Fase Spark lenta con piccole operazioni di I/O
Se si dispone di una fase lenta con non molto I/O, questo potrebbe essere causato da:
- Lettura di molti piccoli file
- Scrittura di un sacco di file di piccole dimensioni
- Funzioni lente definite dall'utente
- Join cartesiano
- Join esplodente
Quasi tutti questi problemi possono essere identificati usando il DAG SQL.
Apri il DAG SQL
Per aprire il DAG SQL, scorrere verso l'alto fino alla parte superiore della pagina dell'attività e fare clic su Query SQL Associata:

Dovresti ora vedere il DAG. In caso contrario, scorrere un po' intorno e dovrebbe essere visualizzato:
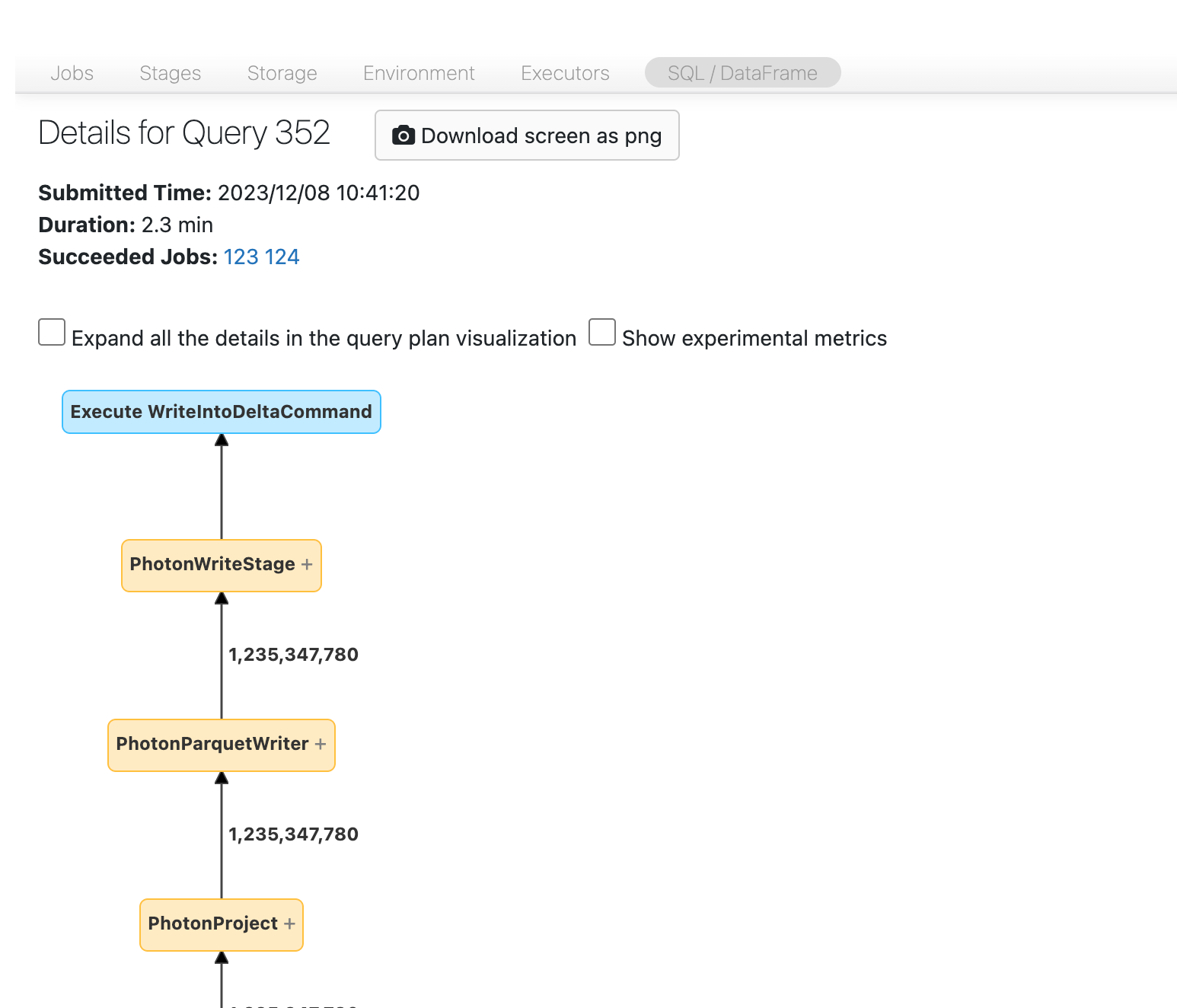
Prima di procedere, familiarizzati con il DAG e individua dove viene speso il tempo. Alcuni nodi nel dag hanno informazioni utili sul tempo e altre no. Ad esempio, questo blocco ha impiegato 2,1 minuti e fornisce anche l'ID della fase.

Questo nodo deve essere aperto per vedere che ci sono voluti 1,4 minuti.
 nodo di scrittura lenta
nodo di scrittura lenta
Questi tempi sono cumulativi, quindi è il tempo totale dedicato a tutte le attività, non all'ora dell'orologio. Ma è ancora molto utile perché sono correlati con l'ora e il costo dell'orologio.
È utile acquisire familiarità con i punti del DAG in cui viene trascorso il tempo.
Lettura di molti file piccoli
Se noti che uno degli operatori di analisi sta impiegando molto tempo, aprilo e verifica il numero di file letti:

Se stai leggendo decine di migliaia di file o più, potresti avere un piccolo problema di file. I file non devono essere inferiori a 8 MB. Il problema di file di piccole dimensioni è spesso causato dal partizionamento su troppe colonne o da una colonna a cardinalità elevata.
Se si è fortunati, potrebbe essere sufficiente eseguire OPTIMIZE. Indipendentemente da tutto, è necessario riconsiderare il layout del file .
Scrittura di un sacco di file di piccole dimensioni
Se si nota che la scrittura richiede molto tempo, aprirla e cercare il numero di file e la quantità di dati scritti:

Se stai scrivendo decine di migliaia di file o più, potresti avere un piccolo problema di file. I file non devono essere inferiori a 8 MB. Il problema di file di piccole dimensioni è spesso causato dal partizionamento su troppe colonne o da una colonna a cardinalità elevata. È necessario riconsiderare il layout del file oppure attivare le scritture ottimizzate .
Funzioni definite dall'utente lente
Se sai di avere funzioni definite dall'utenteo vedi qualcosa di simile nel tuo DAG, potresti soffrire di funzioni lente definite dall'utente.
 del nodo UDF
del nodo UDF
Se pensi di avere questo problema, prova a commentare la UDF per vedere come influisce sulla velocità della pipeline. Se la funzione definita dall'utente è effettivamente la posizione in cui viene impiegato il tempo, la scelta migliore consiste nel riscrivere la funzione definita dall'utente usando funzioni native. Se non è possibile, prendere in considerazione quante attività ci sono nella fase che esegue la funzione definita dall'utente. Se è minore del numero di core nel cluster, repartition() il tuo dataframe prima di usare la funzione definita dall'utente (UDF):
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
Le funzioni definite dall'utente possono anche soffrire di problemi di memoria. Si consideri che ogni attività potrebbe dover caricare tutti i dati nella partizione in memoria. Se questi dati sono troppo grandi, le cose possono diventare molto lente o instabili. La ripartizione può anche risolvere questo problema rendendo ogni attività più piccola.
Join cartesiano
Se viene visualizzato un join cartesiano o un loop annidato nel DAG, è importante sapere che questi join sono molto costosi. Assicurarsi che sia quello che si intende e vedere se c'è un altro modo.
Esplodere un join o esplodere
Se vedi alcune righe che entrano in un nodo e molte di più in uscita, è possibile che si verifichi un'operazione di join o una funzione explode().

Altre informazioni sulle esplosioni nella guida all'ottimizzazione di Databricks .