Gestire il ciclo di vita del modello usando il Registro modelli dell’area di lavoro (legacy)
Importante
Questa documentazione illustra il Registro modelli dell’area di lavoro. Se l'area di lavoro è abilitata per Unity Catalog, non usare le procedure in questa pagina. Vedere invece Models in Unity Catalog.
Per indicazioni su come eseguire l'aggiornamento dal Registro modelli di area di lavoro al catalogo Unity, vedere Eseguire la migrazione di flussi di lavoro e modelli a Unity Catalog.
Se il catalogo predefinito dell'area di lavoro si trova in Unity Catalog (anziché hive_metastore) ed è in esecuzione un cluster con Databricks Runtime 13.3 LTS o versione successiva, i modelli vengono creati automaticamente nel e caricati dal catalogo predefinito dell'area di lavoro, senza la necessità di alcuna configurazione. Per usare il Registro modelli dell’area di lavoro in questo caso, è necessario impostarlo come destinazione in modo esplicito eseguendo import mlflow; mlflow.set_registry_uri("databricks") all'inizio del carico di lavoro. Un numero ridotto di aree di lavoro, dove sia il catalogo predefinito è stato configurato per un catalogo in Unity Catalog prima di gennaio 2024, sia il registro dei modelli di area di lavoro è stato utilizzato prima di gennaio 2024, è esente da questo comportamento e continua a utilizzare il Registro modelli di area di lavoro per impostazione predefinita.
Questo articolo descrive come usare il Registro modelli dell’area di lavoro come parte del flusso di lavoro di apprendimento automatico per gestire il ciclo di vita completo dei modelli di ML. Il Registro modelli dell’area di lavoro è una versione ospitata di Databricks del Registro modelli MLflow.
Il Registro modelli dell'area di lavoro offre:
- Derivazione cronologica del modello (il cui utilizzo ed esecuzione in MLflow ha prodotto il modello in un determinato momento).
- Gestione dei modelli.
- Controllo delle versioni dei modelli.
- Transizioni di fase (ad esempio, dalla gestione temporanea alla produzione o all’archiviazione).
- I webhook consentono di attivare automaticamente le azioni in base agli eventi del registro di sistema.
- Notifiche tramite posta elettronica degli eventi del modello.
È anche possibile creare e visualizzare le descrizioni dei modelli e lasciare commenti.
Questo articolo comprende istruzioni per l'interfaccia utente del registro modelli dell’area di lavoro e l'API del Registro di sistema del modello dell’area di lavoro.
Per una panoramica dei concetti relativi al Registro dei modelli di Workspace, vedere MLflow per l'agente generativo di intelligenza artificiale e il ciclo di vita del modello di Machine Learning.
Creare o registrare un modello
È possibile creare o registrare un modello usando l'interfaccia utente oppure registrare un modello utilizzando l'API.
Creare o registrare un modello usando l'interfaccia utente
Esistono due modi per registrare un modello nel registro dei modelli dell'area di lavoro. È possibile registrare un modello esistente che è stato registrato in MLflow oppure è possibile creare e registrare un nuovo modello vuoto e quindi assegnare a tale modello un modello registrato in precedenza.
Registrare un modello registrato esistente da un notebook
Nell'area di lavoro identificare l'esecuzione di MLflow contenente il modello da registrare.
Fare clic sull'icona Esperimento
 nella barra laterale destra del notebook.
nella barra laterale destra del notebook.
Nella barra laterale Esecuzioni esperimenti fare clic
 sull'icona accanto alla data dell’esecuzione. Viene visualizzata la pagina dell'esecuzione di MLflow. Questa pagina mostra i dettagli dell'esecuzione, inclusi parametri, metriche, tag ed elenco di artefatti.
sull'icona accanto alla data dell’esecuzione. Viene visualizzata la pagina dell'esecuzione di MLflow. Questa pagina mostra i dettagli dell'esecuzione, inclusi parametri, metriche, tag ed elenco di artefatti.
Nella sezione Artefatti fare clic sulla directory denominata xxx-model.
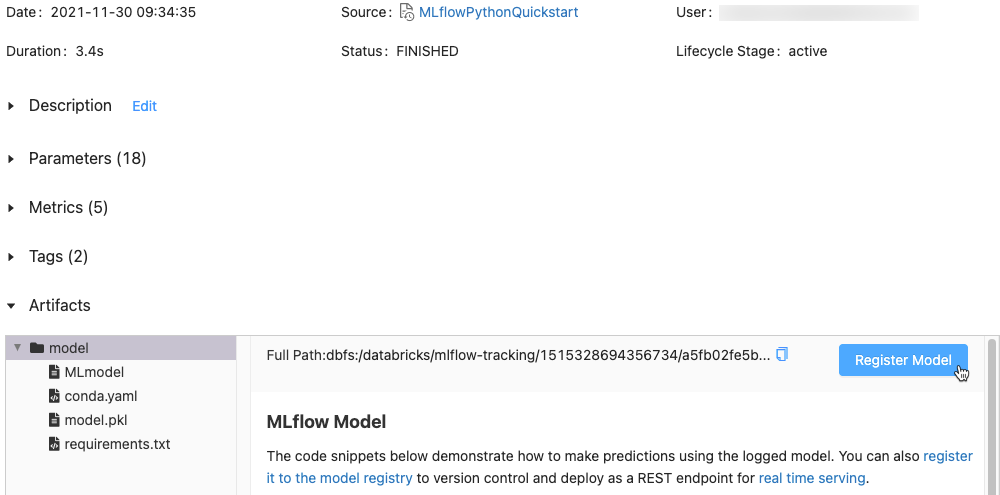
Fare clic sul pulsante Registra modello all'estremità destra.
Nella finestra di dialogo fare clic nella casella Modello ed eseguire una delle seguenti operazioni:
- Selezionare Crea nuovo modello dal menu a discesa. Viene visualizzato il campo Nome modello. Immettere un nome per il modello, ad esempio
scikit-learn-power-forecasting. - Selezionare un modello esistente dal menu a discesa.
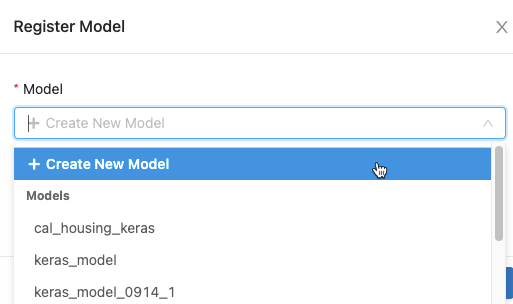
- Selezionare Crea nuovo modello dal menu a discesa. Viene visualizzato il campo Nome modello. Immettere un nome per il modello, ad esempio
Fare clic su Registra.
- Selezionando Crea nuovo modello, verrà registrato un modello denominato
scikit-learn-power-forecasting, verrà eseguita la copia del modello in un percorso protetto gestito dal registro di modelli dell’area di lavoro e verrà creata una nuova versione del modello. - Se è stato selezionato un modello esistente, viene registrata una nuova versione del modello selezionato.
Dopo qualche istante, il pulsante Registra modello si trasforma in un link alla nuova versione del modello registrato.
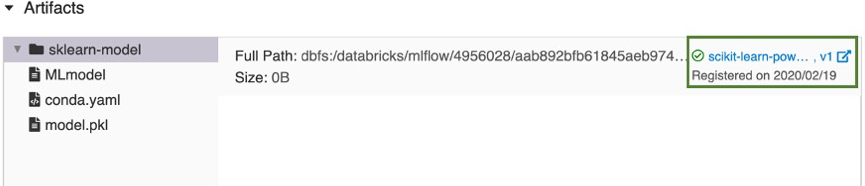
- Selezionando Crea nuovo modello, verrà registrato un modello denominato
Fare clic sul collegamento per aprire la nuova versione del modello nell'interfaccia utente del registro di modelli dell’area di lavoro. È anche possibile trovare il modello nel registro di modelli dell’area di lavoro facendo clic su
 Modelli nella barra laterale.
Modelli nella barra laterale.
Creare un nuovo modello registrato e assegnare a tale modello un modello registrato
È possibile usare il pulsante Crea modello nella pagina dei modelli registrati per creare un nuovo modello vuoto e quindi assegnare a tale modello un modello registrato. Seguire questa procedura:
Nella pagina dei modelli registrati fare clic su Crea modello. Immettere un nome per il modello e fare clic su Crea.
Seguire i passaggi da 1 a 3 in Registrare un modello registrato esistente da un notebook.
Nella finestra di dialogo Registra modello selezionare il nome del modello creato nel passaggio 1 e fare clic su Registra. Verrà registrato un modello con il nome creato, verrà eseguita copia del modello in un percorso protetto gestito dal registro di modelli dell’area di lavoro e verrà creata una versione del modello:
Version 1.Dopo qualche momento l'interfaccia utente di MLflow Run (Esecuzione MLflow) sostituisce il pulsante Registra modello con un collegamento alla nuova versione del modello registrato. È ora possibile selezionare il modello dall'elenco a discesa Modello nella finestra di dialogo Registra Modello sulla pagina Esecuzioni esperimenti. È anche possibile registrare nuove versioni del modello specificandone il nome nei comandi dell'API, ad esempio Create ModelVersion.
Registrare un modello usando l'API
È possibile registrare un modello nel registro di modelli dell’area di lavoro in tre modi programmatici. Tutti i metodi copiano il modello in un percorso protetto gestito dal registro di modelli dell’area di lavoro.
Per registrare un modello e registrarlo con il nome specificato durante un esperimento di MLflow, usare il metodo
mlflow.<model-flavor>.log_model(...). Se non esiste un modello registrato con il nome specifico, il metodo registrerà un nuovo modello, creerà la versione 1 e restituirà un oggettoModelVersiondi MLflow. Se esiste già un modello registrato con il nome specifico, il metodo creerà una nuova versione del modello e restituirà l'oggetto versione.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )Per registrare un modello con il nome specificato dopo il completamento di tutte le esecuzioni dell'esperimento e la selezione del modello più adatto per l'aggiunta al registro, usare il metodo
mlflow.register_model(). Per questo metodo è necessario l'ID esecuzione per l'argomentomlruns:URI. Se non esiste un modello registrato con il nome specifico, il metodo registrerà un nuovo modello, creerà la versione 1 e restituirà un oggettoModelVersiondi MLflow. Se esiste già un modello registrato con il nome specifico, il metodo creerà una nuova versione del modello e restituirà l'oggetto versione.result=mlflow.register_model("runs:<model-path>", "<model-name>")Per creare un nuovo modello registrato con il nome specificato, usare il metodo
create_registered_model()dell'API MLflow Client. Se il nome del modello esiste già, il metodo genera un'eccezioneMLflowException.client = MlflowClient() result = client.create_registered_model("<model-name>")
È anche possibile registrare un modello con il provider Databricks Terraform e databricks_mlflow_model.
Limiti di quota
A partire da maggio 2024 per tutte le aree di lavoro di Databricks, il Registro modelli dell’area di lavoro impone limiti di quota per il numero totale di modelli registrati e versioni del modello per area di lavoro. Vedere Limiti delle risorse. Se si superano le quote del Registro di sistema, Databricks consiglia di eliminare modelli registrati e versioni del modello non più necessari. Databricks consiglia inoltre di regolare la registrazione e la strategia di conservazione del modello per rimanere entro il limite. Se è necessario aumentare i limiti dell'area di lavoro, contattare il team dell'account Databricks.
Il seguente notebook illustra come eseguire l'inventario ed eliminare le entità del Registro di sistema del modello.
Notebook delle entità del Registro di sistema del modello dell'area di lavoro di inventario
Prendi il notebook
Visualizzare i modelli nell'interfaccia utente
Pagina modelli registrati
La pagina dei modelli registrati viene visualizzata facendo clic su ![]() Modelli nella barra laterale. Questa pagina mostra tutti i modelli nel Registro di sistema.
Modelli nella barra laterale. Questa pagina mostra tutti i modelli nel Registro di sistema.
Da questa pagina è possibile creare un nuovo modello.
Inoltre, da questa pagina, gli amministratori dell'area di lavoro possono impostare le autorizzazioni per tutti i modelli nel Registro dei modelli di area di lavoro.

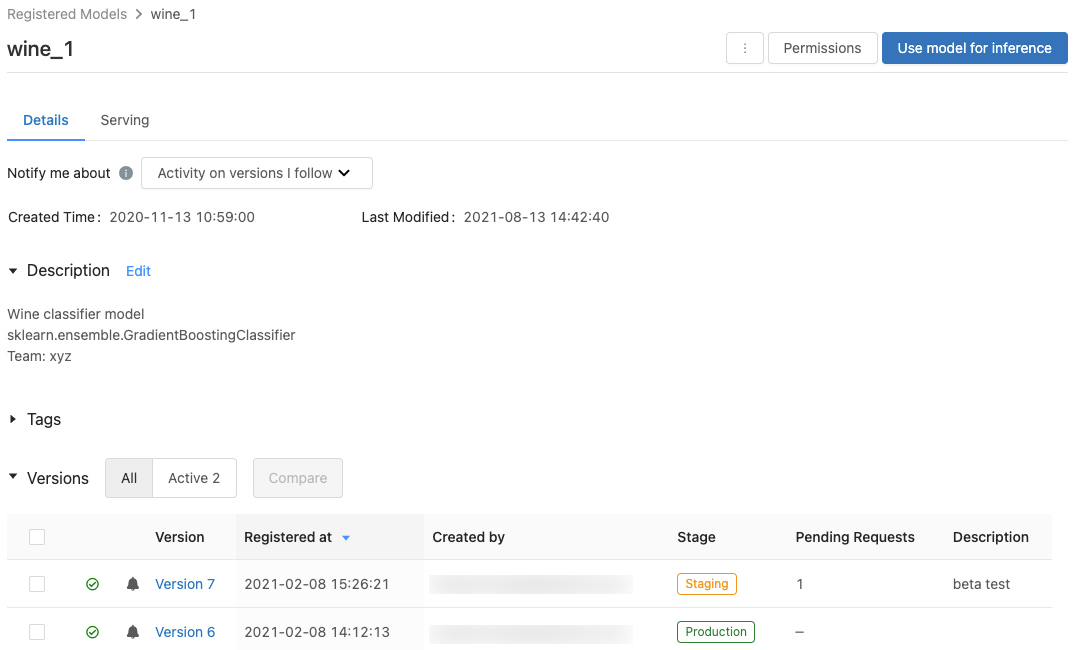
Pagina modello registrato
Per visualizzare la pagina del modello registrato, fare clic sul nome di un modello nella pagina dei modelli registrati. La pagina del modello registrato mostra informazioni sul modello selezionato e una tabella con informazioni su ogni versione del modello. Da questa pagina è anche possibile:
- Configurare modello di gestione.
- Generare automaticamente un notebook per utilizzare il modello per l'inferenza.
- Configurare le notifiche tramite posta elettronica.
- Confrontare le versioni del modello.
- Impostare le autorizzazioni per il modello.
- Elimina un modello.
Pagina della versione del modello
Per visualizzare la pagina della versione del modello, eseguire una delle seguenti operazioni:
- Fare clic su un nome di versione nella colonna versione più recente nella pagina dei modelli registrati.
- Fare clic su un nome di versione nella colonna versione
nella pagina del modello registrato.
Questa pagina visualizza informazioni su una versione specifica di un modello registrato e presenta anche un collegamento all'esecuzione di origine (la versione del notebook eseguita per creare il modello). Da questa pagina è anche possibile:
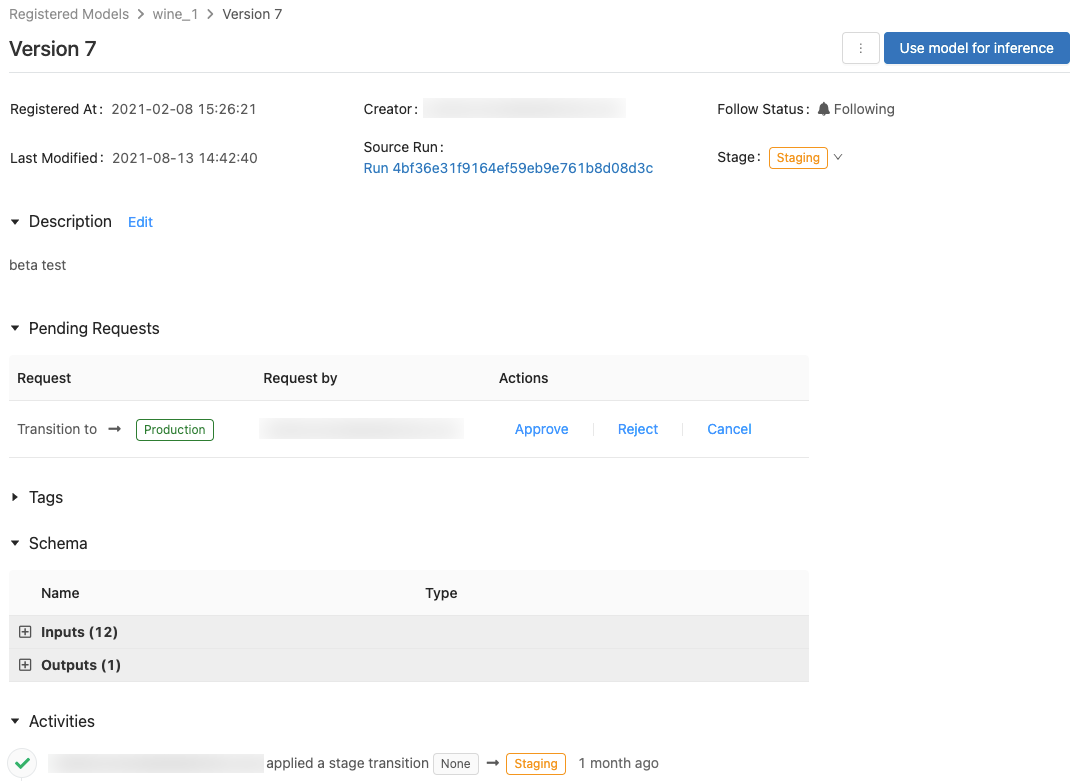
Controllare l'accesso ai modelli
È necessario disporre almeno dell'autorizzazione CAN MANAGE per configurare le autorizzazioni per un modello. Per informazioni sui livelli di autorizzazione del modello, si veda ACL del modello MLflow. Una versione del modello eredita le autorizzazioni dal modello padre. Non è possibile impostare le autorizzazioni per le versioni del modello.
Nella barra laterale fare clic su
Modelli.Selezionare un nome di modello.
Fare clic su Autorizzazioni. Sui aprirà la finestra di dialogo Impostazioni autorizzazione

Nella finestra di dialogo, selezionare l'elenco a discesa Seleziona utente, gruppo o entità servizio e poi selezionare un utente, un gruppo o un'entità servizio.
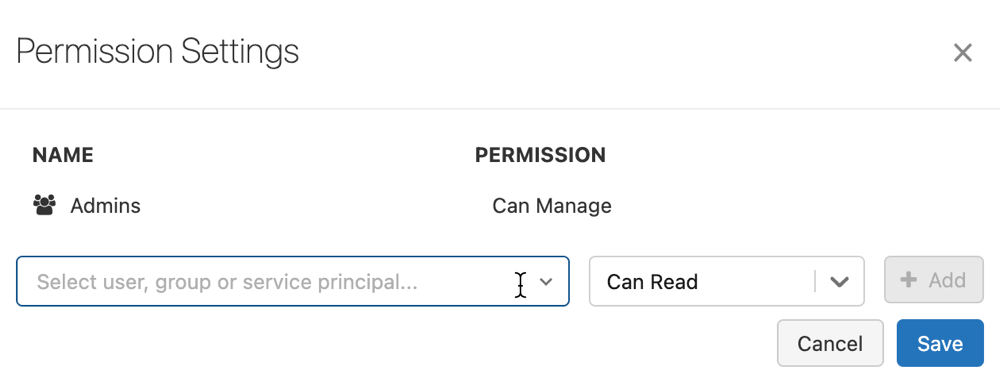
Selezionare un'autorizzazione dal menu a tendina delle autorizzazioni.
Fare clic su Aggiungi e poi su Salva.
Gli amministratori e gli utenti dell'area di lavoro con autorizzazione CAN MANAGE a livello di Registro di sistema possono impostare i livelli di autorizzazione per tutti i modelli nell'area di lavoro facendo clic su Autorizzazioni nella pagina Modelli.
Eseguire la transizione a una fase del modello
Una versione del modello ha una delle fasi seguenti: Nessuno, Gestione temporanea, Produzione o Archiviazione. La fase Staging è destinata al test e alla convalida dei modelli, mentre la fase Produzione è destinata alle versioni dei modelli che hanno completato i processi di test o di verifica e sono state distribuite nelle applicazioni per l'assegnazione dei punteggi attiva. Si presuppone che una versione di modello Archived (Archiviata) sia inattiva ed è quindi possibile considerarne l'eliminazione. Diverse versioni di un modello possono trovarsi in fasi diverse.
Un utente con autorizzazione appropriata può eseguire la transizione di una versione del modello tra le fasi. Se si è autorizzati a eseguire la transizione di una versione del modello a una fase specifica, sarà possibile eseguire direttamente la transizione. Se non si è autorizzati, è possibile richiedere una transizione di fase e un utente autorizzato a eseguire la transizione di versioni del modello può approvare, rifiutare o annullare la richiesta.
È possibile eseguire la transizione di una fase del modello usando l'interfaccia utente o usando l'API.
Eseguire la transizione a una fase del modello usando l'interfaccia utente
Seguire queste istruzioni per eseguire la transizione a una fase del modello.
Per visualizzare l'elenco delle fasi del modello disponibili e le opzioni disponibili, in una pagina della versione del modello fare clic sull'elenco a discesa accanto a Fase: e richiedere o selezionare una transizione a un'altra fase.
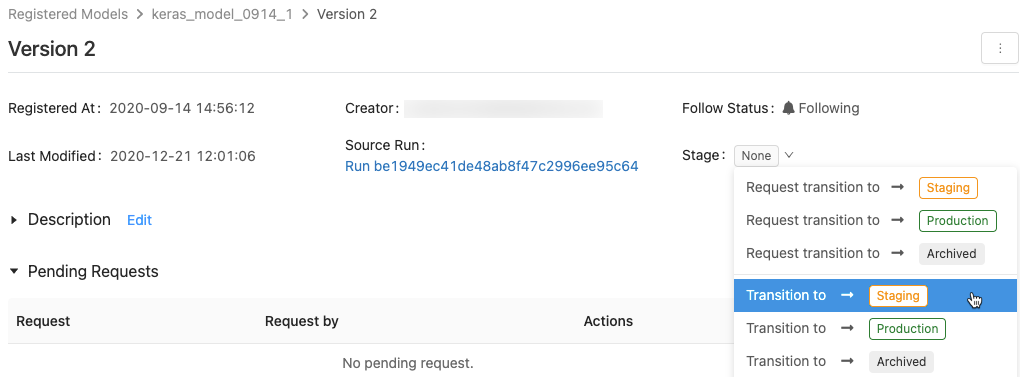
Immettere un commento facoltativo e fare clic su OK.
Eseguire la transizione di una versione del modello alla fase Produzione
Dopo il test e la convalida è possibile eseguire la transizione o richiedere una transizione alla fase Produzione.
Il registro di modelli dell’area di lavoro consente più versioni del modello registrato in ogni fase. Se si vuole avere solo una versione in Produzione, è possibile eseguire la transizione di tutte le versioni del modello attualmente presenti in Produzione alla fase Archiviata selezionando Transition existing Production model versions to Archived (Esegui la transizione delle versioni del modello di Produzione ad Archiviata).
Approvare, rifiutare o annullare una richiesta di transizione a una fase della versione del modello
Un utente senza autorizzazione per la transizione di fase può richiedere una transizione di fase. La richiesta viene visualizzata nella sezione Richieste in sospeso nella pagina della versione del modello:

Per approvare, rifiutare o annullare una richiesta di transizione di fase, fare clic sul collegamento Approva, Rifiuta o Annulla.
L'autore di una richiesta di transizione può anche annullare la richiesta.
Visualizzare le attività della versione del modello
Per visualizzare tutte le transizioni richieste, approvate, in sospeso e applicate a una versione del modello, passare alla sezione Attività. Questo record di attività fornisce una derivazione del ciclo di vita del modello per il controllo o l'indagine.
Eseguire la transizione a una fase del modello usando l'API
Gli utenti con autorizzazioni appropriate possono eseguire la transizione di una versione del modello a una nuova fase.
Per aggiornare una fase della versione del modello a una nuova fase, utilizzare il metodo transition_model_version_stage() del MLflow Client API.
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
I valori accettati per <stage> sono: "Staging"|"staging", "Archived"|"archived", "Production"|"production", "None"|"none".
Utilizzare il modello per l'inferenza
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Dopo la registrazione di un modello nel Registro modelli dell'area di lavoro, è possibile generare automaticamente un notebook per usare il modello per l'inferenza batch o di streaming. In alternativa, è possibile creare un endpoint per usare il modello per la gestione in tempo reale con Gestione modelli.
Nell'angolo in alto a destra della pagina del modello registrato o nella pagina della versione del modello fare clic su  . Viene visualizzata la finestra di dialogo Configura inferenza del modello, che consente di configurare l'inferenza batch, streaming o in tempo reale.
. Viene visualizzata la finestra di dialogo Configura inferenza del modello, che consente di configurare l'inferenza batch, streaming o in tempo reale.
Importante
Anaconda Inc. ha aggiornato le condizioni del servizio per i canali anaconda.org. In base alle nuove condizioni del servizio, potrebbe essere necessaria una licenza commerciale se ci si affida alla distribuzione e alla creazione di pacchetti di Anaconda. Per altre informazioni, vedere Domande frequenti su Anaconda edizione Commerciale. L'uso di qualsiasi canale Anaconda è disciplinato dalle condizioni del servizio.
I modelli MLflow registrati prima della versione 1.18 (Databricks Runtime 8.3 ML o versioni precedenti) sono stati registrati per impostazione predefinita con il canale conda defaults (https://repo.anaconda.com/pkgs/) come dipendenza. A causa di questa modifica della licenza, Databricks ha interrotto l'uso del canale per i modelli defaults registrati usando MLflow v1.18 e versioni successive. Il canale predefinito registrato è ora conda-forge, che punta alla community gestita https://conda-forge.org/.
Se è stato registrato un modello prima di MLflow v1.18 senza escludere il canale defaults dall'ambiente conda per il modello, tale modello potrebbe avere una dipendenza dal canale defaults che potrebbe non essere prevista.
Per verificare manualmente se un modello ha questa dipendenza, è possibile esaminare il valore channel nel file conda.yaml incluso nel pacchetto con il modello registrato. Ad esempio, un modello conda.yaml con una dipendenza defaults del canale può essere simile al seguente:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Poiché Databricks non è in grado di stabilire se l'uso del repository di Anaconda per interagire con i propri modelli sia consentito dal rapporto con Anaconda, Databricks non obbliga i propri clienti ad apportare alcuna modifica. Se l'uso del repository di Anaconda.com attraverso l'uso di Databricks è consentito dalle condizioni di Anaconda, non è necessario eseguire alcuna azione.
Se si vuole modificare il canale usato nell'ambiente di un modello, è possibile registrare nuovamente il modello nel registro modelli dell’area di lavoro con un nuovo oggetto conda.yaml. A tale scopo, è possibile specificare il canale nel parametro conda_env di log_model().
Per altre informazioni sull'API log_model(), vedere la documentazione di MLflow relativa alla versione del modello con cui si sta lavorando, ad esempio log_model per scikit-learn.
Per ulteriori informazioni su conda.yaml, si veda la documentazione MLflow.
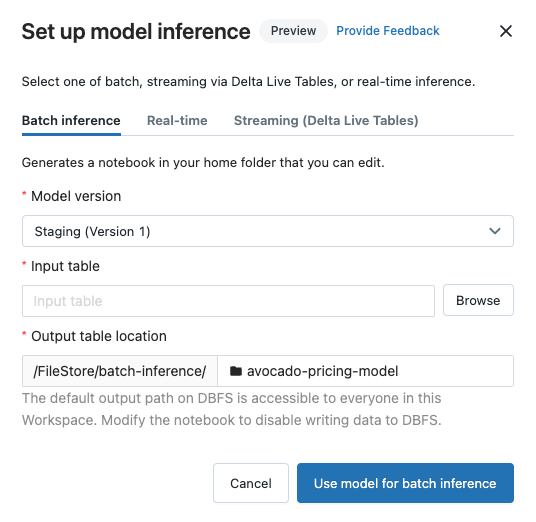
Configurare l'inferenza in batch
Quando si seguono questi passaggi per creare un notebook di inferenza batch, il notebook viene salvato nella cartella utente, nella cartella Batch-Inference sotto una cartella con il nome del modello. È possibile modificare il notebook in base alle esigenze.
Fare clic sulla scheda Inferenza batch.
Nell'elenco a discesa versione del modello selezionare la versione del modello da usare. I primi due elementi nell'elenco a discesa sono la versione corrente di produzione e di gestione temporanea del modello (se presenti). Quando si seleziona una di queste opzioni, il notebook usa automaticamente la versione di produzione o gestione temporanea al momento dell'esecuzione. Non è necessario aggiornare il notebook man mano che si continua a sviluppare il modello.
Fare clic sul pulsante Sfoglia accanto a tabella di input. La finestra di dialogo Seleziona i dati di input viene visualizzata. Se necessario, è possibile modificare il cluster nell'elenco a discesa Calcolo.
Nota
Per le aree di lavoro abilitate per Unity Catalog, la finestra di dialogo Seleziona dati di input consente di selezionare tra tre livelli:
<catalog-name>.<database-name>.<table-name>.Selezionare la tabella contenente i dati di input per il modello e fare clic su Selezionare. Il notebook generato importa automaticamente questi dati e li invia al modello. È possibile modificare il notebook generato se i dati richiedono trasformazioni prima di essere inseriti nel modello.
Le previsioni vengono salvate in una cartella nella directory
dbfs:/FileStore/batch-inference. Per impostazione predefinita, le previsioni vengono salvate in una cartella con lo stesso nome del modello. Ogni esecuzione del notebook generato scrive un nuovo file in questa directory con il timestamp aggiunto in coda al nome. È anche possibile scegliere di non includere il timestamp e di sovrascrivere il file con le esecuzioni successive del notebook; le istruzioni sono fornite nel notebook generato.È possibile modificare la cartella in cui vengono salvate le stime digitando un nuovo nome di cartella nel campo percorso tabella di output oppure facendo clic sull'icona della cartella per esplorare la directory e selezionare una cartella diversa.
Per salvare le previsioni in una posizione in Unity Catalog, è necessario modificare il notebook. Per un notebook di esempio che illustra come eseguire il training di un modello di apprendimento automatico che utilizza i dati in Unity Catalog e restituire i risultati a Unity Catalog, vedere esercitazione di apprendimento automatico.
Configurare l'inferenza di streaming usando le Delta Live Tables
Quando si seguono questi passaggi per creare un notebook di inferenza di streaming, il notebook viene salvato nella cartella utente, nella cartella DLT-Inference sotto una cartella con il nome del modello. È possibile modificare il notebook in base alle esigenze.
Fare clic sulla scheda Streaming (Tabelle live Delta).
Nell'elenco a discesa versione del modello selezionare la versione del modello da usare. I primi due elementi nell'elenco a discesa sono la versione corrente di produzione e di gestione temporanea del modello (se presenti). Quando si seleziona una di queste opzioni, il notebook usa automaticamente la versione di produzione o gestione temporanea al momento dell'esecuzione. Non è necessario aggiornare il notebook man mano che si continua a sviluppare il modello.
Fare clic sul pulsante Sfoglia accanto a tabella di input. La finestra di dialogo Seleziona i dati di input viene visualizzata. Se necessario, è possibile modificare il cluster nell'elenco a discesa Calcolo.
Nota
Per le aree di lavoro abilitate per Unity Catalog, la finestra di dialogo Seleziona dati di input consente di selezionare tra tre livelli:
<catalog-name>.<database-name>.<table-name>.Selezionare la tabella contenente i dati di input per il modello e fare clic su Selezionare. Il notebook generato crea una trasformazione dei dati che usa la tabella di input come origine e integra MLflow UDF di inferenza PySpark per eseguire stime del modello. È possibile modificare il notebook generato se i dati richiedono ulteriori trasformazioni prima o dopo l'applicazione del modello.
Specificare il nome della Delta Live Table di output. Il notebook crea una tabella dinamica con il nome specificato e la usa per archiviare le stime del modello. È possibile modificare il notebook generato per personalizzare il set di dati di destinazione in base alle esigenze, ad esempio definire una tabella live di streaming come output, aggiungere informazioni sullo schema o vincoli di qualità dei dati.
È quindi possibile creare una nuova pipeline delta live tables con questo notebook o aggiungerla a una pipeline esistente come libreria di notebook aggiuntiva.
Configurare l'inferenza in tempo reale
Gestione dei modelli mette a disposizione i modelli di Machine Learning di MLflow come endpoint dell'API REST scalabili. Per creare un endpoint per la gestione dei modelli, si veda Creare endpoint personalizzati per la gestione di modelli.
Inviare commenti
Questa funzionalità è disponibile in anteprima ed è consigliabile ricevere commenti e suggerimenti. Per inviare un feedback, fare clic su Provide Feedback nella finestra di dialogo Configura inferenza del modello.
Confrontare le versioni del modello
È possibile confrontare le versioni del modello nel Registro dei modelli dell'area di lavoro.
- Nella pagina del modello registrato , selezionare due o più versioni dei modelli facendo clic sulla casella di controllo a sinistra della versione.
- Fare clic su Confronta.
- Viene visualizzata la schermata di confronto delle versioni
<N>, che mostra una tabella che mette a confronto i parametri, lo schema e le metriche delle versioni del modello selezionate. Nella parte inferiore della schermata è possibile selezionare il tipo di tracciato (coordinate a dispersione, contorno o parallele) e i parametri o le metriche da tracciare.
Controllare le preferenze di notifica
È possibile configurare il Registro modelli dell’area di lavoro per inviare una notifica tramite posta elettronica sull'attività sui modelli registrati e sulle versioni del modello specificate.
Nella pagina del modello registrato, il menu Notifica informazioni presenta tre opzioni:
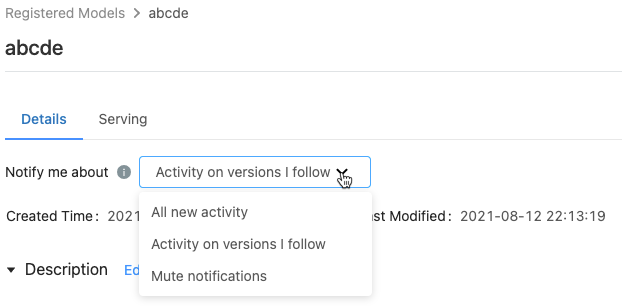
- Tutte le nuove attività: inviare notifiche tramite posta elettronica per tutte le attività in tutte le versioni di questo modello. Se è stato creato il modello registrato, questa impostazione è predefinita.
- Attività nelle seguenti versioni: Inviare notifiche tramite posta elettronica solo per le versioni del modello seguite. Attivando questa selezione, si ricevono notifiche per tutte le versioni del modello seguite; non è possibile disattivare le notifiche per una versione specifica del modello.
- Notifiche disattivate: non inviare notifiche tramite posta elettronica per l’attività in questo modello registrato.
La notifica tramite posta elettronica viene attivata dai seguenti eventi:
- Creazione di una nuova versione del modello
- Richiesta di una transizione di fase
- Transizione di fase
- Nuovi commenti
Si viene automaticamente iscritti alle notifiche dei modelli quando si effettua una delle seguenti operazioni:
- Commento sulla versione del modello
- Transizione di una versione del modello
- Effettuare una richiesta di transizione per la fase del modello
Per verificare se si segue una versione del modello, esaminare il campo Segui stato nella pagina della versione del modello oppure nella tabella delle versioni del modello nella pagina del modello registrato .
Disattivare le notifiche tramite posta elettronica
È possibile disattivare le notifiche tramite posta elettronica nella scheda Impostazioni registro modelli dell’area di lavoro del menu Impostazioni utente:
- Fare clic sul proprio nome utente nell'angolo superiore destro dell'area di lavoro di Azure Databricks e selezionare Impostazioni dal menu a discesa.
- Nella barra laterale di Impostazioni selezionare Notifiche.
- Disattivare le notifiche tramite posta elettronica del Registro modelli.
Un amministratore dell'account può disattivare le notifiche tramite posta elettronica per l'intera organizzazione nella pagina delle impostazioni di amministrazione.
Numero massimo di messaggi di posta elettronica inviati
Il Registro modelli dell’area di lavoro limita il numero di messaggi di posta elettronica inviati al giorno a ogni utente per ogni attività. Ad esempio, se si ricevono 20 messaggi di posta elettronica in un giorno sulle nuove versioni del modello create per un modello registrato, Registro modelli di area di lavoro invia un messaggio di posta elettronica che indica che è stato raggiunto il limite giornaliero e non vengono inviati messaggi di posta elettronica aggiuntivi su tale evento fino al giorno successivo.
Per aumentare il limite del numero di messaggi di posta elettronica consentiti, contattare il team dell'account Azure Databricks.
Webhooks
Importante
Questa funzionalità è disponibile in anteprima pubblica.
I webhook consentono di restare in ascolto degli eventi del Registro dei modelli dell’area di lavoro in modo che le integrazioni possano attivare automaticamente le azioni. È possibile usare webhook per automatizzare e integrare la pipeline di Machine Learning con gli strumenti e i flussi di lavoro CI/CD esistenti. Ad esempio, è possibile attivare compilazioni CI quando viene creata una nuova versione del modello o inviare una notifica ai membri del team tramite Slack ogni volta che viene richiesta una transizione del modello alla produzione.
Annotare un modello o una versione del modello
È possibile fornire informazioni su un modello o una versione del modello mediante le annotazioni. È ad esempio possibile che si voglia includere una panoramica del problema o informazioni sulla metodologia e sull'algoritmo usato.
Annotare un modello o una versione del modello usando l'interfaccia utente
L'interfaccia utente di Azure Databricks offre diversi modi per annotare modelli e versioni del modello. È possibile aggiungere informazioni di testo usando una descrizione o commenti ed è possibile aggiungere tag chiave-valore ricercabili. Le descrizioni e i tag sono disponibili per modelli e versioni del modello; i commenti sono disponibili solo per le versioni del modello.
- Le descrizioni hanno lo scopo di fornire informazioni sul modello.
- I commenti sono un modo per mantenere una discussione continua sulle attività di una versione del modello.
- I tag consentono di personalizzare i metadati del modello per semplificare la ricerca di modelli specifici.
Aggiungere o aggiornare la descrizione per un modello o una versione del modello
Dalla pagina Modelli registrati o Versione modello fare clic sull'icona Modifica accanto all’icona Descrizione. Viene visualizzata una finestra di modifica.
Immettere o modificare la descrizione nella finestra di modifica.
Fare clic su Salva per salvare le modifiche o Annulla per chiudere la finestra.
Se è stata immessa una descrizione di una versione del modello, la descrizione viene visualizzata nella colonna Descrizione della tabella nella pagina del modello registrato . La colonna visualizza un massimo di 32 caratteri o una riga di testo, a seconda di quale sia più corta.
Aggiungere commenti per una versione del modello
- Scorrere verso il basso la pagina della versione del modello e fare clic sulla freccia GIÙ accanto ad Attività.
- Digitare il commento nella finestra di modifica e fare clic su Aggiungi Commento.
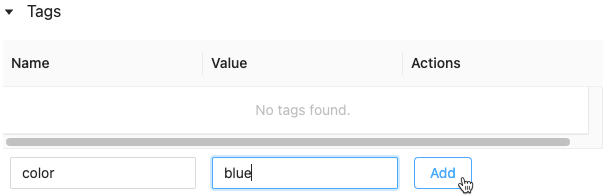
Aggiungere tag per un modello o una versione del modello
Nella pagina modello registrato o versione del modello fare clic su
 se non è già aperto. Viene visualizzata la tabella dei tag.
se non è già aperto. Viene visualizzata la tabella dei tag.
Cliccare i campi Nome e Valore e digitare la chiave e il valore per il tag.
Cliccare Aggiungi.
Modificare o eliminare tag per un modello o una versione del modello
Per modificare o eliminare un tag esistente, usare le icone nella colonna Actions.

Annotare una versione del modello usando l'API
Per aggiornare una descrizione della versione del modello, usare il metodo update_model_version() dell'API client MLflow:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
Per impostare o aggiornare un tag per un modello o una versione del modello registrata, usare il metodo MLflow Client API set_registered_model_tag()) o set_model_version_tag():
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
Rinominare un modello (solo API)
Per rinominare un modello registrato, usare il metodo rename_registered_model() dell'API MLflow Client:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Nota
È possibile rinominare un modello registrato solo se non ha versioni o se tutte le versioni si trovano nella fase Nessuna o Archived (Archiviata).
Cercare un modello
È possibile cercare modelli nel Registro modelli dell’area di lavoro usando l'interfaccia utente o l'API.
Nota
Quando si cerca un modello, vengono restituiti solo i modelli per i quali si dispone almeno delle autorizzazioni CAN READ.
Cercare un modello usando l'interfaccia utente
Per visualizzare i modelli registrati, fare clic su ![]() Modelli nella barra laterale.
Modelli nella barra laterale.
Per cercare un modello specifico, immettere testo nella casella di ricerca. È possibile immettere il nome di un modello o una qualsiasi parte del nome:
È anche possibile fare una ricerca in base a tag. Immettere i tag nel formato: tags.<key>=<value>. Per cercare più tag, usare l'operatore AND.

È possibile cercare sia il nome del modello che i tag usando la sintassi di ricerca MLflow. Ad esempio:

Cercare un modello usando l'API
È possibile cercare modelli registrati nel Registro dei modelli dell’area di lavoro con il metodo API client MLflow search_registered_models()
Se è impostare tag sui modelli, è anche possibile eseguire ricerche in base a tali tag con search_registered_models().
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
È anche possibile cercare un nome di modello specifico ed elencarne i dettagli della versione usando il metodo search_model_versions() API client MLflow:
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
Verrà restituito questo output:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
Eliminare un modello o una versione del modello
È possibile eliminare un modello usando l'interfaccia utente o l'API.
Eliminare una versione del modello o un modello usando l'interfaccia utente
Avviso
Non è possibile annullare questa azione. È possibile eseguire la transizione di una versione del modello alla fase Archived (Archiviata) invece di eliminarla dal registro. Quando si elimina un modello, tutti gli artefatti del modello archiviati dal registro di modelli dell’area di lavoro e tutti i metadati associati al modello registrato vengono eliminati.
Nota
È possibile eliminare modelli e versioni del modello solo nella fase Nessuna o Archived (Archiviata). Se un modello registrato ha versioni nella fase Staging o Produzione, è necessario eseguirne la transizione alla fase Nessuna o Archived (Archiviata) prima di eliminare il modello.
Per eliminare una versione del modello:
- Fare clic su Modelli nella barra laterale.
- Fare clic sul nome di un modello.
- Fare clic su una versione del modello.
- Fare clic sul menu kebab
 nell'angolo in alto a destra dello schermo e selezionare Elimina dal menu a discesa.
nell'angolo in alto a destra dello schermo e selezionare Elimina dal menu a discesa.
Per eliminare un modello:
- Fare clic su Modelli nella barra laterale.
- Fare clic sul nome di un modello.
- Fare clic sul menu kebab nell'angolo in alto a destra dello schermo e selezionare Elimina dal menu a discesa.
Eliminare una versione del modello o un modello usando l'API
Avviso
Non è possibile annullare questa azione. È possibile eseguire la transizione di una versione del modello alla fase Archived (Archiviata) invece di eliminarla dal registro. Quando si elimina un modello, tutti gli artefatti del modello archiviati dal registro di modelli dell’area di lavoro e tutti i metadati associati al modello registrato vengono eliminati.
Nota
È possibile eliminare modelli e versioni del modello solo nella fase Nessuna o Archived (Archiviata). Se un modello registrato ha versioni nella fase Staging o Produzione, è necessario eseguirne la transizione alla fase Nessuna o Archived (Archiviata) prima di eliminare il modello.
Eliminare una versione del modello
Per eliminare una versione del modello, usare il metodo delete_model_version() dell'API MLflow Client:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
Elimina un modello
Per eliminare un modello, usare il metodo delete_registered_model() dell'API MLflow Client:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
Condividere modelli tra le aree di lavoro
Databricks consiglia di usare i modelli in Unity Catalog per condividere i modelli tra diversi ambienti di lavoro. Unity Catalog offre un supporto integrato per l'accesso ai modelli tra diverse aree di lavoro, la governance e il log di controllo.
Tuttavia, se si usa il registro dei modelli dell'area di lavoro, è anche possibile condividere modelli tra più aree di lavoro con alcune impostazioni. Ad esempio, è possibile sviluppare e registrare un modello nella propria area di lavoro e accedervi da un'altra area di lavoro, utilizzando un registro dei modelli di area di lavoro remoto. Questo approccio è utile quando più team condividono l'accesso ai modelli. È possibile creare più aree di lavoro e usare e gestire i modelli in questi ambienti.
Copiare oggetti MLflow tra aree di lavoro
Per importare o esportare oggetti MLflow nell'area di lavoro di Azure Databricks, è possibile usare il progetto open source basato sulla community MLflow Export-Import per eseguire la migrazione di esperimenti, modelli e esecuzioni di MLflow tra aree di lavoro.
Con questi strumenti è possibile:
- Condividere e collaborare con altri data scientist nello stesso server di rilevamento o in un altro server di rilevamento. Ad esempio, nell'area di lavoro è possibile clonare un esperimento da un altro utente.
- Copiare un modello da un'area di lavoro a un'altra, ad esempio da uno sviluppo a un'area di lavoro di produzione.
- Copiare gli esperimenti MLflow ed eseguirli dal server di rilevamento locale nell'area di lavoro di Databricks.
- Eseguire il backup di esperimenti e modelli cruciali in un'altra area di lavoro di Databricks.
Esempio
Questo esempio illustra come usare il registro di modelli dell’area di lavoro per creare un'applicazione di Machine Learning.