Risolvere i problemi di YARN di Apache Hadoop usando Azure HDInsight
Informazioni sui problemi principali che possono verificarsi quando si usano i payload di Apache Hadoop YARN in Apache Ambari unitamente alle risoluzioni.
Come si crea una nuova coda YARN in un cluster?
Procedura per la risoluzione
Seguire questa procedura in Ambari per creare una nuova coda YARN e bilanciare l'allocazione delle capacità tra tutte le code.
In questo esempio è stata modificata la capacità dal 50% al 25% per due code esistenti (predefinita e thriftsvr), in modo da consentire alla nuova coda (Spark) di avere una capacità del 50%.
| Queue | Capacità | Capacità massima |
|---|---|---|
| impostazione predefinita | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Selezionare l'icona Visualizzazioni di Ambari e scegliere il motivo di griglia. Selezionare quindi YARN Queue Manager (Gestore code YARN).
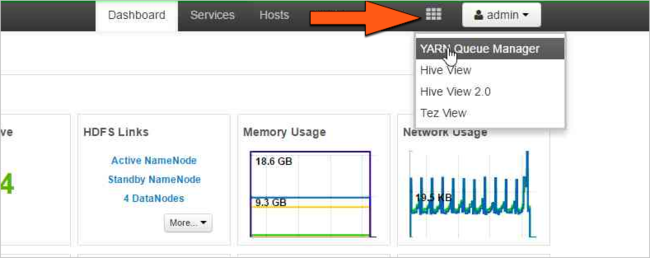
Selezionare la coda predefinita.
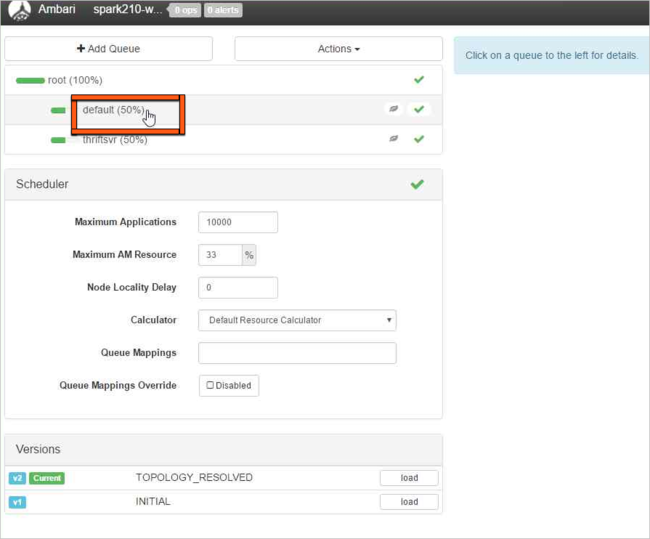
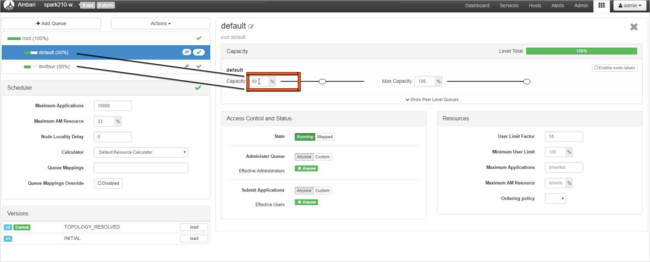
Per la coda predefinita, modificare la capacità dal 50% al 25%. Per la coda thriftsvr, impostare la capacità sul 25%.
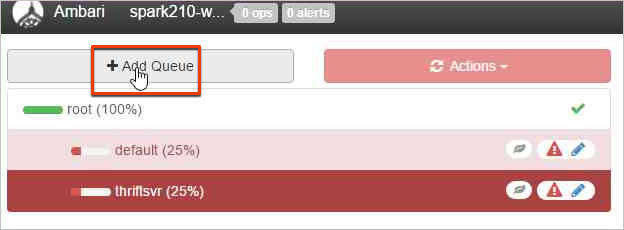
Per creare una nuova coda, fare clic su Aggiungi coda.
Assegnare un nome alla nuova coda.
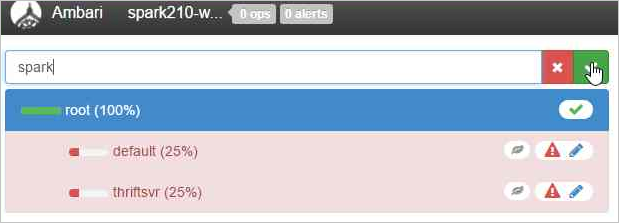
Lasciare i valori di Capacità al 50% e selezionare il pulsante Azioni.
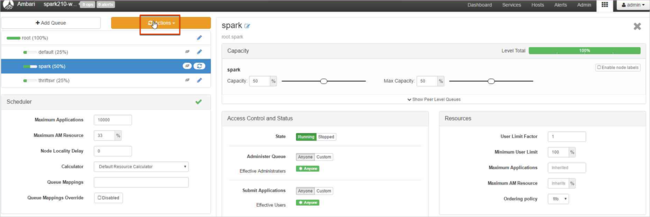
Selezionare Save and Refresh Queues (Salva e aggiorna code).
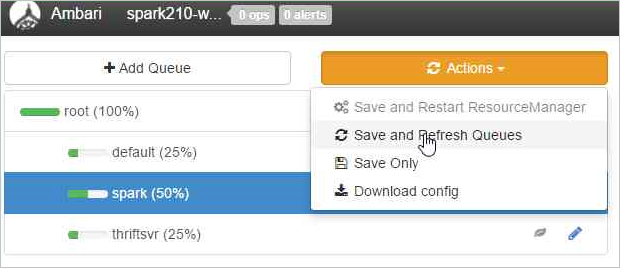
Queste modifiche saranno immediatamente visibili nell'interfaccia utente dell'utilità di pianificazione YARN.
Altre risorse
Come si scaricano i log di YARN da un cluster?
Procedura per la risoluzione
Connettersi al cluster HDInsight con un client Secure Shell (SSH). Per altre informazioni vedere Altre informazioni.
Elencare tutti gli ID applicazione delle applicazioni YARN attualmente in esecuzione con il comando seguente:
yarn topGli ID sono elencati nella colonna APPLICATIONID, di cui è necessario scaricare i log APPLICATIONID.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerPer scaricare i log dei contenitori YARN per tutti gli schemi dell'applicazione, usare il comando seguente:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtVerrà creato un file di log denominato amlogs.txt.
Per scaricare i log dei contenitori YARN solo per gli schemi dell'applicazione più recenti, usare il comando seguente:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtVerrà creato un file di log denominato latestamlogs.txt.
Per scaricare i log dei contenitori YARN per i primi due schemi dell'applicazione, usare il comando seguente:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtVerrà creato un file di log denominato first2amlogs.txt.
Per scaricare tutti i log dei contenitori YARN, usare il comando seguente:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtVerrà creato un file di log denominato logs.txt.
Per scaricare il log dei contenitori YARN per un determinato contenitore, usare il comando seguente:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtVerrà creato un file di log denominato containerlogs.txt.
Altre letture
- Connettersi a HDInsight (Apache Hadoop) con SSH
- Apache Hadoop YARN concepts and applications (Concetti e applicazioni di Apache Hadoop YARN)
Come è possibile controllare le informazioni di Diagnostica applicazioni YARN?
La diagnostica nell'interfaccia utente di Yarn è una funzionalità che consente di visualizzare lo stato e i log delle applicazioni in esecuzione in Yarn. La diagnostica consente di risolvere i problemi e di eseguire il debug delle applicazioni, oltre a monitorare le prestazioni e l'utilizzo delle risorse.
Per visualizzare la diagnostica di un'applicazione specifica fare clic sull'ID applicazione nell'elenco delle applicazioni. Nella pagina dei dettagli dell'applicazione è anche possibile visualizzare un elenco di tutti i tentativi effettuati per eseguire l'applicazione. È possibile fare clic su qualsiasi tentativo per visualizzare altri dettagli, ad esempio l'ID tentativo, l'ID contenitore, l'ID nodo, l'ora di inizio, l'ora di fine e la diagnostica
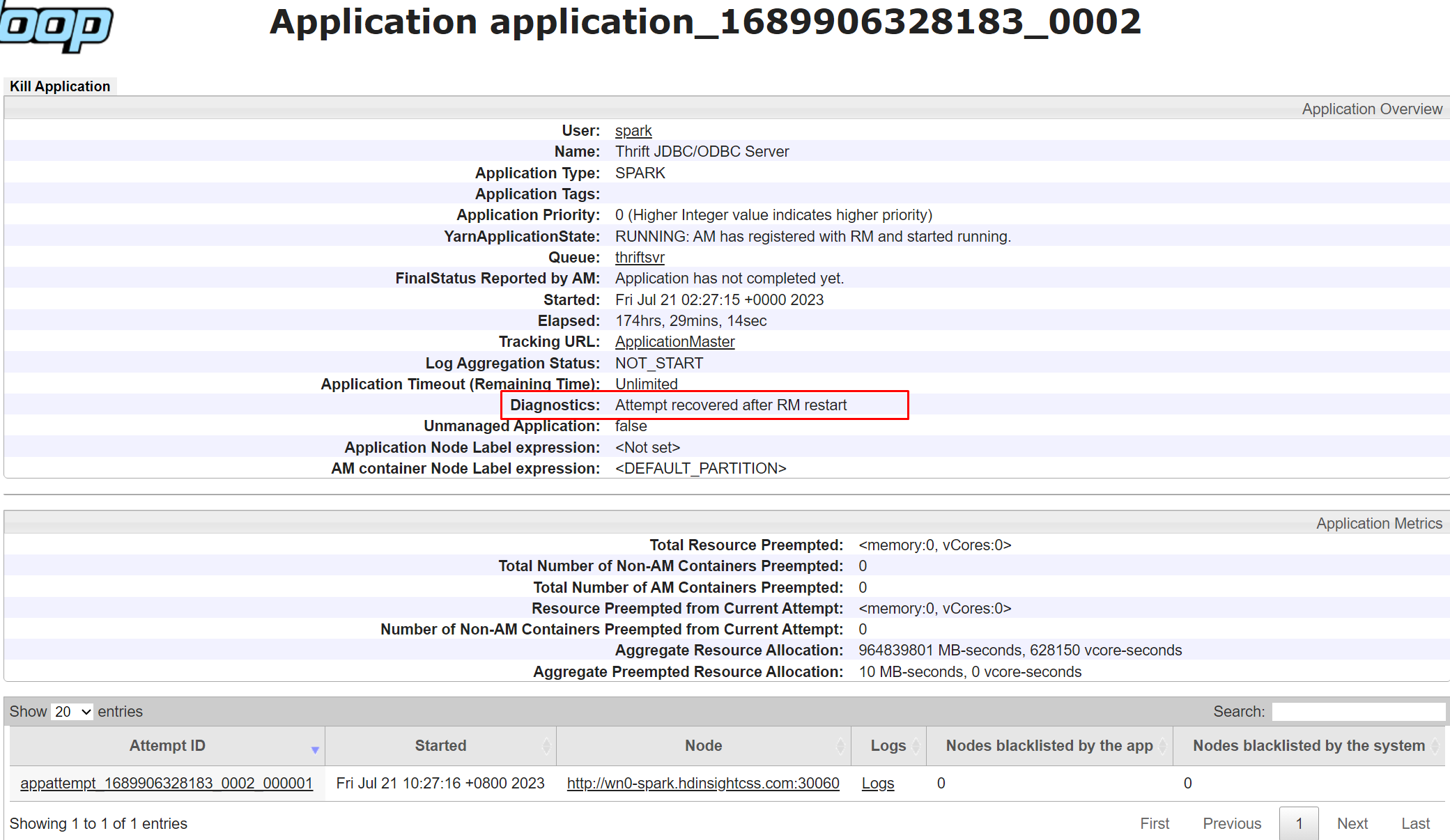
Come risolvere i problemi comuni di YARN?
L'interfaccia utente di YARN non viene caricata
Se l'interfaccia utente di YARN non viene caricata o non è raggiungibile e restituisce "Errore HTTP 502.3 - Gateway non valido", significa che il servizio Gestione risorse non è integro. Per mitigare il problema, seguire questa procedura:
- Passare a Interfaccia utente di Ambari>YARN>RIEPILOGO e verificare se il servizio Gestione risorse è attivo ed è l’unico nello stato Avviato. In caso contrario, provare a risolvere il problema riavviando il servizio Gestione risorse non integro o arrestato.
- Se il passaggio 1 non risolve il problema, connettersi tramite SSH per il nodo head del servizio Gestione risorse attivo e controllare lo stato di Garbage Collection (GC )usando
jstat -gcutil <Resource Manager pid> 1000 100. Se FGCT aumenta in modo significativo in pochi secondi, significa che il servizio Gestione risorse è occupato ad eseguire il GC completo e non è in grado di elaborare le altre richieste. - Passare a Interfaccia utente di Ambari>YARN>CONFIGS>Avanzate e aumentare
Resource Manager java heap size. - Riavviare i servizi obbligatori nell'interfaccia utente di Ambari.
Entrambi i gestori di risorse sono in modalità standby
- Controllare il log di Gestione risorse per verificare se è presente un errore simile.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Se l'errore esiste, verificare se alcuni file sono in fase di replica o se sono in HDFS mancano blocchi. È possibile eseguire
hdfs fsck hdfs://mycluster/Eseguire
hdfs fsck hdfs://mycluster/ -deleteper pulire forzatamente l’HDFS e per eliminare il problema di standby RM. In alternativa, eseguire PatchYarnNodeLabel in uno dei nodi head per applicare la patch al cluster.
Passaggi successivi
Se il problema riscontrato non è presente in questo elenco o se non si riesce a risolverlo, visitare uno dei canali seguenti per ottenere ulteriore assistenza:
Ricevere risposte dagli esperti di Azure tramite la pagina Supporto della community per Azure.
Connettersi con @AzureSupport, l'account ufficiale Microsoft Azure per migliorare l'esperienza del cliente. Mette in contatto la community di Azure con le risorse giuste: risposte, supporto ed esperti.
Se serve ulteriore assistenza, è possibile inviare una richiesta di supporto dal portale di Azure. Selezionare Supporto nella barra dei menu o aprire l'hub Guida e supporto. Per informazioni più dettagliate, vedere Come creare una richiesta di supporto in Azure. L'accesso al supporto per la gestione delle sottoscrizioni e la fatturazione è incluso nella sottoscrizione di Microsoft Azure e il supporto tecnico viene fornito tramite uno dei piani di supporto di Azure.