Rendere operativa una pipeline di analisi dei dati
Le pipeline di dati sono alla base di molte soluzioni di analisi dei dati. Come suggerisce il nome, una pipeline di dati accetta dati non elaborati, pulisce e la modifica in base alle esigenze, quindi esegue in genere calcoli o aggregazioni prima di archiviare i dati elaborati. che vengono utilizzati da client, report o API. Una pipeline di dati deve fornire risultati ripetibili, in base a una pianificazione o quando attivata da nuovi dati.
Questo articolo descrive come rendere operative le pipeline di dati per la ripetibilità usando Oozie in esecuzione su cluster HDInsight Hadoop. Lo scenario di esempio illustra una pipeline di dati che prepara ed elabora i dati temporali relativi ai voli di compagnie aeree.
Nello scenario seguente i dati di input sono costituiti da un file flat contenente un batch di dati sui voli nell'intervallo di un mese. Sono incluse informazioni come gli aeroporti di origine e di destinazione, le distanze percorse, gli orari di partenza e arrivo e così via. Questa pipeline ha lo scopo di fornire un riepilogo delle prestazioni giornaliere delle compagnie aeree, dove per ciascuna compagnia è riportata, per ogni giorno, una riga con i dati relativi alla media dei ritardi in partenza e in arrivo, espressi in minuti, e alla distanza totale percorsa in tale giorno.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
La pipeline di esempio rimane in attesa finché non riceve i dati sui voli relativi a un nuovo periodo e quindi archivia le informazioni dettagliate sui voli nel data warehouse di Apache Hive per l'analisi a lungo termine. La pipeline crea anche un set di dati molto più piccolo contenente il riepilogo dei dati giornalieri sui voli. Questi dati di riepilogo dei voli giornalieri vengono inviati a un database SQL per fornire report, ad esempio per un sito Web.
Il diagramma seguente illustra la pipeline di esempio.
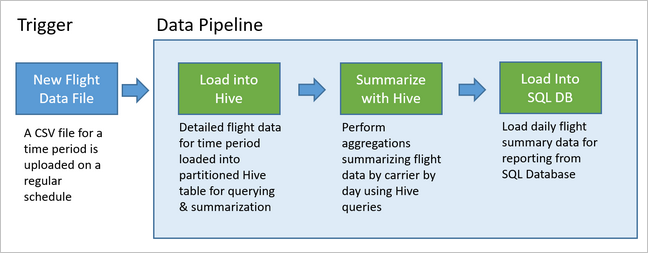
Panoramica della soluzione Apache Oozie
Questa pipeline usa Apache Oozie in esecuzione su un cluster HDInsight Hadoop.
In Oozie le pipeline sono descritte in termini di azioni, flussi di lavoro e coordinatori. Le azioni determinano l'effettiva operazione da eseguire, ad esempio una query Hive. I flussi di lavoro definiscono la sequenza di azioni. I coordinatori definiscono la pianificazione per l'esecuzione del flusso di lavoro. I coordinatori possono anche attendere che siano disponibili nuovi dati prima di avviare un'istanza del flusso di lavoro.
Il diagramma seguente mostra la struttura generale di questa pipeline Oozie di esempio.
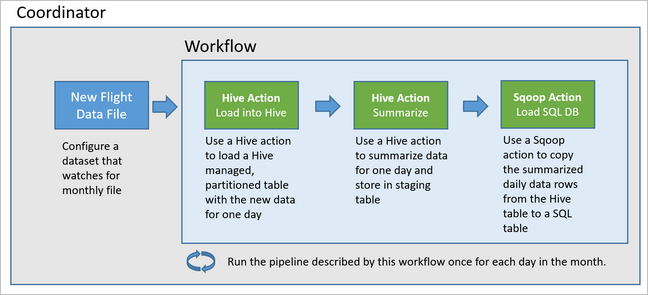
Effettuare il provisioning delle risorse di Azure
Per questa pipeline sono necessari un database SQL di Azure e un cluster HDInsight Hadoop nella stessa posizione. Il database SQL di Azure archivia sia i dati di riepilogo prodotti dalla pipeline che l'archivio metadati Oozie.
Effettuare il provisioning del database SQL di Azure
Creare un database SQL di Azure. Vedere Creare un database SQL di Azure nel portale di Azure.
Per assicurarsi che il cluster HDInsight possa accedere al database SQL di Azure connesso, configurare database SQL di Azure regole del firewall per consentire ai servizi e alle risorse di Azure di accedere al server. È possibile abilitare questa opzione nel portale di Azure selezionando Imposta firewall del server e selezionando SÌ sotto Consenti ai servizi e alle risorse di Azure di accedere a questo server per database SQL di Azure. Per altre informazioni, vedere Creare e gestire le regole del firewall IP.
Usare l'editor di query per eseguire le istruzioni SQL seguenti per creare la
dailyflightstabella che archivierà i dati riepilogati da ogni esecuzione della pipeline.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
A questo punto, il database SQL di Azure è pronto.
Effettuare il provisioning di un cluster Apache Hadoop
Creare un cluster Apache Hadoop con un metastore personalizzato. Durante la creazione del cluster dal portale, nella scheda Archiviazione assicurarsi di selezionare il database SQL in Impostazioni metastore. Per altre informazioni sulla selezione di un metastore, vedere Selezionare un metastore personalizzato durante la creazione del cluster. Per altre informazioni sulla creazione del cluster, vedere Introduzione a HDInsight in Linux.
Verificare la configurazione del tunneling SSH
Per usare Oozie Web Console per visualizzare lo stato delle istanze di coordinatore e flusso di lavoro, configurare un tunnel SSH al cluster HDInsight. Per altre informazioni, vedere Tunneling SSH.
Nota
Per individuare le risorse Web del cluster attraverso il tunnel SSH è anche possibile usare Chrome con l'estensione Foxy Proxy. Configurarlo per l'uso di un proxy in modo da indirizzare tutte le richieste tramite l'host localhost sulla porta 9876 del tunnel. Questo approccio è compatibile con il sottosistema Windows per Linux, noto anche come Bash in Windows 10.
Eseguire il comando seguente per aprire un tunnel SSH al cluster, dove
CLUSTERNAMEè il nome del cluster:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerificare che il tunnel sia operativo passando ad Ambari sul nodo head all'indirizzo seguente:
http://headnodehost:8080Per accedere alla console Web di Oozie dall'interno di Ambari, passare a Collegamenti> rapidi Oozie>[Server attivo]> Oozie Web UI.
Configurare Hive
Caricare dati
Scaricare un file di esempio con estensione csv che contiene i dati sui voli relativi a un mese. Scaricare il file ZIP corrispondente,
2017-01-FlightData.zip, dal repository di GitHub per HDInsight e decomprimerlo nel file CSV,2017-01-FlightData.csv.Copiare il file con estensione csv nell'account di Archiviazione di Azure associato al cluster HDInsight e inserirlo nella cartella
/example/data/flights.Usare SCP per copiare i file dal computer locale nella risorsa di archiviazione locale del nodo head del cluster HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvUsare il comando ssh per connettersi al cluster. Modificare il comando seguente sostituendo
CLUSTERNAMEcon il nome del cluster in uso e quindi immettere il comando:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDalla sessione SSH usare il comando HDFS per copiare il file dalla risorsa di archiviazione locale del nodo head in Archiviazione di Azure.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Creare tabelle
I dati di esempio sono ora disponibili, ma la pipeline richiede due tabelle Hive per l'elaborazione, rispettivamente per i dati in ingresso (rawFlights) e per i dati di riepilogo (flights). Creare le tabelle in Ambari, come indicato di seguito.
Accedere ad Ambari usando l'indirizzo
http://headnodehost:8080.Dall'elenco dei servizi selezionare Hive.
Selezionare Go To View (Vai a visualizzazione) accanto all'etichetta Hive View 2.0.
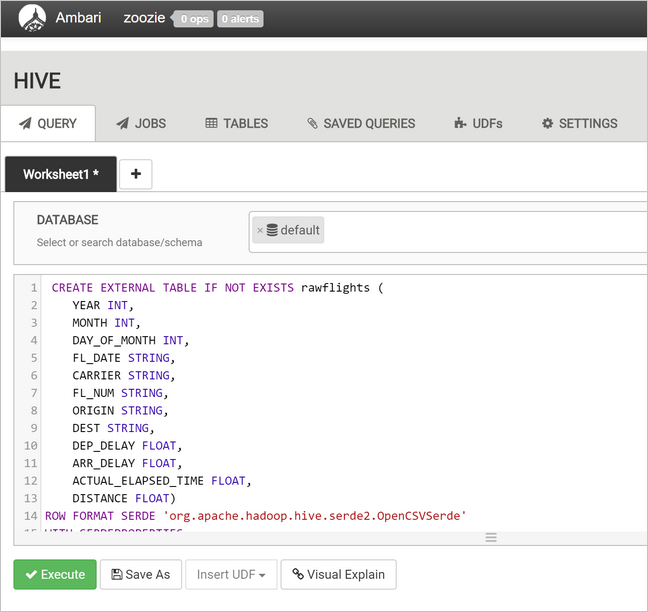
Nell'area di testo della query incollare le istruzioni seguenti per creare la tabella
rawFlights. La tabellarawFlightsfornisce uno schema in lettura per i file con estensione csv all'interno della cartella/example/data/flightsin Archiviazione di Azure.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Selezionare Execute (Esegui) per creare la tabella.
Per creare la tabella
flights, sostituire il testo presente nell'area di testo della query con le istruzioni seguenti. Laflightstabella è una tabella gestita da Hive che partiziona i dati caricati in esso per anno, mese e giorno del mese. Questa tabella conterrà tutti i dati cronologici sui voli con il livello di granularità più basso presente nell'origine dati, ovvero una riga per volo.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Selezionare Execute (Esegui) per creare la tabella.
Creare il flusso di lavoro Oozie
Le pipeline in genere elaborano i dati in batch in base a un determinato intervallo di tempo. In questo caso, la pipeline elabora i dati sui voli con frequenza giornaliera. Questo approccio consente alla pipeline di ricevere i file di input con estensione csv in base a una frequenza giornaliera, settimanale, mensile o annuale.
Il flusso di lavoro di esempio elabora il dati sui voli giorno per giorno, in tre passaggi principali:
- Eseguire una query Hive per estrarre i dati relativi al giorno specifico dal file con estensione csv di origine rappresentato dalla tabella
rawFlightse inserire i dati nella tabellaflights. - Eseguire una query Hive per creare dinamicamente una tabella di staging in Hive per tale giorno, contenente una copia dei dati sui voli riepilogati in base al giorno e al vettore.
- Usare Apache Sqoop per copiare tutti i dati dalla tabella di staging giornaliera in Hive alla tabella
dailyflightsdi destinazione nel database SQL di Azure. Sqoop legge le righe di origine dai dati sottostanti alla tabella Hive che si trovano in Archiviazione di Azure e li carica nel database SQL tramite una connessione JDBC.
Questi tre passaggi vengono coordinati da un flusso di lavoro Oozie.
Dalla workstation locale creare un file denominato
job.properties. Usare il testo seguente come contenuto iniziale per il file. Aggiornare quindi i valori per l'ambiente specifico. La tabella seguente riepiloga ognuna delle proprietà e indica dove trovare i valori per il proprio ambiente.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Proprietà Origine del valore nameNode Percorso completo del contenitore di Archiviazione di Azure associato al cluster HDInsight. jobTracker Nome host interno del nodo head YARN del cluster attivo. Nella home page di Ambari selezionare YARN dall'elenco dei servizi e quindi scegliere Active Resource Manager. L'URI del nome host viene visualizzato nella parte superiore della pagina. Accodare il numero di porta 8050. queueName Nome della coda YARN usata per la pianificazione delle azioni Hive. Lasciare il valore predefinito. oozie.use.system.libpath Lasciare il valore true. appBase Percorso della sottocartella di Archiviazione di Azure in cui si distribuiscono i file di supporto e di flusso di lavoro Oozie. oozie.wf.application.path Percorso per l'esecuzione del flusso di lavoro Oozie workflow.xml.hiveScriptLoadPartition Percorso del file di query Hive hive-load-flights-partition.hqlin Archiviazione di Azure.hiveScriptCreateDailyTable Percorso del file di query Hive hive-create-daily-summary-table.hqlin Archiviazione di Azure.hiveDailyTableName Nome generato dinamicamente da usare per la tabella di staging. hiveDataFolder Percorso dei dati contenuti nella tabella di staging in Archiviazione di Azure. sqlDatabaseConnectionString Stringa di connessione JDBC al database SQL di Azure. sqlDatabaseTableName Nome della tabella del database SQL di Azure in cui vengono inserite le righe di riepilogo. Lasciare dailyflights.year Componente anno della data per cui vengono calcolati i dati di riepilogo sui voli. Lasciare invariato. mese Componente mese della data per cui vengono calcolati i dati di riepilogo sui voli. Lasciare invariato. Giorno Componente giorno della data per cui vengono calcolati i dati di riepilogo sui voli. Lasciare invariato. Dalla workstation locale creare un file denominato
hive-load-flights-partition.hql. Usare il codice seguente come contenuto per il file.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Per le variabili di Oozie viene usata la sintassi
${variableName}. Queste variabili vengono impostate neljob.propertiesfile. Oozie sostituisce i valori effettivi in fase di runtime.Dalla workstation locale creare un file denominato
hive-create-daily-summary-table.hql. Usare il codice seguente come contenuto per il file.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Questa query genera una tabella di staging che archivierà i dati di riepilogo relativi a un singolo giorno. Prendere nota dell'istruzione SELECT che calcola la media dei ritardi e la distanza totale percorsa giornalmente da ogni vettore. I dati inseriti in questa tabella sono archiviati in una posizione nota (il percorso indicato dalla variabile hiveDataFolder) e possono quindi essere usati come origine per Sqoop nel passaggio successivo.
Dalla workstation locale creare un file denominato
workflow.xml. Usare il codice seguente come contenuto per il file. Questi passaggi precedenti sono espressi come azioni separate nel file del flusso di lavoro Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Le due query Hive sono accessibili dal percorso in Archiviazione di Azure e i valori delle variabili rimanenti vengono forniti dal job.properties file. Questo file configura il flusso di lavoro da eseguire per la data 3 gennaio 2017.
Distribuire ed eseguire il flusso di lavoro Oozie
Usare SCP dalla sessione bash per distribuire il flusso di lavoro Oozie (workflow.xml), le query Hive (hive-load-flights-partition.hql e hive-create-daily-summary-table.hql) e la configurazione del processo (job.properties). In Oozie solo il file job.properties può essere presente nella risorsa di archiviazione locale del nodo head. Tutti gli altri file devono essere archiviati in HDFS (Hadoop Distributed File System), in questo caso Archiviazione di Azure. Per le comunicazioni con il database SQL, l'azione Sqoop usata dal flusso di lavoro dipende da un driver JDBC, che deve essere copiato dal nodo head in HDFS.
Creare la sottocartella
load_flights_by_dayall'interno del percorso dell'utente nella risorsa di archiviazione locale del nodo head. Dalla sessione ssh aperta eseguire il comando seguente:mkdir load_flights_by_dayCopiare tutti i file presenti nella directory corrente, ovvero i file
workflow.xmlejob.properties, nella sottocartellaload_flights_by_day. Dalla workstation locale eseguire il comando seguente:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayCopiare i file del flusso di lavoro in HDFS. Dalla sessione ssh aperta eseguire i comandi seguenti:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayCopiare
mssql-jdbc-7.0.0.jre8.jardal nodo head locale alla cartella del flusso di lavoro in HDFS. Rivedere il comando in base alle esigenze se il cluster contiene un file JAR diverso. Rivedereworkflow.xmlin base alle esigenze per riflettere un file JAR diverso. Dalla sessione ssh aperta eseguire il comando seguente:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayEseguire il flusso di lavoro. Dalla sessione ssh aperta eseguire il comando seguente:
oozie job -config job.properties -runOsservare lo stato usando Oozie Web Console. Da Ambari selezionare Oozie, Quick Links (Collegamenti rapidi) e quindi Oozie Web Console. Nella scheda Workflow Jobs (Processi di flusso di lavoro) selezionare All Jobs (Tutti i processi).
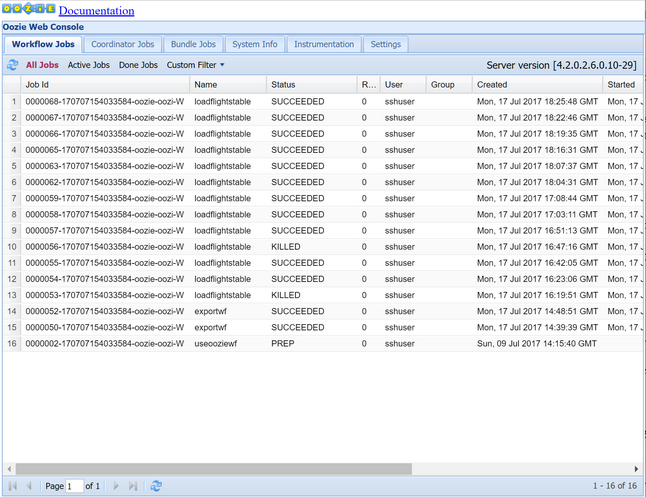
Quando lo stato è SUCCEEDED, eseguire una query sulla tabella database SQL per visualizzare le righe inserite. Tramite il portale di Azure, passare al riquadro relativo al database SQL, selezionare Strumenti e aprire Editor di query.
SELECT * FROM dailyflights
Ora che il flusso di lavoro viene eseguito per il singolo giorno di test, è possibile eseguirne il wrapping con un coordinatore che pianifica l'esecuzione giornaliera del flusso.
Eseguire il flusso di lavoro con un coordinatore
Per pianificare il flusso di lavoro in modo che venga eseguito ogni giorno (o tutti i giorni in un intervallo di date), è possibile usare un coordinatore, che è definito da un file XML, ad esempio coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Come illustrato nell'esempio, la maggior parte dei dati presenti nel file del coordinatore riguarda semplicemente il passaggio di informazioni di configurazione all'istanza del flusso di lavoro. È tuttavia opportuno mettere in evidenza alcuni elementi importanti.
Punto 1: gli attributi
starteendnell'elementocoordinator-appstesso controllano l'intervallo di tempo in cui viene eseguito il coordinatore.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Quest'ultimo è responsabile della pianificazione delle azioni nel periodo compreso tra le date
starteend, in base all'intervallo specificato dall'attributofrequency. Ogni azione pianificata esegue a sua volta il flusso di lavoro in base alla configurazione. Nella definizione del coordinatore precedente, il coordinatore è configurato per eseguire azioni dal 1° gennaio 2017 al 5 gennaio 2017. La frequenza viene impostata su un giorno dall'espressione di frequenza del linguaggio delle espressioni${coord:days(1)}Oozie . Il coordinatore pianifica pertanto l'esecuzione di un'azione, e quindi del flusso di lavoro, una volta al giorno. Per gli intervalli di date già trascorse, come in questo esempio, l'azione verrà pianificata per l'esecuzione immediata. Il momento a partire dal quale è pianificata l'esecuzione di un'azione è definito data/ora nominale. Ad esempio, per elaborare i dati per il 1° gennaio 2017, il coordinatore pianifica l'azione con un orario nominale 2017-01-01T00:00:00 GMT.Punto 2: entro l'intervallo di date del flusso di lavoro, l'elemento
datasetdefinisce il percorso in cui cercare i dati per un particolare intervallo di date in HDFS e specifica il modo in cui Oozie determina se i dati sono ancora disponibili per l'elaborazione.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Il percorso dei dati in HDFS viene generato dinamicamente in base all'espressione specificata nell'elemento
uri-template. In questo coordinatore il valore relativo alla frequenza giornaliera viene usato anche con il set di dati. Mentre le date di inizio e fine definite nell'elemento coordinatore controllano i tempi di pianificazione delle azioni, e quindi definiscono le relative date/ore nominali, gli elementiinitial-instanceefrequencynel set di dati controllano il calcolo della data usata per la generazione diuri-template. In questo caso, impostare l'istanza iniziale su un giorno prima dell'inizio del coordinatore per assicurarsi che venga prelevato il primo giorno (1 gennaio 2017) di dati. Il calcolo della data del set di dati esegue il roll forward dal valore diinitial-instance(31/12/2016) avanzando in incrementi di frequenza del set di dati (un giorno) fino a quando non trova la data più recente che non supera l'ora nominale impostata dal coordinatore (2017-01-01T00:00:00 GMT per la prima azione).L'elemento
done-flagvuoto indica che, all'ora pianificata per la verifica della presenza di dati di input, Oozie determina la disponibilità dei dati in base alla presenza di una directory o di un file. In questo caso, è la presenza di un file CSV. Se è presente un file in questo formato, Oozie presuppone che i dati siano pronti e avvia un'istanza del flusso di lavoro per elaborare il file. Se non è presente alcun file CSV, Oozie presuppone che i dati non siano ancora pronti e che l'esecuzione del flusso di lavoro entri in uno stato di attesa.Punto 3: l'elemento
data-indefinisce lo specifico timestamp da usare come data/ora nominale quando si sostituiscono i valori inuri-templateper il set di dati associato.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>In questo caso, impostare l'istanza sull'espressione
${coord:current(0)}, che configura l'uso della data/ora nominale dell'azione, come originariamente pianificato dal coordinatore. In altre parole, quando il coordinatore pianifica l'azione da eseguire alla data nominale 01/01/2017, quest'ultima viene usata per sostituire le variabili YEAR (2017) e MONTH (01) nel modello URI. Non appena il modello URI viene calcolato per questa istanza, Oozie controlla se la directory o il file previsto è disponibile e pianifica di conseguenza l'esecuzione successiva del flusso di lavoro.
I tre punti precedenti consentono di configurare una situazione in cui il coordinatore pianifica l'elaborazione dei dati di origine in base a una frequenza giornaliera.
Punto 1: il coordinatore inizia con la data nominale 01/01/2017.
Punto 2: Oozie cerca i dati disponibili in
sourceDataFolder/2017-01-FlightData.csv.Punto 3: quando Oozie trova il file, pianifica un'istanza del flusso di lavoro che elabora i dati per il 1° gennaio 2017. Oozie continua quindi l'elaborazione per il giorno successivo, 02/01/2017. Questa valutazione si ripete fino al giorno 05/01/2017 escluso.
Come per i flussi di lavoro, la configurazione di un coordinatore è definita in un file job.properties, che include un superset delle impostazioni usate dal flusso di lavoro.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Le uniche nuove proprietà introdotte in questo file job.properties sono le seguenti:
| Proprietà | Origine del valore |
|---|---|
| oozie.coord.application.path | Percorso del file coordinator.xml contenente il coordinatore Oozie da eseguire. |
| hiveDailyTableNamePrefix | Prefisso usato per la generazione dinamica del nome della tabella di staging. |
| hiveDataFolderPrefix | Prefisso del percorso in cui verranno archiviate tutte le tabelle di staging. |
Distribuire ed eseguire il coordinatore Oozie
Per eseguire la pipeline con un coordinatore, si segue una procedura simile a quella usata per il flusso di lavoro, ad eccezione del fatto che si usa una cartella di un livello superiore a quella che contiene il flusso di lavoro. Questa convenzione d'uso delle cartelle consente di separare i coordinatori dai flussi di lavoro sul disco ed è pertanto possibile associare un singolo coordinatore a diversi flussi di lavoro figlio.
Usare SCP dal computer locale per copiare i file del coordinatore nella risorsa di archiviazione locale del nodo head del cluster.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Stabilire una sessione SSH con il nodo head.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCopiare i file del coordinatore in HDFS.
hdfs dfs -put ./* /oozie/Eseguire il coordinatore.
oozie job -config job.properties -runVerificare lo stato tramite Oozie Web Console. Questa volta, selezionare la scheda Coordinator Jobs (Processi di coordinatore) e quindi Tutti i processi.
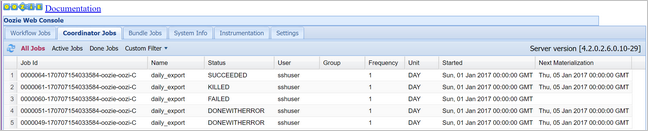
Selezionare un'istanza di coordinatore per visualizzare l'elenco delle azioni pianificate. In questo caso, dovrebbero essere visualizzate quattro azioni con tempi nominale compresi nell'intervallo compreso tra il 1° gennaio 2017 e il 4 gennaio 2017.
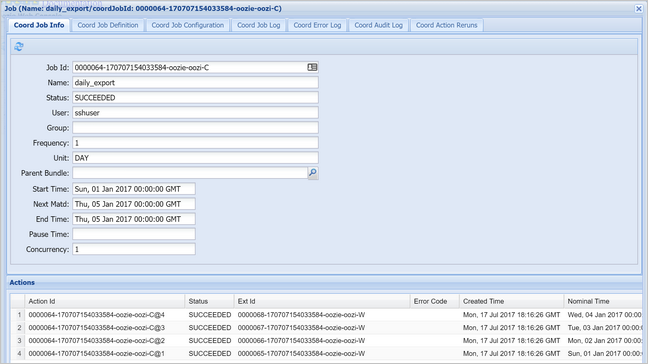
Ogni azione nell'elenco corrisponde a un'istanza del flusso di lavoro che elabora i dati relativi a un singolo giorno, dove l'inizio del giorno è indicato dalla data/ora nominale.