Configurare i criteri di Apache Ranger per Spark SQL in HDInsight con Enterprise Security Package
Questo articolo descrive come configurare i criteri di Apache Ranger per Spark SQL con Enterprise Security Package in HDInsight.
In questo articolo vengono illustrate le operazioni seguenti:
- Creare criteri di Apache Ranger.
- Verificare i criteri ranger applicati.
- Applicare le linee guida per l'impostazione di Apache Ranger per Spark SQL.
Prerequisiti
- Un cluster Apache Spark in HDInsight versione 5.1 con Enterprise Security Package
Connessione all'interfaccia utente di amministrazione di Apache Ranger
Da un browser connettersi all'interfaccia utente amministratore di Ranger usando l'URL
https://ClusterName.azurehdinsight.net/Ranger/.Passare
ClusterNameal nome del cluster Spark.Accedere usando le credenziali di amministratore di Microsoft Entra. Le credenziali di amministratore di Microsoft Entra non corrispondono alle credenziali del cluster HDInsight o alle credenziali SSH (Secure Shell) del nodo HDInsight linux.
Creare utenti del dominio
Per informazioni su come creare sparkuser utenti di dominio, vedere Creare un cluster HDInsight con ESP. In uno scenario di produzione, gli utenti di dominio provengono dal tenant di Microsoft Entra.
Creare un criterio ranger
In questa sezione vengono creati due criteri ranger:
- Criteri di accesso per l'accesso
hivesampletableda Spark SQL - Criteri di mascheramento per offuscare le colonne in
hivesampletable
Creare criteri di accesso di Ranger
Aprire l'interfaccia utente di amministrazione di Ranger.
In HADOOP SQL selezionare hive_and_spark.
Nella scheda Accesso selezionare Aggiungi nuovo criterio.
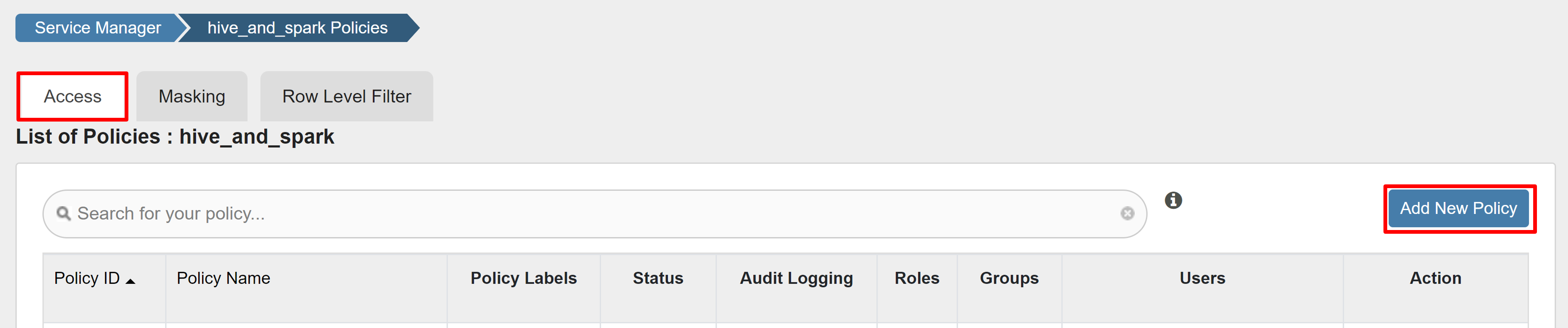
Immettere i valori seguenti:
Proprietà valore Nome criteri read-hivesampletable-all database impostazione predefinita table hivesampletable colonna * Seleziona utente sparkuserAutorizzazioni select 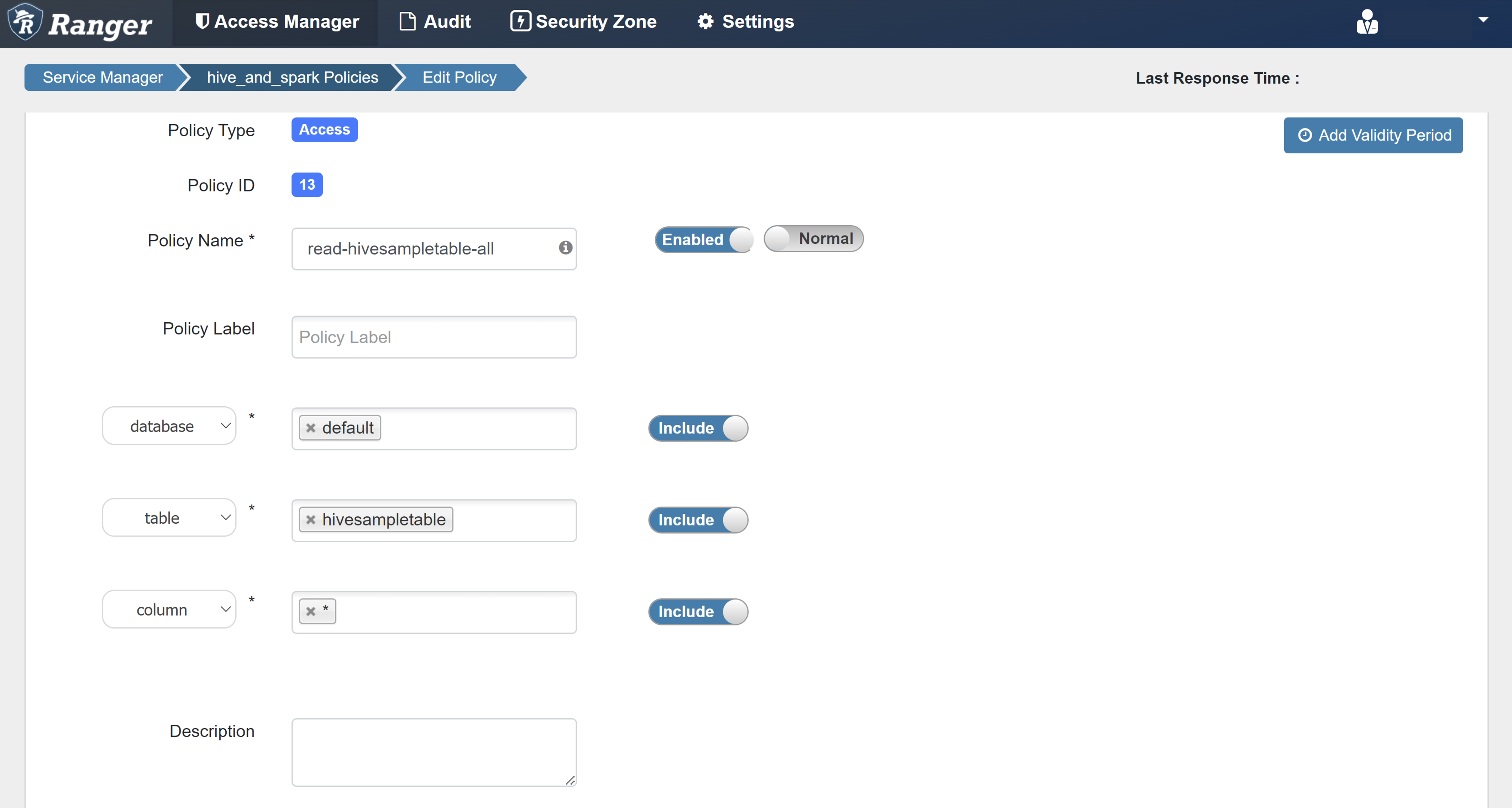
Se un utente di dominio non viene popolato automaticamente per Select User(Seleziona utente), attendere alcuni istanti affinché Ranger si sincronizzi con Microsoft Entra ID.
Selezionare Aggiungi per salvare il criterio.
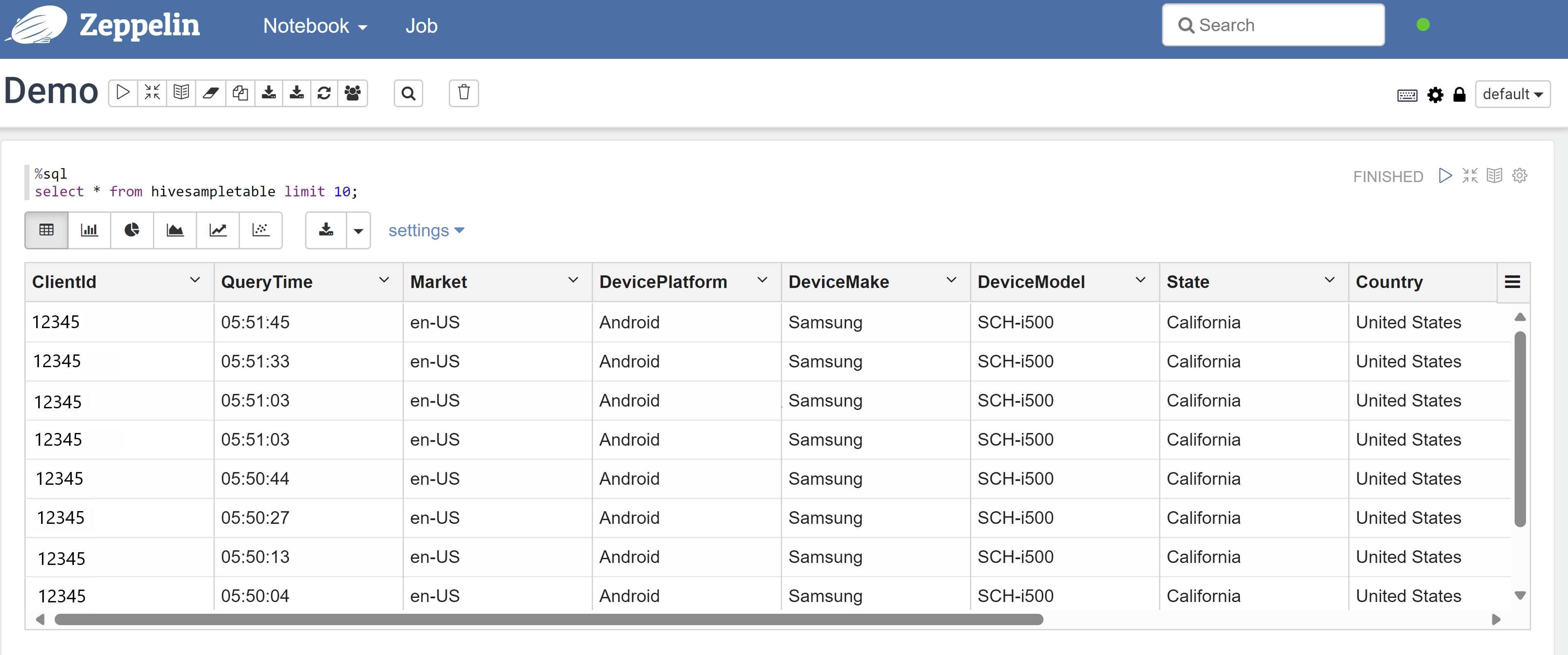
Aprire un notebook Zeppelin ed eseguire il comando seguente per verificare i criteri:
%sql select * from hivesampletable limit 10;Ecco il risultato prima dell'applicazione di un criterio:
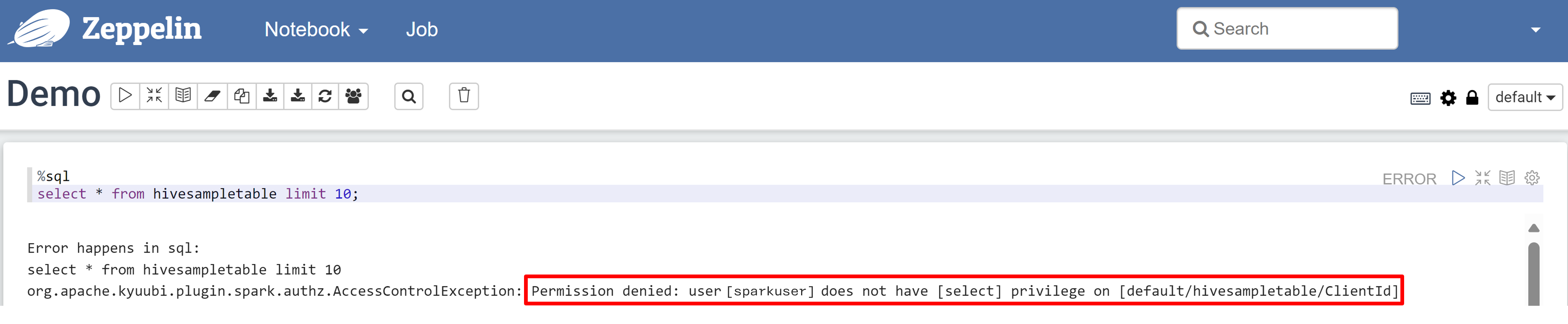
Ecco il risultato dopo l'applicazione di un criterio:




Creare un criterio di maschera ranger
Nell'esempio seguente viene illustrato come creare un criterio per mascherare una colonna:
Nella scheda Maschera selezionare Aggiungi nuovo criterio.
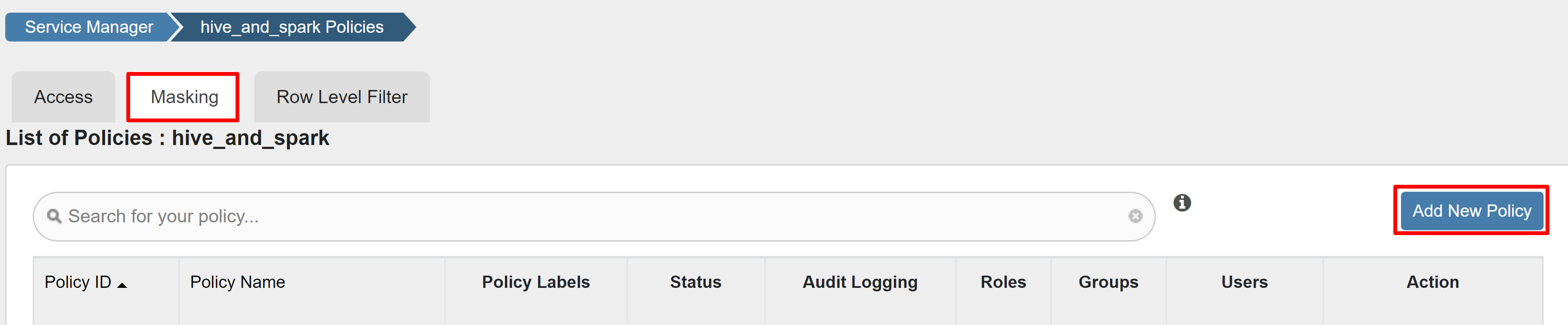
Immettere i valori seguenti:
Proprietà valore Nome criteri mask-hivesampletable Hive Database impostazione predefinita Tabella Hive hivesampletable Colonna Hive devicemake Seleziona utente sparkuserTipi di accesso select Selezionare l'opzione Maschera Hash 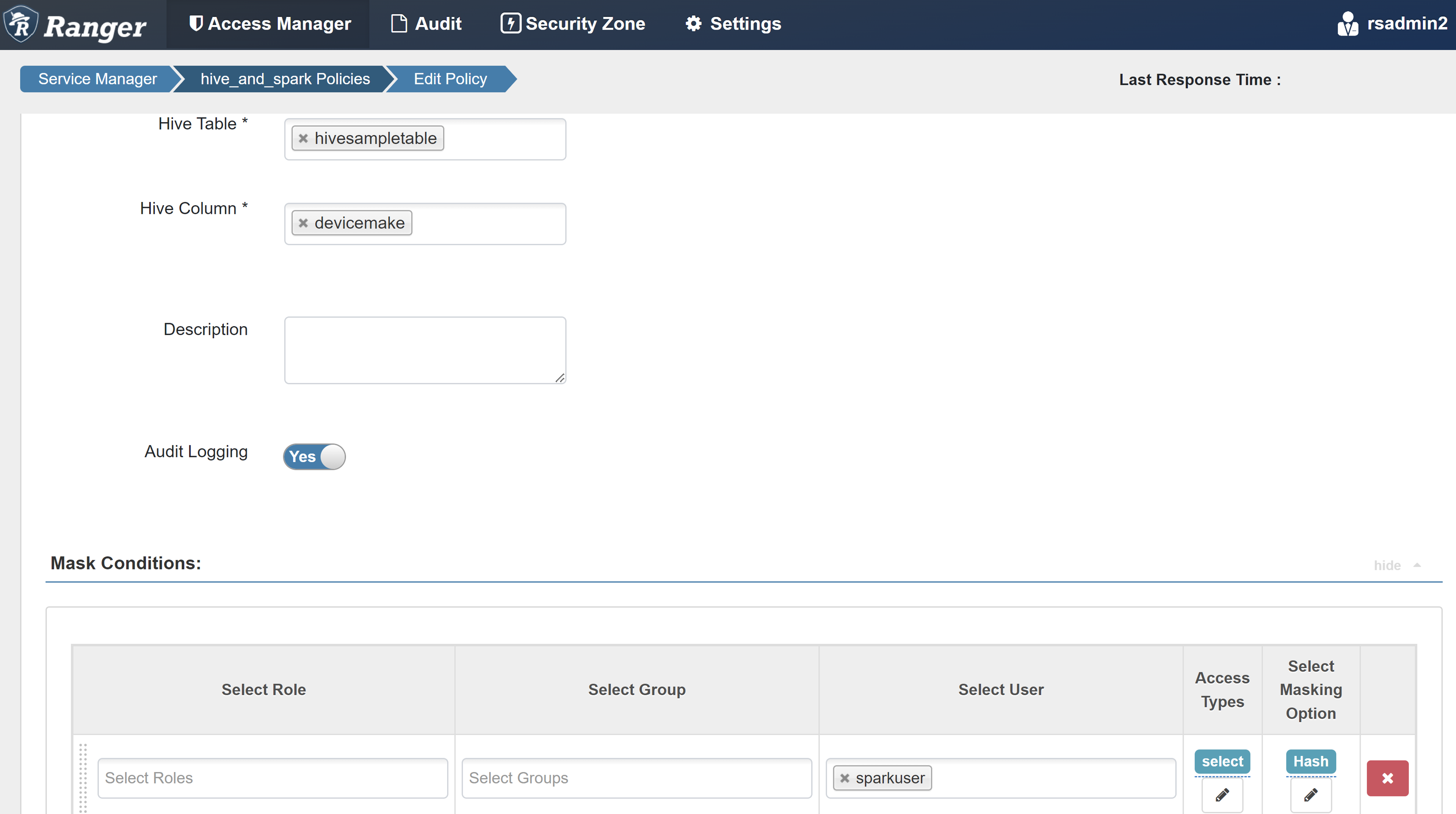
Selezionare Salva per salvare il criterio.
Aprire un notebook Zeppelin ed eseguire il comando seguente per verificare i criteri:
%sql select clientId, deviceMake from hivesampletable;



Nota
Per impostazione predefinita, i criteri per Hive e Spark SQL sono comuni in Ranger.
Applicare le linee guida per la configurazione di Apache Ranger per Spark SQL
Gli scenari seguenti illustrano le linee guida per la creazione di un cluster HDInsight 5.1 Spark usando un nuovo database Ranger e usando un database Ranger esistente.
Scenario 1: Usare un nuovo database Ranger durante la creazione di un cluster HdInsight 5.1 Spark
Quando si usa un nuovo database Ranger per creare un cluster, il repository Ranger pertinente che contiene i criteri Ranger per Hive e Spark viene creato con il nome hive_and_spark nel servizio SQL Hadoop nel database Ranger.

Se si modificano i criteri, vengono applicati sia a Hive che a Spark.
Considerare questi punti:
Se sono presenti due database metastore con lo stesso nome usato per i cataloghi Hive (ad esempio DB1) e Spark (ad esempio DB1):
- Se Spark usa il catalogo Spark (
metastore.catalog.default=spark), i criteri vengono applicati al database DB1 del catalogo Spark. - Se Spark usa il catalogo Hive (
metastore.catalog.default=hive), i criteri vengono applicati al database DB1 del catalogo Hive.
Dal punto di vista di Ranger, non è possibile distinguere tra DB1 dei cataloghi Hive e Spark.
In questi casi, è consigliabile:
- Usare il catalogo Hive sia per Hive che per Spark.
- Gestire nomi di database, tabelle e colonne diversi per i cataloghi Hive e Spark in modo che i criteri non vengano applicati ai database tra i cataloghi.
- Se Spark usa il catalogo Spark (
Se si usa il catalogo Hive sia per Hive che per Spark, prendere in considerazione l'esempio seguente.
Si supponga di creare una tabella denominata table1 tramite Hive con l'utente xyz corrente. Crea un file HDFS (Hadoop Distributed File System) denominato table1.db il cui proprietario è l'utente xyz .
Si supponga ora di usare l'utente abc per avviare la sessione Spark SQL. In questa sessione di user abc, se si tenta di scrivere qualcosa in table1, è associato a un errore perché il proprietario della tabella è xyz.
In questo caso, è consigliabile usare lo stesso utente in Hive e Spark SQL per aggiornare la tabella. L'utente deve disporre di privilegi sufficienti per eseguire operazioni di aggiornamento.
Scenario 2: usare un database Ranger esistente (con i criteri esistenti) durante la creazione di un cluster SPARK HDInsight 5.1
Quando si crea un cluster HDInsight 5.1 usando un database Ranger esistente, in questo database viene creato di nuovo un nuovo repository Ranger con il nome del nuovo cluster in questo formato: hive_and_spark.

Si supponga di avere i criteri definiti nel repository Ranger già con il nome oldclustername_hive nel database Ranger esistente all'interno del servizio SQL Hadoop. Si vogliono condividere gli stessi criteri nel nuovo cluster HDInsight 5.1 Spark. Per raggiungere questo obiettivo, seguire questa procedura.
Nota
Un utente con privilegi di amministratore Ambari può eseguire gli aggiornamenti della configurazione.
Aprire l'interfaccia utente di Ambari dal nuovo cluster HDInsight 5.1.
Passare al servizio Spark3 e quindi passare a Configurazioni.
Aprire la configurazione advanced ranger-spark-security .
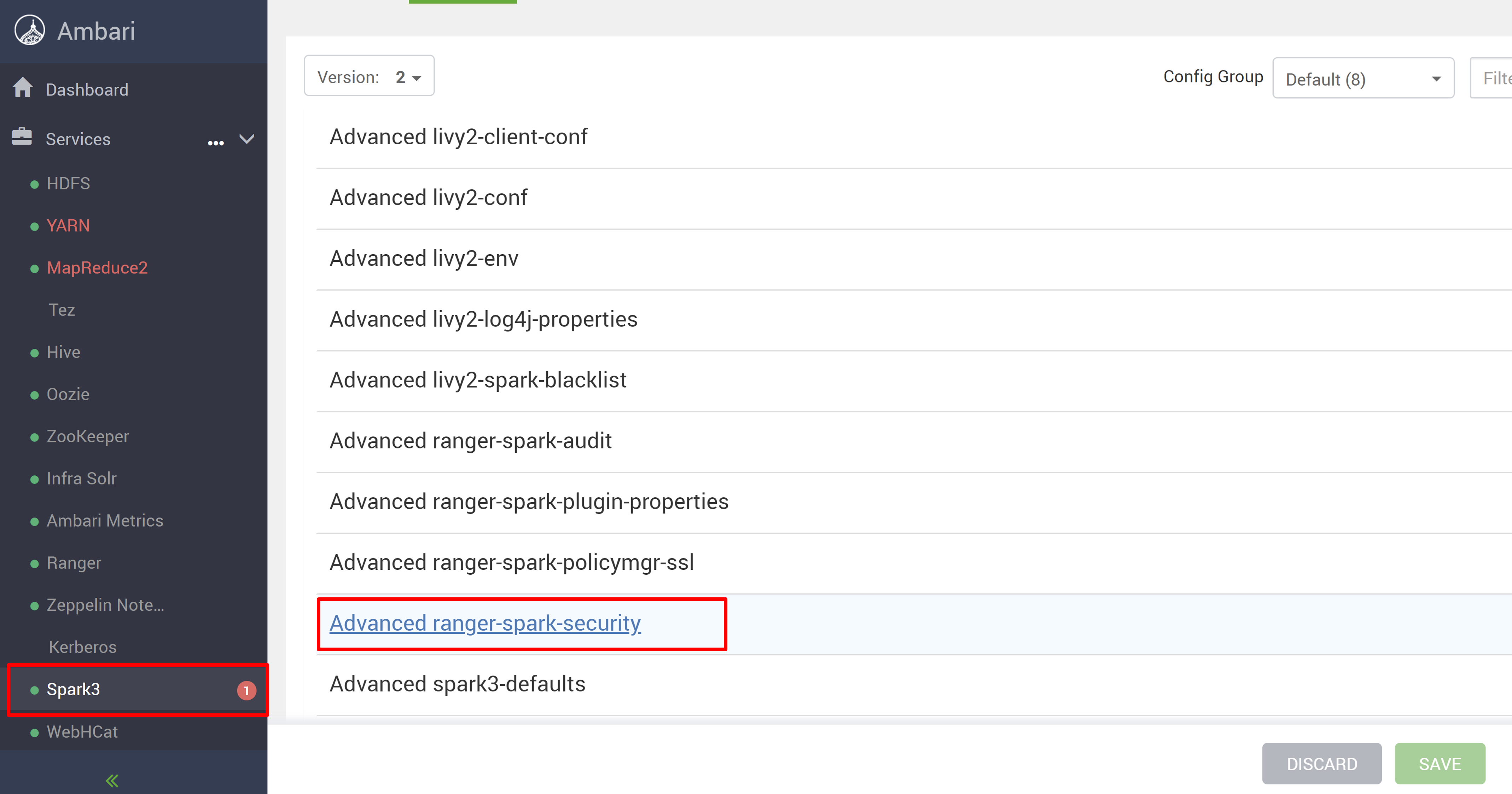
oppure È anche possibile aprire questa configurazione in /etc/spark3/conf usando SSH.
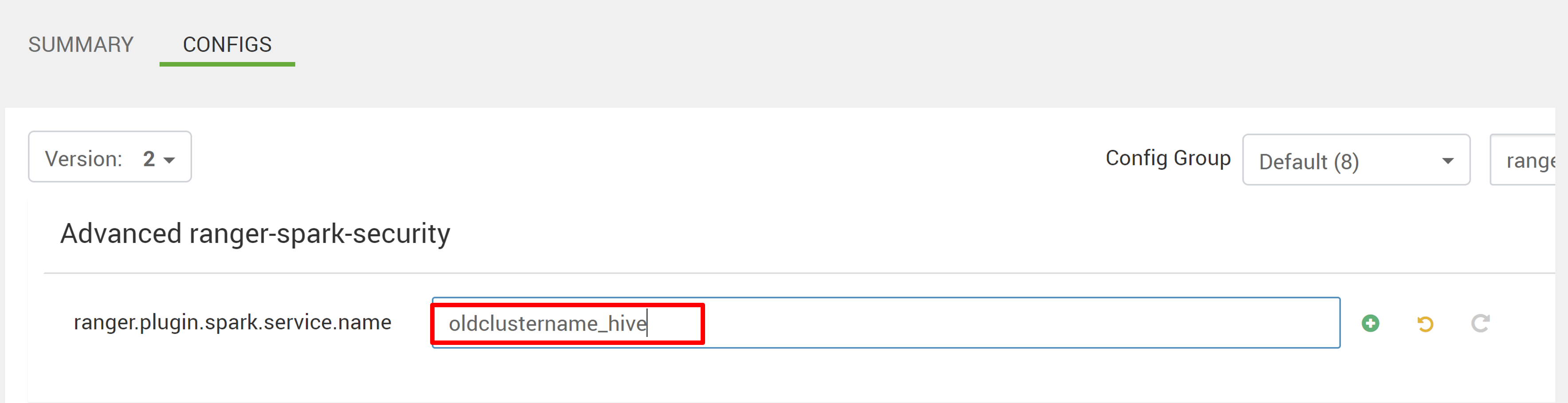
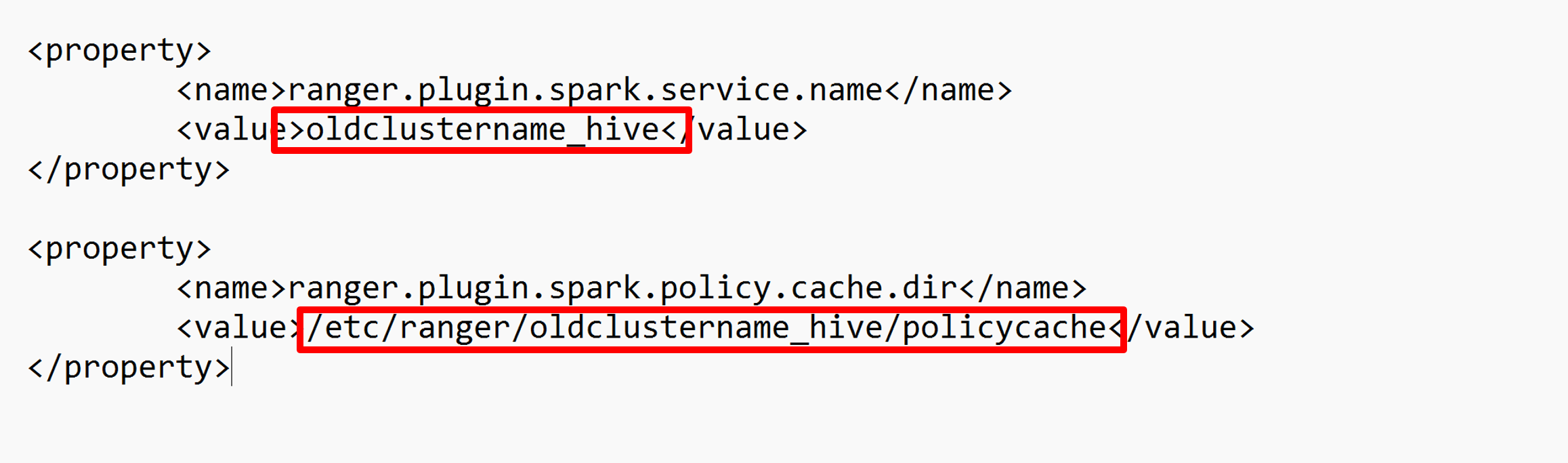
Modificare due configurazioni (ranger.plugin.spark.service.name e ranger.plugin.spark.policy.cache.dir) in modo che puntino al repository dei criteri precedente oldclustername_hive e quindi salvare le configurazioni.
Ambari:
File XML:
Riavviare i servizi Ranger e Spark da Ambari.
Aprire l'interfaccia utente di amministrazione di Ranger e fare clic sul pulsante Modifica nel servizio SQL HADOOP.

Per oldclustername_hive servizio, aggiungere l'utente rangersparklookup nell'elenco policy.download.auth.users e tag.download.auth.users e fare clic su Salva.






I criteri vengono applicati ai database nel catalogo Spark. Per accedere ai database nel catalogo Hive:
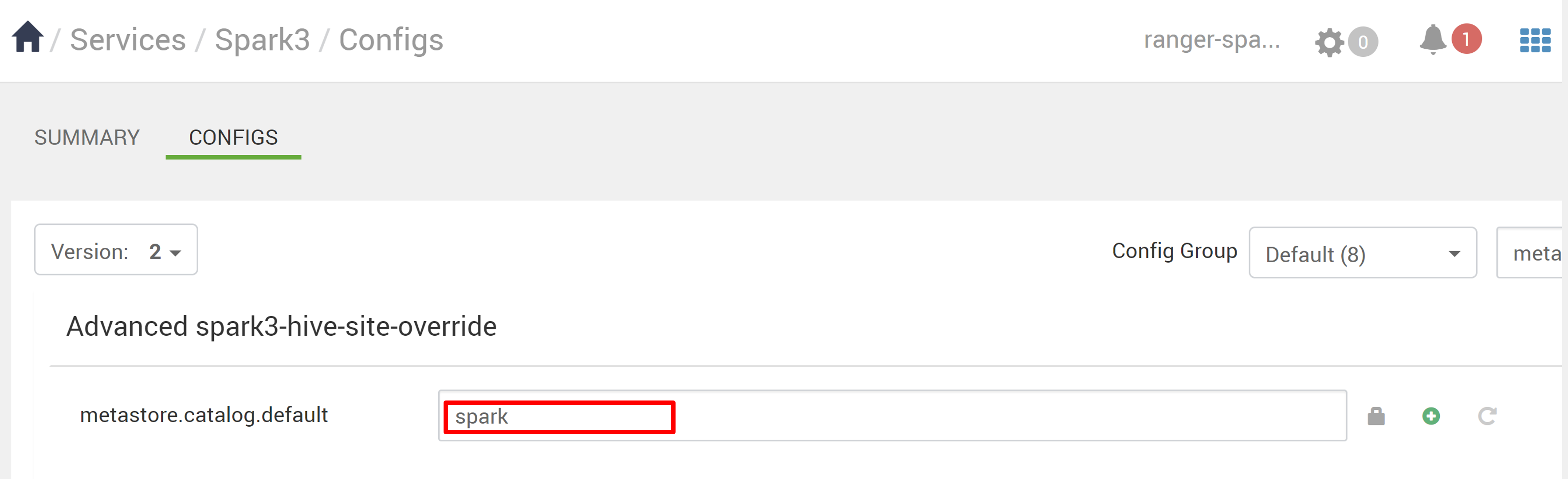
In Ambari passare a Configurazioni Spark3>.
Modificare metastore.catalog.default da spark a hive.

Problemi noti
- L'integrazione di Apache Ranger con Spark SQL non funziona se l'amministratore di Ranger è inattivo.
- Nei log di controllo di Ranger, quando si passa il puntatore del mouse sulla colonna Risorsa , non è possibile visualizzare l'intera query eseguita.