Installare e usare Hue nei cluster Hadoop di HDInsight
Informazioni su come installare Hue nei cluster HDInsight e usare il tunneling per instradare le richieste a Hue.
Nota
Hue non è supportato in HDInsight 4.0 e versioni successive.
Informazioni su Hue
Hue è un insieme di applicazioni Web che consente di interagire con un cluster Apache Hadoop. È possibile usare Hue per esplorare lo spazio di archiviazione associato a un cluster Hadoop (WASB nel caso di cluster HDInsight), eseguire processi Hive e script Pig e così via. I componenti seguenti sono disponibili con l'installazione di Hue in un cluster Hadoop di HDInsight.
- Editor Hive Beeswax
- Apache Pig
- Metastore Manager
- Apache Oozie
- FileBrowser (che interagisce con il contenitore predefinito di WASB)
- Job Browser
Avviso
I componenti forniti con il cluster HDInsight sono supportati in modo completo e il Supporto Microsoft contribuirà a isolare e risolvere i problemi correlati a questi componenti.
I componenti personalizzati ricevono supporto commercialmente ragionevole per semplificare la risoluzione dei problemi. È possibile che si ottenga la risoluzione dei problemi o che venga richiesto di usare i canali disponibili per le tecnologie open source, in cui è possibile ottenere supporto approfondito per la tecnologia specifica. Ad esempio, sono disponibili molti siti della community che possono essere usati, ad esempio: pagina delle domande di Microsoft Q&A per HDInsight, https://stackoverflow.com. Anche per i progetti Apache sono disponibili siti specifici in https://apache.org, ad esempio Hadoop.
Installare Hue mediante azioni script
Usare le informazioni nella tabella seguente per l'azione di script. Per istruzioni specifiche su come utilizzare le azioni di script, vedere Personalizzare cluster HDInsight con azioni di script.
Nota
Per installare Hue nei cluster HDInsight, la dimensione consigliata del nodo head è minimo A4 (8 core, 14 GB di memoria).
| Proprietà | valore |
|---|---|
| Tipo di script: | - Personalizzato |
| Nome | Installare Hue |
| URI script Bash | https://hdiconfigactions.blob.core.windows.net/linuxhueconfigactionv02/install-hue-uber-v02.sh |
| Tipi di nodo: | Head |
Eseguire una query Hive
Nel portale di Hue selezionare Query Editors (Editor di query) e quindi selezionare Hive per aprire l'editor Hive.
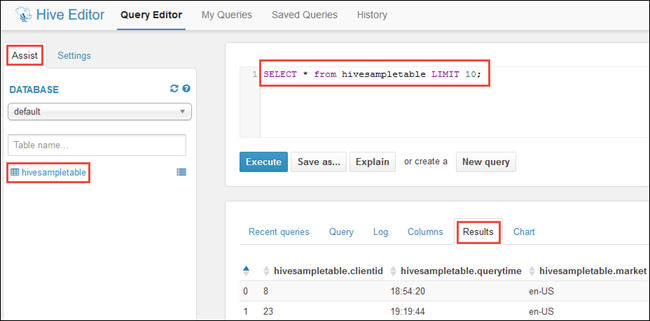
Nella scheda Assist (Assistenza) in Database dovrebbe essere visibile hivesampletable. Si tratta di una tabella di esempio inclusa in tutti i cluster Hadoop in HDInsight. Immettere una query di esempio nel riquadro destro e visualizzare l'output nella scheda Risultati nel riquadro sottostante, come illustrato nella schermata.
È anche possibile usare la scheda Grafico per vedere una rappresentazione visiva dei risultati.
Esplorare l'archiviazione cluster
Nel portale di Hue selezionare Browser file nell'angolo superiore destro della barra dei menu.
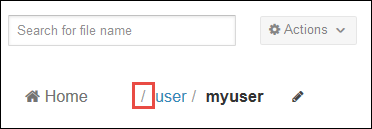
Per impostazione predefinita, il browser file viene aperto in corrispondenza della directory /user/myuser . Selezionare la barra subito prima della directory user nel percorso per passare alla radice del contenitore di archiviazione di Azure associato al cluster.
Fare clic son il pulsante destro del mouse su un file o una cartella per visualizzare le operazioni disponibili. Usare il pulsante Carica nell'angolo destro per caricare i file nella directory corrente. Usare il pulsante Nuovo per creare nuovi file o directory.
Nota
Il browser file Hue può mostrare solo il contenuto del contenitore predefinito associato al cluster HDInsight. Eventuali account di archiviazione o contenitori aggiuntivi associati al cluster non saranno accessibili tramite il browser file. I contenitori aggiuntivi associati al cluster saranno comunque sempre accessibili per i processi Hive. Ad esempio, se si immette il comando dfs -ls wasbs://newcontainer@mystore.blob.core.windows.net nell'editor Hive, è possibile vedere il contenuto anche dei contenitori aggiuntivi. In questo comando newcontainer non è il contenitore predefinito associato a un cluster.
Considerazioni importanti
Lo script usato per installare Hue ne consente l'installazione solo nel nodo head del cluster.
Durante l'installazione vengono riavviati più servizi Hadoop (HDFS, YARN, MR2, Oozie) per l'aggiornamento della configurazione. Al termine dell'installazione di Hue tramite lo script, è possibile che l'avvio di altri servizi Hadoop richieda qualche istante. Ciò potrebbe influire inizialmente sulle prestazioni di Hue. Una volta avviati tutti i servizi, Hue sarà completamente funzionale.
Hue non riconosce i processi di Apache Tez, che attualmente corrisponde all'importazione predefinita per Hive. Se si vuole usare MapReduce come motore di esecuzione di Hive, aggiornare lo script per l'uso dei comandi seguenti:
set hive.execution.engine=mr;Con i cluster Linux è possibile avere uno scenario in cui i servizi vengono eseguiti sul nodo head primario mentre Resource Manager potrebbe essere in esecuzione su quello secondario. Questo scenario potrebbe causare errori (illustrati di seguito) quando si usa Hue per visualizzare i dettagli dei processi IN ESECUZIONE nel cluster. I dettagli del processo possono tuttavia essere visualizzati dopo il completamento del processo.
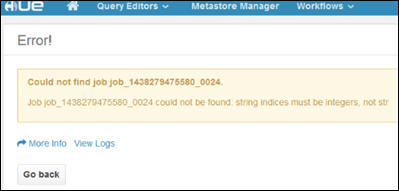
Questo è causato da un problema noto. Come soluzione alternativa, modificare Ambari in modo che anche l'istanza di Resource Manager attiva venga eseguita sul nodo head primario.
Hue riconosce WebHDFS mentre i cluster HDInsight usano Archiviazione di Azure Storage tramite
wasbs://. Lo script personalizzato usato con l'azione script installa WebWasb, un servizio compatibile con WebHDFS-per comunicare con WASB. Quindi, anche se in alcuni punti nel portale di Hue è indicato HDFS (come quando si sposta il mouse su File Browser), dovrà essere interpretato come WASB.