Luglio 2020
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a luglio 2020.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Terminale Web (anteprima pubblica)
29 luglio-4 agosto 2020: versione 3.25
Il terminale Web offre un modo comodo e altamente interattivo per gli utenti con autorizzazione CAN ATTACH TO su un cluster per eseguire comandi di shell, compresi editor come Vim o Emacs. Esempi di utilizzo del terminale web sono il monitoraggio dell'utilizzo delle risorse e l'installazione di pacchetti Linux.
Per informazioni dettagliate, consultare Eseguire i comandi della shell nel terminale Web di Azure Databricks.
Nuovo framework globale di script init più sicuro (anteprima pubblica)
29 luglio - 4 agosto 2020: versione 3.25
Il nuovo framework per gli script di avvio globale apporta miglioramenti significativi rispetto agli script di avvio globale di legacy:
- Gli script di avvio sono più sicuri e richiedono autorizzazioni di amministratore per creare, visualizzare ed eliminare.
- Vengono registrati errori di avvio correlati allo script.
- È possibile impostare l'ordine di esecuzione di più script init.
- Gli script di avvio possono fare riferimento alle variabili di ambiente correlate al cluster.
- Gli script di avvio possono essere creati e gestiti usando la pagina delle impostazioni di amministrazione o la nuova API REST Script Init globali.
Databricks consiglia di eseguire la migrazione di script init globali di legacy esistenti al nuovo framework per sfruttare questi miglioramenti.
Per informazioni dettagliate, vedere Script init globali.
Elenchi di accesso IP ora in disponibilità generale
29 luglio - 4 agosto 2020: versione 3.25
L'API Elenco di Accesso IP è ora generalmente disponibile.
La versione ga include una modifica, ovvero la ridenominazione dei valori list_type:
-
WHITELISTaALLOW -
BLACKLISTaBLOCK
Usare l'API elenco di accesso IP per configurare le aree di lavoro di Azure Databricks in modo che gli utenti si connettano al servizio solo tramite reti aziendali esistenti con un perimetro sicuro. Gli amministratori di Azure Databricks possono usare l'API Elenco di accesso IP per definire un set di indirizzi IP approvati, inclusi gli elenchi di indirizzi consentiti e bloccati. Tutti gli accessi in entrata all'applicazione web e alle API REST richiedono che l'utente si connetta da un indirizzo IP autorizzato, garantendo che gli spazi di lavoro non siano accessibili da una rete pubblica come un bar o un aeroporto, a meno che gli utenti non utilizzino una VPN.
Questa funzionalità richiede il Piano Premium.
Per ulteriori informazioni, consultare Configurazione degli elenchi di accesso IP per le aree di lavoro.
Nuova finestra di dialogo di caricamento file
29 luglio - 4 agosto 2020: versione 3.25
Adesso è possibile caricare file di dati tabulari di piccole dimensioni (ad esempio i volumi condivisi cluster) e accedervi da un notebook selezionando Aggiungi dati dal menuFile del notebook. Il codice generato illustra come caricare i dati in Pandas o dataframe. Gli amministratori possono disattivare questa funzione nella scheda Avanzate della console amministrativa.
Per altre informazioni, consultare Esplorare i file in DBFS.
Miglioramenti apportati a filtro e ordinamento dell’API SCIM
29 luglio - 4 agosto 2020: versione 3.25
L'API SCIM adesso include questi miglioramenti per il filtro e l'ordinamento:
- Gli utenti amministratori possono filtrare gli utenti in base all'attributo
active. - Tutti gli utenti possono ordinare i risultati usando i parametri di query
sortByesortOrder. L'opzione predefinita è l'ordinamento per ID.
Aggiunte aree di Azure per enti pubblici
25 luglio 2020
Azure Databricks di recente è diventato disponibile nelle aree US Gov Arizona e US Gov Virginia per le entità governative degli Stati Uniti e i relativi partner.
Databricks Runtime 7.1 in disponibilità generale
21 luglio 2020
Databricks Runtime 7.1 offre molte funzionalità e miglioramenti aggiuntivi rispetto a Databricks Runtime 7.0, tra cui:
- Connettore Google BigQuery
- Comandi
%pipper gestire le librerie Python installate in una sessione di notebook - Koalas installato
- Molti miglioramenti di Delta Lake, tra cui:
- Impostazione dei metadati di commit definiti dall'utente
- Recupero della versione dell'ultimo commit scritto dall'oggetto corrente
SparkSession - Conversione di tabelle Parquet create da Structured Streaming tramite il log delle transazioni
_spark_metadata - Miglioramenti delle prestazioni
MERGE INTO
Per informazioni dettagliate, consultare le note sulla versione complete per Databricks Runtime 7.1 (EoS).
Databricks Runtime 7.1 ML in disponibilità generale
21 luglio 2020
Databricks Runtime 7.1 per Machine Learning si basa su Databricks Runtime 7.1 e apporta le nuove funzionalità e le modifiche alla libreria riportate di seguito:
- Comandi magic pip e conda abilitati per impostazione predefinita
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Per informazioni dettagliate, consultare le note sulla versione complete per Databricks Runtime 7.1 per ML (EoS).
Databricks Runtime 7.1 Genomica in disponibilità generale
21 luglio 2020
Databricks Runtime 7.1 per Genomica si basa su Databricks Runtime 7.1 e apporta le nuove funzionalità riportate di seguito:
- Trasformazione LOCO
- Funzione di rimodellamento dell'output GloWGR
- RNASeq produce allineamenti non accoppiati
Databricks Connect 7.1 (anteprima pubblica)
17 luglio 2020
Databricks Connect 7.1 è adesso disponibile in anteprima pubblica.
Aggiornamenti dell'API per la lista di accesso IP
15-21 luglio 2020: versione 3.24
Le seguenti proprietà dell'API dell'elenco di accesso IP sono state modificate:
-
updator_user_idaupdated_by -
creator_user_idacreated_by
I notebook Python supportano ora più output per cella
15-21 luglio 2020: versione 3.24
I notebook Python supportano ora più output per cella. Ciò significa che in una cella è possibile inserire un numero qualsiasi di istruzioni di visualizzazione, displayHTML o stampa. Sfruttare la possibilità di visualizzare i dati grezzi e il grafico nella stessa cella o tutti gli output che hanno avuto successo prima che si verificasse un errore.
Questa funzionalità richiede Databricks Runtime 7.1 o versione successiva e per impostazione predefinita è disabilitata in Databricks Runtime 7.1. Abilitarla impostando spark.databricks.workspace.multipleResults.enabled true.
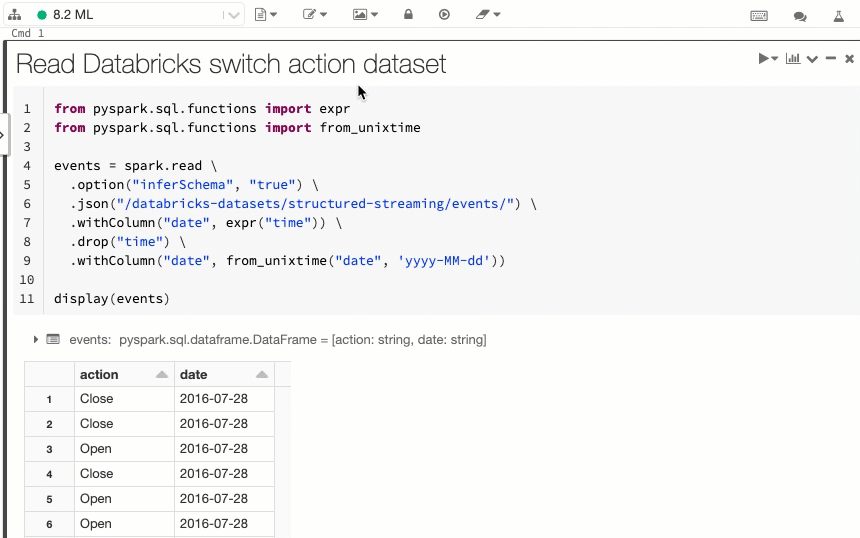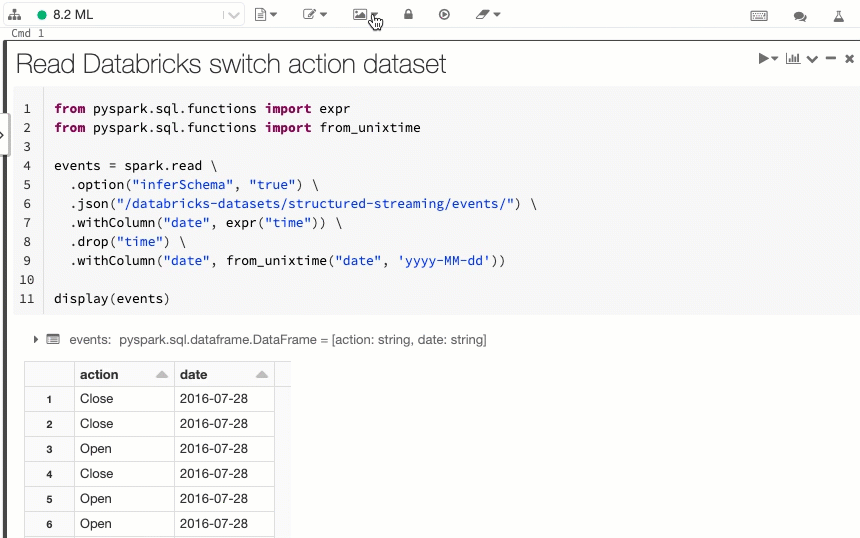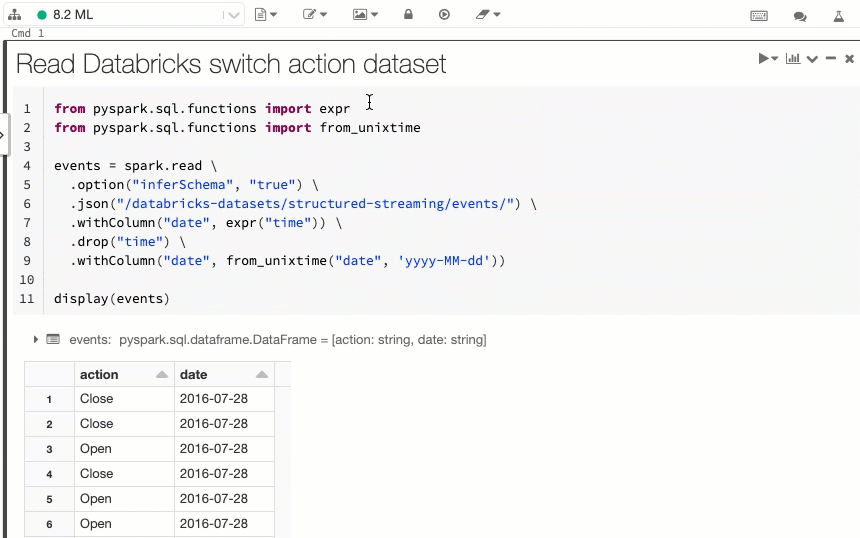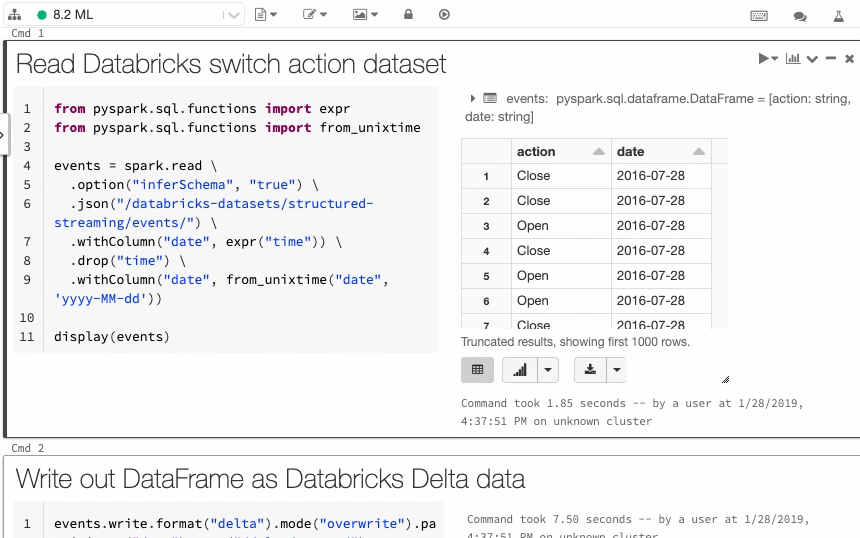
Visualizzare il codice e le celle di risultati dei notebook affiancati
15-21 luglio 2020: versione 3.24
La nuova opzione di visualizzazione side-by-side del notebook consente di visualizzare il codice e i risultati uno accanto all'altro. Questa opzione di visualizzazione unisce l'opzione "Standard" (in precedenza "Codice") e l'opzione "Solo risultati".
Sospendere le pianificazioni di processi
15-21 luglio 2020: versione 3.24
Le pianificazioni dei processi adesso sono dotate di pulsanti di Pausa e Riattiva, che consentono di mettere in pausa e riprendere facilmente i processi. Ora è possibile apportare modifiche a una pianificazione dei processi senza che vengano avviate altre esecuzioni di processi mentre si apportano le modifiche. Le esecuzioni correnti o le esecuzioni attivate da Esegui adesso non sono interessate. Per informazioni dettagliate, consultare Sospendere e riprendere i trigger di processo.
Gli endpoint dell’API dei processi convalidano l’ID esecuzione
15-21 luglio 2020: versione 3.24
Gli endpoint API jobs/runs/cancel e jobs/runs/output adesso convalidano che il parametro run_id sia valido. Per i parametri non validi, questi endpoint API restituiscono ora il codice di stato HTTP 400 anziché il codice 500.
Token ID Microsoft Entra per autorizzare l’API REST di Databricks a livello generale
15-21 luglio 2020: versione 3.24
L'uso dei token ID di Microsoft Entra per l'autenticazione all'API dell'area di lavoro è ora disponibile a livello generale. I token Microsoft Entra ID consentono di automatizzare la creazione e l'impostazione di nuove aree di lavoro. Le entità servizio in Microsoft Entra ID sono oggetti applicativi. È anche possibile usare le entità servizio all'interno delle aree di lavoro di Azure Databricks per automatizzare i flussi di lavoro. Per informazioni dettagliate, vedere Autorizzazione all'accesso alle risorse di Azure Databricks.
Formattare automaticamente SQL nei notebook
15-21 luglio 2020: versione 3.24
È ora possibile formattare le celle del notebook SQL da un tasto di scelta rapida, dal menu di scelta rapida del comando e dal menu Modifica notebook (selezionare Modifica > Formato celle SQL). La formattazione SQL semplifica la lettura e la gestione del codice con un minimo sforzo. Funziona per notebook SQL, nonché per le celle %sql.

Ordine riproducibile di installazione per le librerie Maven e CRAN
1-9 luglio 2020: versione 3.23
Azure Databricks ora elabora le librerie Maven e CRAN nell'ordine in cui sono state installate nel cluster.
Assumere il controllo dei token di accesso personali degli utenti con l’API di gestione dei token (anteprima pubblica)
1-9 luglio 2020: versione 3.23
Ora gli amministratori di Azure Databricks possono usare l'API di gestione dei token per gestire i token di accesso personali degli utenti di Azure Databricks:
- Monitorare e revocare i token di accesso personali degli utenti.
- Controllare la durata dei token futuri nell'area di lavoro.
- Controllare quali utenti possono creare e usare i token.
Vedere Monitorare e revocare i token di accesso personali.
Ripristina le celle tagliate nel notebook
1-9 luglio 2020: versione 3.23
È ora possibile ripristinare le celle del notebook tagliate usando il tasto di scelta rapida (Z) o selezionando Modifica > Annulla celle taglia. Questa funzionalità è analoga a quella per annullare le celle eliminate.
Assegnare l’autorizzazione CAN MANAGE per i processi a utenti non amministratori
1-9 luglio 2020: versione 3.23
È ora possibile assegnare utenti e gruppi non amministratori all'autorizzazione CAN MANAGE per i processi. Questo livello di autorizzazione consente agli utenti di gestire tutte le impostazioni del lavoro, compresa l'assegnazione dei permessi, la modifica del proprietario e la modifica della configurazione del cluster (ad esempio, l'aggiunta di librerie e la modifica delle specifiche del cluster). Consultare Controllare l'accesso ai processi.
Gli utenti non amministratori di Azure Databricks possono usare l’API SCIM per visualizzare e filtrare per nome utente
1-9 luglio 2020: versione 3.23
Gli utenti non amministratori possono ora visualizzare i nomi utente e filtrare gli utenti in base al nome utente usando l'endpoint SCIM /Users.
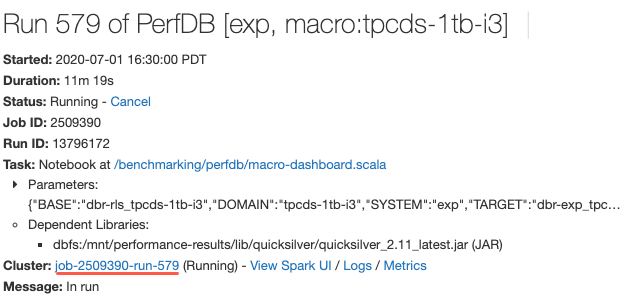
Collegamento per visualizzare la specifica del cluster quando si visualizzano i dettagli dell’esecuzione del processo
1-9 luglio 2020: versione 3.23
Adesso, quando si visualizzano i dettagli dell'esecuzione di un processo, è possibile cliccare un collegamento alla pagina di configurazione del cluster per visualizzare le specifiche del cluster. In precedenza, avresti dovuto copiare l'ID del lavoro dall'URL e andare all'elenco dei cluster per cercarlo.