Configurare le impostazioni del broker per la disponibilità elevata, il ridimensionamento e l'utilizzo della memoria
La risorsa Broker è la risorsa principale che definisce le impostazioni generali per un broker MQTT. Determina anche il numero e il tipo di pod che eseguono la configurazione Broker, ad esempio i front-end e i back-end. È anche possibile usare la risorsa Broker per configurarne il profilo di memoria. I meccanismi di riparazione automatica sono integrati nel broker e spesso possono essere ripristinati automaticamente dagli errori dei componenti. Un esempio è se un nodo non riesce in un cluster Kubernetes configurato per la disponibilità elevata.
È possibile ridimensionare orizzontalmente il broker MQTT aggiungendo più repliche front-end e partizioni back-end. Le repliche front-end sono responsabili dell'accettazione delle connessioni MQTT dai client e dell'inoltro alle partizioni back-end. Le partizioni back-end sono responsabili dell'archiviazione e del recapito dei messaggi ai client. I pod front-end distribuiscono il traffico dei messaggi tra i pod back-end. Il fattore di ridondanza back-end determina il numero di copie dei dati per fornire resilienza contro gli errori dei nodi nel cluster.
Per un elenco delle impostazioni disponibili, vedere le informazioni di riferimento sull'API broker .
Configurare le impostazioni di ridimensionamento
Importante
Per questa impostazione è necessario modificare la risorsa Broker. Viene configurato solo durante la distribuzione iniziale usando l'interfaccia della riga di comando di Azure o il portale di Azure. Se sono necessarie modifiche alla configurazione di Broker, è necessaria una nuova distribuzione. Per altre informazioni, vedere Personalizzare Broker predefinito.
Per configurare le impostazioni di ridimensionamento del broker MQTT, specificare i campi di cardinalità nella specifica della risorsa Broker durante la distribuzione di Azure IoT Operations.
Cardinalità della distribuzione automatica
Per determinare automaticamente la cardinalità iniziale durante la distribuzione, omettere il campo cardinalità nella risorsa Broker.
La cardinalità automatica non è ancora supportata quando si distribuiscono le operazioni IoT tramite il portale di Azure. È possibile specificare manualmente la modalità di distribuzione del cluster come nodo singolo o multinodo. Per altre informazioni, vedere Distribuire le operazioni di Azure IoT.
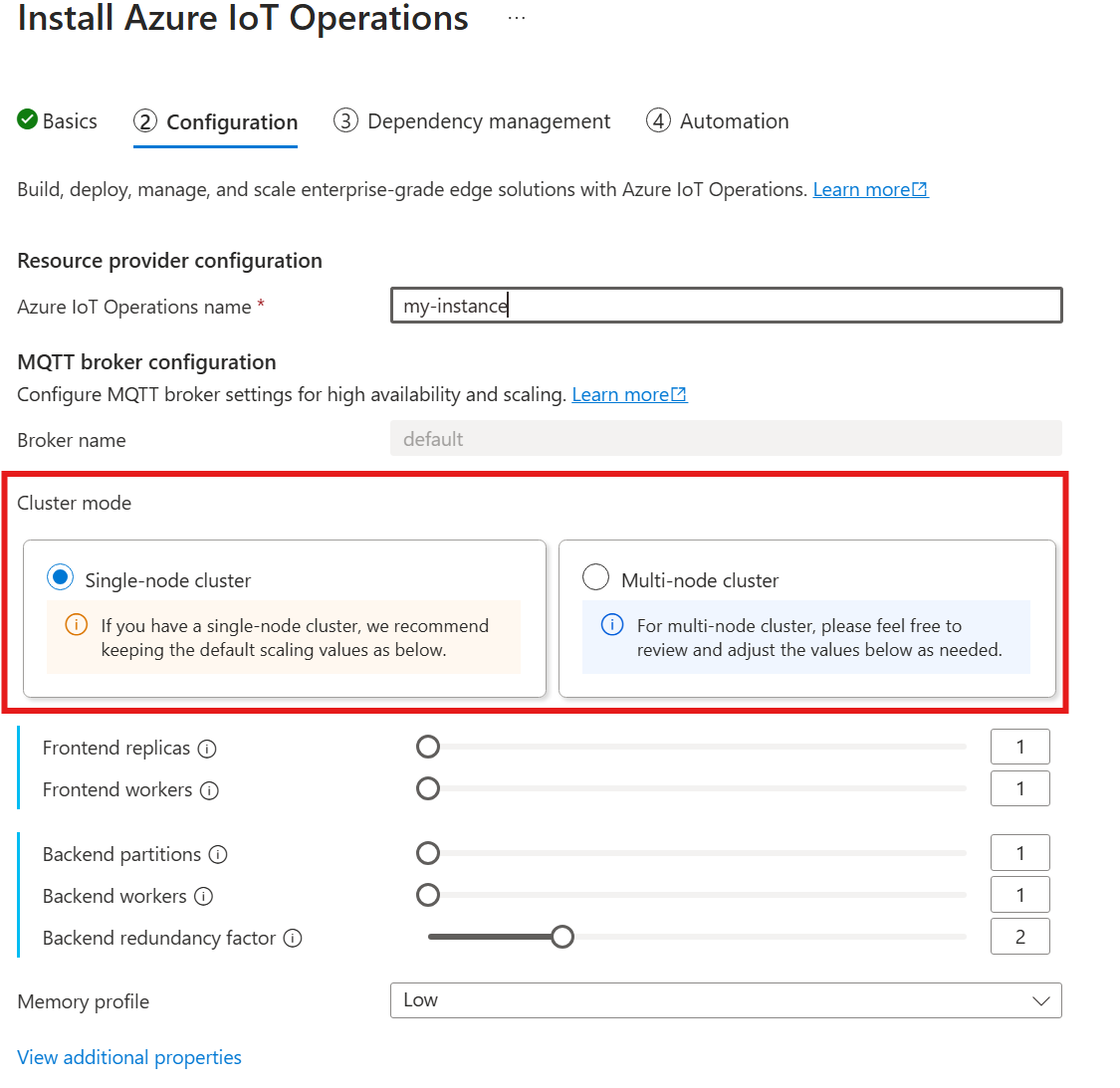
L'operatore broker MQTT distribuisce automaticamente il numero appropriato di pod in base al numero di nodi disponibili al momento della distribuzione. Questa funzionalità è utile per gli scenari non di produzione in cui non è necessaria la disponibilità elevata o la scalabilità.
Questa funzionalità non è la scalabilità automatica. L'operatore non ridimensiona automaticamente il numero di pod in base al carico. L'operatore determina il numero iniziale di pod da distribuire solo in base all'hardware del cluster. Come indicato in precedenza, la cardinalità viene impostata solo in fase di distribuzione iniziale. Se è necessario modificare le impostazioni di cardinalità, è necessaria una nuova distribuzione.
Configurare direttamente la cardinalità
Per configurare direttamente le impostazioni di cardinalità, specificare ognuno dei campi di cardinalità.
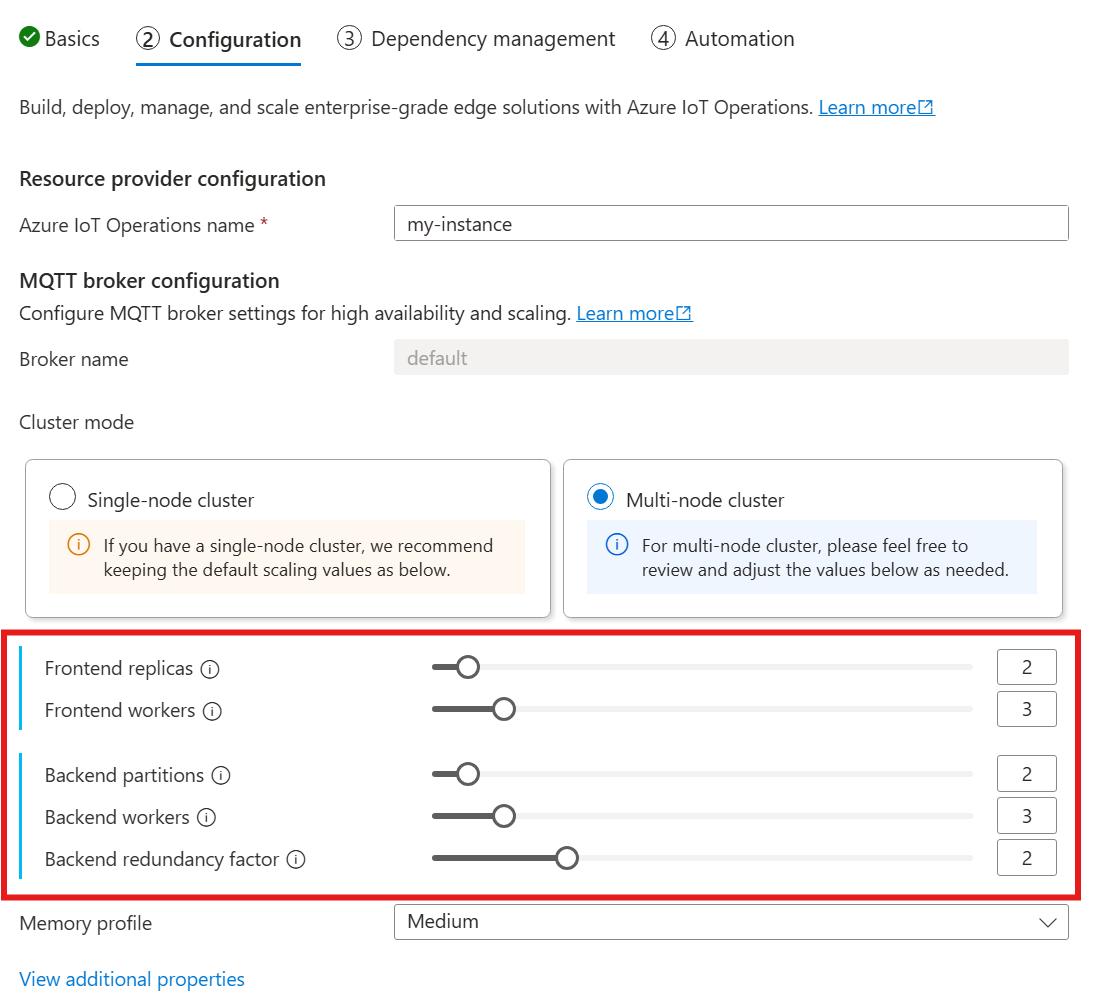
Quando si segue la guida per distribuire le operazioni IoT, nella sezione Configurazione esaminare la configurazione del broker MQTT. In questo caso è possibile specificare il numero di repliche front-end, partizioni back-end e ruoli di lavoro back-end.
Informazioni sulla cardinalità
Cardinalità indica il numero di istanze di una determinata entità in un set. Nel contesto del broker MQTT, la cardinalità si riferisce al numero di repliche front-end, partizioni back-end e ruoli di lavoro back-end da distribuire. Le impostazioni di cardinalità vengono usate per ridimensionare orizzontalmente il broker e migliorare la disponibilità elevata in caso di errori di pod o nodi.
Il campo cardinalità è un campo annidato, con sottocampi per il front-end e la catena back-end. Ognuno di questi campi secondari ha le proprie impostazioni.
Front-end
Il sottocampo front-end definisce le impostazioni per i pod front-end. Le due impostazioni principali sono:
- Repliche: numero di repliche front-end (pod) da distribuire. L'aumento del numero di repliche front-end offre disponibilità elevata nel caso in cui uno dei pod front-end non riesca.
- Ruoli di lavoro: numero di ruoli di lavoro front-end logici per replica. Ogni ruolo di lavoro può utilizzare fino a un core CPU al massimo.
Catena back-end
Il sottocampo della catena back-end definisce le impostazioni per le partizioni back-end. Le tre impostazioni principali sono:
- Partizioni: numero di partizioni da distribuire. Tramite un processo denominato partizionamento orizzontale, ogni partizione è responsabile di una parte dei messaggi, divisa per ID argomento e ID sessione. I pod front-end distribuiscono il traffico dei messaggi tra le partizioni. L'aumento del numero di partizioni aumenta il numero di messaggi che il broker può gestire.
- Fattore di ridondanza: numero di repliche back-end (pod) da distribuire per partizione. L'aumento del fattore di ridondanza aumenta il numero di copie di dati per fornire resilienza contro gli errori dei nodi nel cluster.
- Ruoli di lavoro: numero di ruoli di lavoro da distribuire per replica back-end. L'aumento del numero di ruoli di lavoro per replica back-end potrebbe aumentare il numero di messaggi che il pod back-end può gestire. Ogni ruolo di lavoro può usare al massimo due core CPU, quindi prestare attenzione quando si aumenta il numero di ruoli di lavoro per replica per non superare il numero di core CPU nel cluster.
Considerazioni
Quando si aumentano i valori di cardinalità, la capacità del broker di gestire più connessioni e messaggi migliora in genere e migliora la disponibilità elevata in caso di errori di pod o nodi. Questa maggiore capacità comporta anche un maggiore consumo di risorse. Pertanto, quando si modificano i valori di cardinalità, prendere in considerazione le impostazioni del profilo di memoria e le richieste di risorse CPU del broker. Aumentando il numero di ruoli di lavoro per replica front-end, è possibile aumentare l'utilizzo dei core CPU se si scopre che l'utilizzo della CPU front-end è un collo di bottiglia. L'aumento del numero di ruoli di lavoro back-end può essere utile per la velocità effettiva dei messaggi se l'utilizzo della CPU back-end è un collo di bottiglia.
Ad esempio, se il cluster ha tre nodi, ognuno con otto core CPU, impostare il numero di repliche front-end in modo che corrispondano al numero di nodi (3) e impostare il numero di ruoli di lavoro su 1. Impostare il numero di partizioni back-end in modo che corrispondano al numero di nodi (3) e impostare i ruoli di lavoro back-end su 1. Impostare il fattore di ridondanza come desiderato (2 o 3). Aumentare il numero di ruoli di lavoro front-end se si scopre che l'utilizzo della CPU front-end è un collo di bottiglia. Tenere presente che i ruoli di lavoro back-end e front-end potrebbero competere per le risorse della CPU tra loro e con altri pod.
Configurare il profilo di memoria
Importante
Questa impostazione richiede di modificare la risorsa broker. Viene configurato solo durante la distribuzione iniziale usando l'interfaccia della riga di comando di Azure o il portale di Azure. Se sono necessarie modifiche alla configurazione di Broker, è necessaria una nuova distribuzione. Per altre informazioni, vedere Personalizzare Broker predefinito.
Per configurare le impostazioni del profilo di memoria del broker MQTT, specificare i campi del profilo di memoria nella specifica della risorsa Broker durante la distribuzione delle operazioni IoT.
Quando si usa la guida seguente per distribuire operazioni IoT, nella sezione Configurazione cercare in Configurazione broker MQTT e trovare l'impostazione Profilo di memoria. Qui è possibile selezionare i profili di memoria disponibili in un elenco a discesa.
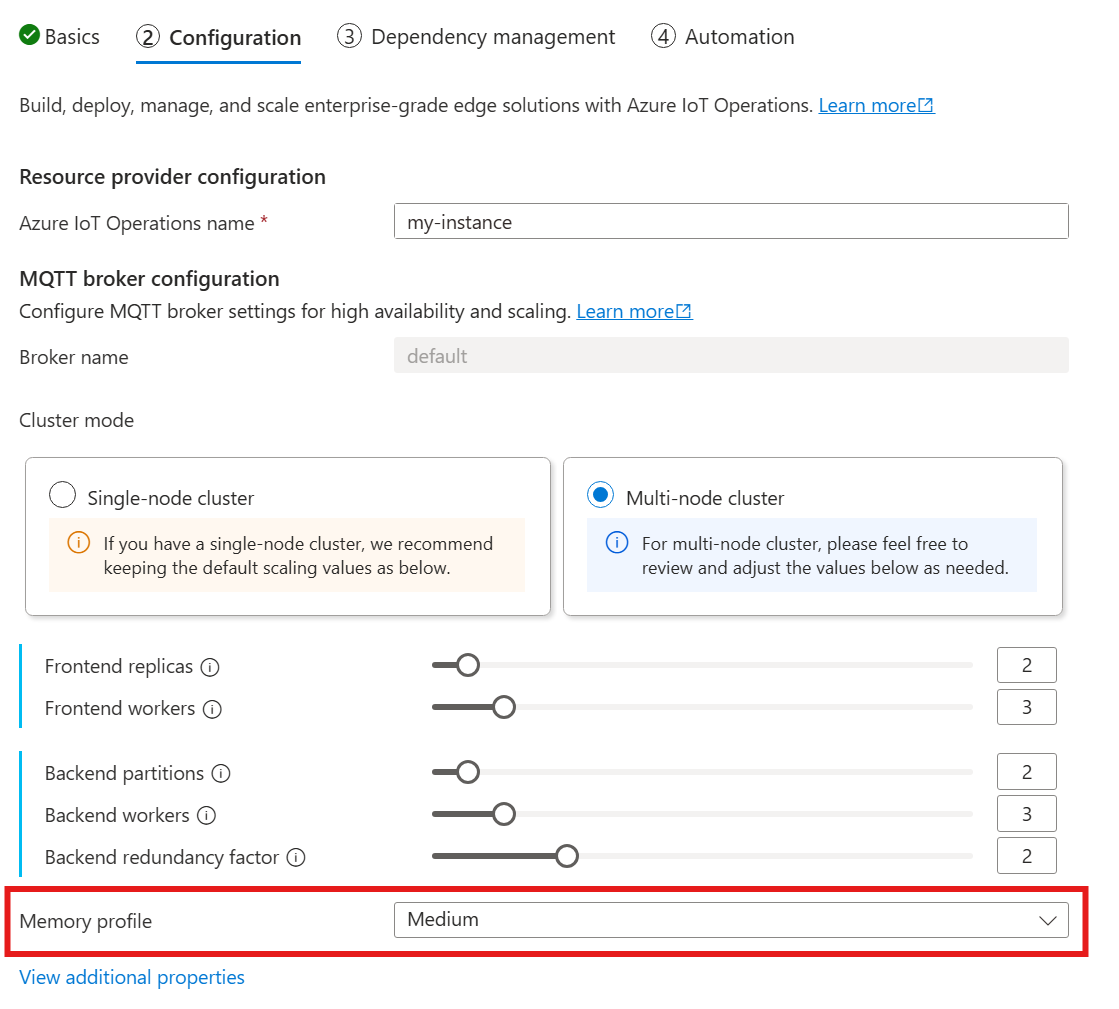
Esistono alcuni profili di memoria tra cui scegliere, ognuno con caratteristiche di utilizzo della memoria diverse.
Tiny
Quando si usa questo profilo:
- L'utilizzo massimo della memoria di ogni replica front-end è di circa 99 MiB, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
- L'utilizzo massimo della memoria di ogni replica back-end è di circa 102 MiB moltiplicato per il numero di ruoli di lavoro back-end, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
Consigli quando si usa questo profilo:
- È consigliabile usare un solo front-end.
- I client non devono inviare pacchetti di grandi dimensioni. È consigliabile inviare pacchetti di dimensioni inferiori a 4 MiB.
Basso
Quando si usa questo profilo:
- L'utilizzo massimo della memoria di ogni replica front-end è di circa 387 MiB, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
- L'utilizzo massimo della memoria di ogni replica back-end è di circa 390 MiB moltiplicato per il numero di ruoli di lavoro back-end, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
Consigli quando si usa questo profilo:
- È consigliabile usare solo uno o due front-end.
- I client non devono inviare pacchetti di grandi dimensioni. È consigliabile inviare pacchetti di dimensioni inferiori a 10 MiB.
Medio
Medium è il profilo predefinito.
- L'utilizzo massimo della memoria di ogni replica front-end è di circa 1,9 GiB, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
- L'utilizzo massimo della memoria di ogni replica back-end è di circa 1,5 GiB moltiplicato per il numero di ruoli di lavoro back-end, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
Alto
- L'utilizzo massimo della memoria di ogni replica front-end è di circa 4,9 GiB, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
- L'utilizzo massimo della memoria di ogni replica back-end è di circa 5,8 GiB moltiplicato per il numero di ruoli di lavoro back-end, ma l'utilizzo effettivo della memoria massima potrebbe essere superiore.
Limiti di cardinalità e risorse Kubernetes
Per evitare la fame di risorse nel cluster, il broker è configurato per impostazione predefinita per richiedere i limiti delle risorse della CPU Kubernetes. Il ridimensionamento del numero di repliche o ruoli di lavoro aumenta proporzionalmente le risorse della CPU necessarie. Se nel cluster sono disponibili risorse CPU insufficienti, viene generato un errore di distribuzione. Questa notifica consente di evitare situazioni in cui la cardinalità del broker richiesta non dispone di risorse sufficienti per l'esecuzione ottimale. Consente anche di evitare potenziali conflitti di CPU e di rimozione dei pod.
Il broker MQTT richiede attualmente un'unità CPU (1,0) per ogni ruolo di lavoro front-end e due unità CPU (2,0) per ogni ruolo di lavoro back-end. Per altre informazioni, vedere Unità di risorse DELLA CPU Kubernetes.
Ad esempio, la cardinalità seguente richiede le risorse CPU seguenti:
- Per i front-end: 2 unità CPU per ogni pod front-end, per un totale di 6 unità CPU.
- Per i back-end: 4 unità CPU per ogni pod back-end (per due ruoli di lavoro back-end), volte 2 (fattore di ridondanza), volte 3 (numero di partizioni), totale di 24 unità CPU.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Per disabilitare questa impostazione, impostare il generateResourceLimits.cpu campo su Disabled nella risorsa Broker.
La modifica del generateResourceLimits campo non è supportata nella portale di Azure. Per disabilitare questa impostazione, usare l'interfaccia della riga di comando di Azure.
Distribuzione a più nodi
Per garantire disponibilità elevata e resilienza con distribuzioni multinodo, il broker MQTT operazioni IoT imposta automaticamente regole di anti-affinità per i pod back-end.
Queste regole sono predefinite e non possono essere modificate.
Scopo delle regole anti-affinità
Le regole anti-affinità assicurano che i pod back-end della stessa partizione non vengano eseguiti nello stesso nodo. Questa funzionalità consente di distribuire il carico e offre resilienza in caso di errori del nodo. In particolare, i pod back-end della stessa partizione hanno un'anti-affinità tra loro.
Verificare le impostazioni di anti-affinità
Per verificare le impostazioni di anti-affinità per un pod back-end, usare il comando seguente:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
L'output mostra la configurazione anti-affinità, simile all'esempio seguente:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Queste regole sono le uniche regole anti-affinità impostate per il broker.