Memorizzazione di query nella cache
La memorizzazione nella cache è una tecnica essenziale per migliorare le prestazioni dei sistemi del data warehouse evitando la necessità di ricompilare o recuperare più volte gli stessi dati. In Databricks SQL la memorizzazione nella cache può velocizzare notevolmente l'esecuzione delle query e ridurre al minimo l'utilizzo del warehouse, con conseguente riduzione dei costi e un utilizzo delle risorse più efficiente. Ogni livello di memorizzazione nella cache migliora le prestazioni delle query, riduce al minimo l'utilizzo del cluster e ottimizza l'utilizzo delle risorse per un'esperienza di data warehouse senza problemi.
La memorizzazione nella cache offre numerosi vantaggi nei data warehouse, tra cui:
- Velocità: archiviando i risultati delle query o i dati a cui si accede di frequente in memoria o in altri supporti di archiviazione veloci, la memorizzazione nella cache può ridurre notevolmente i tempi di esecuzione delle query. Questa risorsa di archiviazione è particolarmente utile per le query ripetitive, perché il sistema può recuperare rapidamente i risultati memorizzati nella cache anziché ricompilarli.
- Riduzione dell'utilizzo del cluster: la memorizzazione nella cache riduce al minimo la necessità di risorse di calcolo aggiuntive riutilizzando i risultati calcolati in precedenza. In questo modo si riduce il tempo di attività complessivo del warehouse e la domanda di cluster di calcolo aggiuntivi, con conseguente risparmio sui costi e migliore allocazione delle risorse.
Tipi di cache di query in Databricks SQL
Databricks SQL esegue diversi tipi di memorizzazione nella cache delle query.
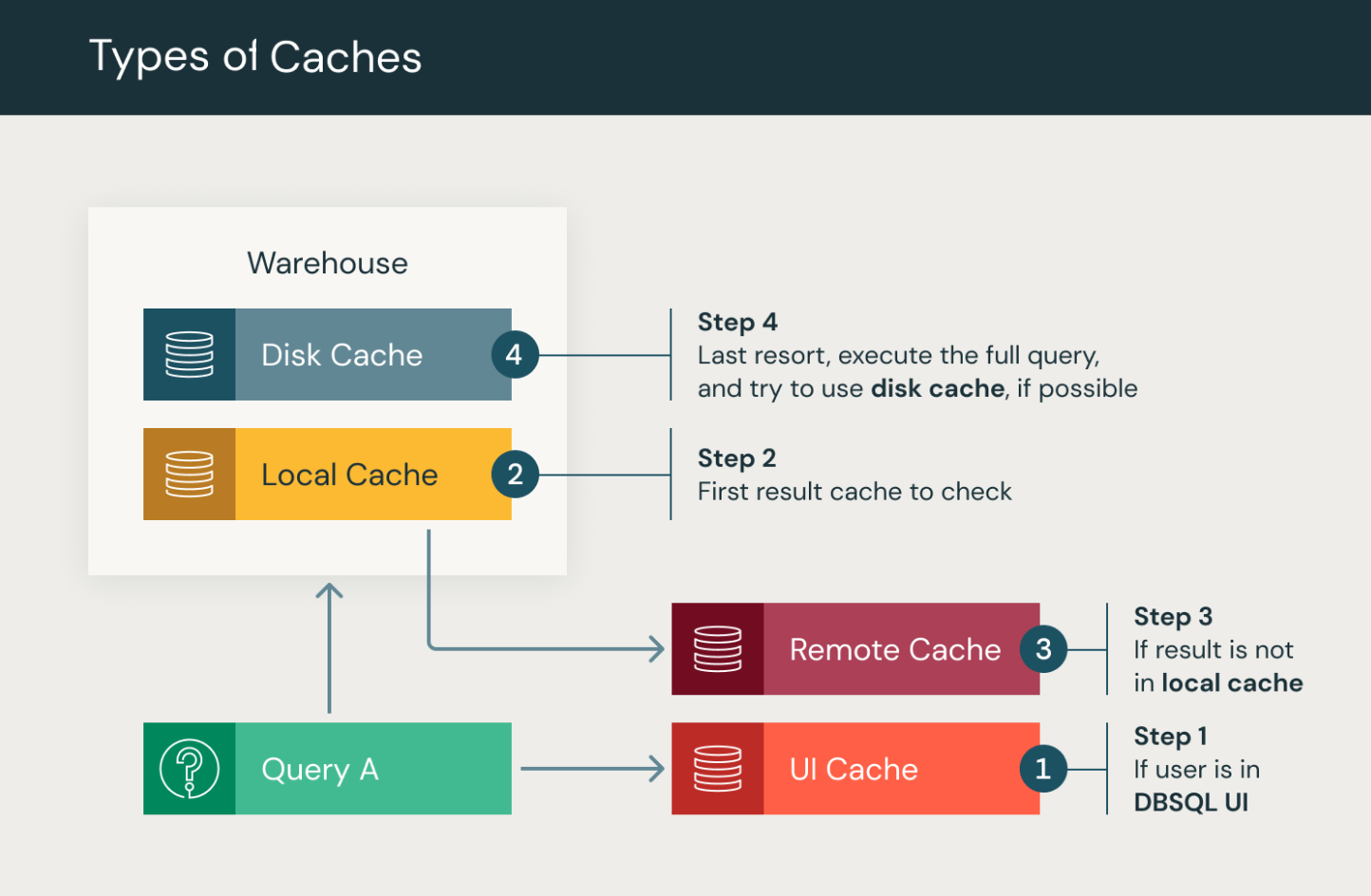
Cache dell'interfaccia utente sql di Databricks: per utente la memorizzazione nella cache di tutte le query e del dashboard viene restituita nell'interfaccia utente sql di Databricks. Quando gli utenti aprono per la prima volta un dashboard o una query SQL, la cache dell'interfaccia utente sql di Databricks visualizza il risultato della query più recente, inclusi i risultati delle esecuzioni pianificate.
La cache dell'interfaccia utente sql di Databricks ha al massimo un ciclo di vita di 7 giorni. La cache si trova all'interno del file system di Azure Databricks nell'account. È possibile eliminare i risultati delle query eseguendo nuovamente la query che non si vuole più archiviare. Una volta eseguito di nuovo, i risultati della query precedenti vengono rimossi dalla cache. Inoltre, la cache viene invalidata una volta che il tables sottostante è stato aggiornato.
Cache dei risultati: memorizzazione nella cache per cluster dei risultati delle query per tutte le query tramite sql warehouse. La memorizzazione nella cache dei risultati dei risultati include sia cache dei risultati locali che remote, che interagiscono per migliorare le prestazioni delle query archiviando i risultati delle query in supporti di memoria o di archiviazione remota.
- Cache locale: la cache locale è una cache in memoria che archivia i risultati delle query per la durata del cluster o fino a quando la cache non è piena, a qualsiasi prima richiesta. Questa cache è utile per velocizzare le query ripetitive, eliminando la necessità di ricompilare gli stessi risultati. Tuttavia, dopo l'arresto o il riavvio del cluster, la cache viene pulita e tutti i risultati della query vengono rimossi.
- Cache dei risultati remota: la cache dei risultati remota è un sistema di cache serverless che mantiene i risultati delle query salvandoli come dati di sistema dell'area di lavoro. Di conseguenza, questa cache non viene invalidata dall'arresto o dal riavvio di un'istanza di SQL Warehouse. La cache dei risultati remota risolve un problema comune nella memorizzazione nella cache dei risultati della query in memoria, che rimane disponibile solo finché le risorse di calcolo sono in esecuzione. La cache remota è una cache condivisa persistente in tutti i warehouse in un'area di lavoro di Databricks.
Per accedere alla cache dei risultati remota è necessario un warehouse in esecuzione. Quando si elabora una query, un cluster cerca innanzitutto nella cache locale e quindi cerca nella cache dei risultati remota, se necessario. Solo se il risultato della query non viene memorizzato nella cache è la query eseguita. Sia la cache locale che quella remota hanno un ciclo di vita di 24 ore, che inizia dalla voce della cache. La cache dei risultati remoti viene mantenuta durante l'arresto o il riavvio di un'istanza di SQL Warehouse. Entrambi i cache vengono invalidati quando le tables sottostanti vengono aggiornate.
La cache dei risultati remota è disponibile per le query che usano client ODBC/JDBC e API istruzione SQL.
Per disabilitare la memorizzazione nella cache dei risultati della query, è possibile eseguire
SET use_cached_result = falsenell'editor SQL.Importante
È consigliabile usare questa opzione solo per il test o il benchmarking.
Cache del disco: memorizzazione nella cache SSD locale per i dati letti dall'archiviazione dei dati per le query tramite SQL Warehouse. La cache dei dischi è progettata per migliorare le prestazioni delle query archiviando i dati su disco, consentendo letture di dati accelerate. I dati vengono memorizzati automaticamente nella cache quando i file vengono recuperati, utilizzando un formato intermedio veloce. Archiviando copie dei file nella risorsa di archiviazione locale collegata ai nodi di calcolo, la cache del disco garantisce che i dati si trovino più vicini ai ruoli di lavoro, con conseguente miglioramento delle prestazioni delle query. Consulta le prestazioni di Optimize con la memorizzazione nella cache su Azure Databricks.
Oltre alla funzione primaria, la cache del disco rileva automaticamente le modifiche ai file di dati sottostanti. Quando rileva le modifiche, la cache viene invalidata. La cache del disco shares ha le stesse caratteristiche del ciclo di vita della cache dei risultati locale. Ciò significa che quando il cluster viene arrestato o riavviato, la cache viene pulita e deve essere ripopolata.
La memorizzazione nella cache dei risultati della query e la cache del disco influiscono sulle query nell'interfaccia utente sql di Databricks e bi e in altri client esterni.