Panoramica di Apache Spark Streaming
Apache Spark Streaming fornisce l'elaborazione del flusso di dati nei cluster HDInsight Spark. Con una garanzia che qualsiasi evento di input venga elaborato esattamente una volta, anche se si verifica un errore del nodo. Un flusso Spark è un processo a esecuzione prolungata che riceve dati di input da un'ampia gamma di origini, tra cui Hub eventi di Azure. Inoltre: hub IoT di Azure, Apache Kafka, Apache Flume, X, ZeroMQ, socket TCP non elaborati o dal monitoraggio dei file system YARN apache Hadoop. A differenza di un processo basato esclusivamente su eventi, un flusso Spark inserisce in batch i dati di input nelle finestre temporali. Ad esempio una sezione di 2 secondi e quindi trasforma ogni batch di dati usando le operazioni di mapping, riduzione, join ed estrazione. Il flusso Spark scrive quindi i dati trasformati in file system, database, dashboard e nella console.
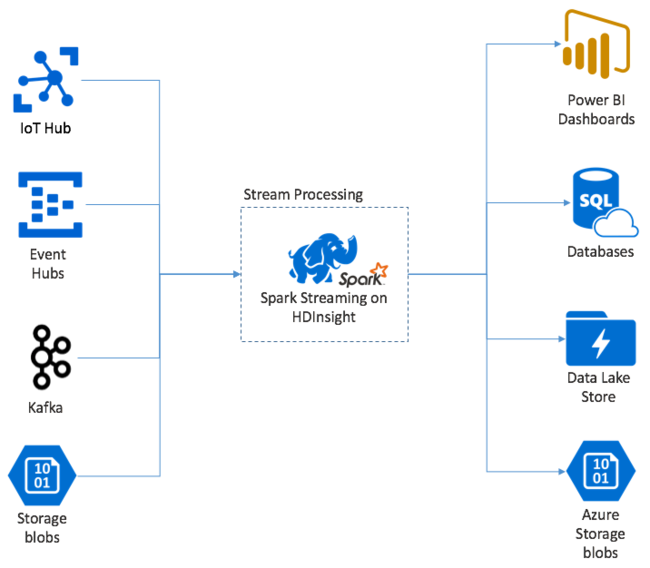
Le applicazioni Spark Streaming devono attendere una frazione di secondo per raccogliere ogni micro-batch evento prima di inviare tale batch per l'elaborazione. Al contrario, un'applicazione guidata dagli eventi elabora ogni evento immediatamente. La latenza di Spark Streaming è in genere inferiore a pochi secondi. I vantaggi dell'approccio basato su micro batch consistono in un'elaborazione dati più efficiente e in calcoli di aggregazione più semplici.
Introduzione a DStream
Spark Streaming rappresenta un flusso continuo di dati in ingresso con un flusso discretizzato chiamato DStream. È possibile creare un DStream da origini di input, ad esempio Hub eventi o Kafka. In alternativa, applicando trasformazioni a un altro DStream.
Un flusso DStream fornisce un livello di astrazione in aggiunta ai dati di evento non elaborati.
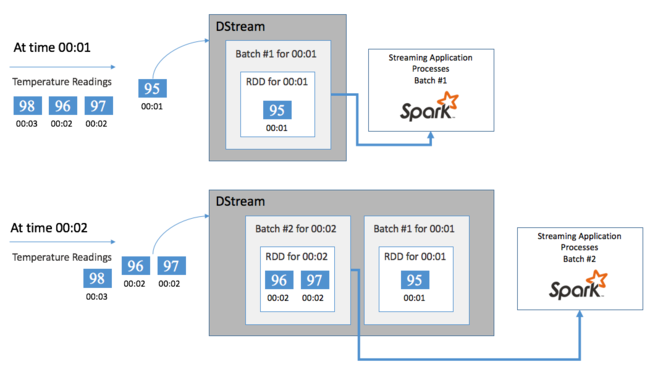
Iniziare con un singolo evento, ad esempio una lettura di temperatura da un termostato connesso. Quando questo evento arriva all'applicazione Spark Streaming, l'evento viene archiviato in modo affidabile, in cui viene replicato in più nodi. Questa tolleranza di errore garantisce che l'errore di un singolo nodo non comporterà la perdita dell'evento. Il core Spark usa una struttura di dati che distribuisce i dati tra più nodi del cluster. Dove ogni nodo mantiene in genere i propri dati in memoria per ottenere prestazioni ottimali. Questa struttura di dati viene chiamata RDD (Resilient Distributed Dataset, set di dati distribuito resiliente).
Ogni RDD rappresenta gli eventi raccolti in un intervallo di tempo definito dall'utente chiamato intervallo di invio in batch. Allo scadere di ogni intervallo di invio in batch, viene prodotto un nuovo RDD che contiene tutti i dati dell'intervallo. Il set continuo di RDD viene raccolto in un DStream. Ad esempio, se l'intervallo di invio in batch è lungo un secondo, il flusso DStream genera ogni secondo un batch che contiene un RDD, che a sua volta contiene tutti i dati inseriti durante il secondo. Durante l'elaborazione del flusso DStream, l'evento di temperatura appare in uno di questi batch. Un'applicazione Spark Streaming elabora i batch che contengono gli eventi e infine agisce sui dati archiviati in ogni RDD.
Struttura di un'applicazione Spark Streaming
Un'applicazione Spark Streaming è un'applicazione a esecuzione prolungata che riceve dati da origini di inserimento. Applica trasformazioni per elaborare i dati e quindi esegue il push dei dati in una o più destinazioni. La struttura di un'applicazione Spark Streaming è costituita da una parte statica e da una parte dinamica. La parte statica definisce la provenienza dei dati, l'elaborazione da eseguire sui dati. E dove dovrebbero andare i risultati. La parte dinamica consiste nell'esecuzione dell'applicazione a tempo indefinito, in attesa di un segnale di arresto.
Ad esempio, la semplice applicazione seguente riceve una riga di testo tramite un socket TCP e conteggia il numero di occorrenze di ogni parola.
Definire l'applicazione
La definizione della logica dell'applicazione è costituita da quattro passaggi:
- Creare un oggetto StreamingContext.
- Creare un flusso DStream da StreamingContext.
- Applicare trasformazioni al flusso DStream.
- Generare i risultati.
Questa definizione è statica e i dati non vengono elaborati fino a quando non si esegue l'applicazione.
Creare un oggetto StreamingContext
Creare un oggetto StreamingContext dall'oggetto SparkContext che punta al cluster. Quando si crea un oggetto StreamingContext, specificare la dimensione del batch in secondi, ad esempio:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Creare un flusso DStream
Con l'istanza StreamingContext creare un flusso DStream di input per l'origine di input. In questo caso, l'applicazione sta controllando l'aspetto dei nuovi file nella risorsa di archiviazione associata predefinita.
val lines = ssc.textFileStream("/uploads/Test/")
Applicare trasformazioni
Per implementare l'elaborazione, applicare trasformazioni nel flusso DStream. Questa applicazione riceve una riga di testo alla volta dal file, suddivide ogni riga in parole. Usa quindi un modello map-reduce per contare il numero di volte in cui viene visualizzata ogni parola.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Generare i risultati
Eseguire il push dei risultati delle trasformazioni nei sistemi di destinazione tramite l'applicazione di operazioni di output. In questo caso, il risultato di ogni esecuzione tramite il calcolo viene visualizzato nell'output della console.
wordCounts.print()
Eseguire l'applicazione
Avviare l'applicazione di streaming e proseguire l'esecuzione fino a quando non si riceve un segnale di arresto.
ssc.start()
ssc.awaitTermination()
Per informazioni dettagliate sull'API Di flusso Spark, vedere Apache Spark Streaming Programming Guide (Guida alla programmazione di Apache Spark Streaming).
L'applicazione di esempio seguente è indipendente e di conseguenza può essere eseguita all'interno di Jupyter Notebook. Questo esempio crea un'origine dati fittizia nella classe DummySource che restituisce il valore di un contatore e l'intervallo di tempo corrente in millisecondi ogni cinque secondi. Un nuovo oggetto StreamingContext è associato a un intervallo di invio in batch di 30 secondi. Ogni volta che viene creato un batch, l'applicazione di streaming esamina il set di dati RDD prodotto. Converte quindi il set di dati RDD in un dataframe Spark e crea una tabella temporanea nel dataframe.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Attendere circa 30 secondi dopo l'avvio dell'applicazione precedente. È quindi possibile eseguire periodicamente una query sul dataframe per visualizzare il set corrente di valori presenti nel batch, ad esempio usando questa query SQL:
%%sql
SELECT * FROM demo_numbers
L'output risultante è simile all'output seguente:
| value | Ora |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Sono presenti sei valori, perché DummySource crea un valore ogni 5 secondi e l'applicazione genera un batch ogni 30 secondi.
Finestre temporali scorrevoli
Per eseguire calcoli aggregati su DStream in un determinato periodo di tempo, ad esempio per ottenere una temperatura media negli ultimi due secondi, usare le sliding window operazioni incluse in Spark Streaming. Una finestra temporale scorrevole ha una durata (lunghezza della finestra) e un intervallo durante il quale viene valutato il contenuto della finestra (intervallo di scorrimento).
Le finestre temporali scorrevoli possono sovrapporsi, ad esempio è possibile definire una finestra con una lunghezza di due secondi, con scorrimento ogni secondo. Questa azione significa che ogni volta che si esegue un calcolo di aggregazione, la finestra includerà i dati dell'ultimo secondo della finestra precedente. E tutti i nuovi dati nel successivo un secondo.
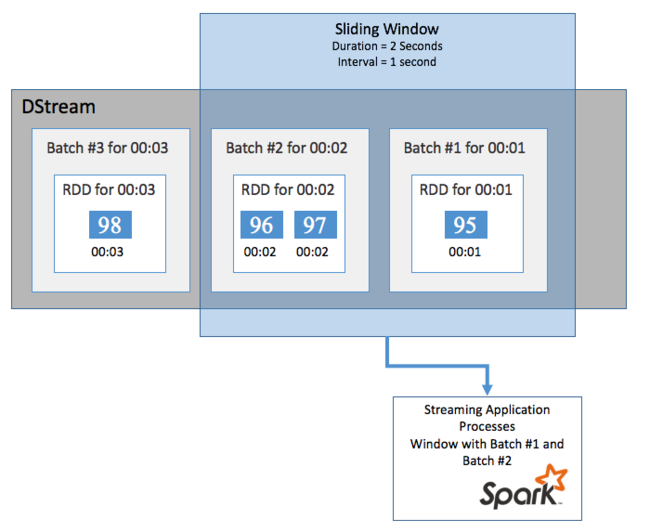
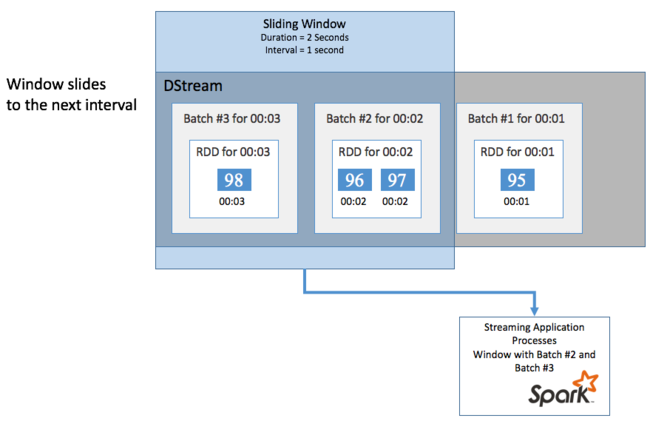
L'esempio seguente aggiorna il codice che usa DummySource per raccogliere i batch in una finestra con una durata di un minuto e uno scorrimento di un minuto.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Dopo il primo minuto sono presenti 12 voci, sei da ognuno dei due batch raccolti nella finestra.
| value | Ora |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Le funzioni di finestra temporale scorrevole disponibili nell'API di Spark Streaming includono window, countByWindow, reduceByWindow e countByValueAndWindow. Per informazioni dettagliate su queste funzioni, vedere Transformations on DStreams (Trasformazioni nei flussi DStream).
Checkpoint
Per offrire resilienza e tolleranza di errore, Spark Streaming usa checkpoint per garantire che l'elaborazione di flussi possa continuare senza interruzioni, anche in caso di errori dei nodi. Spark crea checkpoint per l'archiviazione durevole (Archiviazione di Azure o Data Lake Storage). Questi checkpoint archiviano i metadati dell'applicazione di streaming, ad esempio la configurazione e le operazioni definite dall'applicazione. Inoltre, tutti i batch accodati ma non ancora elaborati. In alcuni casi, i checkpoint includono anche il salvataggio dei dati nei set di dati RDD per ricompilare più rapidamente lo stato dei dati da ciò che è presente nei set di dati RDD gestiti da Spark.
Distribuzione di applicazioni Spark Streaming
In genere si compila un'applicazione Spark Streaming in locale in un file JAR. Distribuirlo quindi in Spark in HDInsight copiando il file JAR nella risorsa di archiviazione collegata predefinita. È possibile avviare l'applicazione tramite le API REST LIVY disponibili dal cluster usando un'operazione POST. Il corpo di POST include un documento JSON che fornisce il percorso del file JAR. E il nome della classe il cui metodo principale definisce ed esegue l'applicazione di streaming e, facoltativamente, i requisiti delle risorse del processo , ad esempio il numero di executor, memoria e core. Inoltre, tutte le impostazioni di configurazione richieste dal codice dell'applicazione.
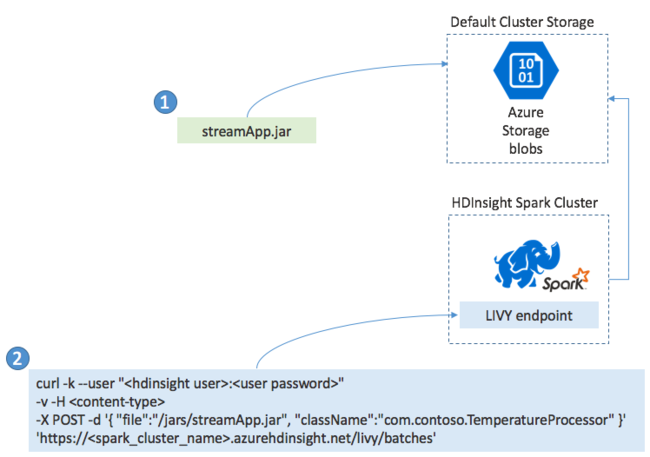
Lo stato di tutte le applicazioni può anche essere verificato con una richiesta GET su un endpoint LIVY. Infine, è possibile terminare un'applicazione in esecuzione inviando una richiesta DELETE sull'endpoint LIVY. Per informazioni dettagliate sull'API LIVY, vedere Processi remoti con Apache LIVY
Passaggi successivi
- Creare un cluster Apache Spark in HDInsight
- Apache Spark Streaming Programming Guide (Guida ad Apache Spark Streaming per programmatori)
- Panoramica di Apache Spark Structured Streaming