Confronto tra Deep Learning e Machine Learning in Azure Machine Learning
Questo articolo illustra il Deep Learning e l’apprendimento automatico e il modo in cui rientrano nella categoria più ampia di intelligenza artificiale. Informazioni sulle soluzioni di Deep Learning che è possibile sviluppare in Azure Machine Learning, ad esempio il rilevamento delle frodi, il riconoscimento vocale e facciale, l'analisi del sentiment e la previsione delle serie temporali.
Per indicazioni sulla scelta degli algoritmi per le soluzioni, vedere il Foglio informativo sugli algoritmi di apprendimento automatico.
I modelli di base in Azure Machine Learning sono modelli di Deep Learning con training preliminare, che possono essere ottimizzati per casi d'uso specifici. Altre informazioni su Modelli di base (anteprima) in Azure Machine Learning e u come usare i Modelli di base in Azure Machine Learning (anteprima).
Deep Learning, apprendimento automatico e IA
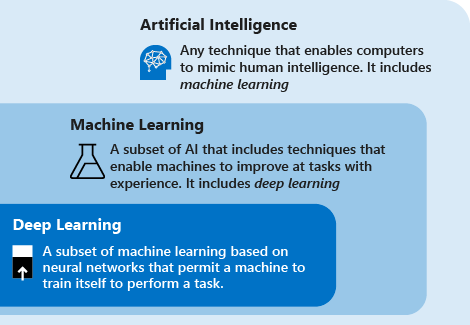
Prendere in considerazione le definizioni seguenti per comprendere il significato di Deep Learning rispetto a quello di apprendimento automatico e di IA:
il Deep Learning è un subset di apprendimento automatico basato su reti neurali artificiali. Il processo di apprendimento è profondo perché la struttura delle reti neurali artificiali è costituita da più livelli di input, di output e di livelli nascosti. Ogni livello contiene unità che trasformano i dati di input in informazioni che il livello successivo può usare per una determinata attività predittiva. Grazie a questa struttura, un computer può apprendere attraverso la propria elaborazione dati.
L’apprendimento automatico è un subset di intelligenza artificiale che utilizza tecniche (come il Deep Learning) che consentono ai computer di usare l'esperienza per migliorare le proprie attività. Il processo di apprendimento si basa sui passaggi seguenti:
- Inserire dati in un algoritmo. In questo passaggio è possibile fornire informazioni aggiuntive al modello, ad esempio eseguendo l'estrazione delle funzionalità.
- Usare questi dati per eseguire il training di un modello.
- Testare e distribuire il modello.
- Usare il modello distribuito per eseguire un'attività predittiva automatizzata. In altre parole, richiamare e utilizzare il modello distribuito per ricevere le stime restituite dal modello.
L'intelligenza artificiale (IA) è una tecnica che consente ai computer di simulare l'intelligenza umana. L’IA include l’apprendimento automatico.
L'intelligenza artificiale generativa è un subset di intelligenza artificiale che usa tecniche (quali il Deep Learning) per generare nuovo contenuto. Ad esempio, è possibile usare l'intelligenza artificiale generativa per creare immagini, testo o audio. Questi modelli sfruttano enormi conoscenze con training preliminare per generare tale tipo di contenuti.
Usando l'apprendimento automatico e le tecniche di Deep Learning, è possibile creare sistemi informatici e applicazioni che eseguono attività comunemente associate all'intelligenza umana. Queste attività includono il riconoscimento delle immagini, il riconoscimento vocale e la traduzione linguistica.
Tecniche di Deep Learning e apprendimento automatico
Dopo questa panoramica su apprendimento automatico e Deep Learning, è possibile confrontare le due tecniche. Nell'apprendimento automatico, all'algoritmo deve essere detto come fare una previsione accurata consumando più informazioni (ad esempio, eseguendo l'estrazione di caratteristiche). Nel caso del Deep Learning, l'algoritmo può imparare a eseguire una previsione accurata tramite la propria elaborazione dei dati, grazie alla struttura della rete neurale artificiale.
Nella tabella seguente vengono confrontate in modo più dettagliato le due tecniche:
| Apprendimento automatico nel suo complesso | Solo Deep Learning | |
|---|---|---|
| Numero di punti dati | Può usare piccole quantità di dati per eseguire previsioni. | Necessita dell’utilizzo di grandi quantità di dati di addestramento per effettuare previsioni. |
| Dipendenze hardware di destinazione | Può funzionare su computer di fascia bassa. Non è necessaria una grande quantità di potenza di calcolo. | Funziona con computer di fascia alta. Esegue intrinsecamente un numero elevato di operazioni di moltiplicazione di matrici. Una GPU può ottimizzare in modo efficiente queste operazioni. |
| Processo di definizione delle caratteristiche | Richiede l'identificazione e la creazione accurate delle funzionalità da parte degli utenti. | Apprende le funzionalità di alto livello dai dati e crea da sé nuove funzionalità. |
| Approccio di apprendimento | Divide il processo di apprendimento in passaggi più piccoli. Combina quindi i risultati di ogni passaggio in un unico output. | Passa attraverso il processo di apprendimento risolvendo il problema in modo end-to-end. |
| Tempi di esecuzione | Richiede relativamente poco tempo per il training, da pochi secondi a poche ore. | In genere il training richiede molto tempo perché un algoritmo di Deep Learning prevede molti livelli. |
| Output | L'output è in genere un valore numerico, ad esempio un punteggio o una classificazione. | L'output può avere più formati, ad esempio un testo, un punteggio o un suono. |
Che cos'è l'apprendimento induttivo?
Il training di modelli di Deep Learning richiede spesso grandi quantità di dati di training, risorse di calcolo di fascia alta (GPU, TPU) e tempi di training più lunghi. Negli scenari in cui non si dispone di nessuno di tali elementi disponibili, è possibile modificare il processo di training usando una tecnica nota come apprendimento induttivo.
L'apprendimento induttivo è una tecnica che applica le conoscenze acquisite dalla risoluzione di un problema a un problema diverso ma ad esso correlato.
A causa della struttura delle reti neurali, il primo set di livelli in genere contiene funzionalità di livello inferiore, mentre il set di livelli finale contiene caratteristiche di livello superiore più vicine al dominio in questione. Ripristinando i livelli finali da usare in un nuovo dominio o problema, è possibile ridurre significativamente la quantità di tempo, dati e risorse di calcolo necessaria per eseguire il training del nuovo modello. Ad esempio, se si dispone già di un modello che riconosce le automobili, è possibile riutilizzare tale modello usando l'apprendimento induttivo per riconoscere anche camion, moto e altre tipologie di veicoli.
Informazioni su come applicare l'apprendimento induttivo per la classificazione delle immagini usando un framework open source in Azure Machine Learning: Eseguire il training di un modello PyTorch di Deep Learning usando l'apprendimento induttivo.
Casi d'uso di Deep Learning
A causa della struttura della rete neurale artificiale, il Deep Learning consente di identificare i modelli in dati non strutturati come immagini, suoni, video e testo. Per questo motivo, il Deep Learning sta trasformando rapidamente molti settori, tra cui sanità, energia, finanza e trasporti. Questi settori stanno ora ripensando i processi aziendali tradizionali.
Alcune delle applicazioni più comuni per il Deep Learning sono descritte nei paragrafi seguenti. In Azure Machine Learning è possibile usare un modello creato da un framework open source oppure compilare il modello usando gli strumenti forniti.
Riconoscimento entità denominata
Il riconoscimento di entità denominate è un metodo di Deep Learning che accetta una parte di testo come input e lo trasforma in una classe pre-specificata. Queste nuove informazioni potrebbero essere un codice postale, una data, un ID prodotto. Le informazioni possono quindi essere archiviate in uno schema strutturato per compilare un elenco di indirizzi o fungere da benchmark per un motore di convalida delle identità.
Rilevamento oggetti
Il Deep Learning è stato applicato in molti casi d'uso di rilevamento oggetti. Il rilevamento oggetti viene usato per identificare gli oggetti in un'immagine (ad esempio automobili o persone) e fornire una posizione specifica per ogni oggetto con un rettangolo delimitatore.
Il rilevamento degli oggetti è già usato in settori come giochi, vendita al dettaglio, turismo e veicoli a guida autonoma.
Generazione di didascalie delle immagini
Al pari del riconoscimento delle immagini, per le didascalie il sistema deve generare una didascalia che descriva il contenuto dell'immagine per ciascuna di essa. Allorché è possibile rilevare ed etichettare oggetti nelle fotografie, il passaggio successivo consiste nel trasformare tali etichette in frasi descrittive.
In genere, le applicazioni per la creazione di didascalie usano reti neurali convoluzionali per identificare gli oggetti all’interno di un'immagine e quindi usare una rete neurale ricorrente per trasformare le etichette in frasi coerenti.
Traduzione automatica
La traduzione automatica accetta parole o frasi da una lingua e le converte automaticamente in un'altra lingua. La traduzione automatica è una procedura conosciuta da molto tempo, ma il Deep Learning ottiene risultati impressionanti in due aree specifiche: la traduzione automatica del testo (e la conversione della voce in testo scritto) e la traduzione automatica delle immagini.
Con la trasformazione dei dati appropriata, una rete neurale è in grado di comprendere segnali di testo, audio e visivi. La traduzione automatica può essere usata per identificare frammenti di suono in file audio di dimensioni maggiori e trascrivere la parola o l'immagine pronunciata come testo.
Analisi del testo
L'analisi del testo basata su metodi di Deep Learning implica l'analisi di grandi quantità di dati di testo (ad esempio documentazione medica o ricevute spese), il riconoscimento dei modelli e la creazione di informazioni organizzate e concise.
Le aziende utilizzano il Deep Learning per eseguire l'analisi del testo al fine di rilevare casi di insider trading e la conformità alle norme governative. Un altro esempio comune è la frode assicurativa: l'analisi del testo è stata spesso utilizzata per analizzare grandi quantità di documenti al fine di riconoscere le probabilità che un reclamo assicurativo possa essere fraudolento.
Reti neurali artificiali
Le reti neurali artificiali sono costituite da livelli di nodi connessi. I modelli di Deep Learning usano reti neurali con un numero elevato di livelli.
Le sezioni seguenti illustrano le più diffuse topologie di reti neurali artificiali.
Rete neurale feedforward
La rete neurale feedforward è il tipo di rete neurale artificiale più semplice. In una rete feedforward, le informazioni si spostano in una sola direzione, dal livello di input al livello di output. Le reti neurali feedforward trasformano un input inserendolo in una serie di livelli nascosti. Ogni livello è costituito da un set di neuroni e ciascun livello è completamente connesso a tutti i neuroni appartenenti al livello precedente. L'ultimo livello completamente connesso (il livello di output) rappresenta le previsioni generate.
Rete neurale ricorrente (RNN, Recurrent Neural Network)
Le reti neurali ricorrenti sono reti neurali artificiali ampiamente utilizzate. Queste reti salvano l'output di un livello e lo inseriscono nuovamente nel livello di input per predire il risultato del livello. Le reti neurali ricorrenti hanno grandi capacità di apprendimento. Vengono ampiamente utilizzate per attività complesse, ad esempio la previsione delle serie temporali, l’apprendimento della scrittura manuale e il riconoscimento del linguaggio.
Rete neurale convoluzionale (CNN, Convolutional Neural Network)
Una rete neurale convoluzionale è una rete neurale artificiale particolarmente efficace e presenta un'architettura unica. I livelli sono organizzati in tre dimensioni: larghezza, altezza e profondità. I neuroni appartenenti a un livello non si connettono a tutti i neuroni del livello successivo, ma solo a una piccola area dei neuroni di quel livello. L'output finale viene ridotto a un singolo vettore di punteggi di probabilità, organizzati lungo la dimensione della profondità.
Le reti neurali convoluzionali sono state usate in aree quali il riconoscimento video, il riconoscimento delle immagini e i sistemi di raccomandazione.
Rete generativa avversaria (GAN; Generative Adversarial Network)
Le reti antagoniste generative sono modelli generativi sottoposti a training per creare contenuti realistici, ad esempio immagini. Sono costituite da due reti, note come generatore e discriminatore. Entrambe le reti vengono addestrate contemporaneamente. Durante il training, il generatore usa il rumore casuale per creare nuovi dati sintetici che assomigliano molto ai dati reali. Il discriminatore accetta l'output del generatore come input e usa dati reali per determinare se il contenuto generato è reale o sintetico. Le reti sono in competizione tra loro. Il generatore prova a generare contenuto sintetico indistinguibile dal contenuto reale e il discriminatore cerca di classificare correttamente gli input come reali o sintetici. L'output viene quindi usato per aggiornare i pesi di entrambe le reti per aiutarle a raggiungere meglio i rispettivi obiettivi.
Le reti antagoniste generative vengono usate per risolvere problemi come la traduzione dell'immagine e la progressione dell'età.
Convertitori
I trasformatori sono un'architettura del modello adatta per la risoluzione di problemi contenenti sequenze, ad esempio dati di testo o serie temporali. Sono costituiti da livelli di codificatori e decodificatori. Il codificatore accetta un input e ne esegue il mapping per una rappresentazione numerica contenente informazioni come il contesto. Il decodificatore usa le informazioni del codificatore per produrre un output, ad esempio il testo tradotto. Ciò che rende i trasformatori diversi da altre architetture contenenti codificatori e decodificatori sono i sub-layer di attenzione. L'attenzione è l'idea di concentrarsi su parti specifiche di un input in base all'importanza del contesto rispetto ad altri input all’interno di una sequenza. Ad esempio, quando si riepiloga un articolo di notizie, non tutte le frasi sono rilevanti per descrivere l'idea principale. Concentrandosi sulle parole chiave presenti in tutto l'articolo, il riepilogo può essere eseguito in una singola frase, il titolo.
I trasformatori sono stati usati per risolvere i problemi di elaborazione del linguaggio naturale, ad esempio la traduzione, la generazione di testo, la risposta alle domande e il riepilogo del testo.
Alcune implementazioni note dei trasformatori sono:
- Rappresentazioni del codificatore bidirezionale da trasformatori (BERT)
- Trasformatore generativo pre-addestrato 2 (GPT-2)
- Trasformatore generativo pre-addestrato 3 (GPT-3)
Passaggi successivi
Gli articoli seguenti illustrano altre opzioni per l'uso di modelli di Deep Learning open source in Azure Machine Learning: