Classificazione con AutoML
Usare AutoML per trovare automaticamente l'algoritmo di classificazione e la configurazione degli iperparametri migliori per stimare l'etichetta o la categoria di un determinato input.
Configurare l'esperimento di classificazione con l'interfaccia utente
È possibile configurare un problema di classificazione usando l'interfaccia utente di AutoML seguendo questa procedura:
Nella barra laterale selezionare Esperimenti.
Nella scheda Classificazione
selezionare Avvia training .Viene visualizzata la pagina Configura esperimento AutoML. In questa pagina, viene configurato il processo AutoML, specificando il set di dati, il tipo di problema, la colonna bersaglio o etichetta da prevedere, la metrica da usare per valutare e assegnare punteggi alle esecuzioni dell'esperimento e le condizioni di interruzione.
Nel campo
calcolo selezionare un cluster che esegue Databricks Runtime ML. Sotto Set di dati, seleziona Sfoglia.
Passare alla tabella da usare e fare clic su Selezionare. Viene visualizzato lo schema della tabella.
- In Databricks Runtime 10.3 ML e versioni successive è possibile specificare quali colonne usare AutoML per il training. Non è possibile rimuovere la colonna selezionata come destinazione di stima o come colonna temporale per suddividere i dati.
- In Databricks Runtime 10.4 LTS ML e versioni successive è possibile specificare il modo in cui i valori Null vengono selezionando dall'elenco a discesa Impute with. Per impostazione predefinita, AutoML seleziona un metodo di imputazione in base al tipo di colonna e al contenuto.
Nota
Se si specifica un metodo di imputazione non predefinito, AutoML non esegue il rilevamento dei tipi semantici.
Fare clic nel campo Obiettivo di previsione. Viene visualizzato un elenco a discesa che elenca le colonne visualizzate nello schema. Seleziona la colonna di cui vuoi che il modello faccia previsioni.
Il campo Nome esperimento mostra il nome predefinito. Per modificarlo, digitare il nuovo nome nel campo.
È anche possibile:
- Specificare opzioni di configurazione aggiuntive.
- Usare tabelle delle funzionalità esistenti in Feature Store per aumentare il set di dati di input originale.
Configurazioni avanzate
Aprire la sezione Configurazione avanzata (facoltativa) per accedere a questi parametri.
- La metrica di valutazione è la metrica primaria usata per assegnare un punteggio alle esecuzioni.
- In Databricks Runtime 10.4 LTS ML e versioni successive è possibile escludere i framework di training dalla considerazione. Per impostazione predefinita, AutoML esegue il training dei modelli usando i framework elencati in Algoritmi AutoML.
- È possibile modificare le condizioni di arresto. Le condizioni di arresto predefinite sono:
- Per gli esperimenti di previsione, eseguire l'aresto dopo 120 minuti.
- In Databricks Runtime 10.4 LTS ML e versioni successive, per gli esperimenti di classificazione e regressione, eseguire l'arresto dopo 60 minuti o dopo aver completato 200 prove, a seconda di quale situazione si verifica per prima. Per Databricks Runtime 11.0 ML e versioni successive, il numero di prove non viene usato come condizione di arresto.
- Inoltre, in Databricks Runtime 10.4 ML e versioni successive, gli esperimenti di classificazione e regressione, AutoML incorpora l'arresto anticipato; interromperà il training e l'ottimizzazione dei modelli se la metrica di convalida non sta più migliorando.
- In Databricks Runtime 10.4 LTS ML e versioni successive è possibile selezionare un
time columnper suddividere i dati per il training, la convalida e il test in ordine cronologico (si applica solo alla classificazione e regressione). - Databricks consiglia di non popolare il campo Directory dati. In questo modo viene attivato il comportamento predefinito dell'archiviazione sicura del set di dati come artefatto MLflow. È possibile specificare un percorso DBFS, ma in questo caso il set di dati non eredita le autorizzazioni di accesso dell'esperimento AutoML.
Eseguire l'esperimento e monitorare i risultati
Per avviare l'esperimento AutoML, cliccare Avvia AutoML. L'esperimento inizia a essere eseguito e viene visualizzata la pagina di training AutoML. Per aggiornare la tabella delle esecuzioni, fare clic sul pulsante Aggiorna  .
.
Visualizzare lo stato dell'esperimento
Da questa pagina è possibile:
- Arrestare l'esperimento in qualsiasi momento.
- Aprire un notebook di esplorazione dei dati.
- Monitorare le esecuzioni.
- Passare alla pagina di esecuzione per qualsiasi esecuzione.
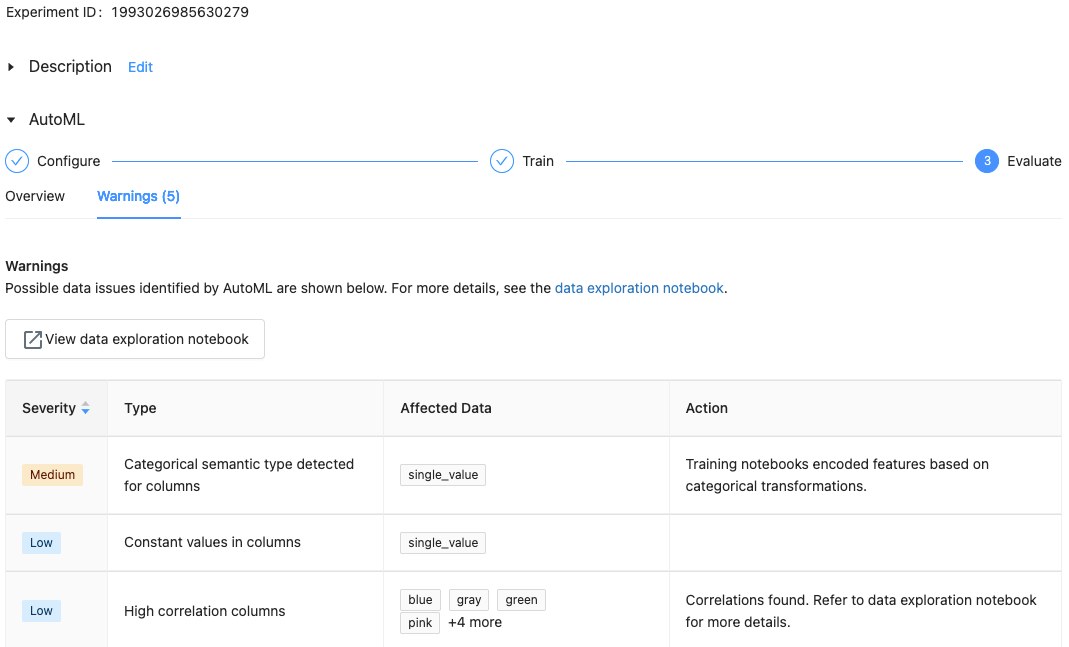
Con Databricks Runtime 10.1 ML e versioni successive, AutoML visualizza avvisi per potenziali problemi con il set di dati, ad esempio tipi di colonna non supportati o colonne a cardinalità elevata.
Nota
Databricks fa del suo meglio per indicare potenziali errori o problemi. Tuttavia, queste segnalazioni potrebbero non essere complete e potrebbero non acquisire i problemi o gli errori che l'utente sta cercando.
Per visualizzare eventuali avvisi per il set di dati, cliccare la scheda Avvisi nella pagina di training o nella pagina dell'esperimento al termine dell'esperimento.
Visualizza risultati
Al termine dell'esperimento, è possibile:
- Registrare e distribuire uno dei modelli con MLflow.
- Selezionare Visualizza notebook per il modello migliore per esaminare e modificare il notebook che ha creato il modello migliore.
- Selezionare Visualizza notebook di esplorazione dei dati per aprire il notebook di esplorazione dei dati.
- Cerca, filtra e ordina le esecuzioni nella tabella delle esecuzioni.
- Vedere i dettagli per qualsiasi esecuzione:
- Il notebook generato contenente il codice sorgente per un'esecuzione di prova è disponibile facendo clic sull'esecuzione di MLflow. Il notebook viene salvato nella sezione Artefatti della pagina di esecuzione. È possibile scaricare questo notebook e importarlo nell’area di lavoro, se il download degli artefatti viene abilitato dagli amministratori dell’area di lavoro.
- Per visualizzare i risultati dell'esecuzione, fare clic nella colonna Modelli o nella colonna Ora di inizio. Viene visualizzata la pagina di esecuzione, che mostra informazioni sull'esecuzione della versione di valutazione (ad esempio parametri, metriche e tag) e sugli artefatti creati dall'esecuzione, incluso il modello. Questa pagina include anche frammenti di codice che possono essere utilizzati per eseguire previsioni con il modello.
Per tornare a questo esperimento AutoML in un secondo momento, trovalo nella tabella nella pagina esperimenti. I risultati di ogni esperimento AutoML, inclusi i notebook di esplorazione e training dei dati, vengono archiviati in una cartella databricks_automl nella home directory dell'utente che ha eseguito l'esperimento.
Registrare e implementare un modello
È possibile registrare e distribuire il modello con l'interfaccia utente di AutoML:
- Selezionare il collegamento nella colonna modelli per registrare il modello. Al termine di un'esecuzione, la riga superiore è il modello migliore (in base alla metrica primaria).
- Selezionare il pulsante Registra Modello
 per registrare il modello nel Registro Modelli .
per registrare il modello nel Registro Modelli . - Selezionare
 Modelli nella barra laterale per accedere al Registro dei Modelli.
Modelli nella barra laterale per accedere al Registro dei Modelli. - Seleziona il nome del tuo modello nella tabella dei modelli.
- Dalla pagina del modello registrato è possibile gestire il modello con Model Serving.
Nessun modulo denominato pandas.core.indexes.numeric
Quando si gestisce un modello compilato usando AutoML con Model Serving, è possibile che venga visualizzato l'errore: No module named 'pandas.core.indexes.numeric.
Ciò è dovuto a una versione incompatibile pandas tra AutoML e l'ambiente endpoint di gestione del modello. È possibile risolvere questo errore eseguendo lo script add-pandas-dependency.py. Lo script modifica requirements.txt e conda.yaml per il modello registrato in modo da includere la versione di dipendenza pandas appropriata: pandas==1.5.3.
- Modificare lo script per includere la
run_iddell'esecuzione MLflow in cui è stato registrato il modello. - Ripetere la registrazione del modello nel Registro di sistema del modello MLflow.
- Provare a gestire la nuova versione del modello MLflow.