Gap tra processi Spark
Di conseguenza, nella sequenza temporale dei processi si noterà un gap simile al seguente:
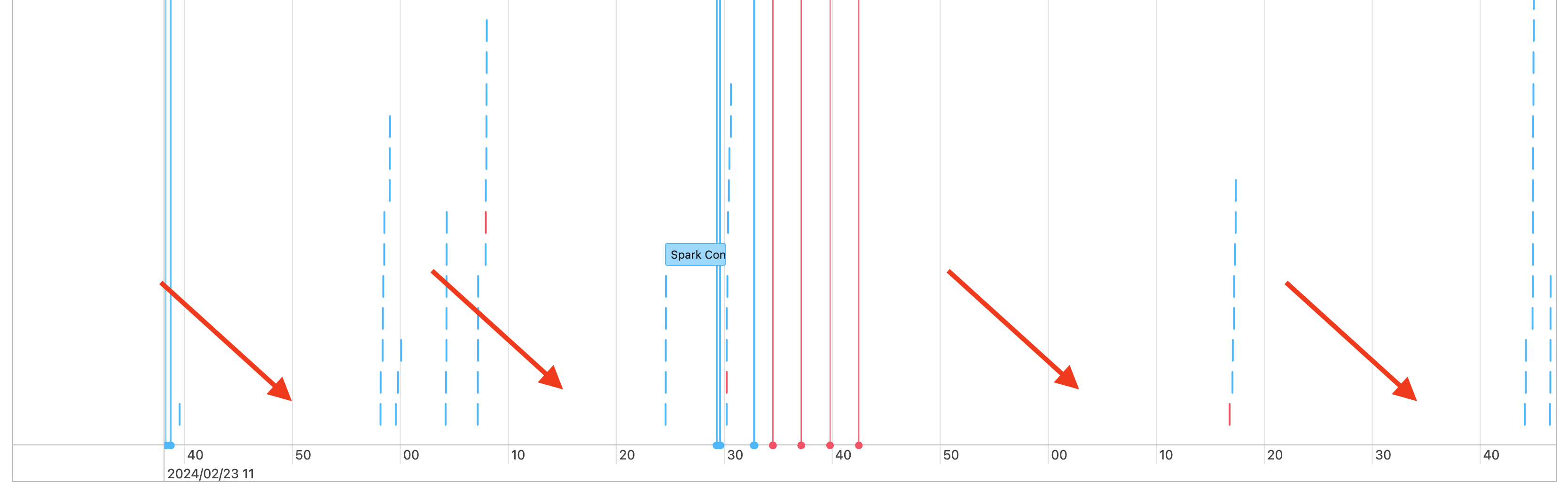
Ci sono alcuni motivi per cui questo potrebbe accadere. Se le lacune costituiscono una percentuale elevata del tempo dedicato al carico di lavoro, è necessario capire cosa sta causando queste lacune e se è previsto o meno. Ci sono alcune cose che potrebbero verificarsi durante le lacune:
- Non c'è lavoro da fare
- Il driver sta compilando un piano di esecuzione complesso
- Esecuzione di codice non Spark
- Il driver è sovraccarico
- Il cluster non funziona correttamente
Nessun lavoro
Nel calcolo multiuso, la spiegazione più probabile dei gap è l'assenza di lavoro da svolgere. Poiché il cluster è in esecuzione e gli utenti inviano query, sono previsti dei gap. Questi gap rappresentano il tempo che intercorre tra l'invio delle query.
Piano di esecuzione complesso
Ad esempio, se si usa withColumn() in un ciclo, viene creato un piano molto costoso da elaborare. Le lacune potrebbero essere il momento in cui il conducente sta spendendo semplicemente la compilazione e l'elaborazione del piano. In questo caso, provare a semplificare il codice. Usare selectExpr() per combinare più chiamate withColumn() in un'unica espressione o convertire il codice in SQL. È comunque possibile incorporare SQL nel codice Python usando Python per modificare la query con funzioni di stringa. Ciò spesso risolve questo tipo di problema.
Esecuzione di codice non Spark
Il codice Spark è scritto in SQL o usando un'API Spark come PySpark. Qualsiasi esecuzione di codice che non è Spark verrà visualizzata nella sequenza temporale come lacune. Ad esempio, è possibile avere un ciclo in Python che chiama funzioni Python native. Questo codice non è in esecuzione in Spark e può essere visualizzato come gap nella sequenza temporale. Se non si è certi che il codice esegua Spark, provare a eseguirlo in modo interattivo in un notebook. Se il codice usa Spark, nella cella verranno visualizzati processi Spark:

È anche possibile espandere l'elenco a discesa Processi Spark sotto la cella per verificare se i processi sono in esecuzione attivamente (nel caso in cui Spark sia ora inattivo). Se non si usa Spark, i processi Spark non verranno visualizzati nella cella o non si noterà che nessuno è attivo. Se non è possibile eseguire il codice in modo interattivo, è possibile provare a eseguire l'accesso al codice e verificare se è possibile trovare una corrispondenza con le sezioni del codice in base al timestamp, ma può risultare difficile.
Se si riscontrano gap nella sequenza temporale causati dall'esecuzione di codice non Spark, ciò significa che i ruoli di lavoro sono tutti inattivi e probabilmente si spreca denaro durante i gap. Forse questo è intenzionale e inevitabile, ma se è possibile scrivere questo codice per usare Spark si userà completamente il cluster. Iniziare con questa esercitazione per informazioni su come usare Spark.
Il driver è sovraccarico
Per determinare se il driver è sovraccarico, è necessario esaminare le metriche del cluster.
Se il cluster si trova in DBR 13.0 o versione successiva, fare clic su Metriche come evidenziato in questo screenshot:
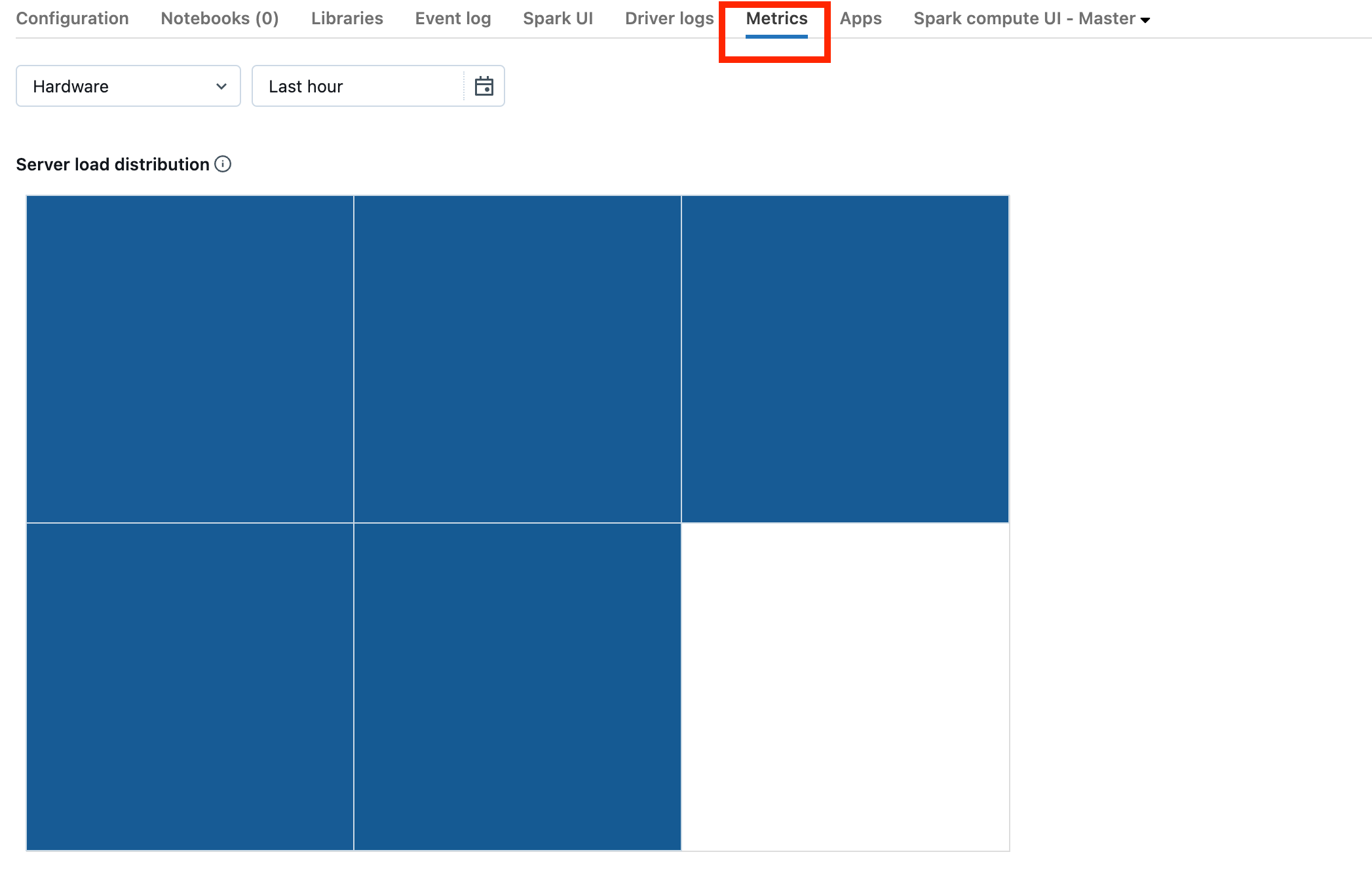
Si noti la visualizzazione Distribuzione del carico del server. Si dovrebbe vedere se il driver è pesantemente caricato. Questa visualizzazione ha un blocco di colore per ogni computer nel cluster. Il rosso significa pesantemente caricato, e blu significa non caricato affatto.
Lo screenshot precedente mostra un cluster inattiva. Se il driver è sottoposto a overload, sarà simile al seguente:
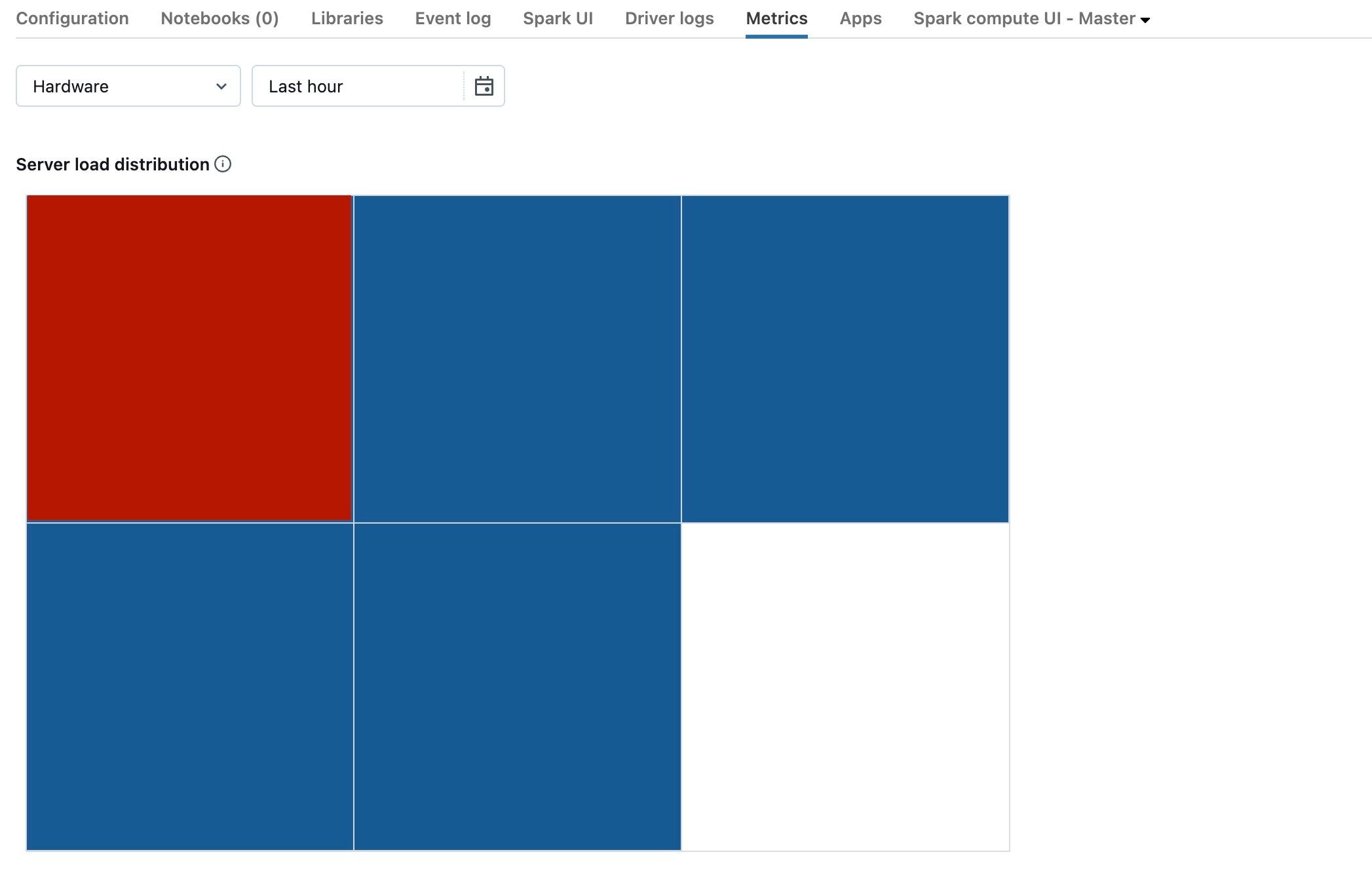
Possiamo vedere che un quadrato è rosso, mentre gli altri sono blu. Rotolare il mouse sul quadrato rosso per assicurarsi che il blocco rosso rappresenti il driver.
Per correggere un driver in overload, vedere Overload del driver Spark.
Il cluster non funziona correttamente
I cluster non funzionanti sono rari, ma in questo caso può essere difficile determinare cosa sia successo. È possibile riavviare il cluster per vedere se il problema si risolve. È anche possibile esaminare i log per verificare se sono presenti elementi sospetti. La scheda Log eventi e le schede Log driver, evidenziate nello screenshot seguente, saranno le posizioni da cercare:
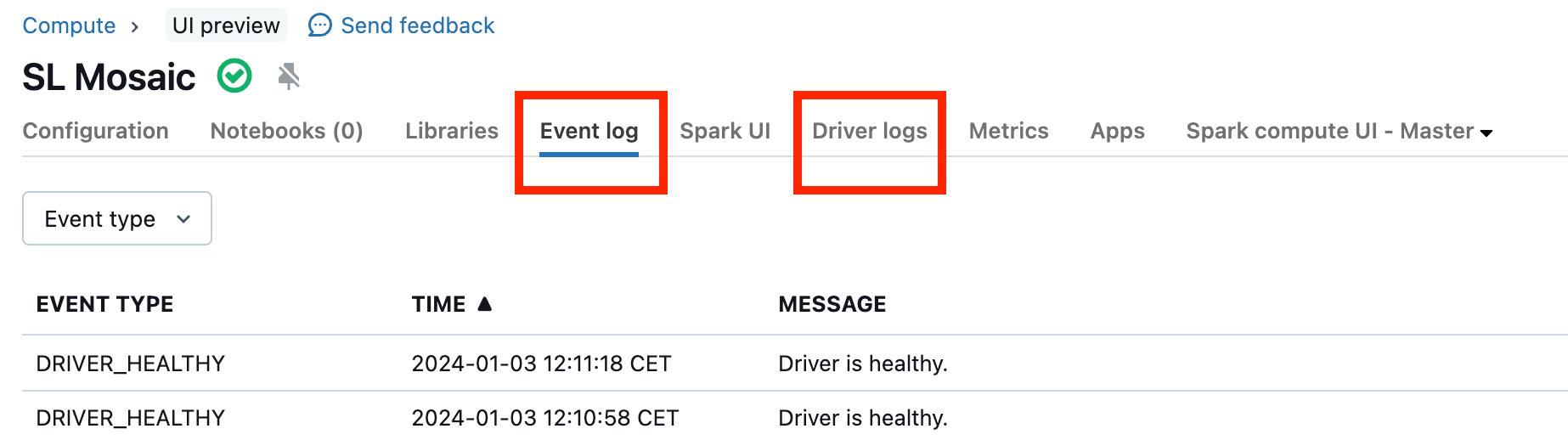
È possibile abilitare la consegna dei registri del cluster per accedere ai registri dei ruoli di lavoro. È anche possibile modificare il livello di registro, ma potrebbe essere necessario contattare il team dell'account Databricks per assistenza.