Configurare Machine Learning automatizzato per eseguire il training di un modello di previsione di serie temporali con Python (Software Development Kit v1)
SI APPLICA A:  Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come configurare il training di Machine Learning automatizzato (AutoML) per modelli di previsione di serie temporali con Machine Learning automatizzato di Azure Machine Learning nel Software Development Kit Python di Azure Machine Learning.
A tale scopo, è necessario:
- Preparare i dati per la modellazione delle serie temporali.
- Configurare parametri di serie temporali specifici in un oggetto
AutoMLConfig. - Eseguire previsioni con dati delle serie temporali.
Per un'esperienza con poco codice, vedere Esercitazione: prevedere la domanda con Machine Learning automatizzato per un esempio di previsione di serie temporali usando Machine Learning automatizzato nello studio di Azure Machine Learning.
A differenza dei metodi classici delle serie temporali, in Machine Learning automatizzato i valori delle serie temporali precedenti vengono "trasformati tramite Pivot" per diventare dimensioni aggiuntive per il regressore insieme ad altri predittori. Questo approccio incorpora più variabili contestuali e la relazione reciproca durante il training. Poiché più fattori possono influenzare una previsione, questo metodo si allinea perfettamente con scenari di previsione reali. Ad esempio, quando si prevedono le vendite, le interazioni delle tendenze storiche, il tasso di cambio e il prezzo influenzano congiuntamente il risultato delle vendite.
Prerequisiti
Per questo articolo sono necessari:
Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, vedere Creare risorse dell'area di lavoro.
Questo articolo presuppone una certa familiarità con la configurazione di un esperimento di Machine Learning automatizzato. Seguire la procedura per visualizzare i principali schemi progettuali dell'esperimento di Machine Learning automatizzato.
Importante
Con i comandi Python descritti in questo articolo è richiesta la versione più recente del pacchetto
azureml-train-automl.- Installare il pacchetto
azureml-train-automlpiù recente nell'ambiente locale. - Per informazioni dettagliate sul pacchetto
azureml-train-automlpiù recente, vedere le note sulla versione.
- Installare il pacchetto
Dati di training e convalida
La differenza più importante tra un tipo di attività di regressione di previsione e un tipo di attività di regressione all'interno di Machine Learning automatizzato è la presenza di una funzionalità nei dati di training che rappresenta una serie temporale valida. Una serie temporale regolare presenta una frequenza ben definita e coerente e un valore in ogni punto di esempio in un intervallo di tempo continuo.
Importante
Quando si esegue il training di un modello per la previsione di valori futuri, assicurarsi che tutte le funzionalità usate nel training possano essere usate quando si eseguono stime per l'orizzonte previsto. Ad esempio, durante la creazione di una previsione della richiesta, includere una funzionalità per il prezzo dei titoli azionari corrente potrebbe aumentare notevolmente l'accuratezza del training. Se, tuttavia, si vogliono effettuare previsioni con un orizzonte lungo, potrebbe non essere possibile stimare in modo accurato i valori dei titoli azionari futuri corrispondenti ai punti futuri della serie temporale e l'accuratezza del modello potrebbe risentirne.
È possibile specificare dati di training e dati di convalida separati direttamente nell'oggetto AutoMLConfig. Altre informazioni sull'oggetto AutoMLConfig.
Per la previsione di serie temporali, per impostazione predefinita viene usata solo la convalida incrociata dell'origine in sequenza per la convalida. La convalida incrociata dell'origine in sequenza divide la serie in dati di training e convalida usando un punto di origine. Scorrere l'origine nel tempo comporta la generazione di riduzioni della convalida incrociata. Questa strategia mantiene l'integrità dei dati delle serie temporali ed elimina il rischio di perdita di dati.
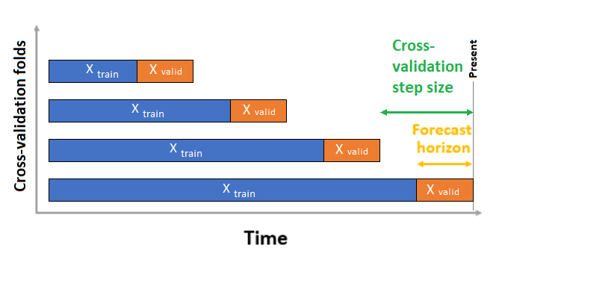
Passare i dati di training e convalida come set di dati al parametro training_data. Impostare il numero di riduzioni di convalida incrociata con il parametro n_cross_validations e impostare il numero di periodi tra due riduzioni di convalida incrociata consecutive con cv_step_size. È anche possibile lasciare uno o entrambi i parametri vuoti e Machine Learning automatizzato li imposterà automaticamente.
SI APPLICA A: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
È anche possibile usare i propri dati di convalida. Altre informazioni sono disponibili in Configurare le divisioni dei dati e la convalida incrociata in Machine Learning automatizzato.
Seguire il collegamento per altre informazioni su come Machine Learning automatizzato applica la convalida incrociata per impedire l'overfitting dei modelli.
Configurare l'esperimento
L'oggetto AutoMLConfig definisce le impostazioni e i dati necessari per un'attività di Machine Learning automatizzato. La configurazione per un modello di previsione è simile alla configurazione di un modello di regressione standard, ma alcuni modelli, opzioni di configurazione e passaggi di definizione delle funzionalità esistono in modo specifico per i dati delle serie temporali.
Modelli supportati
Machine Learning automatizzato prova automaticamente modelli e algoritmi diversi come parte del processo di creazione e ottimizzazione del modello. Come utente, non è necessario specificare l'algoritmo. Per gli esperimenti di previsione, sia i modelli delle serie temporali nativi, sia i modelli di Deep Learning vengono forniti come parte del sistema di raccomandazione.
Suggerimento
Come parte del sistema di raccomandazione per gli esperimenti di previsione, vengono testati anche i modelli di regressione tradizionali. Vedere un elenco completo dei modelli supportati nella documentazione di riferimento del Software Development Kit.
Impostazioni di configurazione
Analogamente a un problema di regressione, si definiscono parametri di training standard, come il tipo di attività, il numero di iterazioni, i dati di training e il numero di convalide incrociate. Le attività di previsione richiedono i parametri time_column_name e forecast_horizon per configurare l'esperimento. Se i dati includono più serie temporali, ad esempio i dati di vendita per più negozi o dati energetici provenienti da stati diversi, Machine Learning automatizzato rileva automaticamente questa situazione e imposta automaticamente il parametro time_series_id_column_names (anteprima). È anche possibile includere parametri aggiuntivi per configurare meglio l'esecuzione. Vedere la sezione Configurazioni facoltative per altri dettagli su cosa può essere incluso.
Importante
L'identificazione automatica delle serie temporali è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
| Nome parametro | Descrizione |
|---|---|
time_column_name |
Usato per specificare la colonna datetime nei dati di input usati per compilare la serie temporale e dedurne la frequenza. |
forecast_horizon |
Definisce il numero di periodi futuri da prevedere. L'orizzonte è espresso in unità di frequenza delle serie temporali. Le unità si basano sull'intervallo temporale dei dati di training, ad esempio mensile o settimanale, che il modulo di previsione deve prevedere. |
Il codice seguente:
- Usa la classe
ForecastingParametersper definire i parametri di previsione per il training dell'esperimento - Imposta
time_column_namesul campoday_datetimenel set di dati. - Imposta
forecast_horizonsu 50 per fornire una previsione per l'intero set di test.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Questi forecasting_parameters vengono quindi passati all'oggetto AutoMLConfig standard insieme al tipo di attività forecasting, alla metrica primaria, ai criteri uscita e ai dati di training.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
La quantità di dati necessari per eseguire correttamente il training di un modello di previsione con Machine Learning automatizzato è influenzata dai valori forecast_horizon, n_cross_validations e target_lags o target_rolling_window_size specificati quando si configura AutoMLConfig.
La formula seguente calcola la quantità di dati cronologici necessari per costruire le funzionalità delle serie temporali.
Dati cronologici minimi necessari: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Viene generata un'eccezione Error exception per qualsiasi serie nel set di dati che non soddisfa la quantità richiesta di dati cronologici per le impostazioni pertinenti specificate.
Passaggi di definizione delle funzionalità
In ogni esperimento di Machine Learning automatizzato, le tecniche di ridimensionamento automatico e normalizzazione vengono applicate ai dati per impostazione predefinita. Queste tecniche sono tipi di definizione delle funzionalità che aiutano determinati algoritmi che sono sensibili a funzionalità su scale diverse. Altre informazioni sui passaggi di definizione delle funzionalità predefiniti sono disponibili in Definizione delle funzionalità in Machine Learning automatizzato
Tuttavia, i passaggi seguenti vengono eseguiti solo per i tipi di attività forecasting:
- Rilevare la frequenza di campionamento della serie temporale (ad esempio, ogni ora, giorno, settimana) e creare nuovi record per i momenti mancanti per rendere la serie continua
- Imputare i valori mancanti nell'oggetto di destinazione (tramite il caricamento in diretta) e nelle colonne di funzioni (usando i valori della colonna mediana)
- Creare funzionalità basate su identificatori di serie temporali per abilitare effetti fissi in serie diverse
- Creare funzionalità basate sul tempo per facilitare l'apprendimento di modelli stagionali
- Codificare variabili categoriche su quantità numeriche
- Rilevare le serie temporali non stazionarie e differenziarle automaticamente per attenuare l'impatto delle radici unitarie.
Per visualizzare l'elenco completo delle possibili funzionalità progettate generate dai dati delle serie temporali, vedere Classe TimeIndexFeaturizer.
Nota
I passaggi di definizione delle funzionalità di Machine Learning automatizzato (normalizzazione delle funzionalità, gestione dei dati mancanti, conversione dei valori di testo in formato numerico e così via) diventano parte del modello sottostante. Quando si usa il modello per le previsioni, gli stessi passaggi di definizione delle funzionalità applicati durante il training vengono automaticamente applicati ai dati di input.
Personalizzare la definizione delle funzionalità
È anche possibile personalizzare le impostazioni di definizione delle funzionalità per assicurarsi che i dati e le funzionalità usati per eseguire il training del modello di Machine Learning risultino in previsioni pertinenti.
Le personalizzazioni supportate per le attività forecasting includono:
| Personalizzazione | Definizione |
|---|---|
| Aggiornamento dello scopo della colonna | Esegue l'override del tipo di funzionalità rilevato automaticamente per la colonna specificata. |
| Aggiornamento dei parametri del trasformatore | Aggiorna i parametri per il trasformatore specificato. Supporta attualmente Imputer (fill_value e median). |
| Eliminazione delle colonne | Specifica le colonne da eliminare dalla definizione delle funzionalità. |
Per personalizzare la definizione delle funzionalità con il Software Development Kit, specificare "featurization": FeaturizationConfig nell'oggetto AutoMLConfig. Seguire il collegamento per altre informazioni sulla definizione delle funzionalità personalizzata.
Nota
La funzionalità di eliminazione delle colonne è deprecata a partire dalla versione 1.19 dell'SDK. Eliminare colonne dal set di dati come parte della pulizia dei dati, prima di usarle nell'esperimento di Machine Learning automatizzato.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Se si usa lo studio di Azure Machine Learning per l'esperimento, vedere come personalizzare la definizione delle funzionalità nello studio.
Configurazioni facoltative
Sono disponibili altre configurazioni facoltative per le attività di previsione, ad esempio l'abilitazione del Deep Learning e la specifica di un'aggregazione della finestra mobile di destinazione. Un elenco completo di parametri aggiuntivi è disponibile nella documentazione di riferimento dell'SDK su ForecastingParameters.
Frequenza e aggregazione dei dati di destinazione
Usare la frequenza, il parametro freq, per evitare errori causati da dati irregolari. I dati irregolari includono i dati che non seguono una cadenza impostata, ad esempio dati orari o giornalieri.
Per dati altamente irregolari o per esigenze aziendali variabili, facoltativamente è possibile impostare la frequenza di previsione desiderata, freq, e specificare target_aggregation_function per aggregare la colonna di destinazione della serie temporale. Usare queste due impostazioni nell'oggetto AutoMLConfig consente di risparmiare tempo durante la preparazione dei dati.
Le operazioni di aggregazione supportate per i valori della colonna di destinazione includono:
| Funzione | Descrizione |
|---|---|
sum |
Somma dei valori di destinazione |
mean |
Media dei valori di destinazione |
min |
Valore minimo di una destinazione |
max |
Valore massimo di una destinazione |
Abilita Deep Learning
Nota
Il supporto della rete neurale profonda per la previsione in Machine Learning automatizzato è in anteprima e non è supportato per le esecuzioni locali o le esecuzioni avviate in Databricks.
È anche possibile applicare il Deep Learning con reti neurali profonde per migliorare i punteggi del modello. Il Deep Learning di Machine Learning automatizzato consente di prevedere i dati univariati e multivariati della serie temporale.
I modelli di Deep Learning hanno tre funzionalità intrinseche:
- Possono imparare da mapping arbitrari da input a output
- Supportano più input e output
- Queste possono estrarre automaticamente modelli nei dati di input che si estendono su sequenze lunghe.
Per abilitare il Deep Learning, impostare enable_dnn=True nell'oggetto AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Avviso
Quando si abilita la rete neurale profonda per gli esperimenti creati con il Software Development Kit, le spiegazioni per il modello migliore sono disabilitate.
Per abilitare la rete neurale profonda per un esperimento di Machine Learning automatizzato creato nello studio di Azure Machine Learning, vedere le impostazioni del tipo di attività nella procedura per l'interfaccia utente dello studio.
Aggregazione della finestra mobile di destinazione
Spesso le informazioni migliori a disposizione di un modulo di previsione sono date dal valore recente della destinazione. Le aggregazioni della finestra mobile di destinazione consentono di aggiungere un'aggregazione mobile di valori di dati come funzionalità. La generazione e l'uso di queste funzionalità come ulteriori dati contestuali contribuiscono all'accuratezza del modello di training.
Si supponga, ad esempio, di voler prevedere la domanda di energia. Si potrebbe voler aggiungere una funzionalità della finestra mobile di tre giorni per tenere conto dei cambiamenti termici degli spazi riscaldati. In questo esempio, creare questa finestra impostando target_rolling_window_size= 3 nel costruttore AutoMLConfig.
La tabella mostra la definizione delle funzionalità risultante che si verifica quando viene applicata l'aggregazione della finestra. Le colonne per minimo, massimo e somma vengono generate in una finestra temporale scorrevole di tre valori in base alle impostazioni definite. Ogni riga ha una nuova funzionalità calcolata. Nel caso del timestamp per l'8 settembre 2017 alle ore 4:00, i valori massimo, minimo e somma vengono calcolati usando i valori della domanda per l'8 settembre 2017 tra l'1:00 e le 3:00. Questa finestra su base tre scorre in avanti per popolare i dati per le righe rimanenti.

Visualizzare un esempio di codice Python che applica la funzionalità di aggregazione della finestra mobile di destinazione.
Gestione di serie brevi
Machine Learning automatizzato considera una serie temporale come una serie breve se non sono presenti punti dati sufficienti per eseguire le fasi di training e convalida dello sviluppo di modelli. Il numero di punti dati varia per ogni esperimento e dipende da max_horizon, dal numero di suddivisioni di convalida incrociata e dalla lunghezza dell'intervallo di ricerca del modello, ovvero il massimo di dati cronologici necessari per costruire le funzionalità della serie temporale.
Machine Learning automatizzato offre la gestione di serie brevi per impostazione predefinita con il parametro short_series_handling_configuration nell'oggetto ForecastingParameters.
Per abilitare la gestione di serie brevi, è necessario definire anche il parametro freq. Per definire una frequenza oraria, si imposta freq='H'. Visualizzare le opzioni della stringa di frequenza visitando la sezione sugli oggetti DataOffset della pagina sulle serie temporali di pandas. Per modificare il comportamento predefinito, short_series_handling_configuration = 'auto', aggiornare il parametro short_series_handling_configuration nell'oggetto ForecastingParameter.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
La tabella seguente riepiloga le impostazioni disponibili per short_series_handling_config.
| Impostazione | Descrizione |
|---|---|
auto |
Valore predefinito per la gestione di serie brevi. - Se tutte le serie sono brevi, eseguire il riempimento dei dati. - Se non tutte le serie sono brevi, eliminare le serie brevi. |
pad |
Se short_series_handling_config = pad, Machine Learning automatizzato aggiunge valori casuali a ogni serie breve trovata. Di seguito sono elencati i tipi di colonna e gli elementi con cui vengono riempiti: - Colonne oggetto con valori "non un numero" - Colonne numeriche con 0 - Colonne booleane/logiche con False - La colonna di destinazione viene riempita con valori casuali con media zero e deviazione standard pari a 1. |
drop |
Se short_series_handling_config = drop, Machine Learning automatizzato elimina la serie breve e non verrà usata per il training o la previsione. Le previsioni per queste serie restituiranno valori "non un numero". |
None |
Nessuna serie viene riempita o eliminata |
Avviso
Il riempimento può influire sull'accuratezza del modello risultante, poiché vengono introdotti dati artificiali solo per superare il training senza errori. Se molte delle serie sono brevi, si potrebbe verificare un certo impatto anche nei risultati di spiegabilità
Rilevamento e gestione di serie temporali non stazionarie
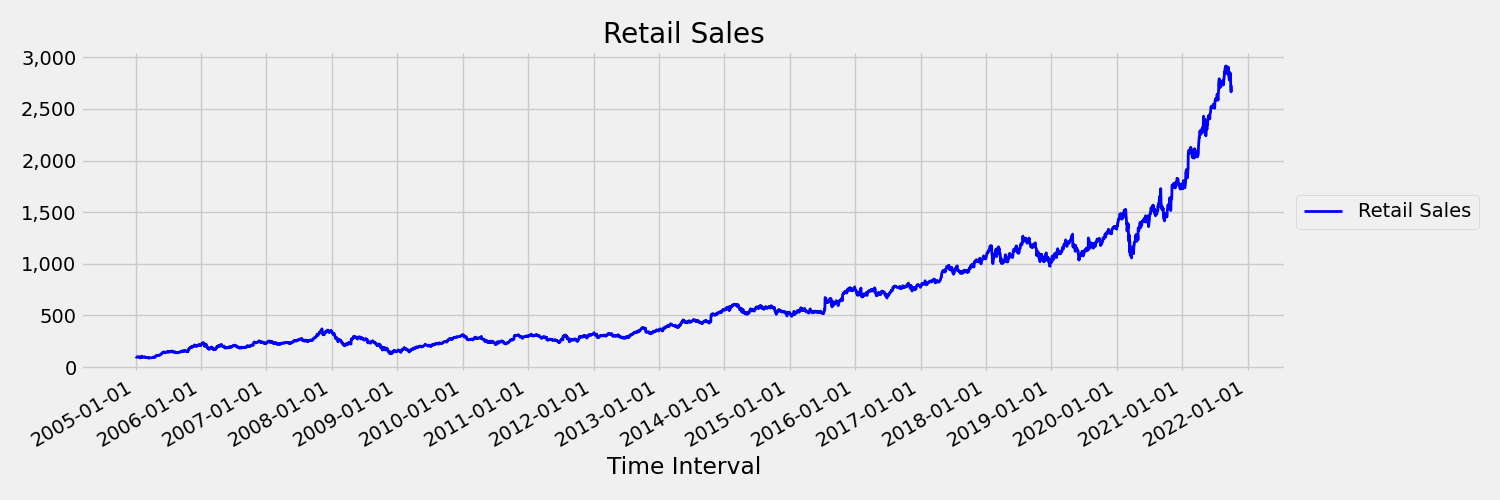
Una serie temporale i cui momenti, media e varianza, cambiano nel tempo viene chiamata non stazionaria. Ad esempio, le serie temporali che presentano tendenze stocastiche non sono stazionarie per natura. Per visualizzare questo concetto, l'immagine seguente mostra il tracciato di una serie che tende generalmente verso l'alto. A questo punto, calcolare e confrontare i valori medi (media) per la prima e la seconda metà della serie. Coincidono? In questo caso, la media della serie nella prima metà del tracciato è significativamente inferiore rispetto alla seconda metà. Il fatto che la media della serie dipende dall'intervallo di tempo che si sta esaminando è un esempio dei momenti variabili nel tempo. Qui, la media di una serie è il primo momento.
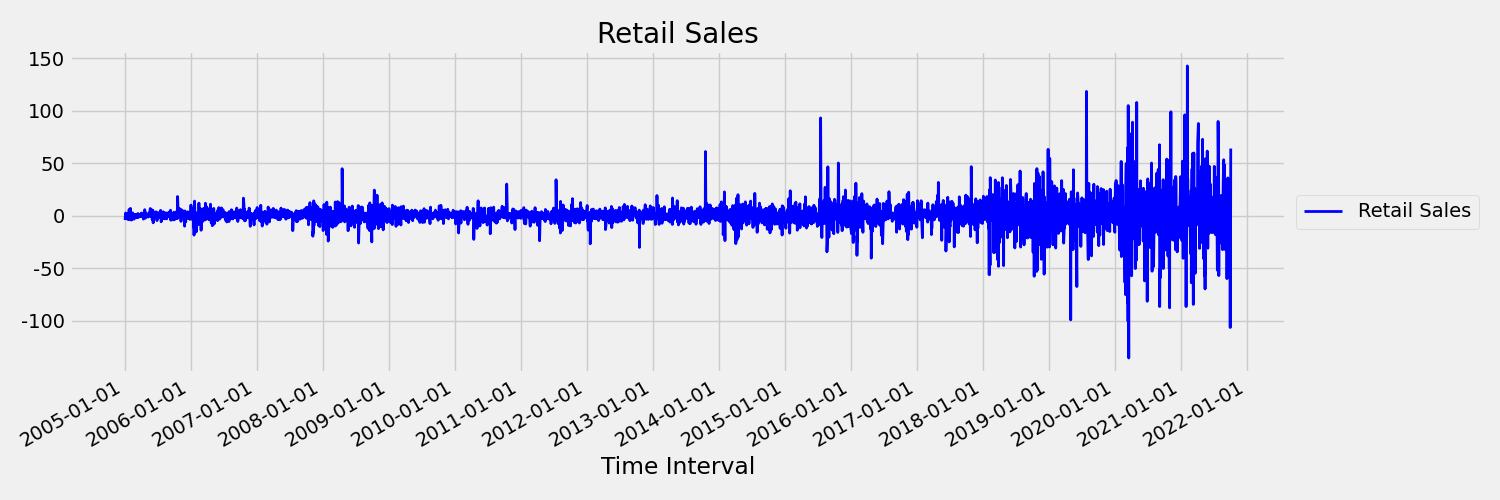
Esaminare ora l'immagine seguente, che traccia la serie originale nelle prime differenze, $x_t = y_t - y_{t-1}$ dove $x_t$ è rispettivamente il cambiamento delle vendite al dettaglio e $y_t$ e $y_{t-1}$ rappresentano rispettivamente la serie originale e il suo primo ritardo. La media della serie è approssimativamente costante, indipendentemente dall'intervallo di tempo esaminato. Questo è un esempio di una serie temporale stazionaria di primo ordine. Il motivo per cui è stato aggiunto il termine di primo ordine è che il primo momento (media) non cambia con l'intervallo di tempo. Lo stesso non può essere detto sulla varianza, che è un secondo momento.
I modelli di Machine Learning di Machine Learning automatizzato non sono intrinsecamente in grado di gestire le tendenze stocastiche o altri problemi noti associati a serie temporali non stazionarie. Di conseguenza, l'accuratezza delle previsioni fuori campione può essere scarsa in presenza di tali tendenze.
Machine Learning automatizzato analizza automaticamente il set di dati della serie temporale per verificare se è o non è stazionaria. Quando vengono rilevate serie temporali non stazionarie, AutoML applica automaticamente una trasformazione differenziante per attenuare l'effetto di serie temporali non fisse.
Eseguire l'esperimento
Quando l'oggetto AutoMLConfig è pronto, è possibile inviare l'esperimento. Al termine del modello, recuperare l'iterazione di esecuzione migliore.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Eseguire previsioni con il modello migliore
Usare l'iterazione del modello migliore per prevedere i valori per i dati non usati per eseguire il training del modello.
Valutare l'accuratezza del modello con una previsione in sequenza
Prima di inserire un modello in produzione, è necessario valutarne l'accuratezza in un set di test escluso dai dati di training. Una procedura consigliata è la cosiddetta valutazione in sequenza, che fa avanzare nel tempo il modulo di previsione sottoposto a training nel set di test, calcolando la media delle metriche di errore in diverse finestre di previsione per ottenere stime statisticamente affidabili per alcuni set di metriche scelte. Idealmente, il set di test per la valutazione è lungo rispetto all'orizzonte di previsione del modello. Le stime dell'errore di previsione potrebbero altrimenti essere statisticamente poco significative e, pertanto, meno affidabili.
Si supponga, ad esempio, di eseguire il training di un modello sulle vendite giornaliere per prevedere la domanda fino a due settimane (14 giorni) nel futuro. Se sono disponibili dati cronologici sufficienti, è possibile riservare i mesi finali, fino a un anno di dati, per il set di test. La valutazione in sequenza inizia generando una previsione di 14 giorni per le prime due settimane del set di test. Il modulo di previsione viene quindi fatto avanzare di un certo numero di giorni nel set di test e si generano altre previsioni di 14 giorni dalla nuova posizione. Il processo continua fino alla fine del set di test.
Per eseguire una valutazione in sequenza, chiamare il metodo rolling_forecast di fitted_model, quindi calcolare le metriche desiderate sul risultato. Si supponga, ad esempio, di avere funzionalità del set di test in un DataFrame pandas denominata test_features_df e i valori effettivi del set di test della destinazione in una matrice numpy denominata test_target. Una valutazione in sequenza che usa l'errore quadratico medio è illustrata nell'esempio di codice seguente:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
In questo esempio, le dimensioni del passaggio per la previsione in sequenza vengono impostate su uno, il che significa che a ogni iterazione il modulo di previsione viene fatto avanzare di un periodo, o un giorno nell'esempio di previsione della domanda. Il numero totale di previsioni restituite da rolling_forecast dipende quindi dalla lunghezza del set di test e dalle dimensioni di questo passaggio. Per altri dettagli ed esempi, vedere la documentazione di rolling_forecast() e il notebook sulla previsione oltre i dati di training.
Previsione nel futuro
La funzione forecast_quantiles() consente di specificare quando iniziare le previsioni, a differenza del metodo predict(), che in genere viene usato per le attività di classificazione e regressione. Per impostazione predefinita, il metodo forecast_quantiles() genera una previsione puntuale o una previsione media/mediana che non ha un alone di incertezza. Per altre informazioni, vedere il notebook sulla previsione oltre i dati di training.
Nell'esempio seguente vengono innanzitutto sostituiti tutti i valori di y_pred con NaN. In questo caso, l'origine della previsione è alla fine dei dati di training. Se, tuttavia, si sostituisce solo la seconda metà di y_pred con NaN, la funzione lascia i valori numerici nella prima metà non modificati, ma prevede i valori NaN nella seconda metà. La funzione restituisce sia i valori previsti, che le funzionalità allineate.
È anche possibile usare il parametro forecast_destination nella funzione forecast_quantiles() per prevedere i valori fino a una data specificata.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Spesso i clienti vogliono comprendere le previsioni in base a un quantile specifico della distribuzione. Ad esempio, quando la previsione viene usata per controllare un inventario di generi alimentari o di macchine virtuali per un servizio cloud. In questi casi, il punto di controllo è in genere simile a "vogliamo che l'articolo sia in magazzino e non esaurito il 99% del tempo". Di seguito viene illustrato come specificare i quantili da visualizzare per le previsioni, ad esempio il 50° o il 95° percentile. Se non si specifica un quantile, come nell'esempio di codice precedente, vengono generate solo le stime del 50° percentile.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
È possibile calcolare le metriche del modello, ad esempio, la radice dell'errore quadratico medio (RMSE) o l'errore assoluto medio percentuale (MAPE) per stimare le prestazioni dei modelli. Per un esempio, vedere la sezione Evaluate del notebook sulla domanda di bike sharing.
Dopo aver determinato l'accuratezza complessiva del modello, il passaggio successivo più realistico consiste nell'usare il modello per prevedere valori futuri sconosciuti.
Fornire un set di dati nello stesso formato del set di test test_dataset, ma con datetime futuri e il set di stime risultante, corrisponde ai valori previsti per ogni passaggio della serie temporale. Si supponga che gli ultimi record della serie temporale nel set di dati si riferiscano al giorno 31/12/2018. Per prevedere la domanda per il giorno successivo, o per tutti i periodi necessari per la previsione, <= forecast_horizon, creare un singolo record della serie temporale per ogni negozio per 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Ripetere i passaggi necessari per caricare i dati futuri in un dataframe e quindi eseguire best_run.forecast_quantiles(test_dataset) per stimare i valori futuri.
Nota
Le previsioni sul campione non sono supportate per la previsione con Machine Learning automatizzato quando target_lags e/o target_rolling_window_size sono abilitati.
Previsione su larga scala
Esistono scenari in cui un singolo modello di Machine Learning è insufficiente e sono necessari più modelli di Machine Learning. Ad esempio, prevedere le vendite per ogni singolo negozio di un marchio o personalizzare un'esperienza per i singoli utenti. La creazione di un modello per ogni istanza può produrre risultati migliori in molti problemi di Machine Learning.
Il raggruppamento è un concetto nella previsione di serie temporali che consente di combinare serie temporali per eseguire il training di un singolo modello per gruppo. Questo approccio può essere particolarmente utile se si dispone di serie temporali che richiedono lo smoothing o il riempimento o se sono presenti entità nel gruppo che possono trarre vantaggio dalla cronologia o dalle tendenze di altre entità. Molti modelli e previsione di serie temporali gerarchiche sono soluzioni basate su Machine Learning automatizzato per questi scenari di previsione su larga scala.
Molti modelli
La soluzione molti modelli di Azure Machine Learning con Machine Learning automatizzato consente agli utenti di eseguire il training e la gestione di milioni di modelli in parallelo. L'acceleratore di soluzione molti modelli, sfrutta le pipeline di Azure Machine Learning per eseguire il training del modello. In particolare, vengono usati un oggetto Pipeline e ParallelRunStep e richiedono parametri di configurazione specifici impostati tramite ParallelRunConfig.
Il diagramma seguente illustra il flusso di lavoro per la soluzione molti modelli.

Il codice seguente illustra i parametri chiave che gli utenti devono configurare per l’esecuzione molti modelli. Per un esempio di previsione molti modelli, vedere il notebook Many Models di Machine Learning automatizzato
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Previsione di serie temporali gerarchiche
Nella maggior parte delle applicazioni, i clienti hanno la necessità di comprendere le previsioni a livello macroscopico e microscopico dell'azienda. Le previsioni possono prevedere le vendite di prodotti in diverse posizioni geografiche o comprendere la domanda prevista di forza lavoro per organizzazioni diverse in un'azienda. La possibilità di eseguire il training di un modello di Machine Learning per prevedere in modo intelligente i dati gerarchici è essenziale.
Una serie temporale gerarchica è una struttura in cui ogni serie univoca viene disposta in una gerarchia in base alle dimensioni, ad esempio area geografica o tipo di prodotto. L'esempio seguente mostra i dati con attributi univoci che formano una gerarchia. La gerarchia è definita dal tipo di prodotto, ad esempio cuffie o tablet, dalla categoria di prodotto, che suddivide i tipi di prodotto in accessori e dispositivi, e dall'area geografica in cui vengono venduti i prodotti.

Per visualizzarlo ancora meglio, i livelli foglia della gerarchia contengono tutte le serie temporali con combinazioni univoche di valori di attributo. Ogni livello superiore nella gerarchia considera una dimensione meno per definire la serie temporale e aggrega ogni set di nodi figlio dal livello inferiore in un nodo padre.

La soluzione di serie temporale gerarchica si basa sulla soluzione molti modelli e condivide una configurazione simile.
Il codice seguente illustra i parametri chiave per configurare le esecuzioni di previsioni delle serie temporali gerarchiche. Per un esempio end-to-end, vedere il notebook per le serie temporali gerarchiche di Machine Learning automatizzato.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Notebook di esempio
Per esempi di codice dettagliati sulla configurazione di previsione avanzata, vedere i notebook di esempio della previsione, tra cui:
- Rilevamento festività e definizione delle funzionalità
- Convalida incrociata dell'origine in sequenza
- Ritardi configurabili
- Funzionalità di aggregazione della finestra mobile
Passaggi successivi
- Altre informazioni su Come distribuire un modello di Machine Learning automatizzato in un endpoint online.
- Informazioni sull'Interpretabilità: spiegazioni del modello in Machine Learning automatizzato (anteprima).
- Informazioni su Come Machine Learning automatizzato compila modelli di previsione.