Previsioni (senza server) con AutoML
Questo articolo illustra come eseguire un esperimento di previsione serverless usando l'interfaccia utente di addestramento del modello d'intelligenza artificiale Mosaic.
Addestramento del modello di intelligenza artificiale Mosaic - il forecasting semplifica la previsione dei dati delle serie temporali selezionando automaticamente l'algoritmo e gli iperparametri migliori, tutto durante l'esecuzione su risorse di calcolo completamente gestite.
Per comprendere la differenza tra la previsione serverless e quella di calcolo classica, vedere previsione serverless vs. previsione classica di calcolo.
Requisiti
Dati di training con una colonna time series salvata come tabella del catalogo Unity.
Se l'area di lavoro dispone di un Gateway di Uscita Protetto (Secure Egress Gateway, SEG) abilitato,
pypi.orgdeve essere aggiunto all'elenco dei domini consentiti. Vedere Gestione dei criteri di rete per il controllo in uscita serverless.
Creare un esperimento di previsione con l'interfaccia utente
Vai alla pagina di destinazione di Azure Databricks e fai clic su Esperimenti nella barra laterale.
Nel riquadro Previsione selezionare Avvia training.
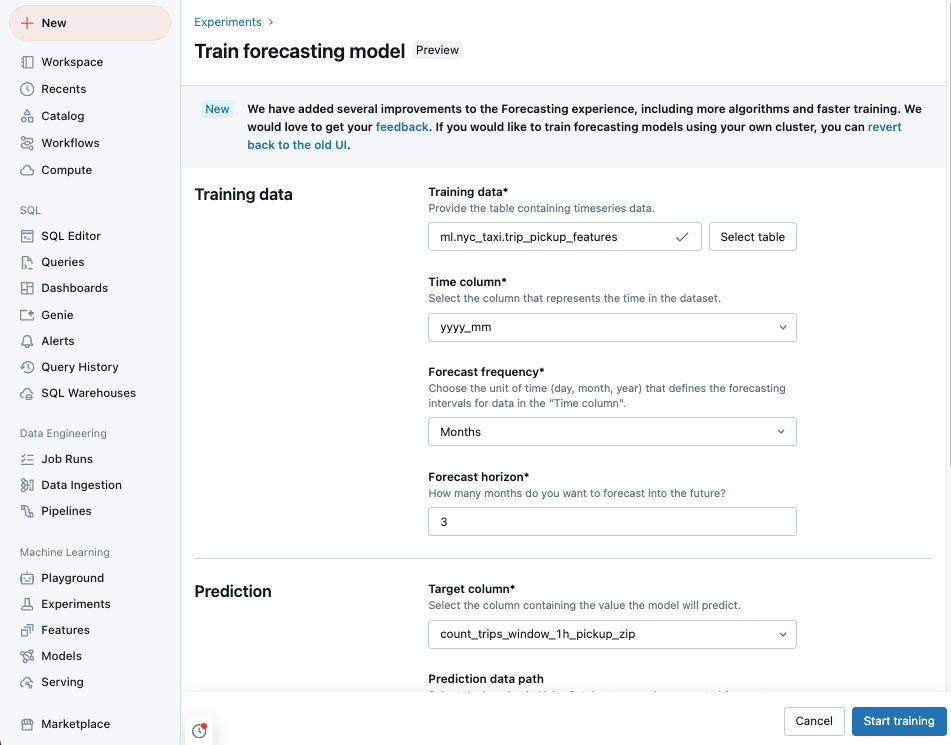
Seleziona i dati di addestramento da un elenco di tabelle del catalogo Unity a cui è possibile accedere.
-
colonna Tempo: selezionare la colonna contenente i periodi di tempo per la serie di dati temporali. Le colonne devono essere di tipo
timestampodate. - Frequenza Previsione: Seleziona l'unità di tempo che rappresenta la frequenza dei dati di input. Ad esempio, minuti, ore, giorni, mesi. Ciò determina la granularità della serie temporale.
- Orizzonte di previsione: Specificare quante unità della frequenza selezionata prevedere. Insieme alla frequenza di previsione, definisce sia le unità di tempo che il numero di unità di tempo da prevedere.
Nota
Per utilizzare l'algoritmo di Auto-ARIMA, la serie temporale deve avere una frequenza regolare, con l'intervallo tra due punti che deve essere costante per tutta la serie temporale. AutoML gestisce i passaggi temporali mancanti compilando tali valori con il valore precedente.
-
colonna Tempo: selezionare la colonna contenente i periodi di tempo per la serie di dati temporali. Le colonne devono essere di tipo
Selezionare una colonna di destinazione della previsione che si desidera far prevedere al modello.
Facoltativamente, specificare una tabella di Unity Catalog percorso dei dati di previsione per archiviare l'output delle previsioni.
Selezionare un percorso e un nome per la registrazione del modello nel Catalogo Unity .
Facoltativamente, impostare Opzioni avanzate:
- Nome esperimento: Inserisci un nome dell'esperimento MLflow.
- colonne identificatrici di serie temporali; per le previsioni su serie multiple, seleziona le colonne che identificano le singole serie temporali. Databricks raggruppa i dati in base a queste colonne come serie temporali diverse ed esegue il training di un modello per ogni serie in modo indipendente.
- metrica primaria: scegliere la metrica primaria usata per valutare e selezionare il modello migliore.
- Framework di addestramento: Scegliere i framework per AutoML da esplorare.
- Split column: Selezionare la colonna contenente la suddivisione dei dati personalizzati. I valori devono essere "train", "validate" , "test"
- Colonna di peso: Selezionare la colonna da usare per la ponderazione delle serie temporali. Tutti i campioni per una determinata serie temporale devono avere lo stesso peso. Il peso deve essere compreso nell'intervallo [0, 10000].
- 'area delle festività: selezionare l'area di vacanza da usare come covariati nel training del modello.
- Timeout: impostare una durata massima per l'esperimento AutoML.
Eseguire l'esperimento e monitorare i risultati
Per avviare l'esperimento AutoML, cliccare su Avvia addestramento. Dalla pagina di training dell'esperimento è possibile eseguire le operazioni seguenti:
- Arrestare l'esperimento in qualsiasi momento.
- Controlla le operazioni.
- Passare alla pagina di esecuzione per qualsiasi esecuzione.
Visualizzare i risultati o usare il modello migliore
Al termine del training, i risultati della stima vengono archiviati nella tabella Delta specificata e il modello migliore viene registrato nel catalogo Unity.
Nella pagina esperimenti scegliere tra i passaggi successivi seguenti:
- Selezionare Visualizzare le stime per visualizzare la tabella dei risultati delle previsioni.
- Selezionare notebook di inferenza batch per aprire un notebook generato automaticamente per l'inferenza batch usando il modello migliore.
- Selezionare Crea endpoint di gestione per distribuire il modello migliore in un endpoint model serving.
Previsione nel cloud rispetto alla previsione di calcolo classica
La tabella seguente riepiloga le differenze tra la previsione serverless e la previsione con calcolo classico
| Caratteristica | Previsione serverless | Previsione di calcolo classica |
|---|---|---|
| Infrastruttura di calcolo | Azure Databricks gestisce la configurazione di calcolo e ottimizza automaticamente i costi e le prestazioni. | Calcolo configurato dall'utente |
| Governance | Modelli e artefatti registrati nel catalogo unity | Archivio file dell'area di lavoro configurato dall'utente |
| Selezione dell'algoritmo | Modelli statistici più l'algoritmo di rete neurale di apprendimento profondo DeepAR | modelli statistici |
| Integrazione del repository di funzionalità | Non supportato | supportati |
| Notebook generati automaticamente | Notebook di inferenza in batch | Codice sorgente per tutte le prove |
| Distribuzione del modello con un clic | Sostenuto | Non confermato |
| Suddivisioni di training/convalida/test personalizzate | Sostenuto | Non supportato |
| Pesi personalizzati per singole serie temporali | Sostenuto | Non supportato |