Visualizzare i risultati dell'addestramento con le esecuzioni di MLflow
Questo articolo descrive come usare le esecuzioni MLflow per visualizzare e analizzare i risultati di un esperimento di training del modello e come gestire e organizzare le esecuzioni. Per ulteriori informazioni sugli esperimenti MLflow, vedere Organizzare le esecuzioni di addestramento utilizzando esperimenti MLflow.
Un'esecuzione MLflow corrisponde a una singola esecuzione del codice del modello. Ogni esecuzione registra informazioni come il notebook che ha avviato l'esecuzione, tutti i modelli creati dall'esecuzione, i parametri del modello e le metriche salvati come coppie chiave-valore, tag per i metadati di esecuzione ed eventuali artefatti o file di output creati dall'esecuzione.
Tutte le esecuzioni di MLflow vengono registrate nell'esperimento attivo. Se non è stato impostato in modo esplicito un esperimento come esperimento attivo, le esecuzioni vengono registrate nell'esperimento del notebook.
Visualizzare i dettagli dell'esecuzione
È possibile accedere a un'esecuzione dalla relativa pagina dei dettagli dell'esperimento o direttamente dal notebook che ha creato l'esecuzione.
Nella pagina dei dettagli dell'esperimento fare clic sul nome dell'esecuzione nella tabella delle esecuzioni.
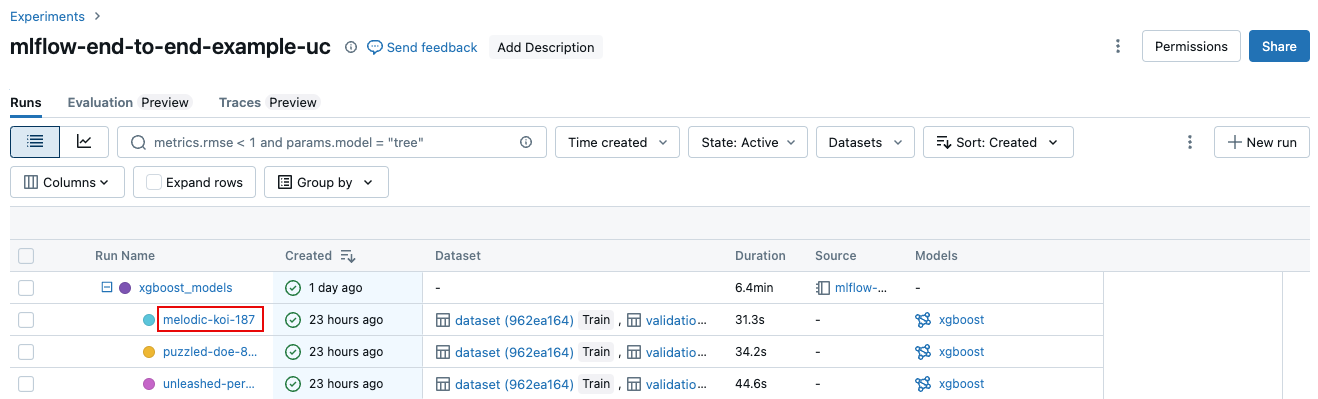
Dal notebook, cliccare sul nome dell'esecuzione nella barra laterale Esecuzioni dell'esperimento.

La schermata di esecuzione mostra l'ID esecuzione, i parametri usati per l'esecuzione, le metriche risultanti dall'esecuzione e i dettagli sull'esecuzione, incluso un collegamento al notebook di origine. Gli artefatti salvati dall'esecuzione sono disponibili nella scheda Artefatti.
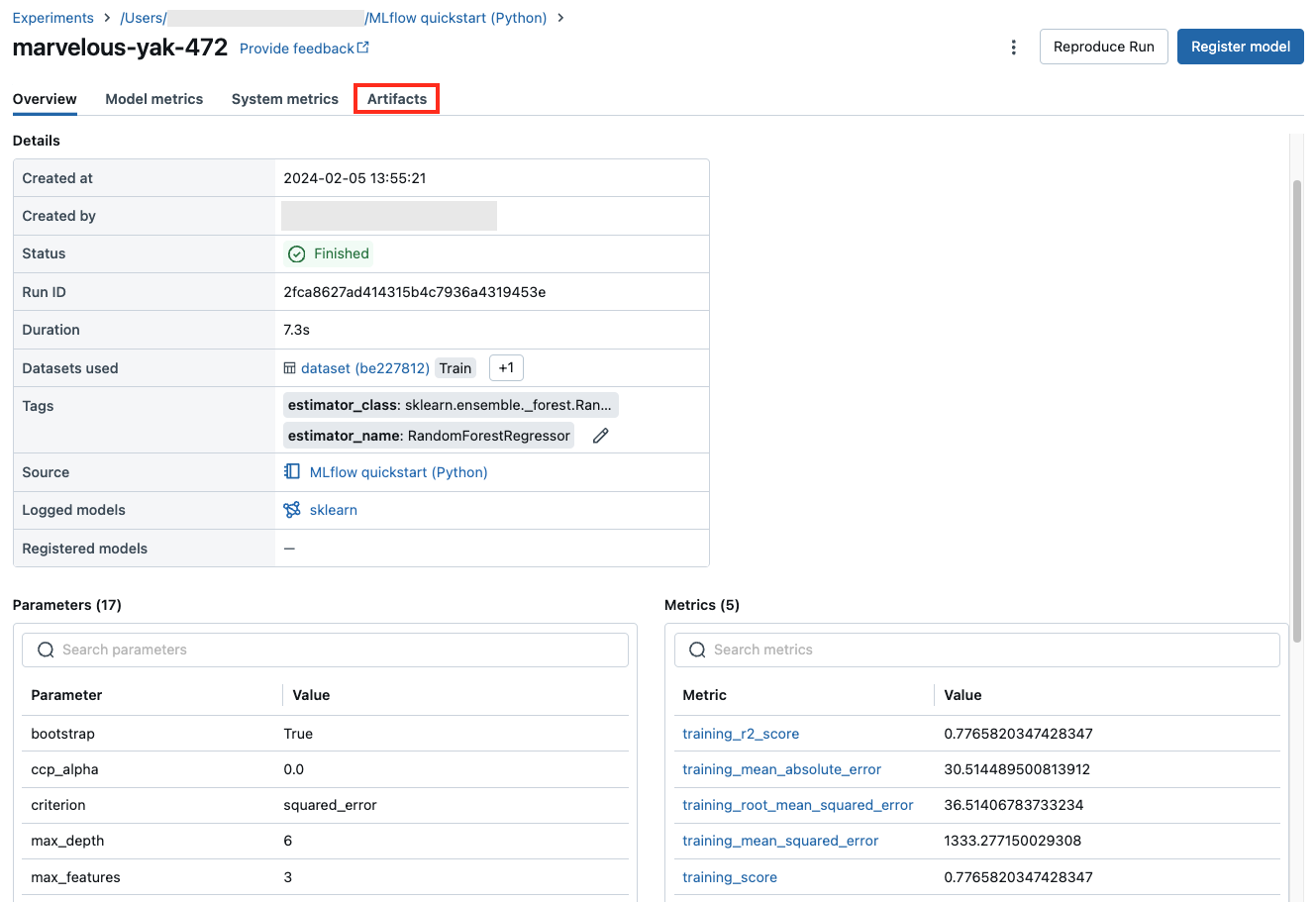
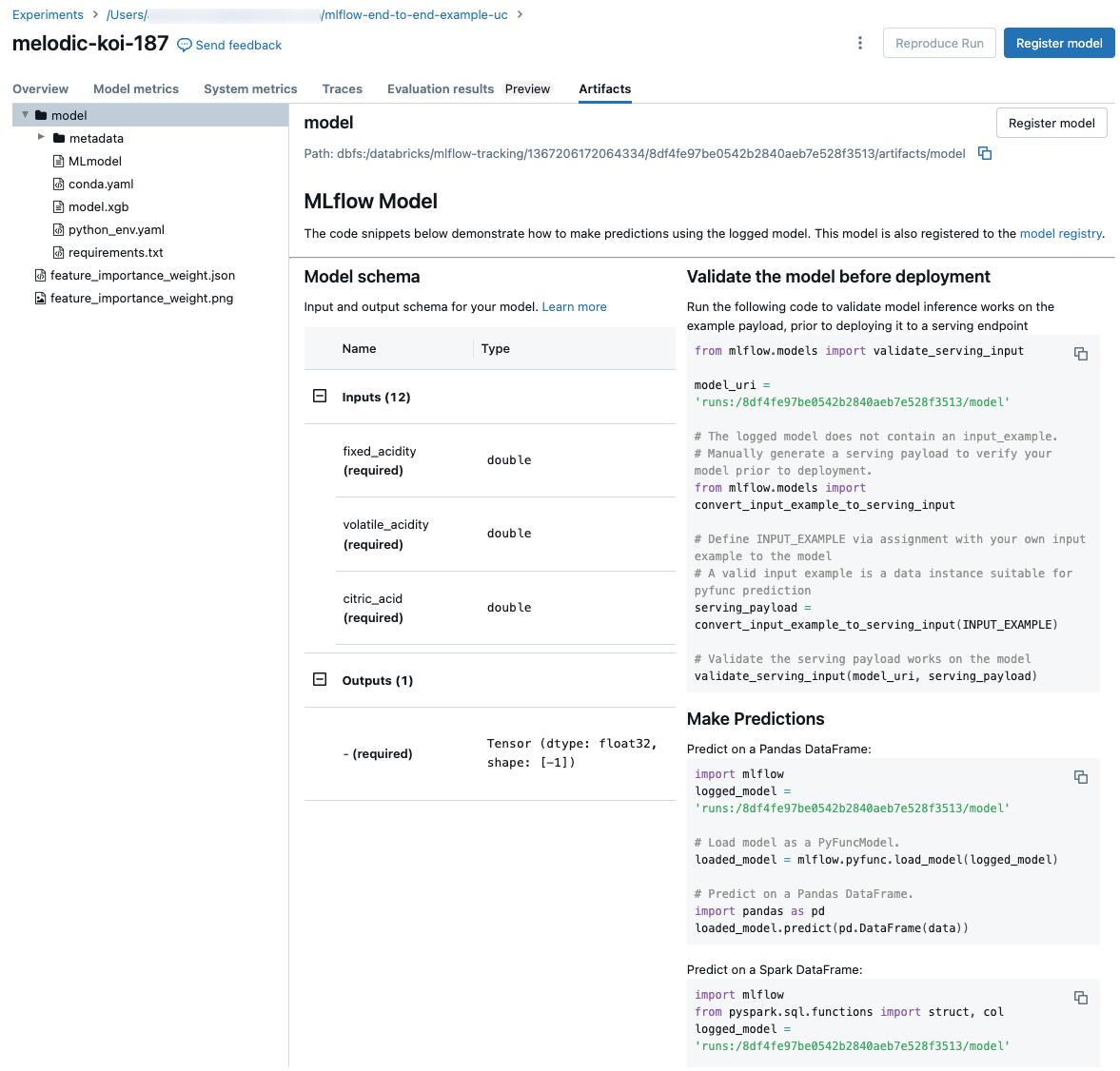
Frammenti di codice per la previsione
Se si registra un modello da un'esecuzione, il modello viene visualizzato nella scheda Artifacts, insieme ai frammenti di codice che illustrano come caricare e usare il modello per eseguire stime sui dataframe Spark e Pandas.
Visualizza il notebook utilizzato per una sessione
Per visualizzare la versione del notebook che ha creato un'esecuzione:
- Nella pagina dei dettagli dell'esperimento, fare clic sul collegamento nella colonna Origine.
- Nella pagina di esecuzione cliccare il collegamento posto accanto a Origine.
- Nel notebook, accedere alla barra laterale Esecuzioni di esperimenti e cliccare l'icona Notebook
 nella casella relativa all'esecuzione dell'esperimento.
nella casella relativa all'esecuzione dell'esperimento.
La versione del notebook associato all'esecuzione viene visualizzata nella finestra principale con una barra di evidenziazione che mostra la data e l'ora dell'esecuzione.
Aggiungere un tag a un'esecuzione
I tag sono coppie chiave-valore che è possibile creare e usare in un secondo momento per cercare le esecuzioni.
Nella tabella Dettagli nella pagina di esecuzione , fare clic su Aggiungi accanto ai Tag .

Verrà visualizzata la finestra di dialogo Aggiungi/Modifica tag. Nel campo Chiave , immettere un nome per la chiave e fare clic su Aggiungi tag.
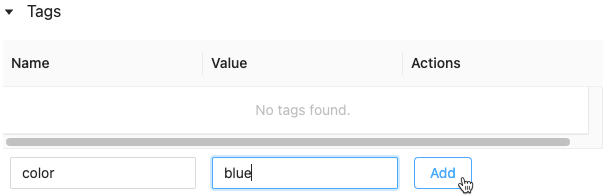
Nel campo valore immettere il valore per il tag.
Fare clic sul segno più per salvare la coppia chiave-valore appena immessa.
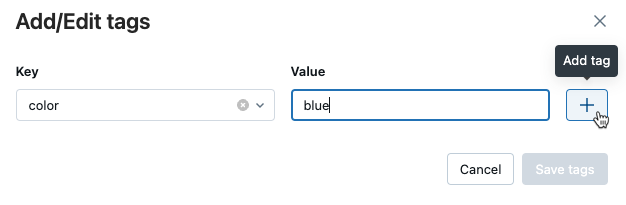
Per aggiungere altri tag, ripetere i passaggi da 2 a 4.
Al termine, fare clic su Salva i tag.
Modificare o eliminare un tag per un'esecuzione
Nella tabella dettagli
della pagina di esecuzione fare clic su Icona a forma di matita. 
Verrà visualizzata la finestra di dialogo Aggiungi/Modifica tag.
Per eliminare un tag, fare clic sulla X sul tag.
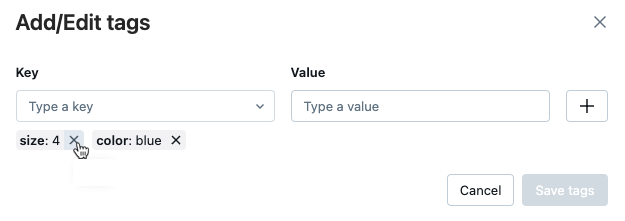
Per modificare un tag, selezionare la chiave dal menu a discesa e modificare il valore nel campo valore
. Fare clic sul segno più per salvare la modifica. 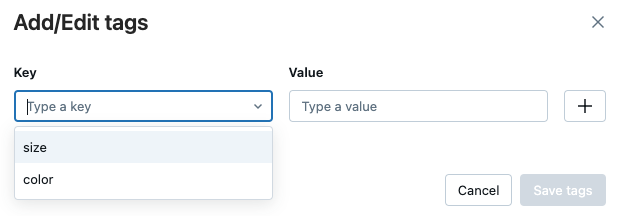
Al termine, fare clic su Salva i tag.
Riprodurre l'ambiente software di un'esecuzione
È possibile riprodurre l'ambiente software esatto per l'esecuzione facendo clic su Riproduci Esecuzione in alto a destra della pagina dell'esecuzione. Viene visualizzata la seguente finestra di dialogo:
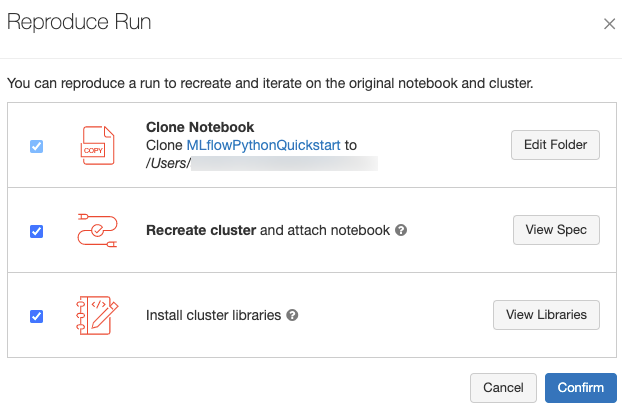
Con le impostazioni predefinite, quando si fa clic su Conferma:
- Il notebook viene clonato nel percorso visualizzato nella finestra di dialogo.
- Se il cluster originale esiste ancora, il notebook clonato viene collegato al cluster originale e il cluster viene avviato.
- Se il cluster originale non esiste più, viene creato e avviato un nuovo cluster con la stessa configurazione, incluse le librerie installate. Il notebook è collegato al nuovo cluster.
È possibile selezionare un percorso diverso per il notebook clonato ed esaminare la configurazione del cluster e le librerie installate:
- Per selezionare una cartella diversa per salvare il notebook clonato, fare clic su Modifica cartella.
- Per visualizzare la specifica del cluster, cliccare Visualizza specifica. Per clonare solo il notebook e non il cluster, deselezionare questa opzione.
- Se il cluster originale non esiste più, è possibile visualizzare le librerie installate nel cluster originale facendo clic su Visualizza librerie. Se il cluster originale esiste ancora, questa sezione è resa inattiva.
Rinominare l'esecuzione
Per rinominare un'esecuzione, fare clic sul menu kebab ![]() nell'angolo superiore destro della pagina di esecuzione (accanto al pulsante Autorizzazioni) e selezionare Rinomina.
nell'angolo superiore destro della pagina di esecuzione (accanto al pulsante Autorizzazioni) e selezionare Rinomina.
Selezionare le colonne da visualizzare
Per gestire le colonne visualizzate nella tabella delle esecuzioni nella pagina dei dettagli dell'esperimento, clicca su Colonne e seleziona dal menu a discesa.
Esecuzioni di filtri
È possibile cercare le esecuzioni nella tabella nella pagina dei dettagli dell'esperimento in base ai valori dei parametri o delle metriche. È anche possibile cercare le esecuzioni in base al tag.
Per cercare esecuzioni che corrispondono a un'espressione contenente i valori di parametro e metrica, immettere una query nel campo di ricerca e premere INVIO. Alcuni esempi di sintassi di query sono:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Per impostazione predefinita, i valori delle metriche vengono filtrati in base all'ultimo valore registrato. L'uso di
MINoMAXconsente di cercare le esecuzioni in base rispettivamente ai valori minimi o massimi delle metriche. Solo le esecuzioni registrate dopo agosto 2024 hanno valori di metrica minimi e massimi.Per cercare le esecuzioni in base al tag, immettere i tag nel formato:
tags.<key>="<value>". I valori stringa devono essere racchiusi tra virgolette, come illustrato.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Sia le chiavi che i valori possono contenere spazi. Se la chiave include spazi, è necessario racchiuderla nei backtick come illustrato.
tags.`my custom tag` = "my value"
È anche possibile filtrare le esecuzioni in base allo stato (Attivo o Eliminato), al momento della creazione dell'esecuzione e ai set di dati usati. A tale scopo, effettuare le selezioni rispettivamente dai menu a tendina Data di creazione, Stato, o Set di dati.
Scarica esecuzioni
È possibile scaricare le esecuzioni dalla pagina dei dettagli dell'esperimento come indicato di seguito:
Fare clic
 per aprire il menu kebab.
per aprire il menu kebab.
Per scaricare un file in formato CSV contenente tutte le esecuzioni visualizzate (fino a un massimo di 100 esecuzioni), selezionare Scarica
<n>esecuzioni. MLflow crea e scarica un file con un'esecuzione per riga contenente i campi seguenti per ogni esecuzione:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Se desideri scaricare più di 100 esecuzioni o farlo in modo automatico, seleziona Scarica tutte le esecuzioni. Viene visualizzata una finestra di dialogo che mostra un frammento di codice che è possibile copiare o aprire in un notebook. Dopo aver eseguito questo codice in una cella del notebook, scegli Scarica tutte le righe dall'output della cella.
Eliminazione di esecuzioni
È possibile eliminare le esecuzioni dalla pagina dei dettagli dell'esperimento seguendo questa procedura:
- Durante l'esperimento, selezionare una o più esecuzioni facendo clic sulla casella di controllo a sinistra delle esecuzioni.
- Fai clic su Elimina.
- Se l'esecuzione è un'esecuzione padre, decidere se eliminare anche le esecuzioni discendenti. Questa opzione è selezionata per impostazione predefinita.
- Cliccare Elimina per confermare. Le esecuzioni eliminate vengono salvate per 30 giorni. Per visualizzare le esecuzioni eliminate, selezionare Eliminato nel campo Stato.
L'eliminazione in blocco viene eseguita in base all'ora di creazione
È possibile usare Python per eliminare in blocco le esecuzioni di un esperimento creato in precedenza a o in corrispondenza di un timestamp UNIX.
Usando Databricks Runtime 14.1 o versione successiva, è possibile richiamare l'API mlflow.delete_runs per eliminare le esecuzioni e restituire il numero di esecuzioni eliminate.
Di seguito sono riportati i parametri mlflow.delete_runs:
-
experiment_id: ID dell'esperimento contenente le esecuzioni da eliminare. -
max_timestamp_millis: timestamp di creazione massimo in millisecondi del periodo UNIX per l'eliminazione delle esecuzioni. Vengono eliminate solo le esecuzioni create prima o in corrispondenza di questo timestamp. -
max_runs: facoltativo. Intero positivo che indica il numero massimo di esecuzioni da eliminare. Il valore massimo consentito per max_runs è 10000. Se non specificato,max_runsviene impostato automaticamente su 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Usando Databricks Runtime 13.3 LTS o versioni precedenti, è possibile eseguire il codice client seguente in un notebook di Azure Databricks.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Consultare la documentazione dell'API Esperimenti di Azure Databricks per i parametri e le specifiche del valore restituito per la cancellazione delle esecuzioni in base al tempo di creazione.
Esecuzioni di ripristino
È possibile ripristinare le esecuzioni eliminate in precedenza dall'interfaccia utente come indicato di seguito:
- Nella pagina esperimento
nel campo Stato selezionare eliminato per visualizzare le esecuzioni eliminate. - Selezionare una o più esecuzioni facendo clic sulla casella di controllo a sinistra dell'esecuzione.
- Fare clic su Ripristina.
- Fare clic su Ripristina per confermare. Le esecuzioni ripristinate vengono ora visualizzate quando si seleziona Attivo nel campo Stato.
Esecuzione del ripristino bulk basata sul tempo di eliminazione
È anche possibile usare Python per ripristinare in blocco le esecuzioni di un esperimento eliminato in corrispondenza o dopo un timestamp UNIX.
Usando Databricks Runtime 14.1 o versione successiva, è possibile chiamare l'API mlflow.restore_runs per ripristinare le esecuzioni e restituire il numero di esecuzioni ripristinate.
Di seguito sono riportati i parametri mlflow.restore_runs:
-
experiment_id: ID dell'esperimento contenente le esecuzioni da ripristinare. -
min_timestamp_millis: timestamp di eliminazione minimo in millisecondi dall'epoca UNIX per il ripristino delle esecuzioni. Vengono eseguite solo le esecuzioni eliminate in corrispondenza o dopo il ripristino di questo timestamp. -
max_runs: facoltativo. Numero intero positivo che indica il numero massimo di esecuzioni da ripristinare. Il valore massimo consentito per max_runs è 10000. Se non specificato, max_runs viene impostato automaticamente su 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Usando Databricks Runtime 13.3 LTS o versioni precedenti, è possibile eseguire il codice client seguente in un notebook di Azure Databricks.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Consulta la documentazione dell'API Esperimenti di Azure Databricks per conoscere i parametri e le specifiche dei valori restituiti per il ripristino delle esecuzioni in base al tempo di eliminazione.
Confrontare le esecuzioni
È possibile confrontare le esecuzioni da un singolo esperimento o da più esperimenti. Nella pagina Confronto esecuzioni vengono visualizzate informazioni sulle esecuzioni selezionate in formato tabulare. È anche possibile creare visualizzazioni di risultati di esecuzione e tabelle di informazioni sull'esecuzione, parametri di esecuzione e metriche. Visualizzare confrontare le esecuzioni di MLflow usando grafici e diagrammi.
Le tabelle dei parametri e delle metriche visualizzano i parametri di esecuzione e le metriche di tutte le esecuzioni scelti. Le colonne di queste tabelle sono identificate dalla tabella Dettagli esecuzione immediatamente sopra. Per semplicità, è possibile nascondere parametri e metriche identici in tutte le esecuzioni selezionate tramite il pulsante  .
.
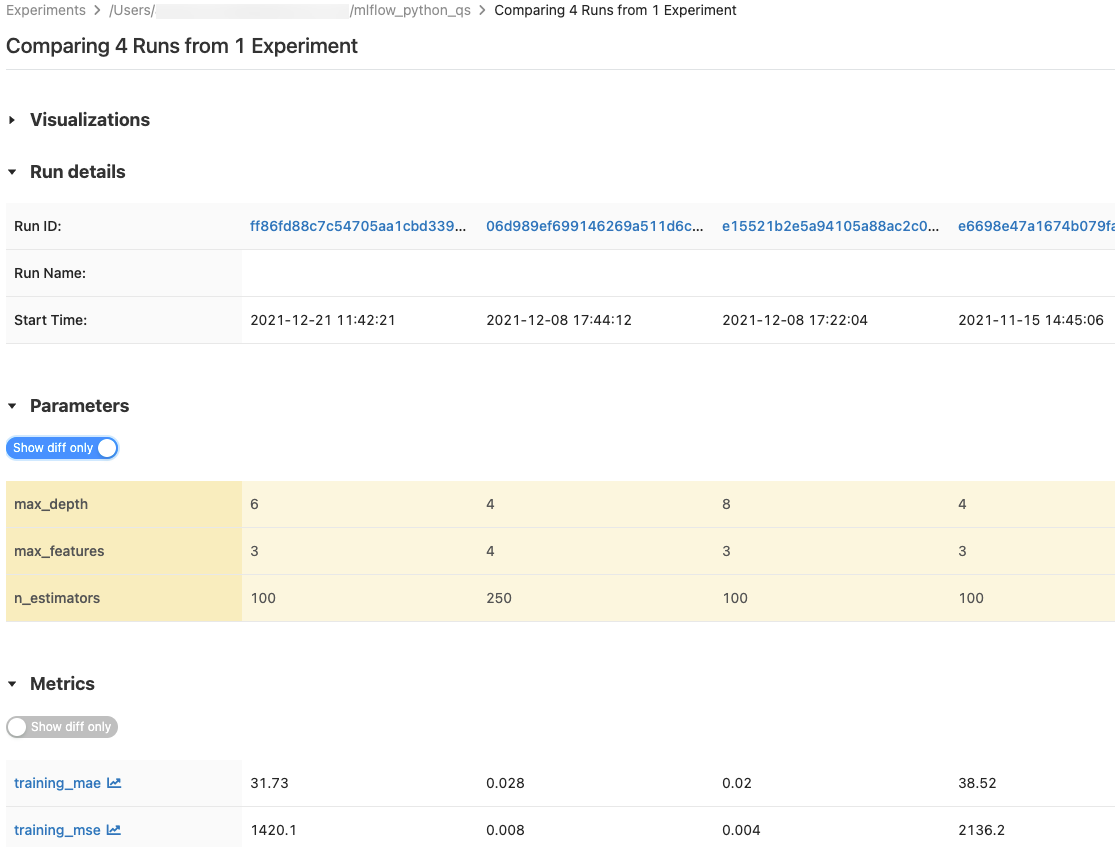
Confrontare le esecuzioni da un singolo esperimento
- Nella pagina dei dettagli dell'esperimento
selezionare due o più esecuzioni facendo clic sulla casella di controllo a sinistra dell'esecuzione oppure selezionando tutte le esecuzioni selezionando la casella nella parte superiore della colonna. - Cliccare Confronta. Viene visualizzata la schermata Confronto
<N>esecuzioni.
Confrontare le esecuzioni ottenute da più esperimenti
- Nella pagina esperimentiselezionare gli esperimenti da confrontare facendo clic nella casella a sinistra del nome dell'esperimento.
- Cliccare Confronta (n) (dove n è il numero di esperimenti selezionati). Viene visualizzata una schermata che mostra tutte le esecuzioni degli esperimenti selezionati.
- Selezionare due o più esecuzioni facendo clic sulla casella di controllo a sinistra dell'esecuzione oppure selezionare tutte le esecuzioni facendo clic sulla casella in alto nella colonna.
- Cliccare Confronta. Viene visualizzata la schermata Confronto
<N>esecuzioni.
Copia delle esecuzioni tra aree di lavoro
Per importare o esportare esecuzioni MLflow nell'area di lavoro di Databricks, è possibile usare il progetto open source basato sulla community MLflow Export-Import.