Usare le tabelle delle caratteristiche nel catalogo Unity
Questa pagina descrive come creare e usare le tabelle delle funzionalità in Unity Catalog.
Questa pagina si applica solo alle aree di lavoro abilitate per Unity Catalog. Se la tua area di lavoro non è abilitata per Catalogo Unity, vedere Usare le tabelle delle funzionalità nell'archivio delle funzionalità dell'area di lavoro (legacy).
Per informazioni dettagliate sui comandi e sui parametri usati negli esempi in questa pagina, vedere il riferimento sulle API Python per l'ingegneria delle funzionalità.
Requisiti
L'ingegneria delle funzionalità in Unity Catalog richiede Databricks Runtime 13.2 o versione successiva. Inoltre, il metastore di Unity Catalog deve avere ilmodello di privilegio versione 1.0.
Installare l'ingegneria delle funzionalità nel client Unity Catalog
L'ingegneria delle funzionalità in Unity Catalog ha un client PythonFeatureEngineeringClient. La classe è disponibile in PyPI con il pacchetto databricks-feature-engineering ed è preinstallata in Databricks Runtime 13.3 LTS ML e versioni successive. Se si usa un runtime di Databricks non ML, è necessario installare il client manualmente. Usare la matrice di compatibilità per trovare la versione corretta per la versione di Databricks Runtime.
%pip install databricks-feature-engineering
dbutils.library.restartPython()
Creare un catalogo e uno schema per le tabelle delle funzionalità in Unity Catalog
È necessario creare un nuovo catalogo o usare un catalogo esistente per le tabelle delle funzionalità.
Per creare un nuovo catalogo, è necessario avere il privilegio CREATE CATALOG per il metastore.
CREATE CATALOG IF NOT EXISTS <catalog-name>
Per utilizzare un catalogo esistente, è necessario disporre del privilegio USE CATALOG sul catalogo.
USE CATALOG <catalog-name>
Le tabelle delle funzionalità in Unity Catalog devono essere archiviate in uno schema. Per creare un nuovo schema nel catalogo, è necessario avere il privilegio CREATE SCHEMA per il catalogo.
CREATE SCHEMA IF NOT EXISTS <schema-name>
Creare una tabella di funzionalità in Unity Catalog
Nota
In Unity Catalog, è possibile usare una tabella Delta esistente che include un vincolo di chiave primaria come tabella di funzionalità. Se per la tabella non è stata definita una chiave primaria, è necessario aggiornare la tabella usando le istruzioni DDL ALTER TABLE per aggiungere il vincolo. Vedere Usare una tabella Delta esistente in Unity Catalog come tabella delle funzionalità
Tuttavia, l'aggiunta di una chiave primaria a una tabella di streaming o a una vista materializzata pubblicata in Unity Catalog da una pipeline di Delta Live Tables richiede la modifica dello schema della tabella di streaming o della definizione della vista materializzata in modo che includa la chiave primaria e quindi l'aggiornamento della tabella di streaming o della vista materializzata. Vedere Usare una tabella di streaming o una vista materializzata creata a partire da una pipeline Delta Live Tables da usare come tabella delle funzionalità.
Le tabelle delle funzionalità in Unity Catalog sono tabelle Delta. Le tabelle delle funzionalità devono avere una chiave primaria. Le tabelle delle funzionalità, come gli altri asset di dati in Unity Catalog, sono accessibili usando uno spazio dei nomi a tre livelli: <catalog-name>.<schema-name>.<table-name>.
È possibile usare Databricks SQL, Python FeatureEngineeringClient o una pipeline Delta Live Tables per creare tabelle di funzionalità all'interno di Unity Catalog.
Databricks SQL
È possibile usare qualsiasi tabella Delta con un vincolo di chiave primaria come tabella delle funzionalità. Il codice seguente mostra come creare una tabella con una chiave primaria:
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
Per creare una tabella di funzionalità con serie temporale, aggiungere una colonna oraria come colonna chiave primaria e specificare la parola chiave TIMESERIES. La parola chiave TIMESERIES richiede Databricks Runtime 13.3 LTS o versione successiva.
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
Dopo aver creato la tabella, è possibile scrivervi dei dati come per ogni altra tabella Delta e usarla come tabella delle funzionalità.
Python
Per informazioni dettagliate sui comandi e sui parametri usati negli esempi seguenti, vedere le informazioni di riferimento sull'API Python di progettazione delle funzionalità.
- Scrivere le funzioni Python per calcolare le funzionalità. L'output di ogni funzione deve essere un DataFrame Apache Spark con una chiave primaria univoca. La chiave primaria può essere costituita da una o più colonne.
- Creare una tabella delle funzionalità creando un'istanza
FeatureEngineeringCliente usandocreate_table. - Popolare la tabella delle funzionalità usando
write_table.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
Creare una tabella delle funzionalità in Unity Catalog con la pipeline di Delta Live Tables
Nota
Il supporto di Delta Live Table per i vincoli di tabella è disponibile in anteprima pubblica. Gli esempi di codice seguenti devono essere eseguiti usando il canale di anteprima delle Delta Live Tables.
Qualsiasi tabella pubblicata da una pipeline Delta Live Tables che include un vincolo di chiave primaria può essere usata come tabella di funzionalità. Per creare una tabella in una pipeline di Delta Live Tables con una chiave primaria, è possibile usare Databricks SQL o l'interfaccia di programmazione Python di Delta Live Tables.
Per creare una tabella in una pipeline di Delta Live Tables con una chiave primaria, usare la sintassi seguente:
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
""")
def customer_features():
return ...
Per creare una tabella di funzionalità con serie temporale, aggiungere una colonna oraria come colonna chiave primaria e specificare la parola chiave TIMESERIES.
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
""")
def customer_features():
return ...
Dopo aver creato la tabella, è possibile scrivervi dei dati come per ogni altro set di dati Delta Live Tables e usarla come tabella delle funzionalità.
Usare una tabella Delta esistente in Unity Catalog come tabella delle funzionalità.
Qualsiasi tabella Delta in Unity Catalog dotata di chiave primaria può essere una tabella delle funzionalità in Unity Catalog, con la quale è possibile usare l'interfaccia utente delle funzionalità e l'API.
Nota
- Solo il proprietario della tabella può dichiarare vincoli di chiave primaria. Il nome del proprietario viene visualizzato nella pagina dei dettagli di Esplora cataloghi.
- Verificare che in Unity Catalog, il tipo di dati nella tabella Delta sia supportato dall'Ingegneria delle funzionalità. Vedere Tipi di dati supportati.
- La parola chiave TIMESERIES richiede Databricks Runtime 13.3 LTS o versione successiva.
Se una tabella Delta esistente non ha un vincolo di chiave primaria, è possibile crearne uno come indicato di seguito:
Impostare le colonne chiave primaria su
NOT NULL. Per ogni colonna di chiave primaria, eseguire:ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULLModificare la tabella per aggiungere il vincolo di chiave primaria:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)pk_nameè il nome del vincolo di chiave primaria. Per convenzione, è possibile usare il nome della tabella (senza schema e catalogo) con un suffisso_pk. Ad esempio, in una tabella nominata"ml.recommender_system.customer_features",customer_features_pksarebbe il nome del suo vincolo di chiave primaria.Per fare in modo che la tabella sia una tabella di funzionalità con serie temporali, specificare la parola chiave TIMESERIES in una delle colonne chiave primaria, come indicato di seguito:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)Dopo aver aggiunto il vincolo di chiave primaria nella tabella, la tabella viene visualizzata nell'interfaccia utente Funzionalità ed è possibile usarla come tabella delle funzionalità.
Usare una tabella di streaming o una vista materializzata creata a partire da una pipeline Delta Live Tables da usare come tabella delle funzionalità
Qualsiasi tabella di streaming o vista materializzata in Unity Catalog dotata di chiave primaria può essere una tabella delle funzionalità in Unity Catalog, con la quale è possibile usare l'interfaccia utente delle funzionalità e l'API.
Nota
- Il supporto di Delta Live Table per i vincoli di tabella è disponibile in anteprima pubblica. Gli esempi di codice seguenti devono essere eseguiti usando il canale di anteprima delle Delta Live Tables.
- Solo il proprietario della tabella può dichiarare vincoli di chiave primaria. Il nome del proprietario viene visualizzato nella pagina dei dettagli di Esplora cataloghi.
- Verificare che Progettazione funzionalità in Unity Catalog supporti il tipo di dati nella tabella Delta. Vedere Tipi di dati supportati.
Per impostare le chiavi primarie per una tabella di streaming esistente o una vista materializzata, aggiornare lo schema della tabella di streaming o della vista materializzata nel notebook che gestisce l'oggetto. Aggiornare quindi la tabella per aggiornare l'oggetto Unity Catalog.
Di seguito è riportata la sintassi per aggiungere una chiave primaria a una vista materializzata:
Databricks SQL
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
Python
import dlt
@dlt.table(
schema="""
id int NOT NULL PRIMARY KEY,
...
"""
)
def existing_live_table():
return ...
Usare una vista esistente in Unity Catalog come tabella delle funzionalità
Per usare una vista come tabella delle funzionalità, è necessario usare databricks-feature-engineering versione 0.7.0 o successiva, integrata in Databricks Runtime 16.0 ML.
Una semplice vista SELECT in Unity Catalog può essere una tabella di funzionalità in Unity Catalog, ed è possibile usare l'API delle funzionalità con la tabella.
Nota
- Una vista SELECT semplice viene definita come vista creata da una singola tabella Delta nel catalogo Unity che può essere usata come tabella delle funzionalità e le cui chiavi primarie sono selezionate senza JOIN, GROUP BYo clausole DISTINCT. Le parole chiave accettabili nell'istruzione SQL sono SELECT, FROM, WHERE, ORDER BY, LIMITe OFFSET.
- Vedere tipi di dati supportati per i tipi di dati supportati.
- Le tabelle delle caratteristiche basate su visualizzazioni non vengono visualizzate nell'interfaccia utente delle funzionalità.
- Se le colonne vengono rinominate nella tabella Delta di origine, le colonne nell'istruzione SELECT per la definizione della vista devono essere rinominate in modo che corrispondano.
Di seguito è riportato un esempio di una visualizzazione SELECT semplice che può essere usata come tabella delle funzionalità:
CREATE OR REPLACE VIEW ml.recommender_system.content_recommendation_subset AS
SELECT
user_id,
content_id,
user_age,
user_gender,
content_genre,
content_release_year,
user_content_watch_duration,
user_content_like_dislike_ratio
FROM
ml.recommender_system.content_recommendations_features
WHERE
user_age BETWEEN 18 AND 35
AND content_genre IN ('Drama', 'Comedy', 'Action')
AND content_release_year >= 2010
AND user_content_watch_duration > 60;
Le tabelle delle funzionalità basate sulle viste possono essere usate per il training e la valutazione del modello offline. Non possono essere pubblicati nei negozi online. Le funzionalità di queste tabelle e modelli basati su queste funzionalità non possono essere gestite.
Aggiornare una tabella delle funzionalità in Unity Catalog
È possibile aggiornare una tabella delle funzionalità in Unity Catalog aggiungendo nuove funzionalità o modificando righe specifiche in base alla chiave primaria.
I seguenti metadati della tabella delle funzionalità non devono essere aggiornati:
- Chiave primaria.
- Chiave di partizione.
- Nome o tipo di dati di una funzionalità esistente.
La modifica di tali pipeline causerà l'interruzione delle pipeline downstream che usano funzionalità per il training e la gestione dei modelli.
Aggiungere nuove funzionalità a una tabella delle funzionalità esistente in Unity Catalog
È possibile aggiungere nuove funzionalità a una tabella delle funzionalità esistente in uno dei due modi seguenti:
- Aggiornare la funzione di calcolo delle funzionalità esistente ed eseguire
write_tablecon il dataframe restituito. In questo modo lo schema della tabella delle funzionalità viene aggiornato e i nuovi valori di funzionalità basati sulla chiave primaria vengono uniti. - Creare una nuova funzione di calcolo delle funzionalità per calcolare i nuovi valori di funzionalità. Il dataframe restituito da questa nuova funzione di calcolo deve contenere le chiavi primarie e di partizione delle tabelle delle funzionalità (se definite). Eseguire
write_tablecon il dataframe per scrivere le nuove funzionalità nella tabella delle funzionalità esistente usando la stessa chiave primaria.
Aggiornare solo righe specifiche in una tabella delle funzionalità
Usare mode = "merge" in write_table. Le righe la cui chiave primaria non esiste nel DataFrame inviato nella chiamata write_table restano invariate.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
Pianificare un processo per aggiornare una tabella delle funzionalità
Per garantire che le funzionalità nelle tabelle delle funzionalità abbiano sempre i valori più recenti, Databricks consiglia di creare un processo che esegua un notebook per aggiornare la tabella delle funzionalità a intervalli regolari, ad esempio ogni giorno. Se è già stato creato un processo non pianificato, è possibile convertirlo in un processo pianificato per assicurarsi che i valori delle funzionalità siano sempre aggiornati. Consultare Panoramica dell'orchestrazione in Databricks.
Il codice per aggiornare una tabella delle funzionalità usa mode='merge', come illustrato nell'esempio seguente.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Archiviare i valori passati delle funzionalità giornaliere
Definire una tabella delle funzionalità con una chiave primaria composita. Includere la data nella chiave primaria. Ad esempio, in una tabella delle funzionalità customer_features, per avere delle letture efficienti, è possibile usare una chiave primaria composita (date, customer_id) e una chiave di partizione date.
Databricks consiglia di abilitare il clustering liquido nella tabella per letture efficienti. Se non si usa il clustering liquido, impostare la colonna data come chiave di partizione per ottenere prestazioni di lettura migliori.
Databricks SQL
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
-- If you are not using liquid clustering, uncomment the following line.
-- PARTITIONED BY (`date`)
COMMENT "Customer features";
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
# If you are not using liquid clustering, uncomment the following line.
# partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
È quindi possibile creare codice da leggere dal filtro della tabella delle funzionalità date riferito al periodo di tempo di interesse.
È inoltre possibile creare una tabella delle funzionalità con serie temporale che consenta ricerche temporali quando si usa create_training_set o score_batch. Vedere Creare una tabella delle funzionalità in Unity Catalog.
Per mantenere aggiornata la tabella delle funzionalità, configurare un processo pianificato regolarmente per scrivere funzionalità o trasmettere in streaming nuovi valori delle funzionalità nella tabella delle funzionalità.
Creare una pipeline di calcolo delle funzionalità di streaming per aggiornare le funzionalità
Per creare una pipeline di calcolo delle funzionalità di streaming, passare uno streaming DataFrame come argomento a write_table. Il metodo restituisce un oggetto StreamingQuery.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.table("prod.events.customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Leggere da una tabella di funzionalità in Unity Catalog
Usare read_table per leggere i valori delle funzionalità.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
Cercare ed esplorare le tabelle delle funzionalità in Unity Catalog
Usare l'interfaccia utente delle funzionalità per cercare o esplorare le tabelle delle funzionalità in Unity Catalog.
Cliccare
 Features (Funzionalità) nella barra laterale per visualizzare l'interfaccia utente delle funzionalità.
Features (Funzionalità) nella barra laterale per visualizzare l'interfaccia utente delle funzionalità.Selezionare il catalogo con il selettore di catalogo per visualizzare tutte le tabelle delle funzionalità disponibili in tale catalogo. Nella casella di ricerca immettere tutto o parte del nome di una tabella di funzionalità, di una funzionalità o di un commento. È anche possibile immettere tutto o parte della chiave o del valore di un tag. Il testo della ricerca non fa distinzione tra maiuscole e minuscole.
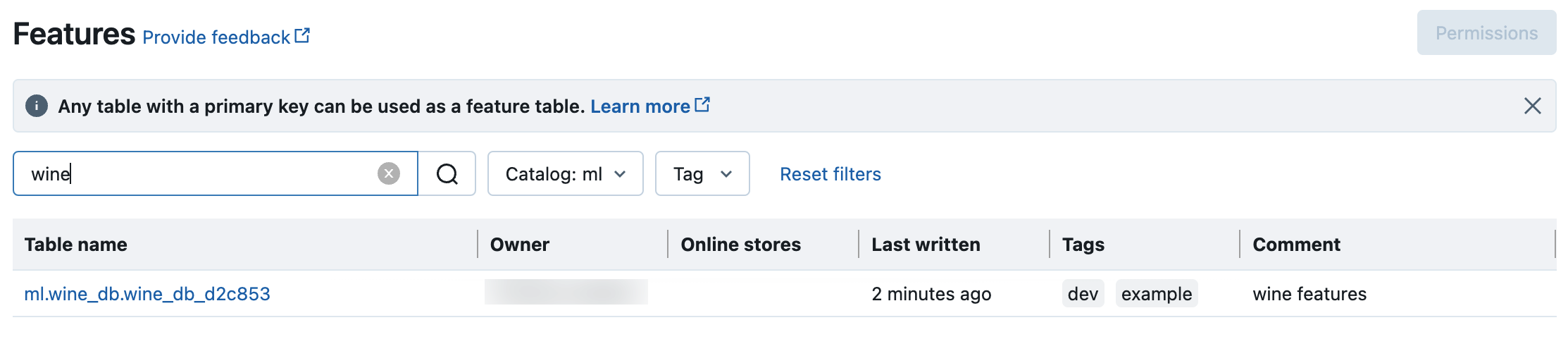
Ottenere i metadati delle tabelle delle funzionalità in Unity Catalog
Usare get_table per ottenere i metadati della tabella delle funzionalità.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
Usare tag con tabelle di funzionalità e funzionalità in Unity Catalog
È possibile usare tag, ovvero semplici coppie chiave-valore, per classificare e gestire le tabelle delle funzionalità e le funzionalità.
Per le tabelle delle funzionalità, è possibile creare, modificare ed eliminare tag usando Esplora cataloghi, istruzioni SQL in un notebook o un editor di query SQL oppure l'API Python di Ingegneria delle funzionalità.
Per le funzionalità, è possibile creare, modificare ed eliminare tag usando Esplora cataloghi o istruzioni SQL in un notebook o in un editor di query SQL.
Vedere Applicare tag agli oggetti a protezione diretta di Unity Catalog e API Python di Ingegneria delle funzionalità e Feature Store dell'area di lavoro.
L'esempio seguente illustra come usare l'API Python di progettazione delle funzionalità per creare, aggiornare ed eliminare i tag della tabella delle funzionalità.
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
Eliminare una tabella delle funzionalità in Unity Catalog
È possibile eliminare una tabella delle funzionalità in Unity Catalog eliminando direttamente la tabella Delta di Unity Catalog usando Esplora cataloghi oppure l'API Python di Ingegneria delle funzionalità.
Nota
- L'eliminazione di una tabella delle funzionalità può causare errori imprevisti nei produttori upstream e nei consumatori downstream (modelli, endpoint e processi pianificati). È necessario eliminare gli archivi online pubblicati presso il proprio provider di servizi cloud.
- Quando si elimina una tabella delle funzionalità in Unity Catalog, viene eliminata anche la tabella Delta sottostante.
-
drop_tablenon è supportato in Databricks Runtime 13.1 ML o versione successiva. Per eliminare la tabella, usare il comando SQL.
È possibile usare Databricks SQL o FeatureEngineeringClient.drop_table per eliminare una tabella delle funzionalità dall'Unity Catalog:
Databricks SQL
DROP TABLE ml.recommender_system.customer_features;
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)
Condividere una tabella delle funzionalità in Unity Catalog tra aree di lavoro o account
Una tabella delle funzionalità in Unity Catalog è accessibile a tutte le aree di lavoro assegnate al metastore Unity Catalog della tabella.
Per condividere una tabella delle funzionalità con aree di lavoro non assegnate allo stesso metastore di Unity Catalog, usare Delta Sharing.