente la pagina per visualizzare lo stato del progetto come Creato.
Risoluzione dei problemi
Per problemi relativi alla creazione di un progetto o all'accesso ai dati, vedere Risolvere i problemi di etichettatura dei dati.