Come creare pipeline di dati semplici, efficienti e a bassa latenza
Le aziende basate sui dati di oggi producono continuamente dati, che richiedono pipeline di dati di progettazione che inseriscono e trasformano continuamente questi dati. Queste pipeline devono essere in grado di elaborare e distribuire i dati esattamente una volta, produrre risultati con latenze inferiori a 200 millisecondi e provare sempre a ridurre al minimo i costi.
Questo articolo descrive gli approcci per l'elaborazione batch e incrementale dei flussi per le pipeline di dati ingegneristici, perché l'elaborazione incrementale dei flussi è l'opzione migliore e i passaggi successivi per iniziare a usare le offerte di elaborazione incrementale dei flussi di Databricks, Streaming su Azure Databricks e Che cos'è DLT?. Queste funzionalità consentono di scrivere ed eseguire rapidamente pipeline che garantiscono semantica di recapito, latenza, costi e altro ancora.
Le insidie dei lavori batch ripetuti
Quando si configura la pipeline di dati, è possibile scrivere prima processi batch ripetuti per inserire i dati. Ad esempio, ogni ora è possibile eseguire un processo Spark che legge dall'origine e scrive i dati in un sink come Delta Lake. La sfida con questo approccio consiste nell'elaborazione incrementale dell'origine, perché il processo Spark eseguito ogni ora deve iniziare da dove è terminato l'ultimo. È possibile registrare il timestamp più recente dei dati elaborati e quindi selezionare tutte le righe con timestamp più recenti rispetto a tale timestamp, ma ci sono problemi:
Per eseguire una pipeline di dati continua, è possibile provare a pianificare un processo batch orario che legge in modo incrementale dall'origine, esegue trasformazioni e scrive il risultato in un sink, ad esempio Delta Lake. Questo approccio può avere problemi:
- Un processo Spark che esegue query su tutti i nuovi dati successivi a un timestamp perderà i dati in arrivo tardivo.
- Un processo Spark che non riesce può causare un'interruzione delle garanzie di tipo exactly-once, se non gestite con attenzione.
- Un processo Spark che elenca il contenuto dei percorsi di archiviazione cloud per trovare nuovi file diventerà costoso.
È comunque necessario trasformare ripetutamente questi dati. È possibile scrivere processi batch ripetuti che aggregano i dati o applicano altre operazioni, che complicano ulteriormente e riducono l'efficienza della pipeline.
Un esempio di batch
Per comprendere appieno le insidie dell'inserimento e della trasformazione batch per la pipeline, prendere in considerazione gli esempi seguenti.
Dati mancanti
Dato un topic Kafka con i dati di utilizzo che determinano quanto addebitare ai tuoi clienti, e la pipeline che elabora in batch, la sequenza di eventi può essere simile alla seguente:
- Il primo batch ha due record alle 8:00 e alle 8:30.
- Si aggiorna il timestamp più recente alle 8:30.
- Si ottiene un altro record alle 8:15.
- La tua seconda query riguarda tutto ciò che avviene dopo le 8:30, quindi ti perdi il record delle 8:15.
Inoltre, non si vuole far pagare troppo o troppo poco gli utenti, quindi è necessario assicurarsi di inserire ogni record esattamente una volta.
Elaborazione ridondante
Si supponga quindi che i dati contengano righe di acquisti utente e si voglia aggregare le vendite all'ora in modo da conoscere i tempi più diffusi nel negozio. Se gli acquisti per la stessa ora arrivano in batch diversi, si avranno più batch che producono output per la stessa ora:
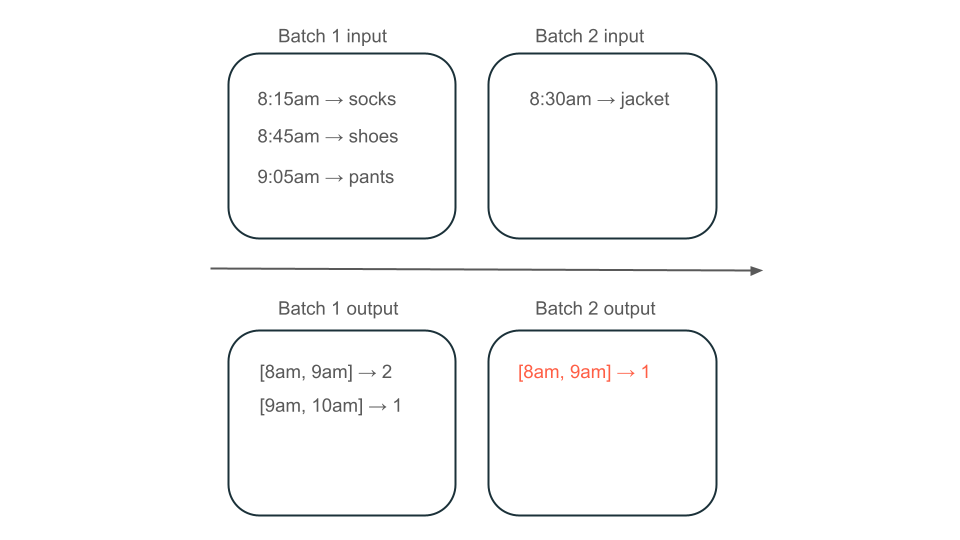
La finestra dalle 8:00 alle 9:00 ha due elementi (l'output del batch 1), un elemento (l'output del batch 2) o tre (l'output di nessuno dei batch)? I dati necessari per produrre un determinato intervallo di tempo vengono visualizzati in più batch di trasformazione. Per risolvere questo problema, è possibile partizionare i dati di giorno e rielaborare l'intera partizione quando è necessario calcolare un risultato. È quindi possibile sovrascrivere i risultati nel sink:
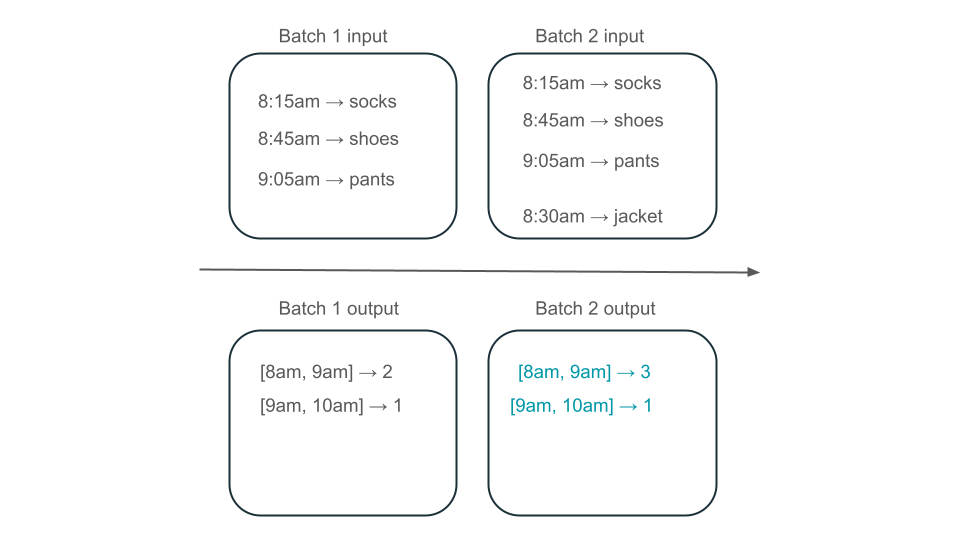
Tuttavia, ciò comporta il costo e la latenza, perché il secondo batch deve eseguire il lavoro non necessario per elaborare i dati che potrebbero essere già stati elaborati.
Nessuna insidie con l'elaborazione incrementale del flusso
L'elaborazione incrementale del flusso rende facile evitare le trappole dei processi batch ripetuti per inserire e trasformare i dati. Databricks Structured Streaming e DLT gestiscono le complessità di implementazione dello streaming per consentirti di concentrarti solo sulla tua logica di business. È sufficiente specificare l'origine a cui connettersi, le trasformazioni da eseguire ai dati e la posizione in cui scrivere il risultato.
Inserimento incrementale
L'inserimento incrementale in Databricks è basato su Apache Spark Structured Streaming, che può utilizzare in modo incrementale un'origine di dati e scriverla in un sink. Il motore Structured Streaming può utilizzare i dati una sola volta e il motore può gestire i dati non ordinati. Il motore può essere eseguito nei notebook o usando tabelle di streaming in DLT.
Il motore Structured Streaming in Databricks fornisce origini di streaming proprietarie, ad esempio AutoLoader, che può elaborare in modo incrementale i file cloud in modo conveniente. Databricks fornisce anche connettori per altri bus di messaggi più diffusi, ad esempio Apache Kafka, Amazon, Apache Pulsare Google Pub/Sub.
Trasformazione incrementale
La trasformazione incrementale in Databricks con Structured Streaming consente di specificare le trasformazioni nei DataFrame con la stessa API di una query batch, ma tiene traccia dei dati tra i batch di dati e dei valori aggregati nel tempo, così che tu non debba farlo. Non è mai necessario rielaborare i dati, quindi è più veloce e conveniente rispetto ai processi batch ripetuti. Structured Streaming produce un flusso di dati che può essere aggiunto al sink, ad esempio Delta Lake, Kafka o qualsiasi altro connettore supportato.
Viste Materializzate in DLT sono alimentate dal motore Enzyme. Enzyme elabora ancora in modo incrementale l'origine, ma invece di produrre un flusso, crea una vista materializzata , che è una tabella pre-calcolata che memorizza i risultati di una query fornita. L'enzima è in grado di determinare in modo efficiente il modo in cui i nuovi dati influiscono sui risultati della query e mantiene la tabella pre-calcolata up-to-date.
Le viste materializzate creano una visualizzazione sull'aggregazione che viene sempre aggiornata in modo efficiente, in modo che, ad esempio, nello scenario descritto in precedenza, si sappia che la finestra dalle 8:00 alle 9:00 ha tre elementi.
Structured Streaming o DLT?
La differenza significativa tra Structured Streaming e DLT è il modo in cui si operano le query di streaming. In Structured Streaming si specificano manualmente molte configurazioni ed è necessario unire manualmente le query. È necessario avviare in modo esplicito le query, attendere che terminino, annullarle in caso di errore e altre azioni. In DLT si forniscono in modo dichiarativo le pipeline da eseguire e DLT continua a mantenerle in esecuzione.
DLT include anche funzionalità come viste materializzate, che precomputano in modo efficiente e incrementale le trasformazioni dei dati.
Per altre informazioni su queste funzionalità, vedere Streaming in Azure Databricks e Che cos'è DLT?.
Passaggi successivi
- Crea la tua prima pipeline con DLT. Consulta Esercitazione: Esegui una prima pipeline DLT.
- Esegui le tue prime query di "Structured Streaming" in Databricks. Consulta per eseguire il primo carico di lavoro Structured Streaming.
- Usare una visualizzazione materializzata. Vedere Usare viste materializzate in Databricks SQL.