File binario
Databricks Runtime supporta l'origine dati di file binari, che legge i file binari e converte ogni file in un singolo record contenente il contenuto non elaborato e i metadati del file. L'origine dei dati del file binario produce un DataFrame con le seguenti colonne e, eventualmente, le colonne di partizione:
-
path (StringType): percorso del file. -
modificationTime (TimestampType): ora di modifica del file. In alcune implementazioni di Hadoop FileSystem questo parametro potrebbe non essere disponibile e il valore verrà impostato su un valore predefinito. -
length (LongType): lunghezza del file in byte. -
content (BinaryType): contenuto del file.
Per leggere i file binari, specificare l'origine format dati come binaryFile.
Immagini
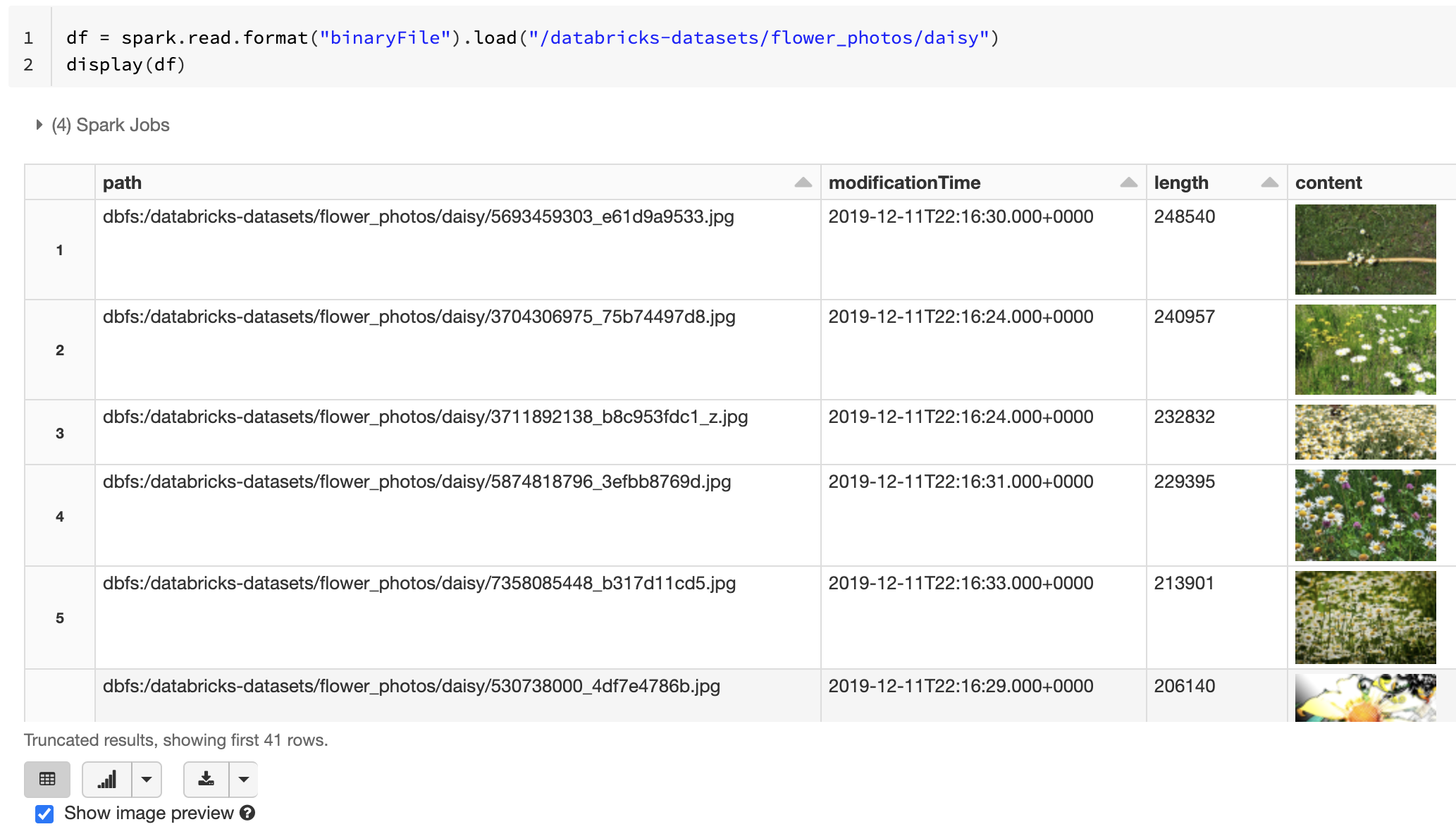
Databricks consiglia di usare l'origine dati del file binario per caricare i dati dell'immagine.
La funzione Databricks display supporta la visualizzazione dei dati immagine caricati usando l'origine dati binaria.
Se tutti i file caricati hanno un nome file con estensione immagine, l'anteprima dell'immagine viene abilitata automaticamente:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
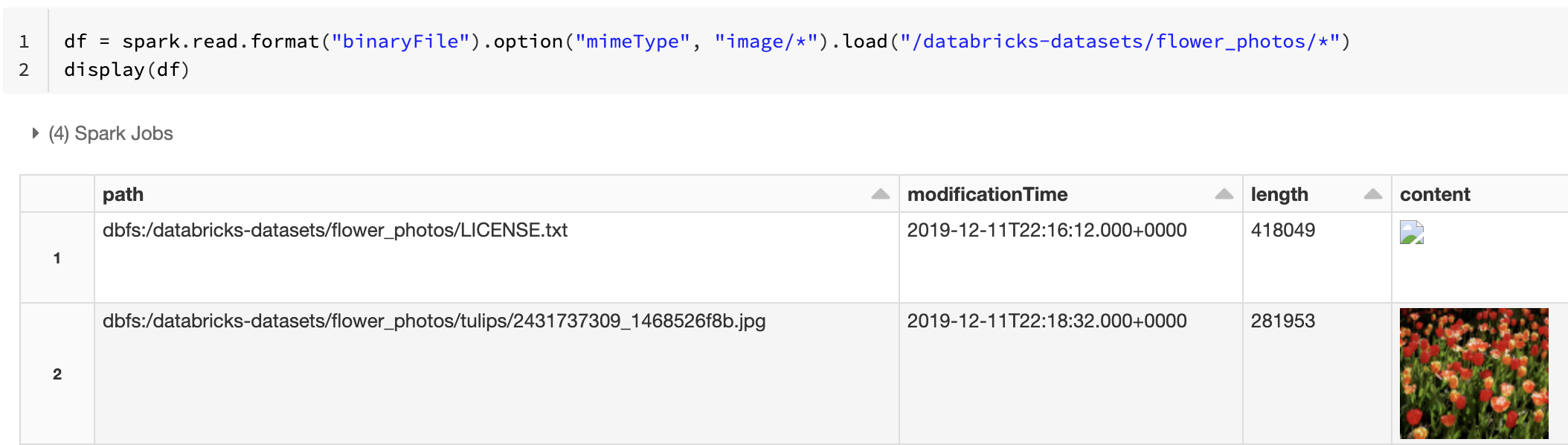
In alternativa, è possibile forzare la funzionalità di anteprima dell'immagine usando l'opzione mimeType con un valore di stringa "image/*" per annotare la colonna binaria. Le immagini vengono decodificate in base alle informazioni sul formato nel contenuto binario. I tipi di immagine supportati sono bmp, gifjpeg, e png. I file non supportati vengono visualizzati come icona di immagine interrotta.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Per il flusso di lavoro consigliato per gestire i dati delle immagini, vedere Soluzione di riferimento per le applicazioni di immagini.
Opzioni
Per caricare i file con percorsi corrispondenti a un modello GLOB specificato mantenendo il comportamento dell'individuazione della partizione, è possibile usare l'opzione pathGlobFilter. Il codice seguente legge tutti i file JPG dalla directory di input con l'individuazione della partizione:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Se vuoi ignorare il rilevamento delle partizioni e cercare in modo ricorsivo i file sotto la directory di input, usa l'opzione recursiveFileLookup. Questa opzione cerca nelle directory annidate anche se i nomi non seguono uno schema di denominazione delle partizioni come date=2019-07-01.
Il codice seguente legge tutti i file JPG in modo ricorsivo dalla directory di input e ignora l'individuazione delle partizioni:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Esistono API simili per Scala, Java e R.
Nota
Per migliorare le prestazioni di lettura quando si caricano nuovamente i dati, Azure Databricks consiglia di salvare i dati caricati da file binari usando tabelle Delta:
df.write.save("<path-to-table>")