Analizzare i log di telemetria di Application Insights con Apache Spark in HDInsight
Informazioni su come usare Apache Spark in HDInsight per analizzare i dati di telemetria di Application Insights.
Visual Studio Application Insights è un servizio di analisi dei dati che consente di monitorare le applicazioni Web. I dati di telemetria generati da Application Insights possono essere esportati in Archiviazione di Azure. Una volta che i dati si trovano in Archiviazione di Azure, è possibile usare HDInsight per analizzarli.
Prerequisiti
Un'applicazione configurata per l'uso di Application Insights.
Familiarità con la creazione di un cluster HDInsight basato su Linux. Per altre informazioni, vedere Introduzione: Creare un cluster Apache Spark in Azure HDInsight.
Un Web browser.
Per lo sviluppo e il test di questo documento, sono state usate le risorse seguenti:
I dati di Application Insights Telemetry sono stati generati tramite un' app Web Node.js configurata per l'uso di Application Insights.
Per analizzare i dati, è stato usato uno Spark basato su Linux nel cluster HDInsight versione 3.5.
Architettura e pianificazione
Il diagramma seguente illustra l'architettura del servizio dell'esempio:
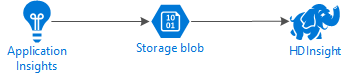
Archiviazione di Azure
Application Insights può essere configurato per l'esportazione continua delle informazioni di telemetria nei BLOB. HDInsight sarà quindi in grado di leggere i dati archiviati nei BLOB. Tuttavia, esistono alcuni requisiti da seguire:
Posizione: se l'account di archiviazione e HDInsight si trovano in posizioni diverse, la latenza potrebbe aumentare. Ciò comporta anche un aumento dei costi dal momento che vengono applicati costi di uscita per lo spostamento di dati tra le aree.
Avviso
L'uso di un account di archiviazione in una località diversa rispetto a HDInsight non è supportato.
Tipo di BLOB: in HDInsight sono supportati solo i BLOB in blocchi. Application Insights usa per impostazione predefinita i BLOB in blocchi, quindi funzionerà con HDInsight.
Per informazioni sull'aggiunta di spazio di archiviazione a un cluster esistente, vedere il documento Aggiungere altri account di archiviazione.
Schema dati
Application Insights offre informazione sul modello di esportazione dei dati per il formato di dati di telemetria esportati nei BLOB. La procedura descritta in questo documento usa Spark SQL per lavorare con i dati. Spark SQL può generare automaticamente uno schema per la struttura di dati JSON registrato da Application Insights.
Esportare i dati di telemetria
Seguire la procedura in Configurare l'esportazione continua per configurare Application Insights per l'esportazione delle informazioni di telemetria in un BLOB di Archiviazione di Azure.
Configurare HDInsight per l'accesso ai dati
Se si sta creando un cluster HDInsight, aggiungere l'account di archiviazione durante la creazione del cluster.
Per aggiungere l'account di Archiviazione di Azure a un cluster esistente, usare le informazioni riportate nel documento Aggiungere altri account di archiviazione.
Analizzare i dati: PySpark
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dove CLUSTERNAME è il nome del cluster.Nell'angolo superiore destro della pagina Jupyter selezionare Nuovo e quindi PySpark. Si apre una nuova scheda del browser contenente un notebook di Jupyter basato su Python.
Nel primo campo della pagina (denominato cella) immettere il testo seguente:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Questo codice configura Spark per l'accesso continuo alla struttura della directory per i dati di input. Application Insights Telemetry è connesso a una struttura di directory simile alla seguente:
/{telemetry type}/YYYY-MM-DD/{##}/.Premere MAIUSC+INVIO per eseguire il codice. Sul lato sinistro della cella viene visualizzato "*" tra parentesi per indicare che il codice contenuto nella cella è in esecuzione. Al termine, "*" viene sostituito da un numero e sotto la cella viene visualizzato un output simile al testo seguente:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Una nuova cella viene creata sotto la prima. Immettere il testo seguente nella nuova cella. Sostituire
CONTAINEReSTORAGEACCOUNTcon il nome dell'account di Archiviazione di Azure e il nome del contenitore BLOB che contiene dati di Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Premere MAIUSC+INVIO per eseguire la cella. Il risultato visualizzato è simile al testo seguente:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Il percorso wasbs restituito è il percorso dei dati di Application Insights Telemetry. Modificare la riga
hdfs dfs -lsnella cella per usare il percorso wasbs restituito e quindi premere MAIUSC+INVIO per eseguire di nuovo la cella. Questa volta, il risultato dovrebbe visualizzare le directory che contengono i dati di telemetria.Nota
Per il resto dei passaggi in questa sezione è stata usata la directory
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. La struttura della directory potrebbe essere diversa.Nella cella successiva immettere il codice seguente: sostituire
WASB_PATHcon il percorso del passaggio precedente.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Questo codice crea un frame di dati dai file JSON esportati dal processo di esportazione continua. Premere MAIUSC+INVIO per eseguire la cella.
Nella prossima cella, immettere ed eseguire il comando seguente per visualizzare lo schema Spark creato per i file JSON:
jsonData.printSchema()Lo schema per ogni tipo di dati di telemetria è diverso. Di seguito è riportato lo schema di esempio generato per le richieste Web (dati archiviati nella sottodirectory
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Per registrare il frame di dati come una tabella temporanea ed eseguire una query sui dati, usare quanto segue:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Questa query restituisce le informazioni sulla città per i primi 20 record in cui context.location.city non ha valore Null.
Nota
La struttura di contesto è presente in tutti i dati di telemetria registrati da Application Insights. L'elemento città potrebbe non essere popolato nei log. Usare lo schema per identificare altri elementi su cui è possibile eseguire una query che potrebbe contenere i dati per i log.
La query restituisce informazioni simili al testo seguente:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analizzare i dati: Scala
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dove CLUSTERNAME è il nome del cluster.Nell'angolo superiore destro della pagina Jupyter selezionare Nuovo e quindi Scala. Si apre una nuova scheda del browser contenente un notebook di Jupyter basato su Scala.
Nel primo campo della pagina (denominato cella) immettere il testo seguente:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Questo codice configura Spark per l'accesso continuo alla struttura della directory per i dati di input. Application Insights Telemetry è connesso a una struttura di directory simile alla seguente:
/{telemetry type}/YYYY-MM-DD/{##}/.Premere MAIUSC+INVIO per eseguire il codice. Sul lato sinistro della cella viene visualizzato "*" tra parentesi per indicare che il codice contenuto nella cella è in esecuzione. Al termine, "*" viene sostituito da un numero e sotto la cella viene visualizzato un output simile al testo seguente:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Una nuova cella viene creata sotto la prima. Immettere il testo seguente nella nuova cella. Sostituire
CONTAINEReSTORAGEACCOUNTcon il nome dell'account di Archiviazione di Azure e il nome del contenitore BLOB che contiene i log di Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Premere MAIUSC+INVIO per eseguire la cella. Il risultato visualizzato è simile al testo seguente:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Il percorso wasbs restituito è il percorso dei dati di Application Insights Telemetry. Modificare la riga
hdfs dfs -lsnella cella per usare il percorso wasbs restituito e quindi premere MAIUSC+INVIO per eseguire di nuovo la cella. Questa volta, il risultato dovrebbe visualizzare le directory che contengono i dati di telemetria.Nota
Per il resto dei passaggi in questa sezione è stata usata la directory
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Questa directory potrebbe non esistere, a meno che i dati di telemetria non siano destinati a un'app Web.Nella cella successiva immettere il codice seguente: sostituire
WASB\_PATHcon il percorso del passaggio precedente.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Questo codice crea un frame di dati dai file JSON esportati dal processo di esportazione continua. Premere MAIUSC+INVIO per eseguire la cella.
Nella prossima cella, immettere ed eseguire il comando seguente per visualizzare lo schema Spark creato per i file JSON:
jsonData.printSchemaLo schema per ogni tipo di dati di telemetria è diverso. Di seguito è riportato lo schema di esempio generato per le richieste Web (dati archiviati nella sottodirectory
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Per registrare il frame di dati come una tabella temporanea ed eseguire una query sui dati, usare quanto segue:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Questa query restituisce le informazioni sulla città per i primi 20 record in cui context.location.city non ha valore Null.
Nota
La struttura di contesto è presente in tutti i dati di telemetria registrati da Application Insights. L'elemento città potrebbe non essere popolato nei log. Usare lo schema per identificare altri elementi su cui è possibile eseguire una query che potrebbe contenere i dati per i log.
La query restituisce informazioni simili al testo seguente:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Passaggi successivi
Per altri esempi sull'uso di Apache Spark per lavorare con dati e servizi di Azure, vedere i documenti seguenti:
- Apache Spark con Business Intelligence: eseguire l'analisi interattiva dei dati con strumenti di Business Intelligence mediante Spark in HDInsight
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per l'analisi della temperatura di compilazione utilizzando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
Per informazioni sulla creazione e l'esecuzione delle applicazioni Spark, vedere i documenti seguenti: