Che cos'è Interactive Query in Azure HDInsight
Interactive Query (chiamato anche Apache Hive LLAP o Low Latency Analytical Processing) è un tipo di cluster di Azure HDInsight. Interactive Query supporta la memorizzazione nella cache in memoria, che rende le query Apache Hive più veloci e molto più interattive. I clienti usano Interactive Query per eseguire query sui dati archiviati in archiviazione di Azure e in Azure Data Lake Storage in modo estremamente veloce. Le query interattive permettono agli sviluppatori e ai data scientist di lavorare con maggiore facilità con i Big Data usando gli strumenti BI che preferiscono. HDInsight Interactive Query supporta diversi strumenti per accedere ai Big Data con facilità.
Un cluster Interactive Query è diverso da un cluster Apache Hadoop in quanto contiene solo il servizio Hive.
È possibile accedere al servizio Hive nel cluster Interactive Query solo tramite la vista Apache Hive di Ambari, Beeline e il driver Microsoft Hive Open Database Connectivity (Hive ODBC). Non è possibile accedervi tramite la console Hive, Templeton, l'interfaccia della riga di comando classica di Azure o Azure PowerShell.
Creare un cluster Interactive Query
Per informazioni sulla creazione di un cluster HDInsight, vedere Creare cluster Apache Hadoop in HDInsight. Scegliere un tipo di cluster Interactive Query.
Importante
La dimensione minima del nodo head per i cluster Interactive Query è Standard_D13_v2. Per altre informazioni, vedere grafico di ridimensionamento delle macchine virtuali di Azure.
Eseguire le query Apache Hive da Interactive Query
Per eseguire query Hive, sono disponibili le opzioni seguenti:
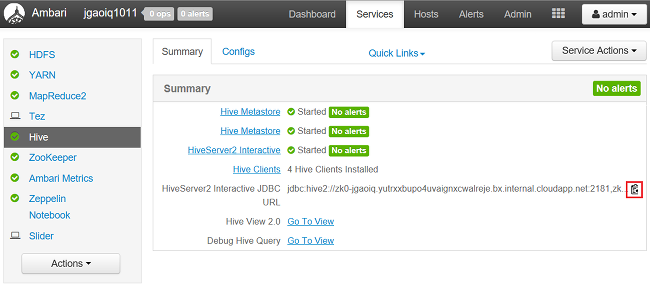
Per trovare la stringa di connessione JDBC (Java Database Connectivity):
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summarydoveCLUSTERNAMEè il nome del cluster.Per copiare l'URL, selezionare l'icona degli Appunti:
Passaggi successivi
- Leggere le informazioni su come creare cluster Interactive Query in HDInsight.
- Leggere le informazioni su come visualizzare Big Data con Power BI in Azure HDInsight.
- Leggere le informazioni su come usare Apache Zeppelin per eseguire query Apache Hive in Azure HDInsight.