TensorBoard
TensorBoard è una suite di strumenti di visualizzazione per il debug, l'ottimizzazione e la comprensione di TensorFlow, PyTorch, Hugging Face Transformers e altri programmi di Machine Learning.
Usare TensorBoard
L'avvio di TensorBoard in Azure Databricks non è diverso dall'avvio in un notebook jupyter nel computer locale.
Caricare il
%tensorboardcomando magic e definire la directory di log.%load_ext tensorboard experiment_log_dir = <log-directory>Richiamare il
%tensorboardcomando magic.%tensorboard --logdir $experiment_log_dirIl server TensorBoard avvia e visualizza l'interfaccia utente inline nel notebook. Fornisce anche un collegamento per aprire TensorBoard in una nuova scheda.
Lo screenshot seguente mostra l'interfaccia utente di TensorBoard avviata in una directory di log popolata.
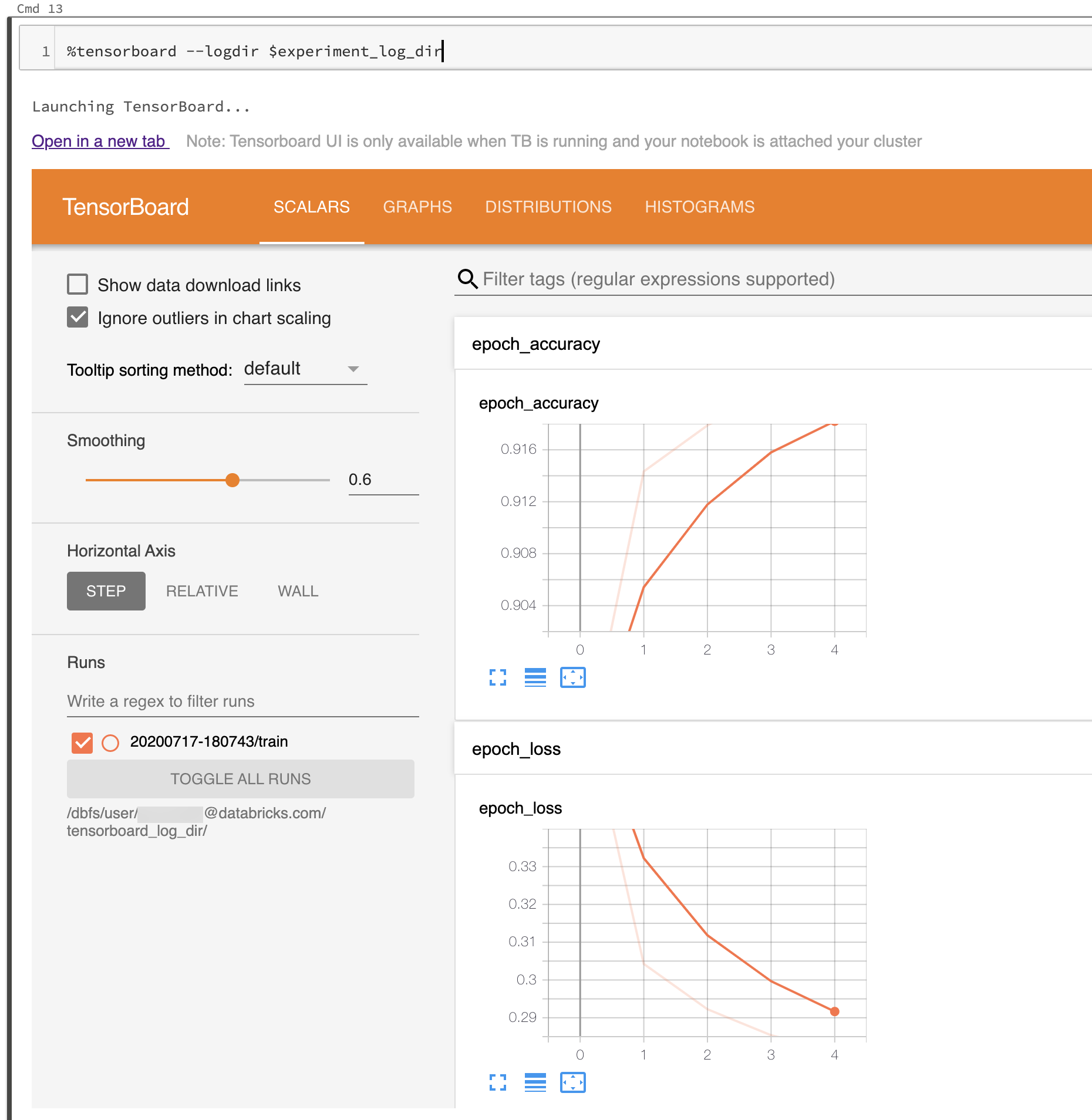
È anche possibile avviare TensorBoard usando direttamente il modulo notebook di TensorBoard.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
Log e directory di TensorBoard
TensorBoard visualizza i programmi di Machine Learning leggendo i log generati dai callback e dalle funzioni tensorBoard in TensorBoard o PyTorch. Per generare log per altre librerie di Machine Learning, è possibile scrivere direttamente i log usando writer di file TensorFlow . Vedere Modulo: tf.summary per TensorFlow 2.x e vedere Module: tf.compat.v1.summary per l'API precedente in TensorFlow 1.x .
Per assicurarsi che i log dell'esperimento siano archiviati in modo affidabile, Databricks consiglia di scrivere log nell'archiviazione cloud anziché nel file system temporaneo del cluster. Per ogni esperimento, avviare TensorBoard in una directory univoca. Per ogni esecuzione del codice di Machine Learning nell'esperimento che genera i log, impostare il callback o il writer di file TensorBoard per scrivere in una sottodirectory della directory dell'esperimento. In questo modo, i dati nell'interfaccia utente di TensorBoard sono separati in esecuzioni.
Leggere la documentazione ufficiale di TensorBoard per iniziare a usare TensorBoard per registrare le informazioni per il programma di Machine Learning.
Gestire i processi di TensorBoard
I processi TensorBoard avviati all'interno del notebook di Azure Databricks non vengono terminati quando il notebook viene scollegato o viene riavviato REPL, ad esempio quando si cancella lo stato del notebook. Per terminare manualmente un processo TensorBoard, inviarlo un segnale di terminazione usando %sh kill -15 pid. I processi TensorBoard uccisi in modo non corretto potrebbero danneggiare notebook.list().
Per elencare i server TensorBoard attualmente in esecuzione nel cluster, con le directory di log e gli ID processo corrispondenti, eseguire notebook.list() dal modulo notebook tensorBoard.
Problemi noti
- L'interfaccia utente di TensorBoard inline si trova all'interno di un iframe. Le funzionalità di sicurezza del browser impediscono il funzionamento dei collegamenti esterni all'interno dell'interfaccia utente, a meno che non si apra il collegamento in una nuova scheda.
- L'opzione
--window_titledi TensorBoard viene sottoposta a override in Azure Databricks. - Per impostazione predefinita, TensorBoard analizza un intervallo di porte per selezionare una porta in ascolto. Se nel cluster sono in esecuzione troppi processi TensorBoard, tutte le porte nell'intervallo di porte potrebbero non essere disponibili. È possibile ovviare a questa limitazione specificando un numero di porta con l'argomento
--port. La porta specificata deve essere compresa tra 6006 e 6106. - Per il funzionamento dei collegamenti per il download, è necessario aprire TensorBoard in una scheda.
- Quando si usa TensorBoard 1.15.0, la scheda Proiettore è vuota. Come soluzione alternativa, per visitare direttamente la pagina del proiettore, è possibile sostituire
#projectornell'URL didata/plugin/projector/projector_binary.html. - TensorBoard 2.4.0 presenta un problema noto che potrebbe influire sul rendering di TensorBoard se aggiornato.
- Se si registrano dati correlati a TensorBoard nei volumi DBFS o UC, è possibile che venga visualizzato un errore simile
No dashboards are active for the current data seta . Per risolvere questo errore, è consigliabile chiamarewriter.flush()ewriter.close()dopo aver usato per registrare iwriterdati. In questo modo tutti i dati registrati vengono scritti correttamente e disponibili per il rendering di TensorBoard.