Disponibilità elevata e ripristino di emergenza dell'hub IoT
Come primo passaggio verso l'implementazione di una soluzione IoT resiliente, architetti, sviluppatori e proprietari di aziende devono definire gli obiettivi dei tempi di attività per le soluzioni che stanno costruendo. Questi obiettivi possono essere definiti principalmente in base a obiettivi di business specifici per ogni scenario di base. In questo contesto, l'articolo Informazioni tecniche sulla continuità aziendale Azure descrive un contesto generale per aiutare a pensare alla continuità aziendale e al ripristino di emergenza. Il documento Ripristino di emergenza e disponibilità elevata per le applicazioni Azure fornisce informazioni sull'architettura nelle strategie per consentire alle applicazioni di Azure di ottenere disponibilità elevata e ripristino di emergenza.
Questo articolo illustra le funzionalità di disponibilità elevata e ripristino di emergenza offerte in modo specifico dal servizio IoT Hub. Le aree generali illustrate in questo articolo sono:
- Disponibilità elevata intra-area
- Ripristino di emergenza tra aree
- Ottenere disponibilità elevata tra aree
A seconda degli obiettivi di tempo di attività definiti per le soluzioni IoT, è necessario determinare le opzioni descritte in questo articolo più adatte agli obiettivi aziendali. L'inclusione di una delle alternative tra disponibilità elevata e ripristino di emergenza nella soluzione IoT richiede un'attenta valutazione dei compromessi tra il:
- Livello di resilienza desiderata
- Complessità di implementazione e manutenzione
- Impatto COGS
Disponibilità elevata intra-area
Il servizio Hub IoT fornisce disponibilità elevata intra-area tramite l'implementazione delle ridondanze in quasi tutti i livelli di servizio. Il Contratto di servizio pubblicato dal servizio Hub IoT è realizzato sfruttando queste ridondanze. Gli sviluppatori di una soluzione IoT non richiedono alcun lavoro aggiuntivo per sfruttare queste funzionalità a disponibilità elevata. Anche se l'Hub IoT offre una garanzia di tempo di attività relativamente elevata, sono comunque attesi errori temporanei come in una qualsiasi piattaforma di elaborazione distribuita. Se si è appena iniziato a eseguire la migrazione delle soluzioni al cloud da una soluzione locale, l'attenzione deve passare dall'ottimizzazione del "tempo medio tra gli errori" al "tempo medio per il ripristino". In altre parole, gli errori temporanei sono considerati normali quando si opera con il cloud in combinazione. I modelli di ripetizione appropriati devono essere compilati nei componenti che interagiscono con un'applicazione cloud per gestire gli errori temporanei.
Zone di disponibilità
hub IoT supporta Zone di disponibilità di Azure. Una zona di disponibilità è un'offerta a disponibilità elevata che protegge le applicazioni e i dati da errori del data center. Un'area con supporto per la zona di disponibilità comprende tre zone che supportano tale area. Ogni zona fornisce uno o più data center, ognuno in una posizione fisica univoca con alimentazione, raffreddamento e rete indipendenti. Questa configurazione fornisce la replica e la ridondanza all'interno dell'area.
Le zone di disponibilità offrono due vantaggi: resilienza dei dati e distribuzioni più fluide.
La resilienza dei dati deriva dalla sostituzione dei servizi di archiviazione sottostanti con l'archiviazione supportata dalle zone di disponibilità. La resilienza dei dati è importante per le soluzioni IoT perché queste soluzioni spesso operano in ambienti complessi, dinamici e incerti in cui gli errori o le interruzioni possono avere conseguenze significative. Indipendentemente dal fatto che una soluzione IoT supporti ambienti di produzione, vendita al dettaglio o ristorante, sistemi sanitari o infrastruttura, la disponibilità e la qualità dei dati è necessaria per il ripristino da errori e per fornire servizi affidabili e coerenti.
Le distribuzioni più fluide provengono dalla sostituzione dell'hardware del data center sottostante con hardware più recente che supporta le zone di disponibilità. Questi miglioramenti hardware riducono al minimo l'impatto dei clienti sulle disconnessioni dei dispositivi e sulle riconnessioni e altri tempi di inattività correlati alla distribuzione. Il team di progettazione hub IoT distribuisce più aggiornamenti a ogni hub IoT ogni mese, sia per motivi di sicurezza che per fornire miglioramenti delle funzionalità. L'hardware supportato dalle zone di disponibilità è suddiviso in 15 domini di aggiornamento in modo che ogni aggiornamento sia più fluido, con un impatto minimo per i flussi di lavoro. Per altre informazioni sui domini di aggiornamento, vedere Set di disponibilità.
Il supporto della zona di disponibilità per hub IoT viene abilitato automaticamente per le nuove risorse hub IoT create nelle aree di Azure seguenti:
| Paese | Resilienza dei dati | Distribuzioni più fluide |
|---|---|---|
| Australia orientale | ||
| Brasile meridionale | ||
| Canada centrale | ||
| India centrale | ||
| Stati Uniti centrali | ||
| Stati Uniti orientali | ||
| Francia centrale | ||
| Germania centro-occidentale | ||
| Giappone orientale | ||
| Corea centrale | ||
| Europa settentrionale | ||
| Norvegia orientale | ||
| Qatar centrale | ||
| Stati Uniti meridionali | ||
| Asia sud-orientale | ||
| Regno Unito meridionale | ||
| Europa occidentale | ||
| West US 2 | ||
| Stati Uniti occidentali 3 |
Ripristino di emergenza tra aree
Potrebbero esserci alcune rare situazioni in cui un data center subisce interruzioni prolungate a causa di interruzioni dell'alimentazione o altri guasti che coinvolgono risorse fisiche. Tali eventi sono rari durante i quali la funzionalità a disponibilità elevata all'interno dell'area descritta in precedenza potrebbe non essere sempre utile. L'Hub IoT offre diverse soluzioni per il ripristino da tali interruzioni estese.
Le opzioni di ripristino disponibili per i clienti in una situazione di questo tipo sono failover avviato da Microsoft e failover manuale. La differenza fondamentale tra i due è che Microsoft avvia il primo mentre l'ultimo è avviato dall'utente. Inoltre, il failover manuale fornisce un obiettivo di recupero inferiore (RTO) rispetto all'opzione di failover avviato da Microsoft. Le specifiche RTO offerte con ogni opzione sono descritte nelle sezioni seguenti. Quando viene eseguita una di queste opzioni per effettuare il failover di un Hub IoT dalla sua area principale, l'Hub diventa pienamente funzionante nella corrispondente area geografica di Azure abbinata.
Entrambe queste opzioni di failover offrono gli obiettivi del punto di ripristino (RPO) seguenti:
| Tipo di dati | Obiettivi del punto di ripristino (RPO) |
|---|---|
| Registro delle identità | Perdita di dati da 0 a 5 minuti |
| Dati del dispositivo gemello | Perdita di dati da 0 a 5 minuti |
| Messaggi da cloud a dispositivo**1 | Perdita di dati da 0 a 5 minuti |
| Processi padre1 e dispositivo | Perdita di dati da 0 a 5 minuti |
| Messaggi da dispositivo a cloud | Tutti i messaggi non letti vengono persi |
| Messaggi di feedback da cloud a dispositivo | Tutti i messaggi non letti vengono persi |
1I messaggi da cloud a dispositivo e i processi padre non vengono recuperati come parte del failover manuale.
Una volta completata l'operazione di failover per l'Hub IoT, tutte le operazioni dal dispositivo e dalle applicazioni di back-end continueranno a funzionare senza richiedere un intervento manuale. Ciò significa che i messaggi da dispositivo a cloud devono continuare a funzionare e l'intero registro dei dispositivi è intatto. Gli eventi generati tramite Griglia di eventi possono essere utilizzati tramite le stesse sottoscrizioni configurate in precedenza, purché tali sottoscrizioni di Griglia di eventi continuino a essere disponibili. Non è necessaria alcuna gestione aggiuntiva per gli endpoint personalizzati.
Attenzione
- Il nome e l'endpoint compatibili con Hub eventi dell'hub IoT modifica dell'endpoint degli eventi predefiniti dopo il failover. Quando si ricevono messaggi di telemetria dall'endpoint predefinito usando il client o l'host del processore di eventi di Hub eventi, è necessario usare l'hub IoT stringa di connessione per stabilire la connessione. Ciò garantisce che le applicazioni back-end continuino a funzionare senza richiedere l'intervento manuale dopo il failover. Se si usa direttamente il nome e l'endpoint compatibili con Hub eventi nell'applicazione, sarà necessario recuperare il nuovo endpoint compatibile con Hub eventi dopo il failover per continuare le operazioni. Per altre informazioni, vedere Failover manuale e Hub eventi.
- Se si usa Funzioni di Azure o Analisi di flusso di Azure per connettere l'endpoint eventi predefinito, potrebbe essere necessario eseguire un riavvio. Ciò è dovuto al fatto che durante gli offset precedenti del failover non sono più validi.
- Quando si esegue il routing all'archiviazione, è consigliabile elencare i BLOB o i file e quindi eseguirne l'iterazione, per assicurarsi che tutti i BLOB o i file vengano letti senza fare ipotesi di partizione. L'intervallo di partizioni potrebbe potenzialmente cambiare durante un failover avviato da Microsoft o un failover manuale. È possibile usare l'API Elenca BLOB per enumerare l'elenco di BLOB o l'API List ADLS Gen2 per l'elenco dei file. Per altre informazioni, vedere Archiviazione di Azure come endpoint di routing.
Failover avviato da Microsoft
Il failover avviato da Microsoft viene eseguito da Microsoft in rare situazioni per eseguire il failover di tutti gli hub IoT da un'area interessata all'area geografica associata corrispondente. Questo processo è un'opzione predefinita e non richiede alcun intervento da parte dell'utente. Microsoft si riserva il diritto di effettuare una determinazione di quando questa opzione viene esercitata. Questo meccanismo non implica il consenso dell'utente prima che l'Hub dell'utente eseguito il failover. Il failover avviato da Microsoft ha un obiettivo di ripristino (RTO) di 2-26 ore.
L'obiettivo RTO è di grandi dimensioni poiché Microsoft deve eseguire l'operazione di failover per conto di tutti i clienti interessati in tale area. Se si esegue una soluzione IoT meno critica che può sostenere un tempo di inattività di circa un giorno, è possibile adottare una dipendenza da questa opzione per soddisfare gli obiettivi generali di ripristino di emergenza per la soluzione IoT. Il tempo totale per cui le operazioni di runtime diventano pienamente operative una volta che questo processo è stato attivato, è descritto nella sezione "Tempo di ripristino".
Solo gli utenti che distribuiscono hub IoT nelle aree Brasile meridionale e Asia sud-orientale (Singapore) possono rifiutare esplicitamente questa funzionalità. Per altre informazioni, vedere Disabilitare il ripristino di emergenza.
Nota
L'hub IoT di Azure non archivia né elabora i dati dei clienti all'esterno dell'area geografica in cui si distribuisce l'istanza del servizio. Per altre informazioni, vedere Replica tra aree in Azure.
Failover manuale
Se gli obiettivi del tempo di attività aziendale non sono soddisfatti dall'obiettivo RTO fornito dal failover avviato da Microsoft, è consigliabile usare il failover manuale per attivare manualmente il processo di failover. L'obiettivo RTO che utilizza questa opzione può essere compreso tra 10 minuti e un paio d'ore. L'obiettivo RTO è attualmente una funzione del numero di dispositivi registrati con l'istanza dell'Hub IoT su cui viene eseguito il failover. È possibile prevedere l'obiettivo RTO per un Hub di hosting di circa 100.000 dispositivi in approssimativamente 15 minuti. Il tempo totale per cui le operazioni di runtime diventano pienamente operative una volta che questo processo è stato attivato, è descritto nella sezione "Tempo di ripristino".
L'opzione di failover manuale è sempre disponibile per l'uso, indipendentemente dal fatto che nell'area primaria si siano verificati o meno tempi di inattività. Pertanto, questa opzione potrebbe potenzialmente essere usata per eseguire i failover pianificati. Un esempio di utilizzo del failover pianificato consiste nell'eseguire esercitazioni periodiche per il failover. Tuttavia, è importante precisare che un'operazione di failover pianificata determina un tempo di inattività per l'Hub per il periodo definito per l'obiettivo RTO per questa opzione e genera anche una perdita di dati definita dalla tabella RPO sovrastante. Si può considerare l'impostazione di un test di istanza dell'Hub IoT per provare l'opzione di failover pianificato periodicamente per ottenere una maggiore fiducia nella capacità di soluzioni end-to-end backup e in esecuzione quando si verifica un'emergenza reale.
Il failover manuale è disponibile senza costi aggiuntivi per gli hub IoT creati dopo il 18 maggio 2017
Per istruzioni dettagliate, vedere Esercitazione: Eseguire il failover manuale per un hub IoT
Failover manuale e Hub eventi
Il nome e l'endpoint compatibili con Hub eventi dell'hub IoT modifica dell'endpoint degli eventi predefiniti dopo il failover manuale. Ciò è dovuto al fatto che il client di Hub eventi non ha visibilità sugli eventi hub IoT. Lo stesso vale per altri client basati sul cloud, ad esempio Funzioni e Analisi di flusso di Azure. Per recuperare l'endpoint e il nome, è possibile usare il portale di Azure o .NET SDK.
Usare il portale
Per altre informazioni sull'uso del portale per recuperare l'endpoint compatibile con Hub eventi e il nome compatibile con Hub eventi, vedere Connettersi all'endpoint predefinito.
Usare .NET SDK
Per usare il hub IoT stringa di connessione per ricapitolare l'endpoint compatibile con Hub eventi, usare un esempio disponibile in https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. L'esempio di codice usa il stringa di connessione per ottenere il nuovo endpoint di Hub eventi e ristabilire la connessione. È necessario aver installato Visual Studio.
Eseguire esercitazioni di test
Le esercitazioni sui test non devono essere eseguite negli hub IoT usati negli ambienti di produzione.
Non usare il failover manuale per eseguire la migrazione dell'hub IoT in un'area diversa
Il failover manuale non deve essere usato come meccanismo per eseguire la migrazione permanente dell'hub tra le aree geografiche associate di Azure. Supponendo che i dispositivi si trovassero più vicini all'area primaria dell'hub, la latenza per le operazioni eseguite sull'hub IoT aumenterà quando l'hub esegue il failover in un'area secondaria.
Failback
È possibile eseguire il failback nell'area primaria precedente attivando l'azione di failover una seconda volta. Se l'operazione di failover originale è stata eseguita per il ripristino da un'interruzione prolungata nell'area primaria originale, si consiglia di ripristinare l'Hub nella posizione originale dalla situazione di interruzione.
Importante
- Gli utenti possono eseguire al giorn solo 2 failover riusciti e 2 operazioni di failback riuscite.
- Eseguire il backup per eseguire le operazioni di failover/failback non è consentito. È necessario attendere 1 ora tra queste operazioni.
Tempo di ripristino
Anche se il nome di dominio completo (e quindi il stringa di connessione) dell'istanza dell'hub IoT rimane invariato dopo il failover, l'indirizzo IP sottostante cambia. Tempo per l'esecuzione delle operazioni di runtime sull'istanza dell'hub IoT per diventare completamente operativo dopo che il processo di failover può essere espresso usando la funzione seguente:
Tempi di ripristino = RTO [10 min - 2 ore per il failover manuale | 2-26 ore per il failover avviato da Microsoft] + ritardo nella propagazione DNS + Tempo impiegato dall'applicazione client per aggiornare qualsiasi indirizzo IP dell'hub IoT memorizzato nella cache.
Importante
Gli SDK IoT non memorizzano nella cache l'indirizzo IP dell'Hub IoT. Raccomandiamo che il codice utente che si interfaccia con gli SDK non deve memorizzare nella cache l'indirizzo IP dell'Hub IoT.
Disabilitare il ripristino di emergenza
hub IoT fornisce failover avviato da Microsoft e failover manuale replicando i dati nell'area abbinata per ogni hub IoT. Per alcune aree, è possibile evitare la replica dei dati all'esterno dell'area disabilitando il ripristino di emergenza durante la creazione di un hub IoT. Le aree seguenti supportano questa funzionalità:
- Brasile meridionale; area abbinata, Stati Uniti centro-meridionali.
- Asia sud-orientale (Singapore); area abbinata, Asia orientale (HONG KONG SAR).
Per disabilitare il ripristino di emergenza nelle aree supportate, assicurarsi che il ripristino di emergenza abilitato sia deselezionato quando si crea l'hub IoT:
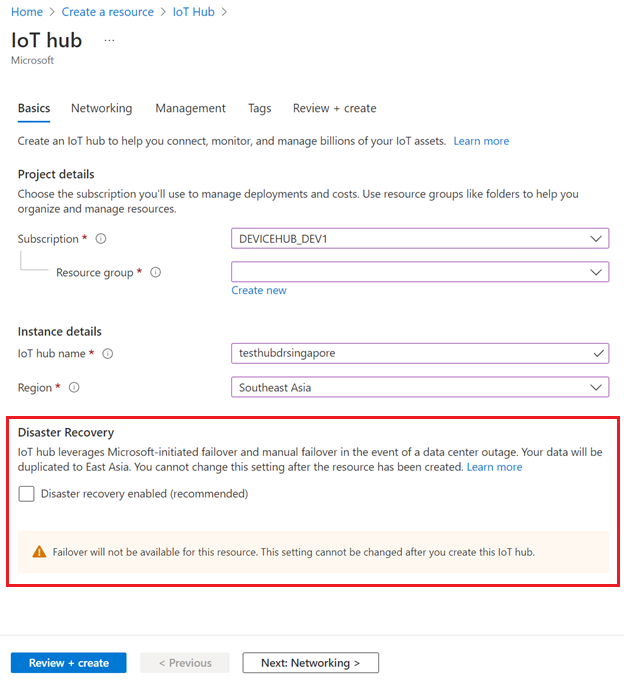
È anche possibile disabilitare il ripristino di emergenza quando si crea un hub IoT usando un modello di Resource Manager.
La funzionalità di failover non sarà disponibile se si disabilita il ripristino di emergenza per un hub IoT.
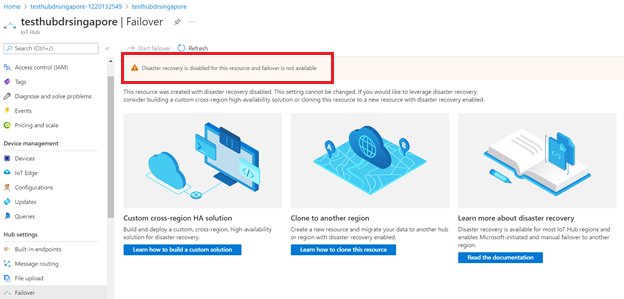
È possibile disabilitare il ripristino di emergenza solo per evitare la replica dei dati all'esterno dell'area abbinata in Brasile meridionale o asia sud-orientale quando si crea un hub IoT. Se si vuole configurare l'hub IoT esistente per disabilitare il ripristino di emergenza, è necessario creare un nuovo hub IoT con ripristino di emergenza disabilitato ed eseguire manualmente la migrazione dell'hub IoT esistente. Per indicazioni, vedere Come eseguire la migrazione di un hub IoT.
Ottenere disponibilità elevata tra aree
Se gli obiettivi di uptime aziendali non sono soddisfatti dal RTO che forniscono le opzioni di failover manuale o di failover avviato da Microsoft, si dovrebbe prendere in considerazione l'implementazione di un meccanismo di failover automatico tra aree per dispositivo. L'analisi completa delle topologie di distribuzione nelle soluzioni IoT esula dall'ambito di questo articolo. L'articolo illustra il modello di distribuzione di failover a livello di area per la disponibilità elevata e il ripristino di emergenza.
In un modello di failover a livello di area il back-end della soluzione viene eseguito principalmente nella località di un data center. Un hub IoT e un back-end secondari vengono distribuiti in un'altra località di data center. Se l'Hub IoT nella regione principale subisce un'interruzione o la connettività di rete dal dispositivo all'area principale viene interrotta, i dispositivi usano un endpoint del servizio secondario. È possibile migliorare la disponibilità della soluzione implementando un modello di failover tra aree invece di usare una sola area.
In generale, per implementare un modello di failover regionale con l'Hub IoT è necessario quanto segue:
Un hub IoT secondario e una logica di routing del dispositivo: se il servizio nell'area primaria viene interrotto, i dispositivi devono avviare la connessione all'area secondaria. Data la condizione con riconoscimento dello stato della maggior parte dei servizi coinvolti, gli amministratori delle soluzioni attivano comunemente il processo di failover tra aree. Il modo migliore per comunicare il nuovo endpoint ai dispositivi, mantenendo il controllo del processo, consiste nel fare in modo che controllino regolarmente un servizio concierge per verificare la disponibilità dell'endpoint attualmente attivo. Il servizio concierge può essere un'applicazione Web replicata e mantenuta raggiungibile con tecniche di reindirizzamento DNS, ad esempio con Gestione traffico di Azure.
Nota
Il servizio Hub IoT non è un tipo di endpoint supportato in Gestione traffico di Azure. La raccomandazione è quella di integrare il servizio di concierge proposto con il gestore del traffico di Azure, implementando l'API della sonda di endpoint.
Replica del registro delle identità: per poter essere usato, l'hub IoT secondario deve contenere tutte le identità dei dispositivi che possono connettersi alla soluzione. La soluzione deve mantenere backup con replica geografica delle identità dei dispositivi e caricarli nell'hub IoT secondario prima del passaggio all'endpoint attivo per i dispositivi. La funzionalità di esportazione delle identità dei dispositivi dell'hub IoT è utile in questo contesto. Per altre informazioni, vedere la Guida per gli sviluppatori dell'hub IoT: registro delle identità.
Logica di unione: quando un'area primaria diventa di nuovo disponibile, deve essere eseguita la migrazione di tutti i dati e dello stato creati nel sito secondario all'area primaria. Lo stato e i dati sono per lo più correlati alle identità dei dispositivi e ai metadati dell'applicazione, che devono essere uniti all'hub IoT primario e agli altri archivi specifici dell'applicazione nell'area primaria.
Per semplificare questo passaggio è consigliabile usare operazioni idempotenti. Le operazioni idempotenti riducono al minimo gli effetti collaterali della distribuzione coerente degli eventi e dei duplicati o del recapito non ordinato degli eventi. La logica dell'applicazione deve inoltre essere progettata per tollerare eventuali incoerenze o uno stato "leggermente" obsoleto. Questa situazione può verificarsi a causa del tempo aggiuntivo necessario per il ripristino del sistema in base agli obiettivi del punto di ripristino (RPO).
Scegliere l'opzione disponibilità elevata o ripristino di emergenza corretta
Ecco un riepilogo delle opzioni di disponibilità elevata e ripristino di emergenza presentate in questo articolo, utilizzabili come riferimento per scegliere l'opzione corretta per la soluzione.
| Opzione a disponibilità elevata e ripristino di emergenza | RTO | RPO | È necessario un intervento manuale? | Complessità dell'implementazione | Impatto sui costi |
|---|---|---|---|---|---|
| Failover avviato da Microsoft | 2-26 ore | Fare riferimento alla tabella RPO precedente | No | None | None |
| Failover manuale | 10 min-2 ore | Fare riferimento alla tabella RPO precedente | Sì | Molto bassa. È sufficiente attivare questa operazione dal portale. | None |
| Disponibilità elevata fra aree | < 1 min | Dipende dalla frequenza di replica della soluzione disponibilità elevata personalizzata | No | Alto | > 1x il costo di 1 hub IoT |