Data science con una Data Science Virtual Machine per Windows
La Data Science Virtual Machine (DSVM) per Windows è un ambiente di sviluppo di analisi scientifica dei dati avanzato che supporta diverse attività di esplorazione e modellazione dati. L'ambiente è precompilato e già abbinato in bundle con diversi strumenti comuni di analisi dei dati che consentono di usare facilmente l'analisi per le distribuzioni locali, cloud o ibride.
La DSVM interagisce strettamente con i servizi di Azure. È in grado di leggere ed elaborare i dati già archiviati in Azure, in Azure Synapse (in precedenza SQL DW), Azure Data Lake, Archiviazione di Azure o Azure Cosmos DB. È anche in grado di utilizzare altri strumenti di analisi, ad esempio Azure Machine Learning.
Questo articolo illustra come usare la DSVM sia per gestire le attività di data science sia per interagire con altri servizi di Azure. Di seguito è riportato un esempio di attività che la DSVM può coprire:
- Usare Jupyter Notebook per sperimentare i dati in un browser usando Python 2, Python 3 e Microsoft R. (Microsoft R è una versione di R di livello Enterprise progettata per le prestazioni elevate).
- Esplorare dati e sviluppare modelli in locale nella DSVM usando Microsoft Machine Learning Server e Python.
- Amministrare le risorse di Azure usando il portale di Azure o PowerShell.
- Estendere lo spazio di archiviazione e condividere codice/set di dati su larga scala con l'intero team con la condivisione File di Azure come unità installabile nella DSVM.
- Condividere il codice con il team con GitHub. Accedere al repository con i client Git preinstallati: Git Bash e Git GUI.
- Accedere a servizi dati e analisi di Azure:
- Archiviazione BLOB di Azure
- Azure Cosmos DB
- Azure Synapse (in precedenza SQL Data Warehouse)
- Database SQL di Azure
- Creare report e un dashboard con l'istanza di Power BI Desktop preinstallata nella DSVM e distribuirli nel cloud.
- Installare altri strumenti nella macchina virtuale.
Nota
Per molti dei servizi di archiviazione e analisi dei dati aggiuntivi elencati in questo articolo vengono applicati costi di utilizzo aggiuntivi. Per altre informazioni, vedi la pagina dei prezzi di Azure.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Una DSVM di cui è stato effettuato il provisioning nel portale di Azure. Per altre informazioni, visitare la risorsa Creazione di una macchina virtuale.
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Usare i notebook di Jupyter Notebook
Jupyter Notebook fornisce un IDE basato su browser per l'esplorazione e la modellazione dei dati. È possibile usare Python 2, Python 3 o R in un Jupyter Notebook.
Per avviare il Jupyter Notebook, selezionare l'icona Jupyter Notebook nel menu Start o sul desktop. Nel prompt dei comandi della DSVM è anche possibile eseguire il comando jupyter notebook dalla directory che ospita altri notebook o dove si vogliono creare nuovi notebook.
Dopo aver avviato Jupyter, passare alla directory /notebooks. Questa directory ospita notebook di esempio preconfezionati nella DSVM. È possibile:
- Selezionare il notebook per visualizzare il codice.
- Selezionare MAIUSC+INVIO per eseguire ogni cella.
- Selezionare Cella>Esegui per eseguire l'intero notebook.
- Creare un nuovo notebook; selezionare l'icona di Jupyter (angolo superiore sinistro), selezionare il pulsante Nuovo e quindi scegliere il linguaggio del notebook (noto anche come kernel).
Nota
Attualmente in Jupyter sono supportati i kernel Python 2.7, Python 3.6, R, Julia e PySpark. Il kernel R supporta la programmazione sia in R open source che in Microsoft R. Nel notebook è possibile esplorare i dati, compilare il modello e testare tale modello con le librerie preferite.
Esplorare i dati e sviluppare modelli con Microsoft Machine Learning Server
Nota
Il supporto per la versione autonoma di Machine Learning Server è terminato il 1° luglio 2021. È stato rimosso dalle immagini DSVM dopo il 30 giugno 2021. Le distribuzioni esistenti possono comunque accedere al software, ma il supporto è terminato il 1° luglio 2021.
È possibile usare R e Python per l'analisi dei dati direttamente nella DSVM.
Per R, è possibile usare R Tools per Visual Studio. Microsoft fornisce altre librerie, oltre alla risorsa CRAN R open source. Queste librerie consentono sia l'analisi scalabile sia la possibilità di analizzare le masse di dati che superano le limitazioni delle dimensioni della memoria dell'analisi parallela in blocchi.
Per Python è possibile usare un IDE, ad esempio Visual Studio Community Edition, in cui è preinstallata l'estensione Python Tools for Visual Studio (PTVS). Per impostazione predefinita, in PTVS è installato solo Python 3.6, l'ambiente root di Conda. Per abilitare Anaconda Python 2.7:
- Creare ambienti personalizzati per ogni versione. Selezionare Strumenti>Strumenti Python>Ambienti Python e quindi selezionare + Personalizzato in Visual Studio Community Edition.
- Immettere una descrizione e impostare il percorso con il prefisso dell'ambiente come c:\anaconda\envs\python2 per Anaconda Python 2.7.
- Selezionare Rilevamento automatico>Applica per salvare l'ambiente.
Per altre informazioni su come creare ambienti Python, vedere la risorsa della documentazione PTVS.
È ora possibile creare un nuovo progetto Python. Selezionare File>Nuovo>Progetto>Python e selezionare il tipo di applicazione Python da compilare. È possibile impostare la versione di ambiente Python desiderata per il progetto corrente, ad esempio Python 2.7 o 3.6, facendo clic con il pulsante destro del mouse su Ambienti Python, e quindi selezionando Aggiungi/Rimuovi ambienti Python. Visitare la documentazione del prodotto per ulteriori informazioni sull'uso di PTVS.
Manage Azure resources (Gestire risorse di Azure)
La DSVM consente di creare la soluzione di analisi in locale nella macchina virtuale. Consente anche di accedere ai servizi nella piattaforma cloud di Azure. Azure offre diversi servizi tra cui calcolo, archiviazione e analisi dei dati e altri amministrabili e accessibili dalla DSVM.
Per amministrare la sottoscrizione di Azure e le risorse cloud, sono disponibili due opzioni:
Visitare il portale di Azure dal browser.
Usare gli script di PowerShell. Eseguire Azure PowerShell da un collegamento desktop o dal menu Start. Per altre informazioni, vedere la risorsa della documentazione di Microsoft Azure PowerShell.
Estendere l'archiviazione usando file system condivisi
I data scientist possono condividere grandi set di dati, codice o alte risorse all'interno del team. La DSVM ha circa 45 GB di spazio disponibile. Per espandere lo spazio di archiviazione, è possibile usare File di Azure e montarlo in una o più istanze della DSVM, oppure accedervi con un'API REST. È inoltre possibile usare il portale di Azure oppure Azure PowerShell per aggiungere altri dischi dati dedicati.
Nota
Lo spazio massimo in una condivisione file di Azure è di 5 TB. Ogni file ha un limite di dimensioni di 1 TB.
Questo script di Azure PowerShell crea una condivisione File di Azure:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
È possibile montare una condivisione File di Azure in qualsiasi macchina virtuale in Azure. È consigliabile inserire la VM e l'account di archiviazione nello stesso data center di Azure per evitare addebiti per latenza e di trasferimento dei dati. Questi comandi di Azure PowerShell montano l'unità nella DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
È possibile accedere a questa unità come a qualsiasi altra unità della VM.
Condividere il codice in GitHub
Il repository di codice GitHub ospita esempi di codice e origini di codice per molti strumenti condivisi dalla Developer Community. Usa Git come tecnologia per tenere traccia delle versioni dei file di codice e per archiviarle. GitHub funge anche da piattaforma per creare un proprio repository. Questo può archiviare il codice condiviso e la documentazione del team, implementare il controllo versione e controllare le autorizzazioni di accesso per gli stakeholder che vogliono visualizzare e contribuire al codice. GitHub supporta la collaborazione all'interno del team, l'uso del codice sviluppato dalla community e i contributi del codice per la community. Per altre informazioni su Git, visitare le pagine della guida di GitHub.
In DSVM sono caricati gli strumenti client nella riga di comando e nella GUI per accedere al repository GitHub. Lo strumento da riga di comando Git Bash funziona con Git e GitHub. Visual Studio è installato in DSVM e include le estensioni Git. Sia il menu Start che il desktop hanno icone per questi strumenti.
Per scaricare il codice da un repository GitHub, usare il comando git clone. Per scaricare il repository di data science pubblicato da Microsoft nella directory corrente, ad esempio, eseguire il comando seguente in Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio può gestire la stessa operazione di clone. Questo screenshot mostra come accedere agli strumenti Git e GitHub in Visual Studio:

È possibile lavorare con le risorse github.com disponibili nel repository GitHub. Per altre informazioni, visitare la risorsa scheda di riferimento rapido di GitHub.
Accedere a servizi dati e analisi di Azure
Archivio BLOB di Azure
Archiviazione BLOB di Azure è un servizio di archiviazione cloud affidabile ed economico per le risorse di dati di grandi e piccole dimensioni. Questa sezione descrive come spostare dati nell'archiviazione Blob di Azure e accedere ai dati archiviati in un BLOB di Azure.
Prerequisiti
Un account di archiviazione BLOB di Azure creato nel portale di Azure.
Verificare che lo strumento AzCopy della riga di comando sia preinstallato; a tal fine usare il comando:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeLa directory che ospita il file azcopy.exe è già definita nella variabile di ambiente PATH, così da evitare all'utente di digitare il percorso completo del comando quando esegue questo strumento. Per altre informazioni sullo strumento AzCopy, leggere la documentazione di AzCopy.
Avviare lo strumento Esplora archivi di Azure. È possibile scaricarla dalla pagina Web di Storage Explorer.


Spostare i dati da una macchina virtuale a un Blob di Azure: AzCopy
Per spostare i dati tra i file locali e l'archiviazione Blob, è possibile usare AzCopy nella riga di comando o in PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Sostituire C:\myfolder con il percorso della directory che ospita il file
- Sostituire mystorageaccount con il nome dell'account di archiviazione BLOB
- Sostituire mycontainer con il nome del contenitore
- Sostituire la chiave dell'account di archiviazione con la chiave di accesso alle risorse di archiviazione BLOB
È possibile trovare le credenziali dell'account di archiviazione nel portale di Azure.
Eseguire il comando AzCopy in PowerShell o dal prompt dei comandi. Di seguito sono riportati esempi di comandi di AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Dopo l'esecuzione del comando AzCopy per copiare il file in un BLOB di Azure, questo viene visualizzato in Azure Storage Explorer.

Spostare i dati da una VM a un Blob di Azure: Azure Storage Explorer
È anche possibile caricare i dati dal file locale nella VM con Azure Storage Explorer:
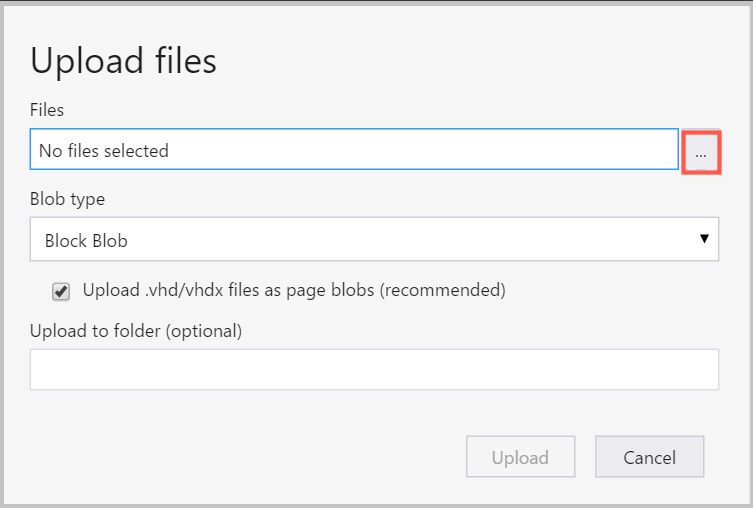
Per caricare dati in un contenitore, selezionare il contenitore di destinazione e selezionare il pulsante Carica.
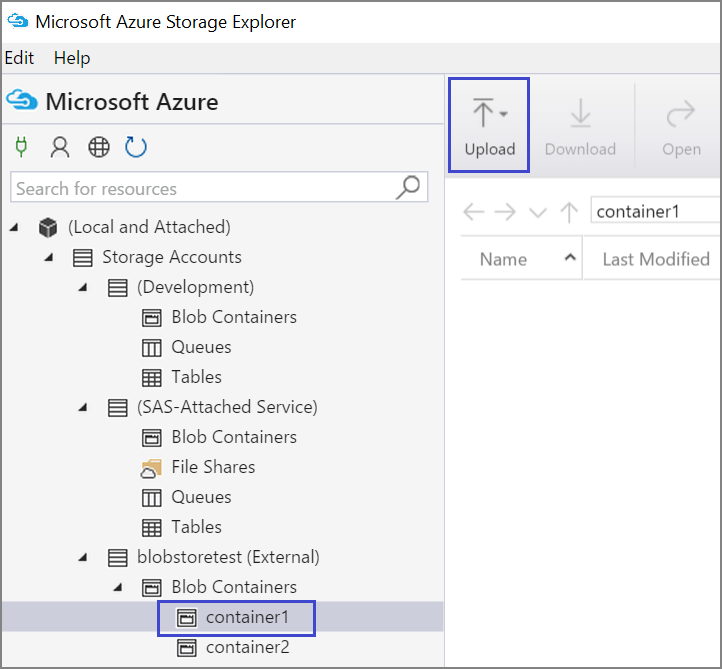
A destra della casella File, selezionare i puntini di sospensione (...), scegliere uno o più file da caricare dal file system e selezionare Carica per iniziare a caricare i file.


Leggere i dati dal Blob di Azure: ODBC Python
La libreria BlobService può leggere i dati direttamente da un BLOB in un Jupyter Notebook o in un programma Python. Prima di tutto importare i pacchetti necessari:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Collegare le credenziali dell'account di archiviazione Blob e leggere i dati dal BLOB:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
I dati vengono letti come frame di dati:

Azure Synapse Analytics e database
Azure Synapse Analytics è un data warehouse elastico distribuito come servizio con un'esperienza di classe Enterprise di SQL Server. Questa risorsa descrive come effettuare il provisioning di Azure Synapse Analytics. Dopo il provisioning di Azure Synapse Analytics, questa procedura dettagliata spiega come gestire il caricamento, l'esplorazione e la modellazione dei dati usando i dati disponibili in Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB è un database NoSQL basato sul cloud. Può gestire documenti JSON, ad esempio, e può archiviare ed eseguire query sui documenti. Questi passi di esempio mostrano come accedere ad Azure Cosmos DB dalla DSVM:
L'SDK di Azure Cosmos DB Python è già installato nella DSVM. Per aggiornarlo, eseguire
pip install pydocumentdb --upgradeda un prompt dei comandi.Creare l'account e il database Azure Cosmos DB nel portale di Azure.
Scaricare lo strumento di migrazione dei dati di Azure Cosmos DB dal Microsoft Download Centre ed estrarlo in una directory di propria scelta.
Importare i dati JSON (dati sui vulcani) archiviati in un BLOB pubblico in Azure Cosmos DB nello strumento di migrazione utilizzando i seguenti parametri di comando. (usare dtui.exe dalla directory di installazione dello strumento di migrazione dei dati di Azure Cosmos DB). Immettere i percorsi di origine e di destinazione con questi parametri:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Dopo aver importato i dati, è possibile passare a Jupyter e aprire il notebook denominato DocumentDBSample. Contiene il codice Python per accedere ad Azure Cosmos DB e gestire alcune query di base. Per altre informazioni su Azure Cosmos DB, vedere la pagina della documentazione del servizio Azure Cosmos DB.
Usare report e dashboard di Power BI
È possibile visualizzare il file JSON Volcano descritto nell'esempio precedente di Azure Cosmos DB in Power BI Desktop per una rappresentazione grafica dettagliata dei dati. Questo articolo di Power BI offre i passi dettagliati. Questi sono i passi, a livello generale:
- Aprire Power BI Desktop e selezionare Ottieni dati. Specificare questo URL:
https://cahandson.blob.core.windows.net/samples/volcano.json. - I record JSON, importati come elenco, dovrebbero diventare visibili. Convertire l'elenco in una tabella in modo che Power BI possa usarli.
- Selezionare l'icona espandi (freccia) per espandere le colonne.
- La posizione è un campo Record. Espandere il record e selezionare solo le coordinate. La coordinata è una colonna elenco.
- Aggiungere una nuova colonna per convertire la colonna di elenco di coordinate in una colonna LatLong delimitata da virgole. Usare la formula
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})per concatenare i due elementi nel campo dell'elenco di coordinate. - Convertire la colonna Elevazione in decimale e selezionare i pulsanti Chiudi e Applica.
Come alternativa ai passi precedenti, è possibile usare il codice seguente. Esegue lo script dei passaggi usati nell'Editor avanzato in Power BI per scrivere le trasformazioni dei dati in un linguaggio di query:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
I dati sono ora inclusi nel modello di dati di Power BI. L'istanza di Power BI Desktop deve avere un aspetto simile al seguente:

È possibile avviare la compilazione di report e visualizzazioni con il modello di dati. Questo articolo di Power BI illustra come compilare un report.
Ridimensionare la DSVM in modo dinamico
È possibile ridimensionare la DSVM in modo da soddisfare le esigenze del progetto. Se non è necessario usare la VM la sera o nei fine settimana, è sufficiente arrestarla dal portale di Azure.
Nota
Vengono addebitati i costi di calcolo se si usa solo il pulsante di arresto del sistema operativo nella VM. Invece, è consigliabile deallocare la DSVM usando il portale di Azure o Cloud Shell.
Per un progetto di analisi su larga scala, potrebbe essere necessaria una maggiore capacità di CPU, memoria o disco. In tal caso, è possibile trovare VM con diversi numeri di core CPU, capacità di memoria, tipi di disco (incluse unità a stato solido) e istanze basate su GPU per Deep Learning che soddisfano le esigenze di calcolo e budget. La pagina dei prezzi delle Macchine virtuali di Microsoft Azure mostra l'elenco completo delle VM, insieme ai prezzi di calcolo orari.
Aggiungere altri strumenti
La DSVM offre strumenti predefiniti che possono soddisfare molte esigenze comuni di analisi dei dati. Consentono di risparmiare tempo perché non è necessario installare e configurare singolarmente gli ambienti. Inoltre consentono anche di risparmiare denaro, perché si paga solo per le risorse usate.
È possibile sfruttare altri servizi di Azure per i dati e l'analisi, come illustrato in questo articolo, per migliorare l'ambiente di analisi. In alcuni casi, potrebbero essere necessari altri strumenti, inclusi quelli specifici di partner proprietari. L'accesso amministrativo completo alla macchina virtuale consente di installare gli strumenti necessari. Inoltre è possibile installare in Python e R altri strumenti non preinstallati. Per Python è possibile usare conda o pip. Per R è possibile usare install.packages() nella console di R, oppure usare l'IDE e scegliere Pacchetti>Installa pacchetti.
Deep Learning
Oltre a esempi basati su framework, è possibile ottenere un set di procedure dettagliate complete che erano state convalidate nella DSVM. Queste procedure dettagliate consentono di iniziare subito a sviluppare applicazioni di apprendimento avanzato nella comprensione delle immagini e del linguaggio/testo.
Esecuzione di reti neurali in diversi framework: questa procedura dettagliata completa illustra come eseguire la migrazione del codice da un framework a un altro. Mostra anche come confrontare le prestazioni dei modelli e di runtime fra i framework.
Guida dettagliata alla creazione di una soluzione end-to-end per individuare prodotti all'interno di immagini: la tecnica di rilevamento immagine consente di individuare e classificare gli oggetti all'interno delle immagini. Questa tecnologia può portare enormi vantaggi in molte applicazioni aziendali reali. Ad esempio, i rivenditori possono usare questa tecnica per identificare un prodotto che un cliente ha prelevato dallo scaffale. Queste informazioni consentono ai punti vendita al dettaglio di gestire l'inventario dei prodotti.
Deep learning per audio: questa esercitazione illustra come eseguire il training di un modello di Deep Learning per il rilevamento di eventi audio nel set di dati Urban Sounds. Fornisce anche una panoramica su come usare i dati audio.
Classificazione di documenti di testo: questa procedura dettagliata illustra come creare e addestrare due architetture di rete neurale, ovvero rete Hierarchical Attention Network e Long Short Term Memory (LSTM). Queste reti neurali usano l'API Keras per l'apprendimento avanzato per classificare i documenti di testo.
Riepilogo
Questo articolo contiene alcune delle attività che è possibile eseguire nella Microsoft Data Science Virtual Machine. Ce ne sono molte altre che è possibile eseguire per rendere la DSVM un ambiente di analisi efficace.