Risolvere i problemi di Apache Spark tramite Azure HDInsight
Informazioni sui problemi principali che possono verificarsi quando si usano i payload di Apache Spark in Apache Ambari unitamente alle risoluzioni.
Come si configura un'applicazione Apache Spark tramite Apache Ambari nei cluster?
I valori di configurazione di Spark possono essere ottimizzati per evitare un'eccezione OutofMemoryError dell'applicazione Apache Spark. I passaggi seguenti illustrano i valori di configurazione di Spark predefiniti in Azure HDInsight:
Accedere ad Ambari all'indirizzo
https://CLUSTERNAME.azurehdidnsight.netcon le credenziali del cluster. La schermata iniziale visualizza un dashboard generale. Esistono lievi differenze cosmetiche tra HDInsight 4.0.Andare a Spark2>Configurazioni.
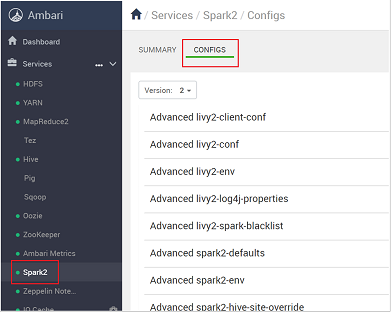
Nell'elenco delle configurazioni selezionare ed espandere Custom-spark2-defaults.
Ricercare l'impostazione del valore che si desidera modificare, come spark.executor.memory. In questo caso il valore 9728m è troppo alto.
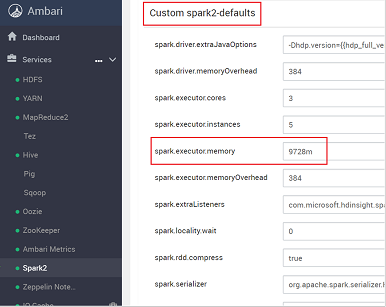
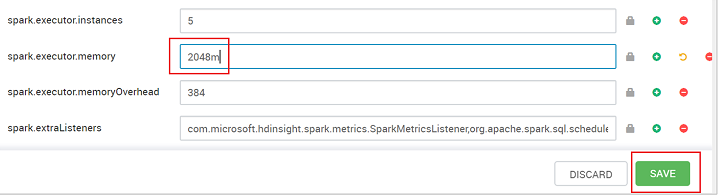
Configurare il valore sull'impostazione consigliata. Il valore 2048m è consigliato per questa impostazione.
Salvare il valore, quindi salvare la configurazione. Seleziona Salva.
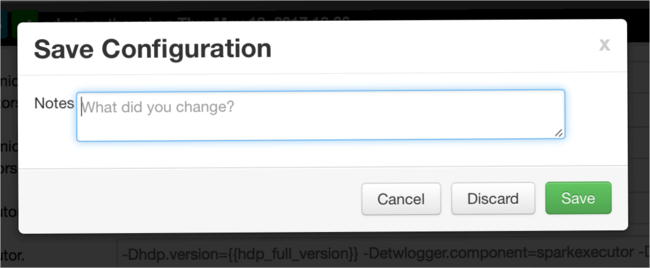
Immettere una nota sulle modifiche apportate alla configurazione, quindi selezionare Save (Salva).
Si riceve una notifica se una delle configurazioni richiede attenzione. Annotare gli elementi e quindi selezionare Proceed Anyway (Continuare comunque).

Ogni volta che viene salvata una configurazione, viene chiesto di riavviare il servizio. Seleziona Riavvia.
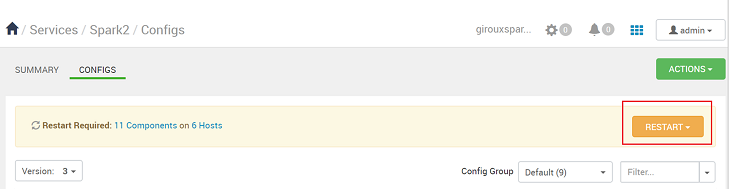
Confermare il riavvio.
È possibile esaminare i processi in esecuzione.
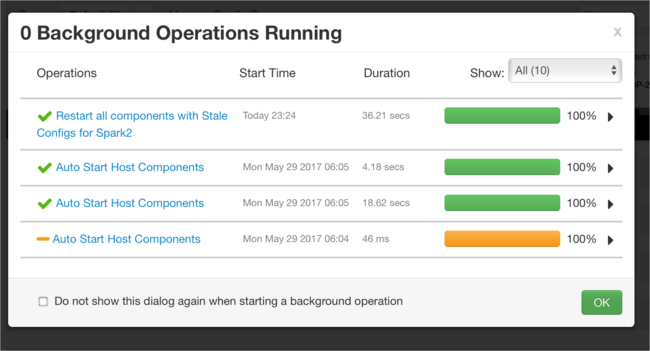
È possibile aggiungere configurazioni. Nell'elenco delle configurazioni selezionare Custom-spark2-defaults e quindi selezionare Add Property (Aggiungi proprietà).
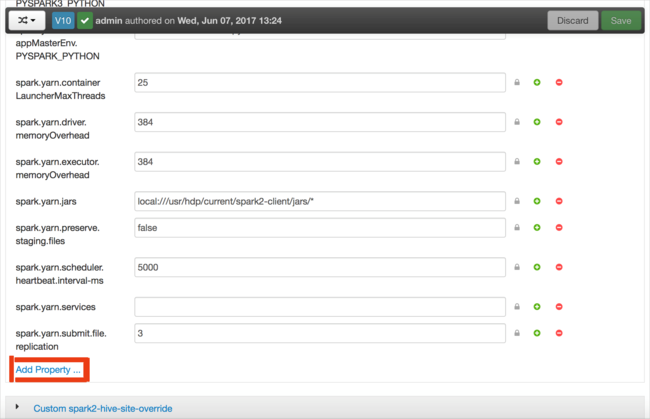
Definire una nuova proprietà. È possibile definire una singola proprietà usando una finestra di dialogo per impostazioni specifiche, ad esempio il tipo di dati. In alternativa, è possibile definire più proprietà usando una definizione per riga.
In questo esempio la proprietà spark.driver.memory è stata definita con un valore di 4g.
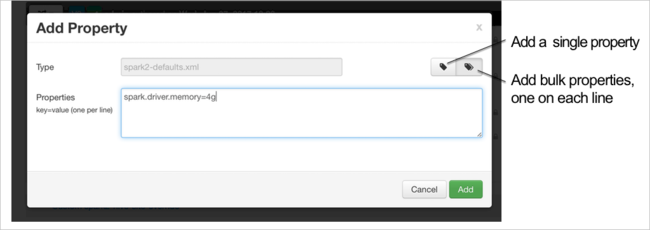
Salvare la configurazione e quindi riavviare il servizio come descritto nei passaggi 6 e 7.
Queste modifiche si applicano a tutto il cluster ma è possibile eseguirne l'override quando si invia il processo Spark.
Come si configura un'applicazione Apache Spark usando un notebook di Jupyter nei cluster?
Nella prima cella del Jupyter Notebook, dopo la direttiva %%configure, specificare le configurazioni di Spark in un formato JSON valido. Modificare i valori effettivi in base alla necessità:

Come si configura un'applicazione Apache Spark tramite Apache Livy nei cluster?
Inviare l'applicazione Spark a Livy usando un client REST come cURL. Usare un comando simile al seguente. Modificare i valori effettivi in base alla necessità:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Come si configura un'applicazione Apache Spark tramite lo script spark-submit nei cluster?
Avviare spark-shell usando un comando simile al seguente. Modificare il valore effettivo delle configurazioni in base alla necessità:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Lettura aggiuntiva
Invio del processo Apache Spark nei cluster HDInsight
Passaggi successivi
Se il problema riscontrato non è presente in questo elenco o se non si riesce a risolverlo, visitare uno dei canali seguenti per ottenere ulteriore assistenza:
Eseguire il debug dell'applicazione Spark nei cluster HDInsight.
Ricevere risposte dagli esperti di Azure tramite la pagina Supporto della community per Azure.
Connettersi con @AzureSupport, l'account ufficiale Microsoft Azure per migliorare l'esperienza del cliente. Mette in contatto la community di Azure con le risorse giuste: risposte, supporto ed esperti.
Se serve ulteriore assistenza, è possibile inviare una richiesta di supporto dal portale di Azure. Selezionare Supporto nella barra dei menu o aprire l'hub Guida e supporto. Per informazioni più dettagliate, vedere Come creare una richiesta di supporto in Azure. L'accesso al supporto per la gestione delle sottoscrizioni e la fatturazione è incluso nella sottoscrizione di Microsoft Azure e il supporto tecnico viene fornito tramite uno dei piani di supporto di Azure.