Autorizzazione negli endpoint batch
Gli endpoint batch supportano l'autenticazione di Microsoft Entra o aad_token. Ciò significa che per richiamare un endpoint batch, l'utente deve presentare un token di autenticazione Microsoft Entra valido all'URI dell'endpoint batch. L'autorizzazione viene applicata a livello di endpoint. L'articolo seguente illustra come interagire correttamente con gli endpoint batch e i requisiti di sicurezza.
Funzionamento dell’autorizzazione
Per richiamare un endpoint batch, l'utente deve presentare un token di Microsoft Entra valido che rappresenta un'entità di sicurezza. Questa entità può essere un'entità utente o un'entità servizio. In ogni caso, una volta richiamato un endpoint, viene creato un processo di distribuzione batch con l'identità associata al token. Per creare correttamente un processo, l'identità deve disporre delle autorizzazioni seguenti:
- Lettura endpoint/distribuzioni batch.
- Creazione di processi in endpoint/distribuzione di inferenza batch.
- Creazione di esperimenti/esecuzioni.
- Lettura e scrittura da/in archivi dati.
- Creare un elenco dei segreti dell'archivio dati.
Per un elenco dettagliato delle autorizzazioni di controllo degli accessi in base al ruolo, vedere Configurare il controllo degli accessi in base al ruolo per il richiamo degli endpoint batch.
Importante
L'identità usata per richiamare un endpoint batch potrebbe non essere usata per leggere i dati sottostanti a seconda della configurazione dell'archivio dati. Per altre informazioni, vedere Configurare i cluster di elaborazione per l'accesso ai dati.
Come eseguire processi usando diversi tipi di credenziali
Gli esempi seguenti illustrano diversi modi per avviare processi di distribuzione batch usando diversi tipi di credenziali:
Importante
Quando si lavora su aree di lavoro abilitate per il collegamento privato, gli endpoint batch non possono essere richiamati dall'interfaccia utente nello studio di Azure Machine Learning. Usare invece l'interfaccia della riga di comando di Azure Machine Learning v2 per la creazione di processi.
Prerequisiti
- Questo esempio presuppone che sia stato distribuito correttamente un modello come endpoint batch. In particolare, viene usato il classificatore di condizioni cardiache creato nell'esercitazione Uso di modelli MLflow nelle distribuzioni batch.
Esecuzione di processi con le credenziali dell'utente
In questo caso, si vuole eseguire un endpoint batch usando l'identità dell'utente attualmente connesso. Seguire questa procedura:
Usare l'interfaccia della riga di comando di Azure per accedere usando l'autenticazione interattiva o del codice del dispositivo:
az loginDopo l'autenticazione, usare il comando seguente per eseguire un processo di distribuzione batch:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Esecuzione di processi con un'entità servizio
In questo caso, si vuole eseguire un endpoint batch usando un'entità servizio già creata in Microsoft Entra ID. Per completare il processo, è necessario creare un segreto per eseguire l'autenticazione. Seguire questa procedura:
Creare un segreto da usare per l'autenticazione come illustrato in Opzione 3: Creare un nuovo segreto client.
Per eseguire l'autenticazione con un'entità servizio, usare il comando seguente. Per altri dettagli, vedere Accedere tramite l'interfaccia della riga di comando di Azure.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>Dopo l'autenticazione, usare il comando seguente per eseguire un processo di distribuzione batch:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
Esecuzione di processi con un'identità gestita
È possibile usare le identità gestite per richiamare endpoint e distribuzioni batch. Si noti che questa identità di gestione non appartiene all'endpoint batch, ma è l'identità usata per eseguire l'endpoint e quindi creare un processo batch. In questo scenario è possibile usare sia le identità assegnate dall'utente che le identità assegnate dal sistema.
Per le risorse di Azure configurate per le identità gestite, è possibile effettuare l'accesso usando l'identità gestita. L'accesso con l'identità della risorsa viene eseguito tramite il flag --identity. Per altri dettagli, vedere Accedere tramite l'interfaccia della riga di comando di Azure.
az login --identity
Dopo l'autenticazione, usare il comando seguente per eseguire un processo di distribuzione batch:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Configurare il controllo degli accessi in base al ruolo per richiamare gli endpoint batch
Gli endpoint batch espongono un API durevole che i consumer possono usare per generare processi. L'invoker richiede l'autorizzazione appropriata per poter generare tali processi. È possibile usare uno dei ruoli di sicurezza predefiniti oppure creare un ruolo personalizzato ai fini.
Per richiamare correttamente un endpoint batch, sono necessarie le seguenti azioni esplicite concesse all'identità usata per richiamare gli endpoint. Per istruzioni su come assegnarle, vedere Passaggi per assegnare un ruolo di Azure.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
Configurare i cluster di elaborazione per l'accesso ai dati
Gli endpoint batch assicurano che solo gli utenti autorizzati siano in grado di richiamare distribuzioni batch e generare processi. Tuttavia, a seconda della configurazione dei dati di input, sarebbe possibile usare altre credenziali per leggere i dati sottostanti. Usare la tabella seguente per comprendere quali credenziali vengono usate:
| Tipo di input dati | Credenziali nell'archivio | Credenziali usate | Accesso concesso da |
|---|---|---|---|
| Archivio dati | Sì | Credenziali dell'archivio dati nell'area di lavoro | Chiave di accesso o firma di accesso condiviso |
| Asset di dati | Sì | Credenziali dell'archivio dati nell'area di lavoro | Chiave di accesso o firma di accesso condiviso |
| Archivio dati | No | Identità del processo e identità gestita del cluster di elaborazione | RBAC |
| Asset di dati | No | Identità del processo e identità gestita del cluster di elaborazione | RBAC |
| Archiviazione BLOB di Azure | Non applicabile | Identità del processo e identità gestita del cluster di elaborazione | RBAC |
| Azure Data Lake Storage Gen1 | Non applicabile | Identità del processo e identità gestita del cluster di elaborazione | POSIX |
| Azure Data Lake Storage Gen2 | Non applicabile | Identità del processo e identità gestita del cluster di elaborazione | POSIX e controllo degli accessi in base al ruolo |
Per tali elementi nella tabella in cui viene visualizzata l'identità del processo e l'identità gestita del cluster di elaborazione, l'identità gestita del cluster di elaborazione viene usata per il montaggio e la configurazione degli account di archiviazione. Tuttavia, l'identità del processo viene comunque usata per leggere i dati sottostanti, consentendo di ottenere un controllo di accesso granulare. Ciò significa che per leggere correttamente i dati di archiviazione, l'identità gestita del cluster di elaborazione in cui la distribuzione è in esecuzione deve avere almeno l'accesso al Lettore dei dati del Blob di archiviazione sull'account di archiviazione.
Per configurare il cluster di elaborazione per l'accesso ai dati, procedere come segue:
Andare a studio di Azure Machine Learning.
Andare a Calcolo, quindi Cluster di elaborazionee selezionare il cluster di elaborazione usato dalla distribuzione.
Assegnare un'identità gestita al cluster di elaborazione:
Nella sezioneIdentità gestita verificare se al calcolo è assegnata un'identità gestita. In caso contrario, selezionare l'opzione Modifica.
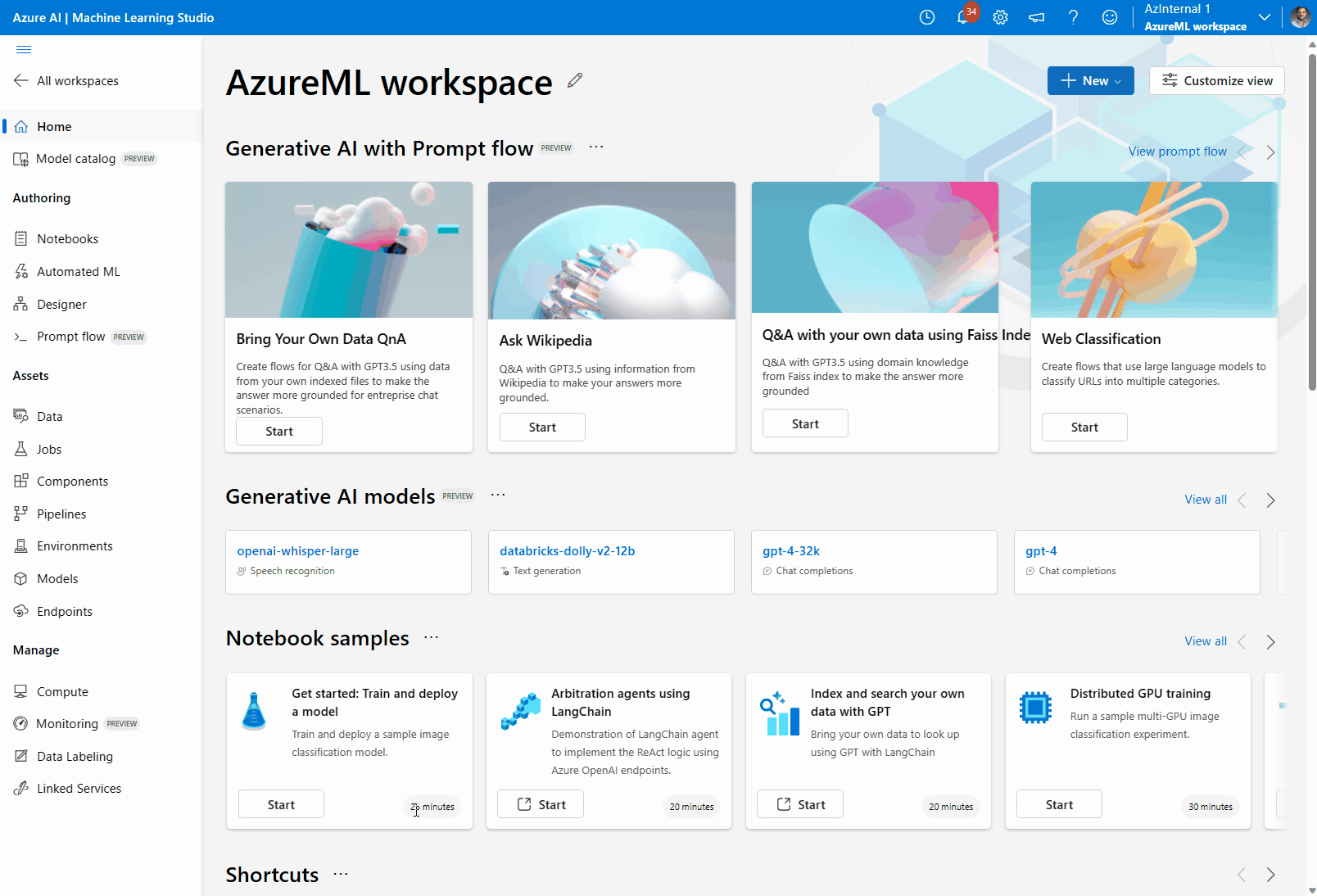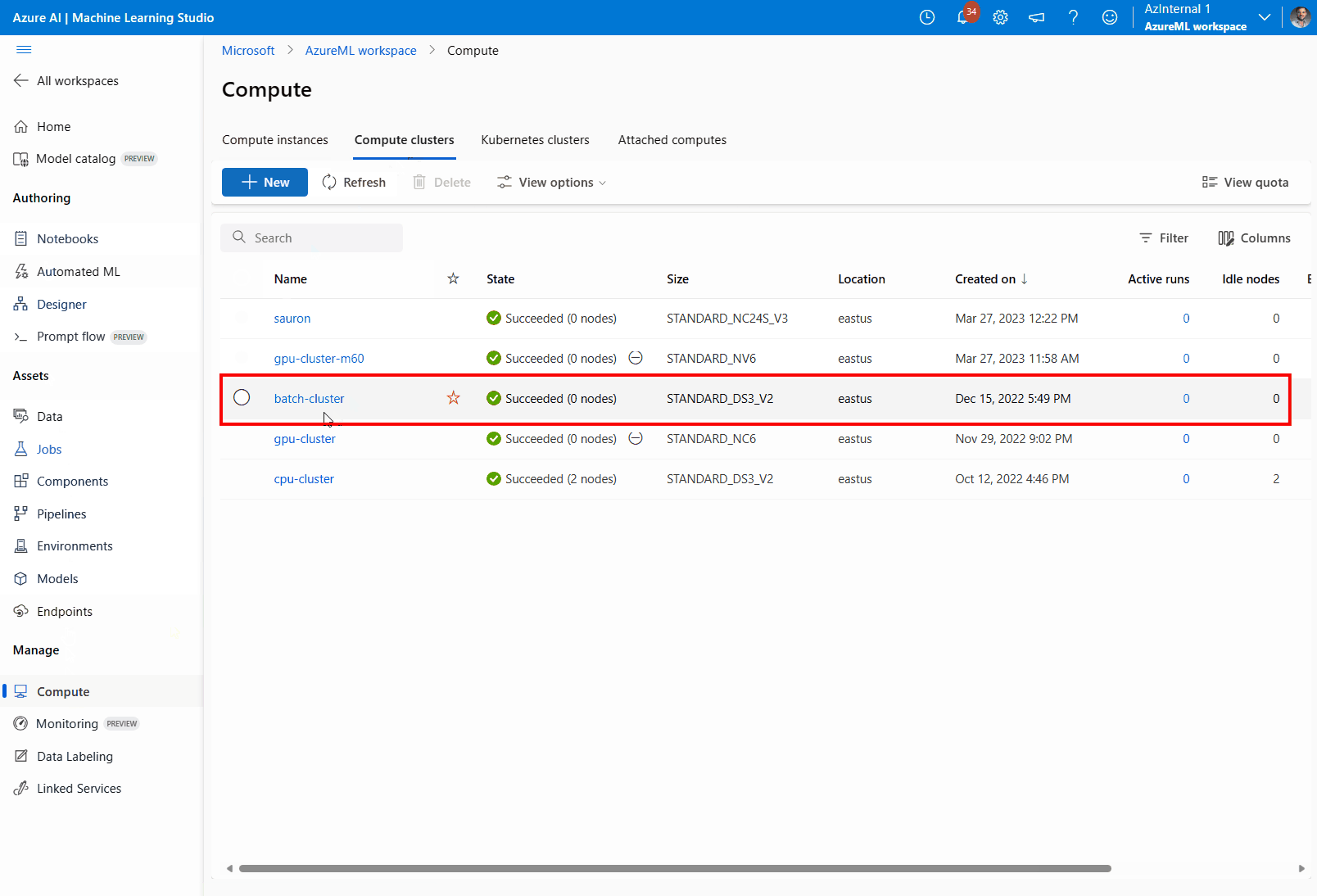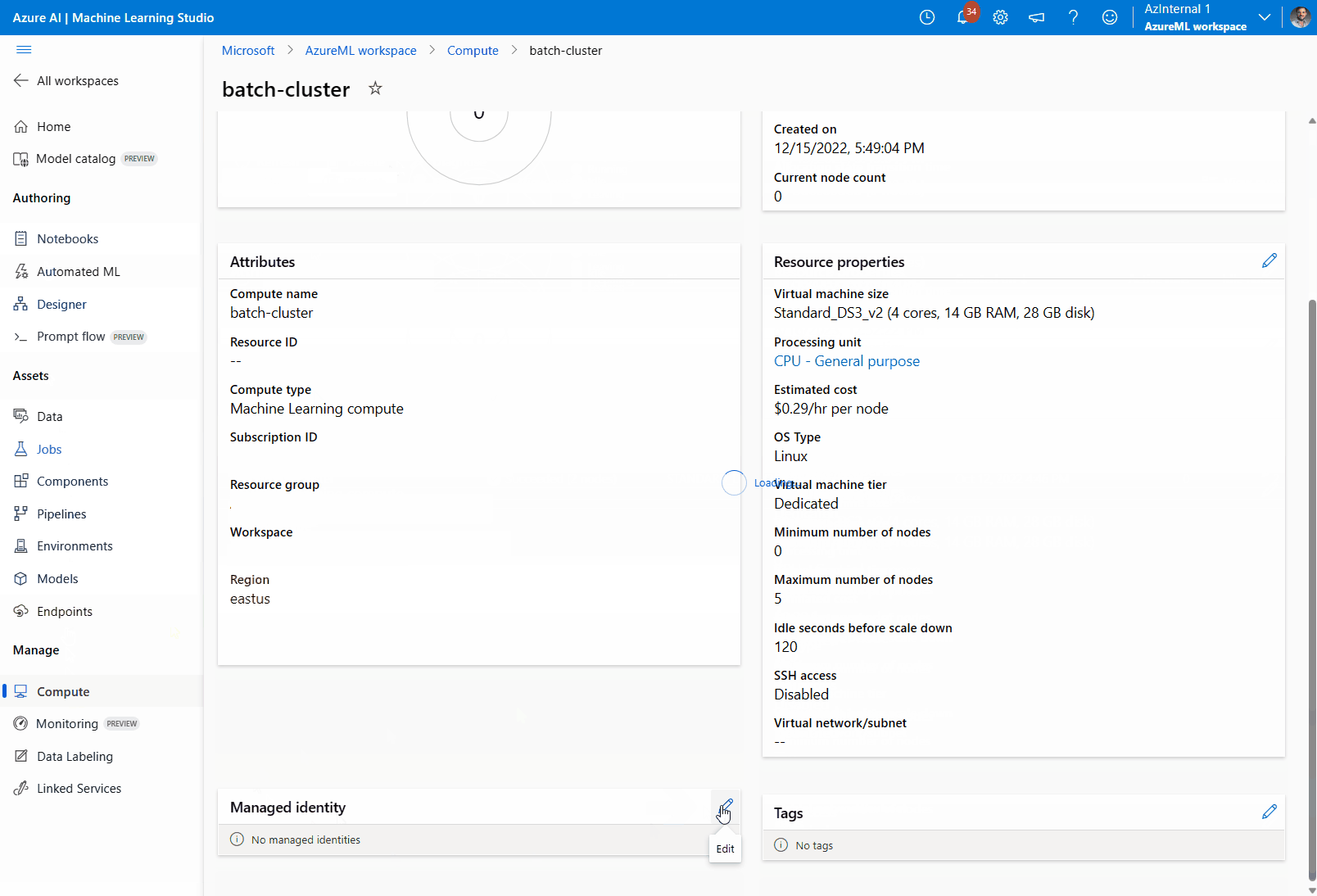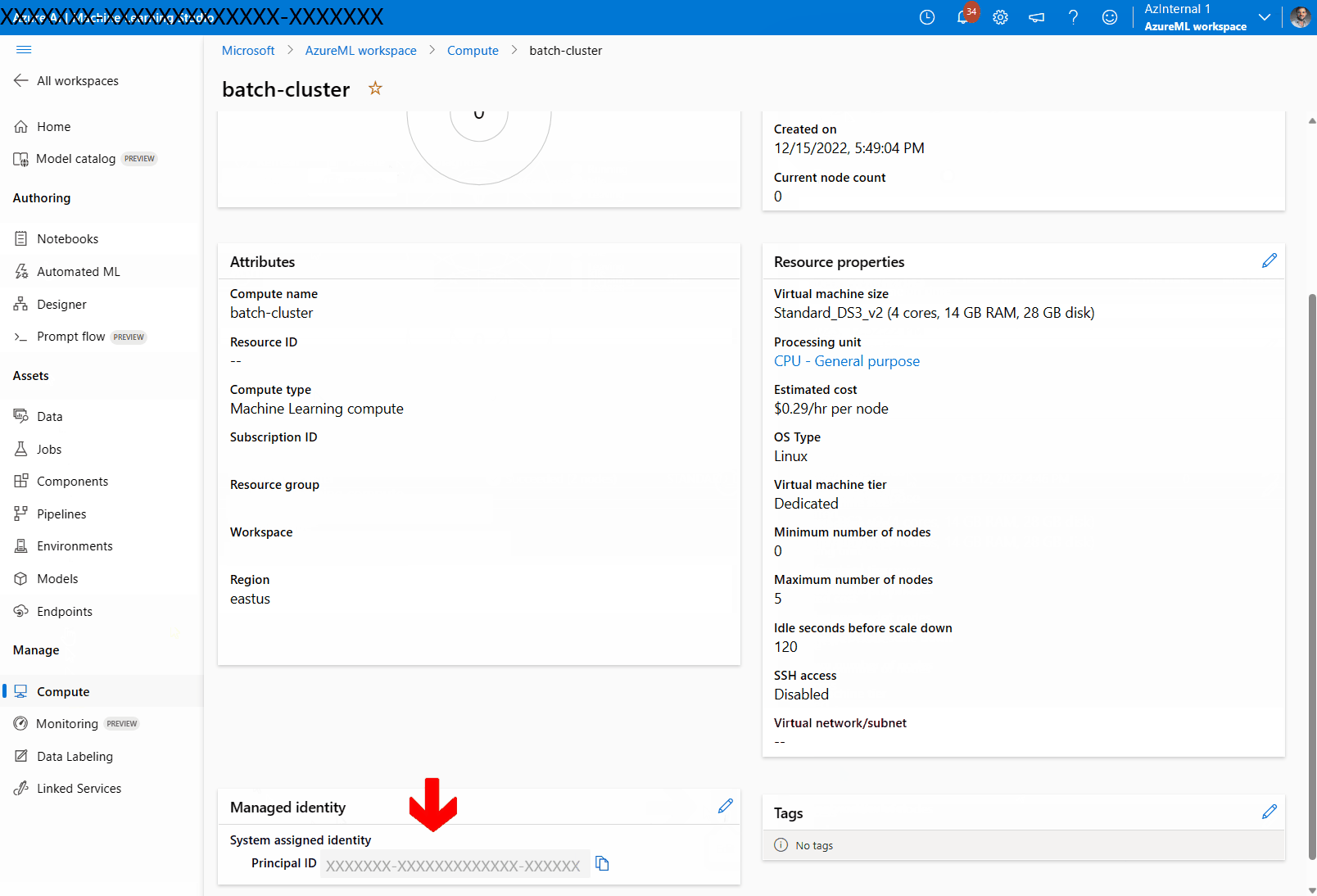
Selezionare Assegna un'identità gestita e configurarla in base alle esigenze. È possibile usare un'identità gestita assegnata dal sistema o un'identità gestita assegnata dall'utente. Se si usa un'identità gestita assegnata dal sistema, viene denominata "[nome dell'area di lavoro]/computes/[nome del cluster di elaborazione]".
Salvare le modifiche.
Andare al portale di Azure, quindi andare all'account di archiviazione associato in cui si trovano i dati. Se l'input dei dati è un asset di dati o un archivio dati, cercare l'account di archiviazione in cui vengono inseriti tali asset.
Assegnare il livello di accesso lettore di dati del Blob di archiviazione nell'account di archiviazione:
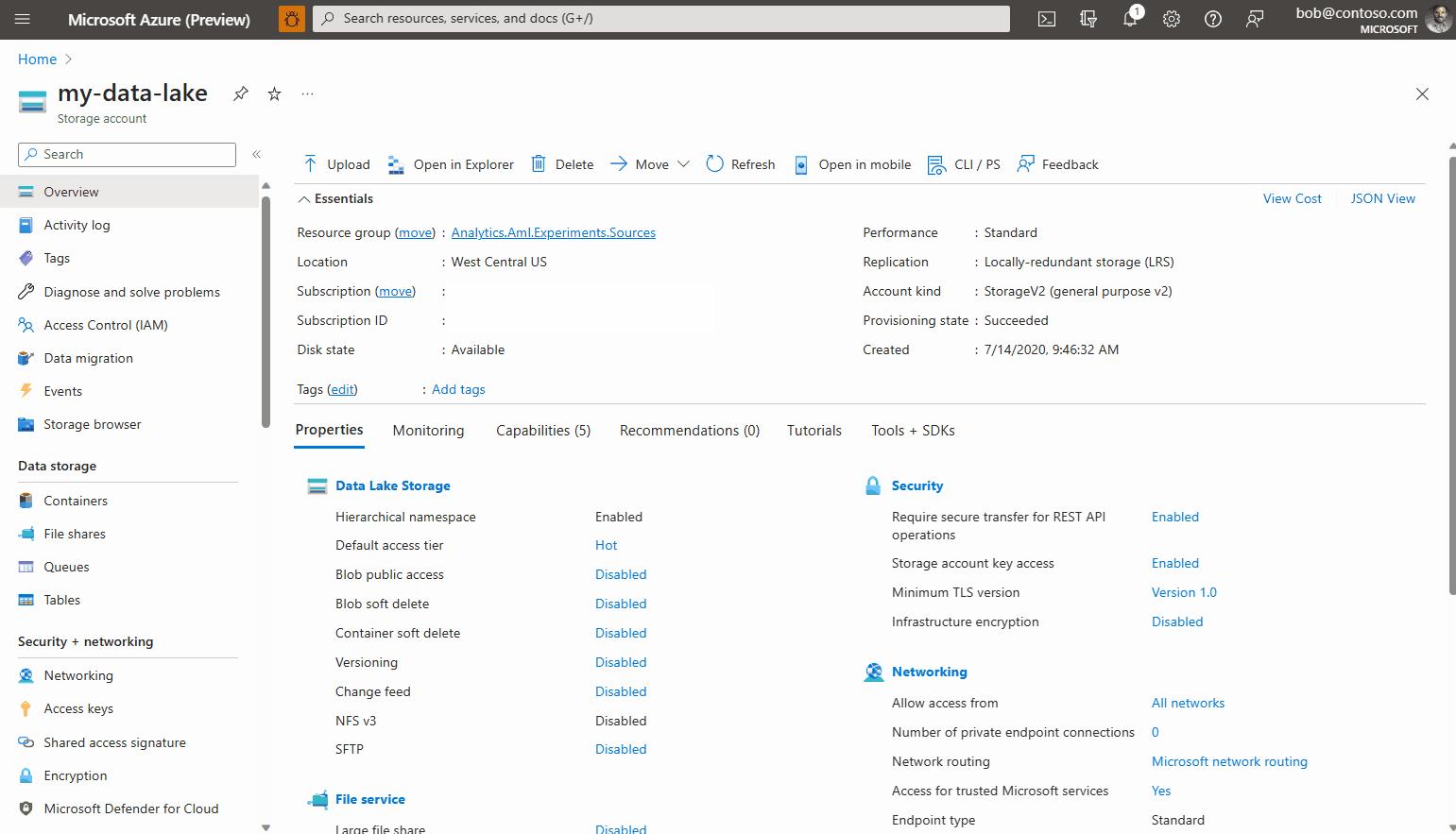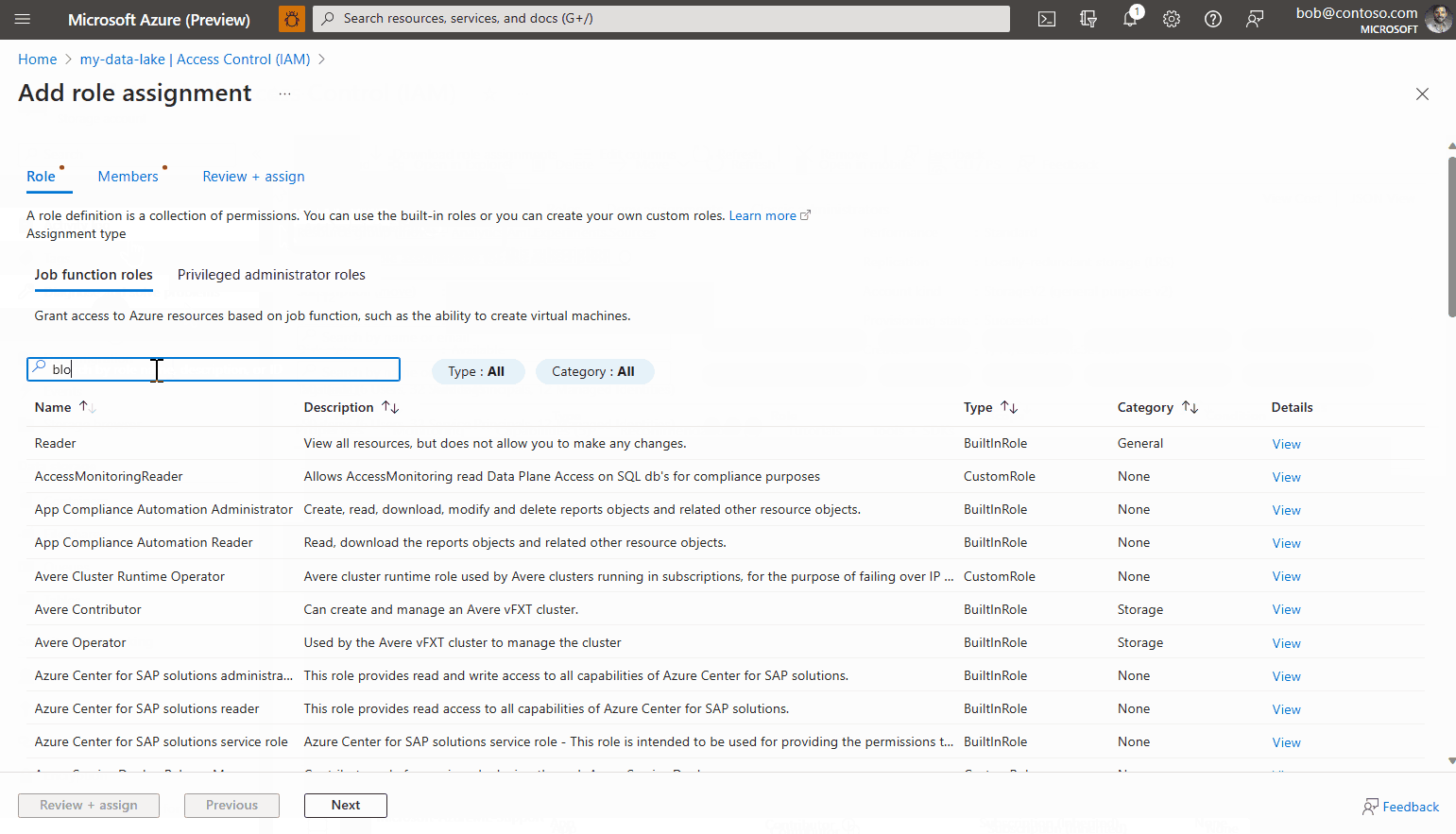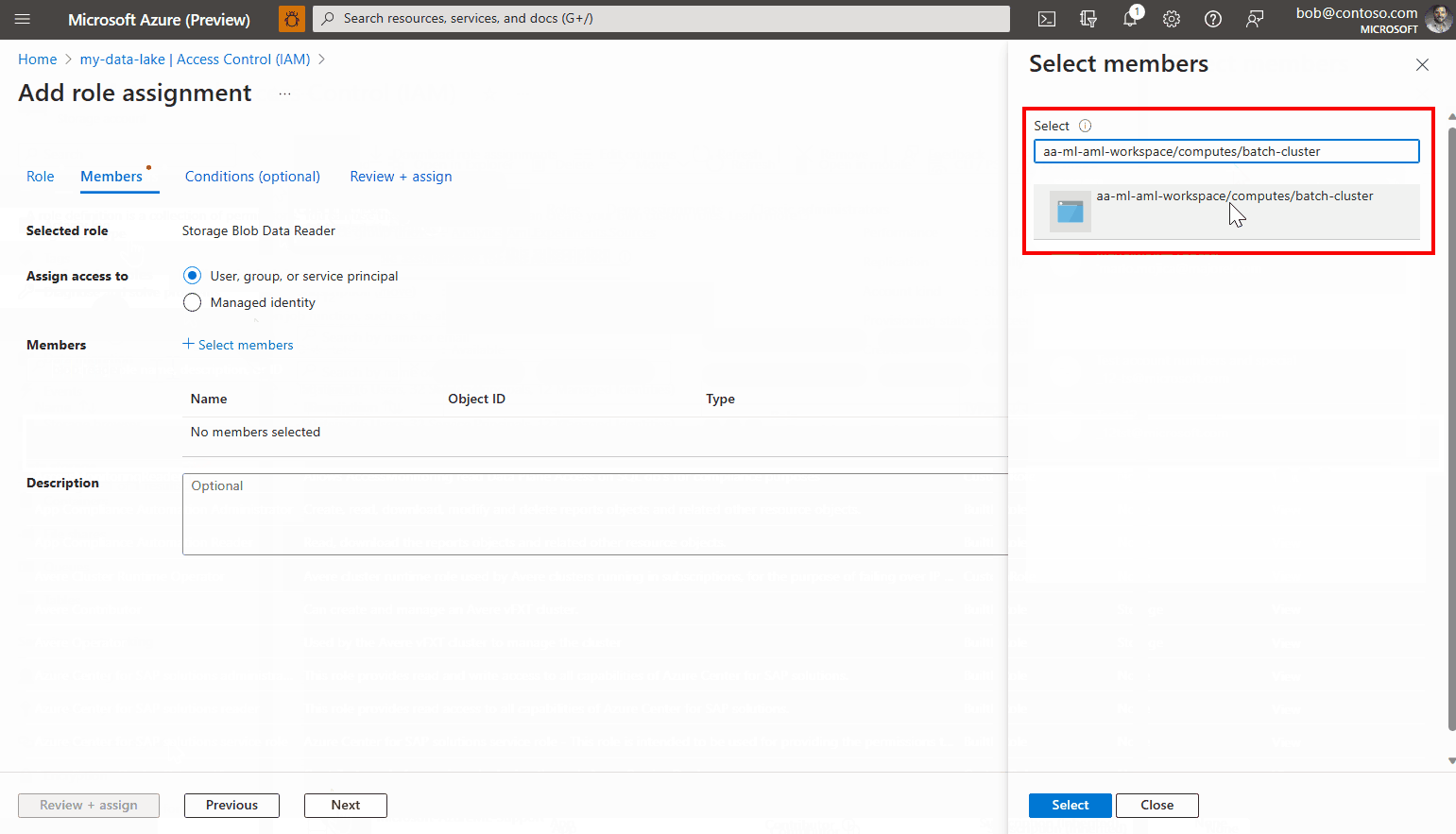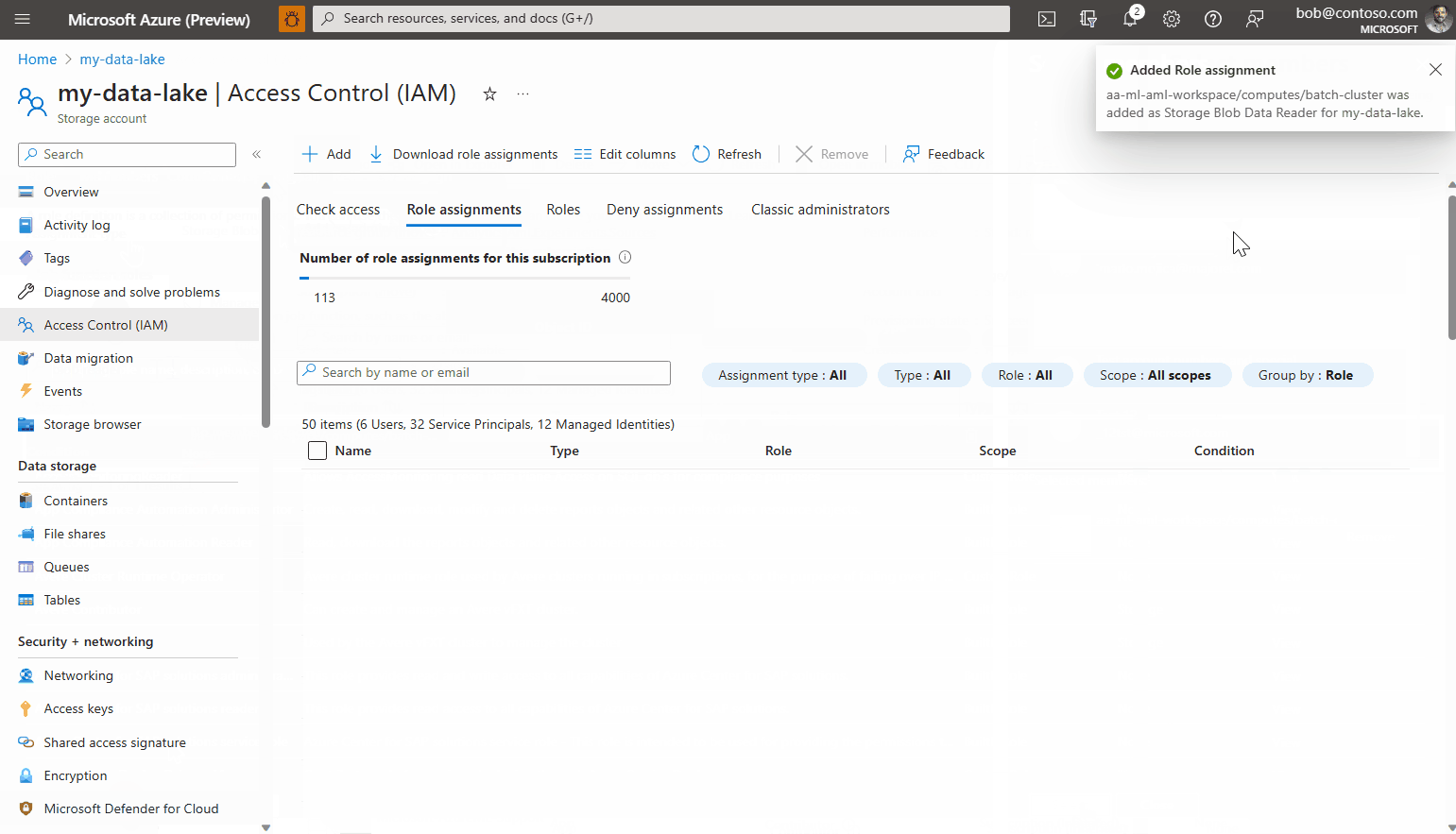
Andare alla sezione Controllo di accesso (IAM).
Selezionare la scheda Assegnazione di ruolo, quindi fare clic su Aggiungi>Assegnazione di ruolo.
Cercare il ruolo denominato Lettore di dati del Blob di archiviazione, selezionarlo e fare clic su Avanti.
Fare clic su Seleziona membri.
Cercare l'identità gestita creata. Se si usa un'identità gestita assegnata dal sistema, viene denominata "[nome dell'area di lavoro]/computes/[nome del cluster di elaborazione]".
Aggiungere l'account e completare la procedura guidata.
L'endpoint è pronto per ricevere processi e dati di input dall'account di archiviazione selezionato.